Agility Meets Stability: Versatile Humanoid Control with Heterogeneous Data
Abstract: Humanoid robots are envisioned to perform a wide range of tasks in human-centered environments, requiring controllers that combine agility with robust balance. Recent advances in locomotion and whole-body tracking have enabled impressive progress in either agile dynamic skills or stability-critical behaviors, but existing methods remain specialized, focusing on one capability while compromising the other. In this work, we introduce AMS (Agility Meets Stability), the first framework that unifies both dynamic motion tracking and extreme balance maintenance in a single policy. Our key insight is to leverage heterogeneous data sources: human motion capture datasets that provide rich, agile behaviors, and physically constrained synthetic balance motions that capture stability configurations. To reconcile the divergent optimization goals of agility and stability, we design a hybrid reward scheme that applies general tracking objectives across all data while injecting balance-specific priors only into synthetic motions. Further, an adaptive learning strategy with performance-driven sampling and motion-specific reward shaping enables efficient training across diverse motion distributions. We validate AMS extensively in simulation and on a real Unitree G1 humanoid. Experiments demonstrate that a single policy can execute agile skills such as dancing and running, while also performing zero-shot extreme balance motions like Ip Man's Squat, highlighting AMS as a versatile control paradigm for future humanoid applications.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
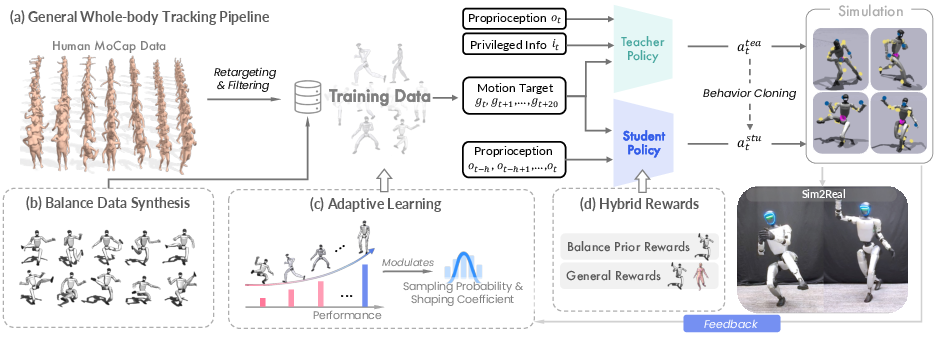
This paper is about teaching a humanoid robot to be both agile and stable at the same time. Think of a person who can run and dance (agility) but also hold tricky poses like standing on one leg without falling (stability). The authors built a single control system, called AMS (Agility Meets Stability), that lets one robot do both kinds of moves smoothly.
What questions did the researchers ask?
The team focused on three simple questions:
- Can one robot “brain” learn to do fast, fancy moves and also hold tough balance poses without switching modes?
- How can we give the robot the right practice data so it learns both skills well?
- What training tricks help the robot learn faster and handle new, unseen motions?
How did they teach the robot?
The big idea
They mixed two kinds of practice data and designed a smart way to reward the robot during training, so it learns agility and stability together instead of one at the cost of the other.
Two kinds of data (like two kinds of coaches)
- Human motion capture (MoCap): Real people’s movements (e.g., dancing, running). This is great for learning natural, agile motions.
- Computer-generated balance motions: The computer creates safe, physically realistic “hard balance” poses for the robot (like standing on one leg while moving the other foot to a target spot). These are designed with the robot’s body limits in mind, so they’re clean and reliable.
Why both? Human data doesn’t include many extreme balance cases, and some human moves don’t fit a robot’s body perfectly. The computer-made balance moves fill that gap.
Reward system (like a scoring rule in a game)
- General rewards for all motions: The robot gets points for tracking the reference motion well (matching joint positions, speeds, and body orientation).
- Balance-only rewards for the synthetic balance data: Extra points for keeping its center of mass over the support foot, and keeping foot contacts steady. This avoids punishing natural momentum in dynamic moves, while still teaching strong balance when it matters.
In short: agility is learned from human data; extra balance tips are applied only to balance practice.
Adaptive learning (practice what you’re bad at, and adjust difficulty)
- Adaptive sampling: The system watches which motions the robot struggles with and shows those more often, like a tutor giving you more practice on tricky problems.
