Towards Adaptable Humanoid Control via Adaptive Motion Tracking
Abstract: Humanoid robots are envisioned to adapt demonstrated motions to diverse real-world conditions while accurately preserving motion patterns. Existing motion prior approaches enable well adaptability with a few motions but often sacrifice imitation accuracy, whereas motion-tracking methods achieve accurate imitation yet require many training motions and a test-time target motion to adapt. To combine their strengths, we introduce AdaMimic, a novel motion tracking algorithm that enables adaptable humanoid control from a single reference motion. To reduce data dependence while ensuring adaptability, our method first creates an augmented dataset by sparsifying the single reference motion into keyframes and applying light editing with minimal physical assumptions. A policy is then initialized by tracking these sparse keyframes to generate dense intermediate motions, and adapters are subsequently trained to adjust tracking speed and refine low-level actions based on the adjustment, enabling flexible time warping that further improves imitation accuracy and adaptability. We validate these significant improvements in our approach in both simulation and the real-world Unitree G1 humanoid robot in multiple tasks across a wide range of adaptation conditions. Videos and code are available at https://taohuang13.github.io/adamimic.github.io/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a humanoid robot to copy a human movement from just one example and then adapt that movement to new situations. The method is called OmniH2O. Think of it like learning a single dance move from a short video and then being able to perform it faster, higher, farther, or in a slightly different place while still keeping the same style and rhythm.
What questions does the paper try to answer?
- Can a robot learn a whole-body skill (like a jump or a racket swing) from only one recorded motion and still perform it well in many different situations?
- How can a robot keep the “feel” and key patterns of the original move, but change things like speed, distance, or timing to fit new goals (for example, hit a ball that’s farther away or jump farther)?
- Is there a way to do this without needing a huge library of example motions or a carefully prepared target motion every time?
How did they do it? (Methods in simple terms)
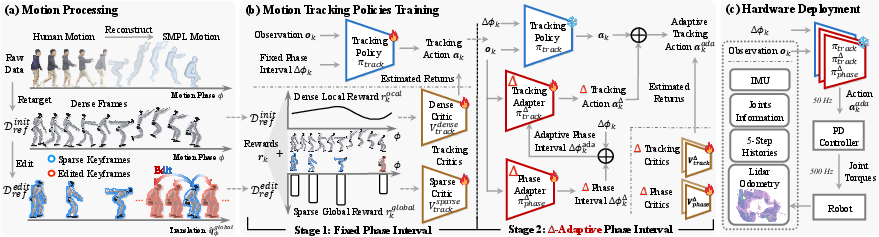
The authors use a two-step training plan with a clever “edit-and-adapt” idea.
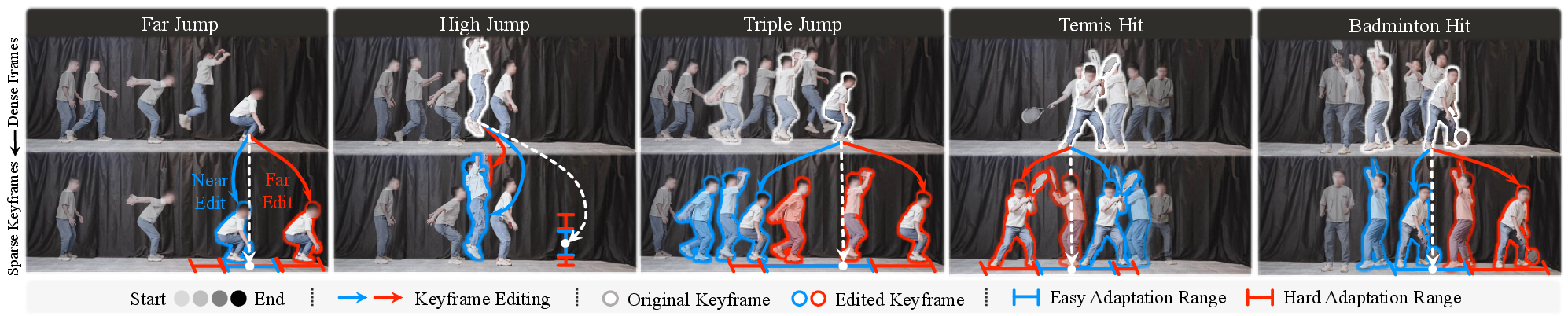
- Pick the key moments and lightly edit them
- Keyframes: Imagine a video of a jump. Instead of using every single frame, they pick a few important snapshots, like start, takeoff, and landing. These are called keyframes.
