- The paper introduces a hybrid method that combines SMPL-X based 3D modeling with diffusion-driven video generation to generate pose-rich training data from a single image.
- The paper demonstrates that balanced sampling and geometry-weighted optimization significantly enhance identity preservation and rendering sharpness across diverse poses.
- The paper reports real-time rendering at 25.56 FPS on RTX A6000, outperforming previous single-image methods in both quantitative metrics and user preference studies.
PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
Introduction and Motivation
The PERSONA framework addresses the challenge of constructing animatable, personalized 3D human avatars from a single image, with explicit modeling of pose-driven deformations. Existing 3D-based methods, such as those leveraging NeRF or 3D Gaussian Splatting (3DGS), provide strong identity preservation but are limited in their ability to model non-rigid, pose-dependent deformations due to the scarcity of pose-diverse training data. Conversely, diffusion-based generative models can synthesize pose-driven deformations from large-scale video data but suffer from poor identity consistency and entanglement between pose and identity. PERSONA proposes a hybrid approach, integrating the strengths of both paradigms to enable scalable, high-fidelity avatar creation from minimal input.
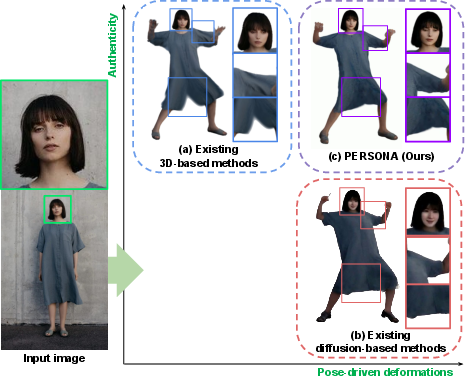
Figure 1: Comparison of (a) existing 3D-based method, (b) existing diffusion-based method, and (c) PERSONA, which integrates the strengths of both approaches.
Pipeline Overview
PERSONA's pipeline consists of three main stages: (1) pose-rich video generation from a single image using a diffusion-based animator, (2) hybrid 3D avatar representation and animation, and (3) optimization with balanced sampling and geometry-weighted loss.
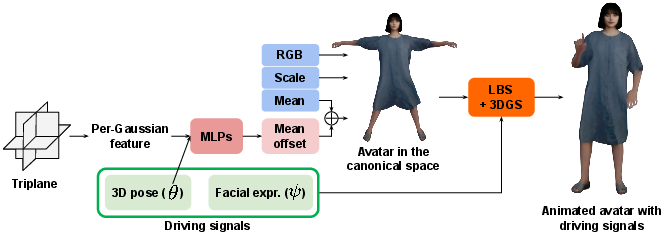
Figure 2: The pipeline of PERSONA. The mean offset from MLPs is used to represent pose-driven deformations.
Diffusion-Based Pose-Rich Video Generation
A diffusion-based human animation model (MimicMotion) generates synthetic videos depicting the subject in diverse poses, using the input image as the appearance reference and SMPL-X-derived 3D pose sequences as motion drivers. This process provides the necessary pose and deformation diversity for downstream avatar optimization, circumventing the need for subject-specific, pose-rich video capture.
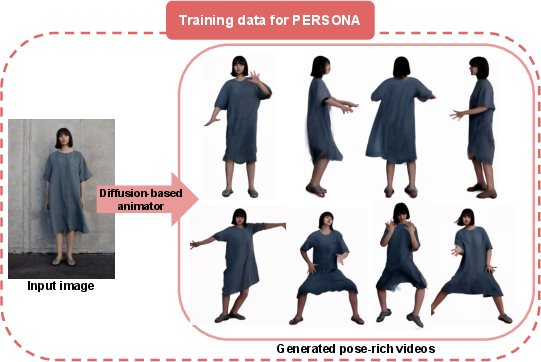
Figure 3: A diffusion-based animator generates pose-rich training videos from a single image.
Hybrid 3D Avatar Representation
PERSONA employs a hybrid representation combining SMPL-X parametric mesh and 3D Gaussian Splatting. Each SMPL-X mesh vertex is associated with a 3D Gaussian, and pose-driven deformations are modeled as mean offsets predicted by MLPs conditioned on local pose features. Animation is performed via linear blend skinning (LBS), and rendering utilizes Mip-Splatting for efficient, high-quality synthesis.