- Adaptive reward shaping: The “tolerance” in the scoring adjusts per motion over time (using a moving average of errors), so each motion gets a fair challenge level. This avoids one-size-fits-all settings that can hold back either agility or balance.
How the robot learns (teacher–student approach)
- In simulation, a “teacher” policy learns with extra information that a real robot wouldn’t have (like having GPS and x-ray vision during practice).
- Then a “student” policy learns to copy the teacher but uses only sensors a real robot has. This makes it ready for the real world.
They trained in a physics simulator and then deployed on a real Unitree G1 humanoid robot.
What did they find?
Here are the main results in simple terms:
- One policy, two skills: The same robot control system can dance and run (agility), and also hold extreme balance poses like “Ip Man’s Squat” and single-leg stances—even ones it never saw during training.
- Better than previous methods: It tracked motions more accurately and kept better balance than other state-of-the-art systems that focused mainly on agility or mainly on balance.
- Strong generalization: It handled new, unseen motions more reliably, not just the ones it practiced.
- Real-world success: It worked on an actual humanoid robot, not just in simulation. It also handled live teleoperation (a person moves; the robot follows), even with a simple camera-based pose system.
Why is this important? Robots in homes, hospitals, or workplaces need to move naturally and safely. Being both agile and stable in one brain makes them more useful and reliable.
Why it matters (implications and impact)
- Towards truly versatile humanoids: Combining agility and stability in one policy is a big step toward robots that can do day-to-day human-like tasks without falling or becoming stiff.
- Better training recipes: Mixing human data with robot-specific, computer-generated balance data—and rewarding them differently—could become a standard way to train versatile robot skills.
- Safer, more capable helpers: From climbing stairs and turning quickly to reaching and holding tricky poses, robots trained like this could be more helpful in homes, factories, and disaster zones.
Limitations and what’s next
- Not yet precise at hand/foot manipulation: It’s great at whole-body motion, but fine control for tasks like picking up objects needs work.
- Noisy teleoperation: Using a simple RGB camera for human pose tracking adds errors for fast moves. Future work: better teleoperation tools and smarter retargeting.
Overall, AMS shows that agility and stability don’t have to be trade-offs. With the right data and training strategy, a single robot brain can learn both—and do them well in the real world.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and open problems left by the paper that future research could address:
- Dynamic validity of synthetic balance data: the generator enforces a quasi-static CoM-in-support constraint but does not model full dynamics (e.g., centroidal momentum, capture point/ZMP, friction cones, torque/velocity/acceleration limits). How to synthesize balance-critical trajectories that are dynamically feasible under actuation and contact constraints?
- Limited contact modes in synthetic data: generation is restricted to single-support with feet. How to extend to double-support transitions, multi-contact (hands, knees, elbows), contact creation/destruction timing, and hand-assisted balance?
- Source-dependent reward gating: balance priors are applied only to synthetic motions, not to MoCap states that may also require tight balance. Can we learn a state- or phase-dependent gating mechanism that activates balance priors when needed regardless of data source?
- Mixing ratios and scheduling: the paper does not study how the proportion and curriculum of MoCap vs. synthetic data affect learning. What is the optimal mixture, and can automated schedulers or bandit-style controllers tune it online?
- Adaptive sampling biases and stability: sampling uses MPJPE and failure signals that differ in scale across motion families. How robust is it to skewed error distributions and non-stationary learning, and how to prevent catastrophic forgetting of easy but essential motions?
- Adaptive reward shaping sensitivity: EMA-updated per-motion σ parameters may be sensitive to α and body-part weighting. Can we meta-learn or regularize shaping parameters to avoid inconsistent scales and improve stability/convergence guarantees?
- Disturbance rejection and robustness: no tests under external pushes, impulsive forces, or sensor dropouts are reported. How does the policy handle perturbations, and can we train explicit push recovery and robustness to partial observability?
- Terrain and environment diversity: evaluation is limited to flat, rigid ground. How does the policy generalize to slopes, stairs, compliant/uneven or low-friction surfaces, and terrain transitions?
- Sim2real quantification: the work shows qualitative success on hardware but lacks quantitative sim-to-real error analysis (tracking error, latency, actuator dynamics, sensor noise). What are the dominant sim2real gaps and how do domain randomization and actuator modeling mitigate them?
- Torque/impedance control and contact compliance: the controller operates at position level with PD. What benefits arise from torque/impedance whole-body control for contact-rich stability and safe interaction, and how to integrate it with the learned policy?