- Light editing: They adjust just the global placement of a few keyframes (for example, move the landing spot forward to make a longer jump), but they keep the joint movements (the “style” of the motion) the same. This creates an “augmented” set of goals for the robot without making unrealistic assumptions about physics.
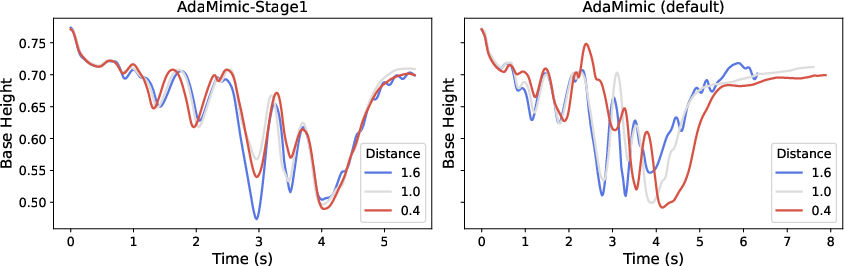
- Teach the robot to fill in the gaps smoothly (Stage 1)
- The robot trains in simulation using reinforcement learning (like trial-and-error practice in a safe virtual gym).
- Rewards:
- Sparse global rewards: Gold stars only at the keyframes to make sure the robot is in the right place and orientation at those important moments.
- Dense local rewards: Gentle guidance all the time to keep the robot’s joints moving like the original human motion.
- Add smart adapters for timing and effort (Stage 2)
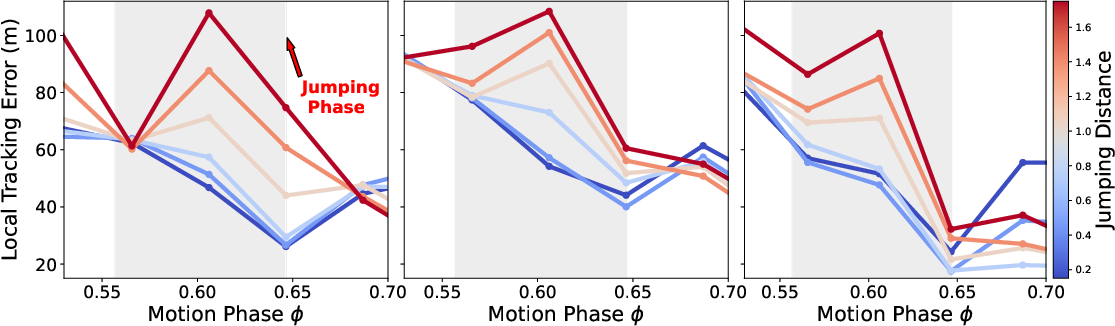
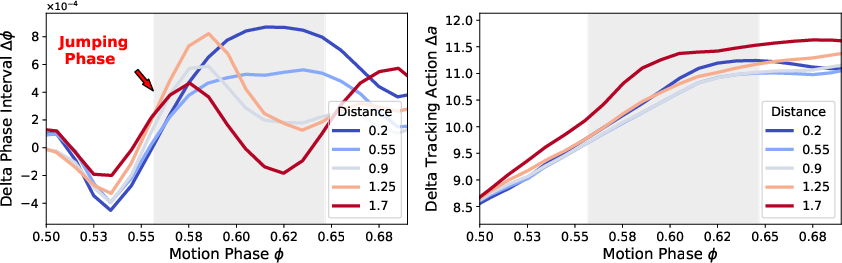
- Phase adapter (timing): This is like a tempo knob for the motion. It lets the robot speed up or slow down parts of the move (a bit like playing a video slightly faster or slower) so it can, for example, stay in the air longer for a farther jump or shorten the airtime for a shorter jump.