Core Technical Contributions
Balanced Sampling for Identity Preservation
Diffusion-generated frames often exhibit identity drift and inconsistent textures. PERSONA introduces a balanced sampling strategy during optimization, oversampling the input image relative to generated frames. This mitigates identity shifts and ensures that the avatar's appearance remains faithful to the subject, especially in critical regions such as the face.
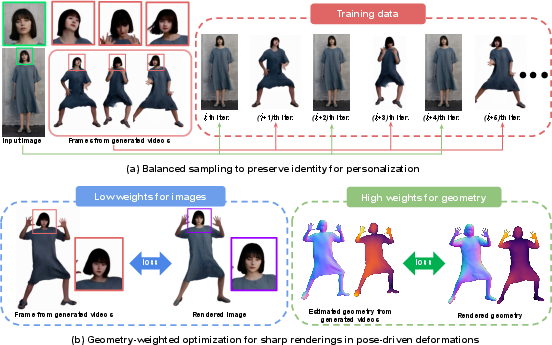
Figure 4: Two core components of PERSONA: balanced sampling for identity preservation and geometry-weighted optimization for sharp renderings in pose-driven deformations.
To further reduce baked-in artifacts (e.g., shadows, seam artifacts), PERSONA detects seam boundaries in the canonical space using Sobel-filtered positional maps, allowing for targeted regularization of problematic regions.
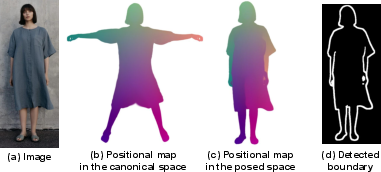
Figure 5: Seam boundary detection from positional maps, enabling artifact mitigation at body part boundaries.
Directly optimizing on diffusion-generated frames can degrade rendering quality due to texture inconsistencies. PERSONA addresses this by prioritizing geometry-based losses (binary masks, depth, normals, part segmentations) over image-based losses when updating the pose-driven deformation MLPs. This ensures that the learned deformations are physically plausible and robust to generative artifacts, resulting in sharper, more consistent renderings across diverse poses.
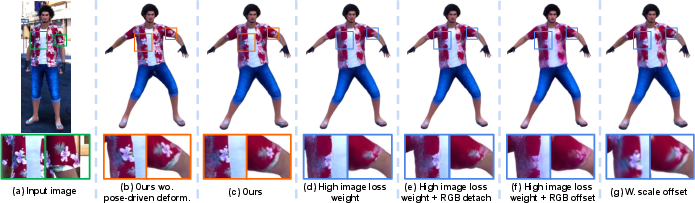
Figure 6: Comparison of various pose-driven deformation modeling strategies. Geometry-weighted optimization is essential for maintaining authentic and sharp renderings.
Pose-driven deformations are modeled exclusively via mean offsets to the Gaussians, avoiding scale or RGB offsets. This design choice preserves texture sharpness and prevents blurring, as only the spatial positions of Gaussians are modulated in response to pose changes.
Experimental Results
Quantitative and Qualitative Evaluation
PERSONA is evaluated on NeuMan and X-Humans datasets, using PSNR, SSIM, and LPIPS as metrics. It consistently outperforms all single-image-based baselines, including both 3D- and diffusion-based methods, in terms of rendering quality and identity preservation.

Figure 7: Effectiveness of balanced sampling. Without it, the avatar loses the identity of the input image.
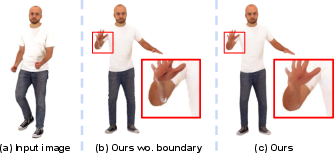
Figure 8: Effectiveness of detected boundary in balanced sampling. Without it, color leakage between body parts leads to artifacts.
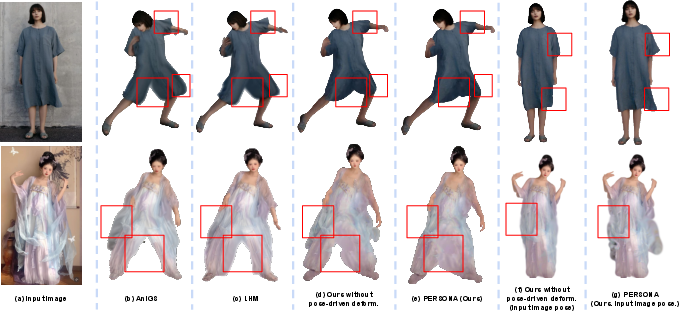
Figure 9: Effectiveness of pose-driven deformations. PERSONA mitigates baked-in artifacts and enables natural, pose-dependent deformations.