- End-effector precision and loco-manipulation: acknowledged as a limitation. How to incorporate task-space tracking, force/impedance objectives, and grasp/contact planning to extend AMS to manipulation and coordinated loco-manipulation?
- Teleoperation fidelity: the RGB-only pose pipeline yields noisy global pose and hampers agile locomotion. What are the gains from multi-view, IMU suits, marker-based systems, or online optimization-based retargeting, and how to fuse operator intent with autonomous stabilization?
- Coverage gaps in data: despite synthetic balance data, important behaviors remain underrepresented (e.g., fall-and-recovery, sit/stand, stair/clutter negotiation, acrobatics). How to curate or generate such motions with physics-constrained planners or generative models?
- Perception-free policy: the student relies on proprioception; no exteroceptive perception is used. How to condition on vision/depth/terrain maps and integrate online perception for obstacle-aware whole-body control?
- Evaluation metrics: focus is on MPJPE/contact mismatch/slippage; energy, peak torque/velocity, joint temperature, stability margins (e.g., CoP/ZMP bounds), and time-to-failure are not reported. Can a more comprehensive metric suite reveal trade-offs and hardware stress?
- Baseline breadth: comparisons are limited to OmniH2O and HuB. How does AMS compare against recent agile trackers (e.g., ASAP, BeyondMimic) and large-library policies, including cross-dataset generalization and sample efficiency?
- Morphological generalization: results are shown on Unitree G1 only. Can a single policy generalize across humanoids or be conditioned on morphology, and what adaptations are needed (e.g., retargeting, morphology embeddings)?
- Formal safety and stability guarantees: the method offers no certified guarantees. Can control-theoretic constraints (CBFs/CLFs, robust MPC) be incorporated to provide verifiable safety/stability while retaining agility?
- Transition fluency across motions: sequencing and blending of diverse motions is not analyzed. How to ensure smooth, safe transitions and online motion selection under high-level commands?
- Teacher-student observability: privileged info used by the teacher and the student’s sensing stack are not fully specified. What is the impact of different sensory modalities (IMU, force/torque, foot contact sensors) and recurrent memory on performance under partial observability?
- Failure mode characterization: the paper lacks a taxonomy of common failures (e.g., foot scuff, pelvis yaw drift, contact timing errors). A systematic failure analysis could guide targeted data augmentation and reward design.
- Computational footprint: training time, GPU hours, and runtime latency on robot are not reported. What are the compute requirements and scalability limits for larger motion libraries and more complex synthetic generators?
- Reproducibility of the generator: several optimization details (support rectangle dimensions, ε thresholds, solver settings) and equation typos suggest ambiguity. Can the authors release exact parameters, seeds, and code to ensure reproductions match reported performance?
- Friction and contact modeling: the slippage metric is reported, but friction identification and contact force validation are not. How to incorporate friction estimation and ensure friction-cone feasibility both in generation and policy training?
- Autonomy-teleop fusion: teleoperation shows promise but struggles with global locomotion. How to robustly fuse human intent with autonomous stabilization/locomotion policies for shared control in dynamic tasks?
Practical Applications
Immediate Applications
Below is a concise set of real‑world use cases that can be deployed now, grounded in the paper’s findings and methods.
- Versatile humanoid demo and teleoperation for non-manipulative tasks — sectors: robotics, entertainment, education
- Description: Deploy the AMS policy on humanoids (e.g., Unitree G1) to execute expressive, dynamic motions (dancing, running) and extreme balance poses (single-leg stances, Ip Man’s Squat) under operator control via RGB pose estimation.
- Tools/Products/Workflows: AMS teacher–student policy; teleop via off-the-shelf 2D/3D pose estimation (e.g., METRABS); simple retargeting pipeline; motion library playback.
- Assumptions/Dependencies: Comparable humanoid hardware with PD control; safety supervision; teleop camera placement; noise-tolerant global pose scaling; terrain with adequate friction; no precise manipulation.
- Balance stress testing and QA for humanoid hardware — sectors: robotics manufacturing, testing and certification
- Description: Use synthetic balance motion generator to systematically probe stability (contact mismatch, slippage), quantify tracking errors, and validate hardware/software stacks before field deployment.