- Tracking adapter (muscle fine-tuning): When the timing changes, the robot also tweaks its “muscle commands” (low-level actions) to stay stable and accurate.
- Together, these adapters let the robot “time-warp” the motion while keeping the original pattern.
They test all this both in simulation and on a real humanoid robot (Unitree G1) for skills like different kinds of jumps, tennis hitting, and badminton hitting.
What did they find and why is it important?
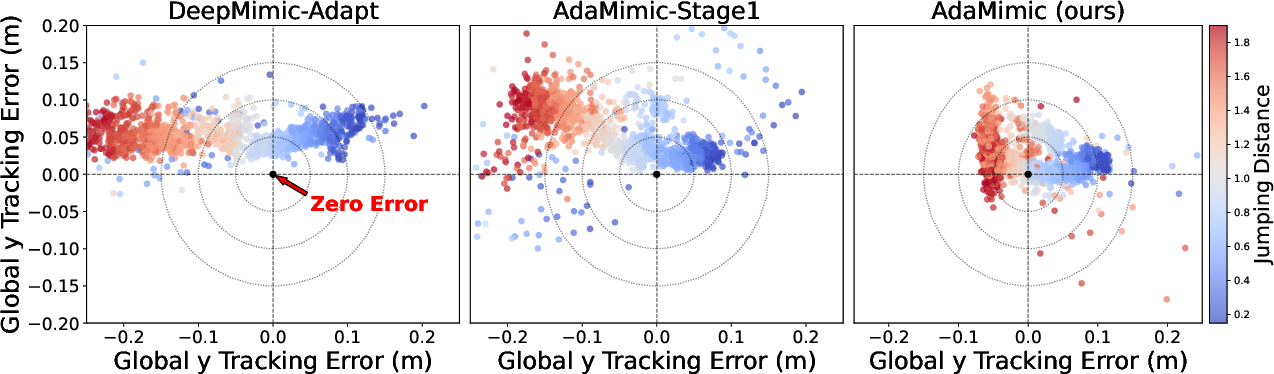
- Strong adaptation from just one motion: The robot can learn from a single demonstration (like one jump or one hit) and then perform versions of it that are higher, farther, or shifted, while still looking like the original move.
- Accurate and smooth: Compared to other methods, OmniH2O keeps the motion’s style accurate (it really looks like the demo) and makes it less jerky and more stable.
- Works in the real world: The trained policies ran on a real humanoid robot and handled challenging variations, not just easy ones.
- Beats common baselines:
- Methods that treat motions as a “style” often adapt but lose precision and look jerky.
- Methods that track motion frame-by-frame can be precise but need many example motions and often break when the motion edits are physically unrealistic.
- Large “universal” trackers trained on tons of data still struggled with agile moves here. OmniH2O did better with just one motion plus smart editing and adapters.
Why it matters: Training robots usually needs lots of data. Doing more with less (one motion) is faster, cheaper, and easier. And being both adaptable and accurate is key for real tasks, like sports moves or agile actions.
What does this mean for the future?
- Fewer examples needed: This approach could train robots quickly from small amounts of data while keeping motions realistic and safe.
- Broader skills: It could help humanoids learn many whole-body skills—jumps, swings, and complex actions—then tailor them on the fly.
- Real-world readiness: Because the method considers physics and uses timing/action adapters, it’s more likely to work outside the lab.
Simple note on limitations and next steps:
- Right now, people still pick keyframes and simple edits by hand; automating that would help.
- The method works best for tasks with clear “knobs” (like jump distance); handling fuzzier tasks is a future goal.
- Adding perception (seeing and reacting in real time) would let the robot adapt to moving targets or changing environments even better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or left unexplored in the paper. Each item is phrased to support actionable follow-up research.
- Automatic discovery of keyframes: Develop methods to infer $#1{\Phi}^{\mathrm{key}$ (semantic and non-semantic) from data rather than manual selection; quantify sensitivity to the number and placement of keyframes across tasks.