Figure 10: Comparison of diffusion-based state-of-the-art methods and PERSONA.
User studies further confirm a strong preference for PERSONA's outputs over prior methods, particularly in terms of identity consistency and naturalness of deformations.
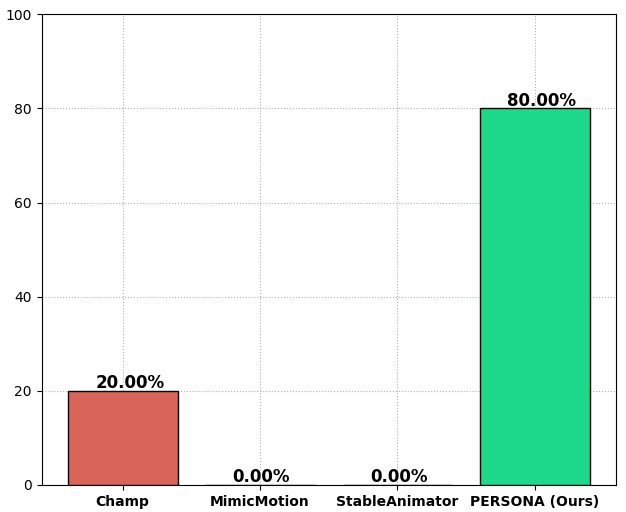
Figure 11: User preference study results from 40 participants.
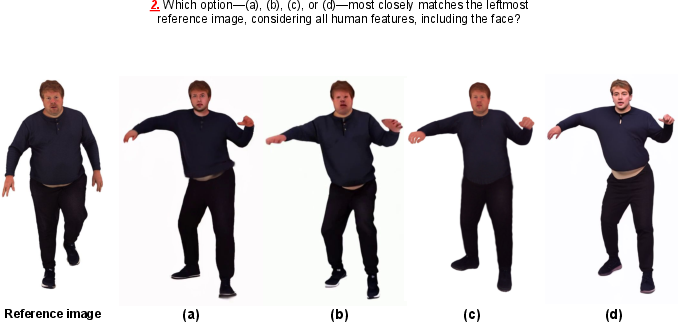
Figure 12: An example of the user study interface.
Real-Time Rendering
PERSONA achieves real-time rendering speeds (25.56 FPS on RTX A6000), a significant advantage over diffusion-based video synthesis methods, which are orders of magnitude slower.
Ablation Studies
Ablations demonstrate the necessity of both balanced sampling and geometry-weighted optimization. Removing either component leads to identity loss, blurring, or artifact propagation. The use of mean offsets alone for deformation is validated as optimal for maintaining sharpness.
Limitations
PERSONA inherits several limitations from its reliance on diffusion-generated training data:
Implications and Future Directions
PERSONA demonstrates that hybridizing 3D-based and diffusion-based paradigms enables scalable, high-fidelity avatar creation from minimal input. The framework's modularity allows for future integration of more advanced generative models, improved geometry estimators, and explicit garment/hair layers to address current limitations. The real-time rendering capability positions PERSONA as a practical solution for interactive applications in virtual reality, telepresence, and digital content creation.
Potential future research directions include:
- Incorporating motion-dependent deformation layers for garments and hair.
- Leveraging more consistent, 3D-aware generative models for training data synthesis.
- Extending the framework to support relighting and material editing.
- Optimizing the data generation pipeline for reduced preprocessing time.
Conclusion
PERSONA introduces a principled, scalable approach for constructing personalized, animatable 3D avatars with explicit pose-driven deformations from a single image. By integrating balanced sampling and geometry-weighted optimization, PERSONA achieves superior identity preservation and rendering quality compared to prior single-image methods, while enabling real-time performance. The framework sets a new standard for practical, high-fidelity avatar creation and opens avenues for further research in hybrid generative modeling and human-centric 3D synthesis.