- Tools/Products/Workflows: Synthetic balance motion generator; test suite with contact/slippage metrics; batch evaluation pipeline in IsaacGym; hybrid reward templates for tuning stability.
- Assumptions/Dependencies: Accurate robot model (joint limits, mass distribution), simulator fidelity, domain randomization parameters aligned with hardware.
- Rapid motion design for shows, retail displays, and outreach — sectors: entertainment, marketing, education
- Description: Retarget human MoCap choreographies to robots and augment with synthetic balance variants to produce reliable performances without falls.
- Tools/Products/Workflows: MoCap retargeting; AMS policy; curated motion library; rehearsal-in-simulator workflow; run-of-show scheduler.
- Assumptions/Dependencies: Quality MoCap sources; retargeting filters to remove infeasible kinematics; stage surfaces compliant with balance assumptions.
- Training and benchmarking package for academic courses and labs — sectors: academia (robotics, RL)
- Description: Provide hands-on modules in whole-body tracking, reward design, and data heterogeneity using AMS, with standardized metrics (MPJPE, contact mismatch, slippage) and OOD tests.
- Tools/Products/Workflows: IsaacGym-based training scripts; hybrid reward composer; adaptive sampling utilities; released motion sets (filtered AMASS/LAFAN1 + synthetic balance).
- Assumptions/Dependencies: GPU compute availability; access to datasets; course-safe hardware or simulators; basic RL know-how.
- Operator-in-the-loop mobile telepresence with expressive motion — sectors: service robotics, hospitality, events
- Description: Teleoperated humanoid leverages AMS to move through venues and convey intent/personality via gestures and balanced poses, enhancing user engagement without physical manipulation.
- Tools/Products/Workflows: AMS student policy; mobile base navigation (if available); pose-to-gesture mapping; event control UI.
- Assumptions/Dependencies: Controlled environments; fallback stop mechanisms; minimal interaction force requirements.
- Model-based augmentation of long-tailed datasets in RL — sectors: software/tools for ML/RL
- Description: Plug the synthetic balance generator into existing RL pipelines to counter long-tail gaps (e.g., underrepresented balance states), improving generalization and safety.
- Tools/Products/Workflows: Generator API; adaptive sampling module; motion-specific reward shaping (EMA-driven σ tuning); teacher–student distillation.
- Assumptions/Dependencies: Access to robot models; reward composability; compatibility with existing simulators.
Long-Term Applications
These use cases require further research, scaling, or development (e.g., precise manipulation, richer sensing, broader hardware support).
- Autonomous household assistance blending agility with robust balance — sectors: home robotics, eldercare
- Description: Seamless transitions between locomotion and balance-critical actions (e.g., stepping onto stools, stabilizing while opening doors) with eventual manipulation integration (grasping, tool use).
- Tools/Products/Workflows: AMS extended with end-effector precision control; on-board multimodal sensing (IMU, depth, tactile); online retargeting and planning; safety-aware motion primitives.
- Assumptions/Dependencies: Advances in manipulation accuracy, contact-rich control; standardized home safety protocols; robust perception in clutter; learned recovery behaviors.
- Rehabilitation and balance coaching with adaptive programs — sectors: healthcare, physiotherapy
- Description: Robots demonstrate and co-train balance routines, adjusting difficulty based on patient progress; eventual light haptic support when safe.
- Tools/Products/Workflows: Motion libraries targeted at rehab; clinician dashboard; patient progress tracking; compliance-aware contact control.
- Assumptions/Dependencies: Clinical validation; precise force/impedance control; regulatory approvals; fall-prevention and fail-safes.
- Industrial loco-manipulation on uneven or dynamic terrain — sectors: manufacturing, logistics, construction
- Description: Robots carry or position items while negotiating non-flat surfaces (ramps, grates), maintaining stability during transitions (e.g., stepping over obstacles).
- Tools/Products/Workflows: AMS fused with manipulation planners; terrain estimation and footstep planning; balance-aware task schedulers; safety certification.
- Assumptions/Dependencies: Gripper/dexterous hands; improved contact modeling; certified failsafe behaviors; high-load balance policies.
- Search-and-rescue in hazardous environments — sectors: public safety, defense
- Description: Navigate rubble and unstable structures, maintaining balance under perturbations, eventually with light manipulation (opening doors, clearing debris).
- Tools/Products/Workflows: Robust domain randomization for rough terrain; disturbance-recovery policies; operator guidance via multimodal teleop; mission planning.