- General motion editing functions: Learn or synthesize that supports multi-dimensional global changes (translations, rotations, curved paths), obstacle avoidance, and terrain-aware constraints while preserving physical plausibility.
- Adapting local motion patterns when required: Enable controlled deviations from the “strictly preserved” local joint trajectories to accommodate environment-driven changes (e.g., altered contact timings, stance width, footfall sequence), while maintaining style consistency.
- Principled bounds for time warping: Derive safety- and dynamics-informed constraints for the phase adapter outputs (e.g., bounds on ), and study their effect on stability, performance, and failure modes.
- End-to-end adapter optimization: Address training instability that currently necessitates freezing the tracking policy in stage two; investigate curricula, regularization, or alternative objectives to enable joint optimization without performance degradation.
- Reward sensitivity and automation: Perform a systematic sensitivity analysis of reward weights (including the sparse/dense grouping and numerous regularizers) and explore automatic or learned reward tuning strategies.
- ψ acquisition at test time: Clarify and generalize how the task variable is provided on hardware; design perception or estimation modules to infer online and evaluate robustness to estimation error.
- Perception for interactive tasks: Integrate environment and object perception (e.g., ball tracking, predicted impact timing/pose) to enable closed-loop reactive adaptation rather than open-loop execution.
- Hardware evaluation of global tracking: Add accurate motion capture or higher-fidelity odometry to measure global errors on hardware (e.g., ), and analyze the impact of drift and sensing latency on tracking quality.
- Terrain and contact variability: Test and adapt to uneven/compliant terrain, friction changes, and unexpected contact events; extend editing and rewards to include ground height and surface properties.
- Morphology generalization: Validate on multiple humanoid platforms with different kinematics and actuator characteristics; study retargeting portability and policy transfer across morphologies.
- Safety and physical limits: Introduce formal safety constraints (e.g., ground reaction force bounds, joint load limits) and provide guarantees or certified checks to prevent unsafe behaviors during aggressive adaptations.
- Adaptation range extrapolation: Quantify how performance degrades when extrapolating beyond the trained adaptation ranges; design curricula or regularizers to expand the reliable adaptation envelope.
- Multi-task/unified policy: Investigate whether a single policy can adapt across multiple skills from single references (skill composition, switching, and adapters re-use), rather than training per-skill policies.
- Robust online phase estimation: Develop phase-tracking mechanisms resilient to disturbances and sensor noise without relying on a full reference trajectory; study phase drift detection and correction.
- Energy efficiency and thermal behavior: Measure and optimize energy consumption and actuator heating during adapted motions, especially for high-power, rapid movements.
- Computational cost and sample efficiency: Report training time and sample requirements; explore more sample-efficient or model-based algorithms, offline RL, or on-device adaptation for practical deployment.
- Automatic semantic event detection: Create general-purpose detectors (e.g., take-off, landing, impact) from contact/IMU data to define $#1{\Phi}^{\mathrm{key}$ for non-jumping skills and less structured motions.
- Rich editing for racket/arm tasks: Extend editing to hand/racket orientation, impact timing, and lateral displacement for tennis/badminton, beyond simple distance changes, and validate resulting physical plausibility.
- Quantitative style preservation: Define and evaluate additional style-consistency metrics (e.g., learned style classifiers, tempo/rhythm measures) beyond dense local errors to rigorously assess “pattern preservation.”
- Sim-to-real quantification: Systematically characterize sim–hardware mismatch (PD gains, actuator dynamics, contact models) and integrate system identification loops to reduce transfer gaps.
- Robustness to sensing delays and noise: Evaluate controller performance under FastLIO’s 10 Hz updates, latency, and noisy state estimation; design observers/filters or adapter-level compensations.
- Hardware experiment scale and statistics: Increase the number and diversity of trials, tasks, and conditions to improve statistical confidence; include real-world ablations isolating the impact of keyframes vs. adapters.
Practical Applications
Immediate Applications
The following applications can be deployed now with modest integration effort, primarily in settings that do not require real-time perception or complex contact with the environment. They leverage the paper’s single-clip adaptive motion tracking, sparse keyframe editing, and adapter-based time warping.
Industry
- Rapid skill onboarding for humanoid demos and showrooms (robotics, entertainment)
- Use OmniH2O’s pipeline to teach a humanoid a new choreographed motion (e.g., a short dance, bow, gesture, jump) from a single video and adapt it to different stage layouts (varying distances or landing spots).
- Tools/workflows: “Single-Clip Skill Onboarding” pipeline (video → GVHMR → SMPL → retarget → sparse keyframe editor → Stage-1 tracking → Stage-2 adapters → deploy).
- Assumptions/dependencies: Non-interactive motions, reliable retargeting (GVHMR/SMPL), stable PD control and odometry; Unitree G1 or similar hardware with comparable morphology.
- Event marketing and theme park robots performing adaptable choreographies (entertainment, retail)
- Adapt reference motions to different prop placements or audience positions by editing sparse global keyframes (e.g., where to stop, jump, or point).
- Tools/products: “Keyframe Adaptive Motion Editor” plug-in for robotics middleware, pre-made adapter-tuned choreo packs.
- Assumptions/dependencies: Safety constraints, space free of unpredictable human interference; calibration between SMPL and robot kinematics.
- Warehouse and manufacturing demos with non-contact routines (robotics, manufacturing)
- Demonstrate consistent, spatially adjustable motions—e.g., approach-and-inspect, step-over, turn-and-signal—without needing large motion datasets.
- Tools/workflows: Adapter-augmented controllers for path-dependent routines; sparse global keyframe templates per workstation.
- Assumptions/dependencies: Motions remain largely non-contact; fixed or lightly varying spatial parameters (distances, positions); basic localization (e.g., lidar odometry).
Academia
- Low-data motion tracking benchmarks and baselines (robotics research, simulation)
- Replace large motion datasets with single-clip inputs and sparse keyframe augmentation to study adaptation vs. imitation accuracy trade-offs.
- Tools/products: OmniH2O codebase integrated into Isaac Gym; “Adapter Ablation Suite” to evaluate phase/track adapters and reward sparsity.
- Assumptions/dependencies: Access to simulation (Isaac Gym), PPO or equivalent RL stack, standardized retargeting pipeline.
- Physically plausible motion editing from sparse constraints (graphics, animation, robotics)
- Use RL-based tracking to generate dynamic-consistent in-between frames from edited keyframes, improving plausibility over purely kinematic editing.
- Tools/products: Adapter-based time-warping module for animation toolchains; academic datasets of edited keyframes and RL-generated in-betweens.
- Assumptions/dependencies: Accurate rewards (sparse global + dense local) and separate critics; limited contact-rich interactions.
Daily Life
- Educational robots demonstrating movement science and sports technique (education, sports training)
- Replay and adapt a tennis or badminton swing pattern from a single clip to different ball placement demos (without real-time ball tracking).
- Tools/workflows: Classroom kits with pre-recorded motions and adjustable keyframes; simple slider for distance/height parameters.
- Assumptions/dependencies: Non-reactive demonstrations (no live ball tracking); safe, constrained environment.
- Home humanoid demonstrations for routine motions (consumer robotics)
- Show safe, pre-scripted motions (e.g., pointing, waving, stepping to marked spots) adapted to living room layouts.
- Tools/products: Consumer-friendly motion library with parameter sliders for spatial edits; safety-focused adapter presets.
- Assumptions/dependencies: Non-contact tasks, limited variability, reliable localization (e.g., simple fiducials or lidar).
Policy
- Data minimization in robot skill acquisition (policy, compliance)
- Encourage organizations to reduce stored motion data by using single-clip learning with sparse edits, aligning with privacy-by-design principles.
- Tools/workflows: Internal guidance and auditing checklists that reference single-clip pipelines; documentation of sparse keyframe edits as “data-light” augmentation.
- Assumptions/dependencies: Legal rights to use the single source clip; clear data governance for video-to-motion conversion.