- Assumptions/Dependencies: High-reliability hardware; battery endurance; robust communications; tested emergency stop and recovery.
- Foundation control models for humanoids (cross-platform generalization) — sectors: robotics software, standards
- Description: Pretrained, adaptable AMS-like policies shipped with humanoid platforms, fine-tuned to hardware specifics; standardized evaluation and safety benchmarks (agility–stability stress tests).
- Tools/Products/Workflows: AMS SDK; robot-specific adapters; cross-robot retargeting; benchmark suites and certification pipelines.
- Assumptions/Dependencies: Broad dataset sharing; common robot description formats; industry consortiums for standards; reproducible sim-to-real tooling.
- Language-/vision-driven motion synthesis with balance guarantees — sectors: software, HRI, education
- Description: Generate novel motions from natural language or video while enforcing stability constraints via synthetic priors, enabling safe creative expression and instruction.
- Tools/Products/Workflows: Generative motion models conditioned on text/vision; AMS hybrid reward backends; online motion verification; user-friendly authoring tools.
- Assumptions/Dependencies: Reliable generative models; real-time feasibility checks; human-in-the-loop validation; content safety filters.
- Policy and safety frameworks for humanoid deployment in public spaces — sectors: policy/regulation, urban planning
- Description: Establish certification protocols emphasizing diverse balance stress tests, contact consistency, OOD generalization, and teleop privacy/compliance; mandate heterogeneous training data for safety-critical capabilities.
- Tools/Products/Workflows: Test batteries (contact mismatch, slippage thresholds); dataset diversity guidelines; incident reporting workflow; audit checklists.
- Assumptions/Dependencies: Multi-stakeholder standards development; legal clarity on liability; transparent model documentation; independent test labs.
- Educational ecosystems and competitions for agility–stability robotics — sectors: education, STEM outreach
- Description: Curricula and challenges that push integrated agility and stability (e.g., choreographed tasks with balance hurdles), fostering reproducible research and student skills.
- Tools/Products/Workflows: Open motion datasets; simulator-based practice kits; leaderboard with standardized metrics; community hubs.
- Assumptions/Dependencies: Sustained funding; accessible hardware or high-fidelity simulators; IP/licensing for datasets; safety rules.
Notes on global feasibility across applications:
- Current limitations from the paper: limited end-effector precision for manipulation; noise in RGB teleoperation for global pose; dependence on PD control and teacher–student distillation; physics-based sim-to-real gap; terrain/contact assumptions.
- Key dependencies: heterogeneous data availability (MoCap + synthetic generator), robot-specific retargeting/calibration, high-quality sensing (IMU/force/vision), safety oversight and certification, compute resources for training and evaluation.
Glossary
- Adaptive reward shaping: A learning technique that adjusts reward tolerances per motion to reflect current performance and motion type. "adaptive reward shaping maintains motion-specific error tolerances based on individual performance rather than treating all motions uniformly."
- Adaptive sampling: A strategy that increases the sampling probability of poorly-tracked motions to focus learning on harder examples. "Adaptive sampling prioritizes challenging motions by automatically adjusting sampling probability for effective hard sample mining."
- AMASS: A large human motion capture dataset commonly used for training imitation policies. "Our training dataset comprises a filtered subset of the AMASS~\cite{mahmood2019amass} and LAFAN1~\cite{harvey2020robust} datasets"
- Center of mass (CoM): The point representing the average position of mass, critical for balance control. "maintaining the center of mass (CoM) within a valid support region"
- Contact-aware tracking: Tracking that explicitly models and enforces contact states (e.g., feet-ground) to improve stability. "which emphasizes balance motions and contact-aware tracking."
- Contact mismatch (Cont., %): The percentage of frames where the predicted contact state differs from the reference. "(4) Contact mismatch (Cont., \%), measuring the percentage of frames where foot contact states differ from the reference motion;"
- Degrees of Freedom (DoFs): Independent joint variables that define a robot’s configuration space. "a humanoid robot with 23 DoFs"
- Domain randomization: Training-time randomization of simulation parameters to improve sim-to-real transfer. "For fair comparison, all baselines are trained from scratch with consistent domain randomization."