Long-Term Applications
The following applications are feasible with further research, scaling, and development—particularly adding perception, robust contact modeling, automatic editing, and broader task generalization.
Industry
- Adaptive assembly and pick-and-place from a single human demonstration (manufacturing, logistics)
- Teach robots a base manipulation pattern once; adapt to variable part locations and orientations with perception and time warping.
- Tools/products: “Adapter-augmented Manipulation SDK” integrating vision (pose/segment), impedance control, and sparse keyframe planners.
- Assumptions/dependencies: Robust perception stack, contact/compliance control, safety certification; automatic keyframe selection for complex tasks.
- Real-time sports training partners (sports robotics)
- Humanoids that learn a swing pattern from one clip and adapt in real time to ball trajectories and opponent actions.
- Tools/workflows: Closed-loop controllers combining phase/track adapters with high-frequency vision and predictive models.
- Assumptions/dependencies: Fast perception, responsive balance control, durable hardware; risk management in dynamic, high-impact motions.
- Human-robot collaboration on dynamic tasks (robotics, workplace safety)
- Robots adjust timing and action compensation around human co-workers using adapters, while preserving learned motion patterns.
- Tools/products: Safety-aware adapter policies, proximity sensing, certified HRC (human-robot collaboration) packages.
- Assumptions/dependencies: Real-time human tracking, formal safety guarantees, robust fall-prevention and recovery.
Academia
- Generalized motion editing with automatic keyframe discovery (robotics, machine learning, graphics)
- Learn where and how to edit keyframes automatically from task goals (constraints, targets), increasing scalability beyond manually defined edits.
- Tools/workflows: Keyframe discovery via sequence modeling, constraint learning, and meta-RL; integrated pipeline with auto-retargeting.
- Assumptions/dependencies: Reliable discovery of semantically meaningful frames; interpretable constraints; task-agnostic generalization.
- Unified controllers for interactive, contact-rich skills (robotics control)
- Extend adapters to handle haptics, contact transitions, and bi-directional environment feedback while preserving local motion patterns.
- Tools/products: Hybrid model-based/model-free controllers with adapter layers; curriculum learning across contact regimes.
- Assumptions/dependencies: Accurate contact models, improved reward shaping for contact events, high-bandwidth sensing.
- Motion libraries built from minimal curated clips (open-source standards)
- Community-driven repositories of single-clip skills with parameterized adapters and sparse edits, enabling broad adaptation without massive datasets.
- Tools/workflows: Standardized benchmarks, protocols for clip curation, retargeting metadata formats (SMPL-to-robot mappings).
- Assumptions/dependencies: Interoperability across robots; licensing for motion clips; consensus on evaluation metrics.
Daily Life
- Household assistance with adaptive routines from one demonstration (consumer robotics)
- Teach a robot a cleaning, tidying, or exercise routine once, and let it adapt to varying home layouts and user preferences.
- Tools/products: Consumer “Teach-by-Showing” apps, spatial editing via AR markers; adapter profiles for safety and energy use.
- Assumptions/dependencies: Perception of clutter and humans, compliance for contacts, robust fall avoidance; user-friendly keyframe editing.
- Personalized rehabilitation coaching and assisted exercise (healthcare)
- Adapt exercise motions to patient-specific ranges and progression plans, preserving therapeutic motion patterns from clinician demo.
- Tools/workflows: Clinical motion templates with adjustable adapters, compliance control, outcomes monitoring.
- Assumptions/dependencies: Medical device safety and regulation, precise contact/assistance control, clinician oversight.
Policy
- Safety certification for adaptive controllers (regulation, standards)
- Develop test suites and conformance criteria for adapter-based time warping and sparse keyframe tracking in public and workplace settings.
- Tools/products: Standardized validation protocols (success rate, tracking error, smoothness, fail-safe behavior), scenario libraries with parameter ranges.
- Assumptions/dependencies: Agreement on acceptable risk envelopes, transparent controller introspection, event logging.
- Governance for teach-by-video robot skills (privacy, IP, data rights)
- Establish policies for sourcing single reference clips (ownership, consent), retargeting transformations, and derivative motion rights.
- Tools/workflows: Consent capture in teach-by-showing apps, traceability from video to deployed motion, rights management layers.
- Assumptions/dependencies: Clear IP frameworks for motion derivatives, robust compliance tracking.
Cross-cutting Tools and Products (enabling multiple sectors)
- OmniH2O Studio (end-to-end pipeline)
- A productized suite that bundles video-to-SMPL conversion, robot retargeting, sparse keyframe editing, Stage-1 tracking, Stage-2 adapters, and deployment.
- Assumptions/dependencies: Modularity to support different robots; integration with simulators (Isaac Gym, Mujoco); hardware safety layers.
- Adapter-augmented controller libraries
- Reusable modules for phase adaptation (time warping) and tracking action compensation, compatible with PPO/SAC and PD control stacks.
- Assumptions/dependencies: Well-documented APIs; reward template packs (sparse global + dense local); portable observation models.
- Physically plausible motion editing plug-ins
- RL-backed in-between frame generation from sparse keyframes for animation tools (e.g., Blender, Unity), bridging graphics and robotics.
- Assumptions/dependencies: Stable sim interfaces; retargeting fidelity; optional export to real robot controllers.
Key Assumptions and Dependencies (affecting feasibility across applications)
- Single-clip adaptability works best for tasks with clear parametric edits (distance, height, displacement) and limited environmental interaction.
- Reliable retargeting from human video (GVHMR → SMPL) to robot kinematics, with morphology close enough to human motions.
- PD controller tuning, reward design (sparse global + dense local), and separate critics are critical for smooth and accurate tracking.
- Hardware needs stable localization (e.g., lidar odometry), appropriate joint locking for safety, and sufficient control frequency.
- Interactive and contact-rich tasks will require adding perception, compliance/contact controllers, and safety certification.
- Intellectual property and privacy considerations for source videos must be addressed before deployment.
Glossary
- Adversarial Motion Priors (AMP): A reinforcement learning approach that uses motion data as a prior via a discriminator, often as a style constraint to encourage naturalistic behaviors. "Adversarial motion priors (AMP-Style;~\cite{peng2021amp}), which use motions as a style regularizer combined with sparse keyframe tracking as the task reward."
- DeepMimic: A motion-tracking RL framework that learns to imitate reference motions with per-frame tracking rewards. "Motion tracking from target data: DeepMimic~\cite{peng2018deepmimic}, including (i) DeepMimic-NoAdapt, which tracks the original motion..."
- Degrees of Freedom (DoF): The number of independent joint variables that define a robot’s configuration. "We directly deploy the trained policies on the Unitree 29-DoFs G1 humanoid robot."
- Double critics: Using two value functions to separately estimate returns from different reward groups (e.g., sparse global and dense local). "fixed phase intervals and double critics for sparse global tracking and dense local tracking rewards"
- FastLIO: A lidar odometry algorithm for accurate real-time pose estimation. "Global localization is realized by lidar odometry through FastLIO~\cite{xu2021fast}."
- Goal-conditioned reinforcement learning: An RL formulation where the policy is conditioned on a goal (e.g., a reference motion state) to guide behavior. "We formulate humanoid motion tracking as a goal-conditioned reinforcement learning (RL) problem..."
- GVHMR: A method to reconstruct human motion videos into parametric body models (e.g., SMPL). "Human motions are reconstructed into SMPL motions via GVHMR~\cite{Shen2024WorldGroundedHM}..."
- Isaac Gym: A GPU-accelerated physics simulation platform for large-scale parallel RL training. "Training is conducted in the Isaac Gym simulator~\cite{makoviychuk2021isaac}..."
- Keyframe: A selected, semantically important pose or time in a motion sequence used to anchor and guide tracking or editing. "Sparse keyframes are then selected and edited to form an augmented dataset for adaptive tracking."
- Keyframing: The process of selecting and using sparse, important frames to structure motion editing or tracking. "we also adopt a keyframe-based editing scheme to preserve the global motion structure"
- L2C2 regularization: A regularization approach to improve stability and safety for sim-to-real deployment. "we adopt L2C2 regularization~\cite{Kobayashi2022L2C2LL,huang2025learning}."