- Exponential Moving Average (EMA): A smoothing method to update parameters using a decayed average of recent measurements. "For stable and responsive adaptation, we employ Exponential Moving Average (EMA) to update these parameters:"
- Global MPJPE: A metric measuring global joint position error relative to world coordinates. "Global MPJPE ($\mathit{E}_{\text{g-mpjpe}$, ) measures global position tracking accuracy."
- Goal-conditioned reinforcement learning (RL): RL where the policy is conditioned on a time-varying target goal (e.g., a reference motion state). "We formulate humanoid whole-body tracking as a goal-conditioned reinforcement learning (RL) task"
- Hard sample mining: Emphasizing difficult training examples to accelerate learning and improve robustness. "Adaptive sampling prioritizes challenging motions by automatically adjusting sampling probability for effective hard sample mining."
- Hybrid reward scheme: A reward design that mixes general tracking terms with motion-specific balance priors depending on data source. "we introduce a hybrid reward scheme that distinguishes between general motion tracking and balance-specific guidance based on the motion source"
- IsaacGym: A high-throughput GPU-based physics simulator for robotics and RL. "we use IsaacGym~\cite{makoviychuk2021isaac} as our physics simulator."
- Kinematic retargeting: Mapping human motion data to a robot’s kinematics, often introducing errors due to morphology differences. "sensor noise and kinematic retargeting errors"
- LAFAN1: A motion dataset providing human locomotion and action sequences for learning. "Our training dataset comprises a filtered subset of the AMASS~\cite{mahmood2019amass} and LAFAN1~\cite{harvey2020robust} datasets"
- LevenbergâMarquardt solver: A nonlinear least-squares optimization algorithm used for trajectory fitting. "The optimization is solved using LevenbergâMarquardt solver"
- Loco-manipulation: Coordinated locomotion and manipulation tasks performed simultaneously by a robot. "and loco-manipulation~\cite{ben2025homie,li2025amo}"
- Motion capture (MoCap): Recorded human motion data used as reference trajectories for imitation learning. "predominantly rely on human motion capture (MoCap) data for training."
- MPJPE (Root-relative): Mean Per Joint Position Error measured in the body’s local/root frame. "Root-relative MPJPE ($\mathit{E}_{\text{mpjpe}$, ) evaluates local joint position tracking performance."
- Out-of-distribution (OOD): Data or scenarios not seen during training, used to test generalization. "we collect 1000 unseen motions as out-of-distribution (OOD) test data"
- PD controller: Proportional-Derivative joint-level controller tracking desired positions. "The action specifies desired joint positions, applied through a PD controller."
- Privileged information: Extra state information available only during training (e.g., simulator internals) to aid teacher policies. "We train a teacher policy with privileged information "
- Proprioceptive observations: Internal robot sensing (e.g., joint angles, velocities) used as policy inputs. "the system state contains the agentâs proprioceptive observations "
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm for training policies. "using Proximal Policy Optimization (PPO)~\cite{schulman2017proximal}"
- Quasi-static stability: Stability regime where motions are slow enough that dynamic effects are negligible. "focusing on quasi-static stability rather than agility."
- SE(3) interpolation: Interpolating rigid body poses (position and orientation) in the Special Euclidean group. "using SE(3) interpolation."
- Slippage (Slip., m/s): Ground-relative velocity of a contact (e.g., foot), indicating loss of sticking contact. "and (5) Slippage (Slip., ), which quantifies the ground-relative velocity of the support foot"
- Support rectangle: The planar region under the support foot within which the CoM should lie for balance. "where defines the support rectangle"
- Teacher-student-based strategy: A training scheme where a high-information teacher guides a deployable student policy. "adopts a teacher-student-based strategy for reinforcement learning"
- Teleoperation: Controlling a robot in real time using human inputs or pose estimates. "we conduct real-time teleoperation with an off-the-shelf human pose estimation model"
- Trajectory optimization: Optimizing a sequence of states/controls to satisfy objectives and constraints over time. "we employ a two-stage batch trajectory optimization"
- Unitree G1: A specific humanoid robot platform used for real-world experiments. "on a real Unitree G1 humanoid."
- Whole-body tracking (WBT): Imitation control that tracks full-body reference motions across many joints. "train whole-body tracking (WBT) policies"
- Zero-shot: Executing tasks or motions successfully without having seen them during training. "while also performing zero-shot extreme balance motions like Ip Man's Squat"
Collections
Sign up for free to add this paper to one or more collections.