- Lidar odometry: Estimating the robot’s position and orientation over time using lidar measurements. "Global localization is realized by lidar odometry through FastLIO~\cite{xu2021fast}."
- Markov decision process (MDP): A mathematical framework for sequential decision making with states, actions, transition dynamics, and rewards. "within the framework of a Markov decision process (MDP;~\cite{puterman2014markov})."
- MLP: A multilayer perceptron neural network used to parameterize policies and value functions. "Both the policy and value functions are parameterized as 3-layer MLPs."
- PD controller: A proportional-derivative controller that converts target joint positions to torques for low-level control. "The action is the target of a PD controller during a control period."
- Phase adapter: A learned module that modulates the phase interval to adjust motion timing (time warping) for adaptation. "This motivates our design of the phase adapter \phi \in [0,1]$ parameterizes the whole reference motion:" - **PPO**: Proximal Policy Optimization, a stable on-policy RL algorithm for training policies. "employing PPO~\cite{schulman2017proximal} as the RL algorithm." - **Retargeting**: Mapping motion from a source model (e.g., human SMPL) onto a target robot’s kinematics. "Human motions are reconstructed into SMPL motions via GVHMR~\cite{Shen2024WorldGroundedHM} and retargeted to the humanoid robot." - **Root frame**: The coordinate frame attached to the robot’s base/root, used for evaluating local motion errors. "averaged in the root frame over all timesteps to assess local accuracy." - **Sim-to-real transfer**: Techniques for deploying policies trained in simulation onto physical robots with minimal performance loss. "Approaches to these tasks often rely on sophisticated reward engineering and carefully designed sim-to-real transfer pipelines." - **SMPL**: A parametric 3D human body model widely used to represent and reconstruct human motion. "SMPL motions via GVHMR~\cite{Shen2024WorldGroundedHM}..." - **Sparse global reward**: A reward signal given only at selected keyframes to enforce global trajectory alignment without over-constraining motion. "we design a sparse global reward function:" - **Spacetime constraints**: Optimization-based motion editing constraints that enforce consistency across space and time. "motion editing, which can be achieved either through spacetime constraints~\cite{gleicher1997spacetime,witkin1995motion,Lee1999AHA,popovic1999physically}" - **Style regularizer**: A reward or discriminator that encourages generated motion to match the stylistic distribution of reference data. "which use motions as a style regularizer combined with sparse keyframe tracking as the task reward." - **Teleoperation**: Controlling a robot directly by a human operator, often to collect reference motions. "rely on teleoperation or pre-collected reference motions during deployment" - **Time warping**: Temporally re-parameterizing a motion to preserve natural pacing under spatial edits. "This two-stage design enables flexible time warping~\cite{witkin1995motion,hsu2007guided}, enhancing both imitation accuracy and adaptability." - **Trajectory-level consistency constraints**: Constraints ensuring interpolated frames remain coherent with edited keyframes across an entire trajectory. "interpolate the intermediate frames under trajectory-level consistency constraints~\cite{witkin1995motion,gleicher1997spacetime}" - **Tracking adapter**: A learned module that compensates low-level actions in response to phase adjustments to maintain accurate tracking. "we need a tracking adapter$ to compensate for the tracking action to track the next-step reference motion:"</li> <li><strong>UniTracker</strong>: A universal motion-tracking framework trained on large-scale datasets for generalization across motions. "UniTracker~\cite{Yin2025UniTrackerLU}, trained on large-scale motion datasets"</li> <li><strong>Unitree G1</strong>: A commercially available humanoid robot platform used for real-world deployment. "real-world Unitree G1 humanoid robot"</li> <li><strong>Value function</strong>: A function estimating expected return from a state, used to stabilize RL training and handle sparse rewards. "introduce a separate value function $V_\mathrm{track}^{\mathrm{sparse}$ to better estimate the return from such sparse rewards."
Collections
Sign up for free to add this paper to one or more collections.

