Decomposing Theory of Mind: How Emotional Processing Mediates ToM Abilities in LLMs
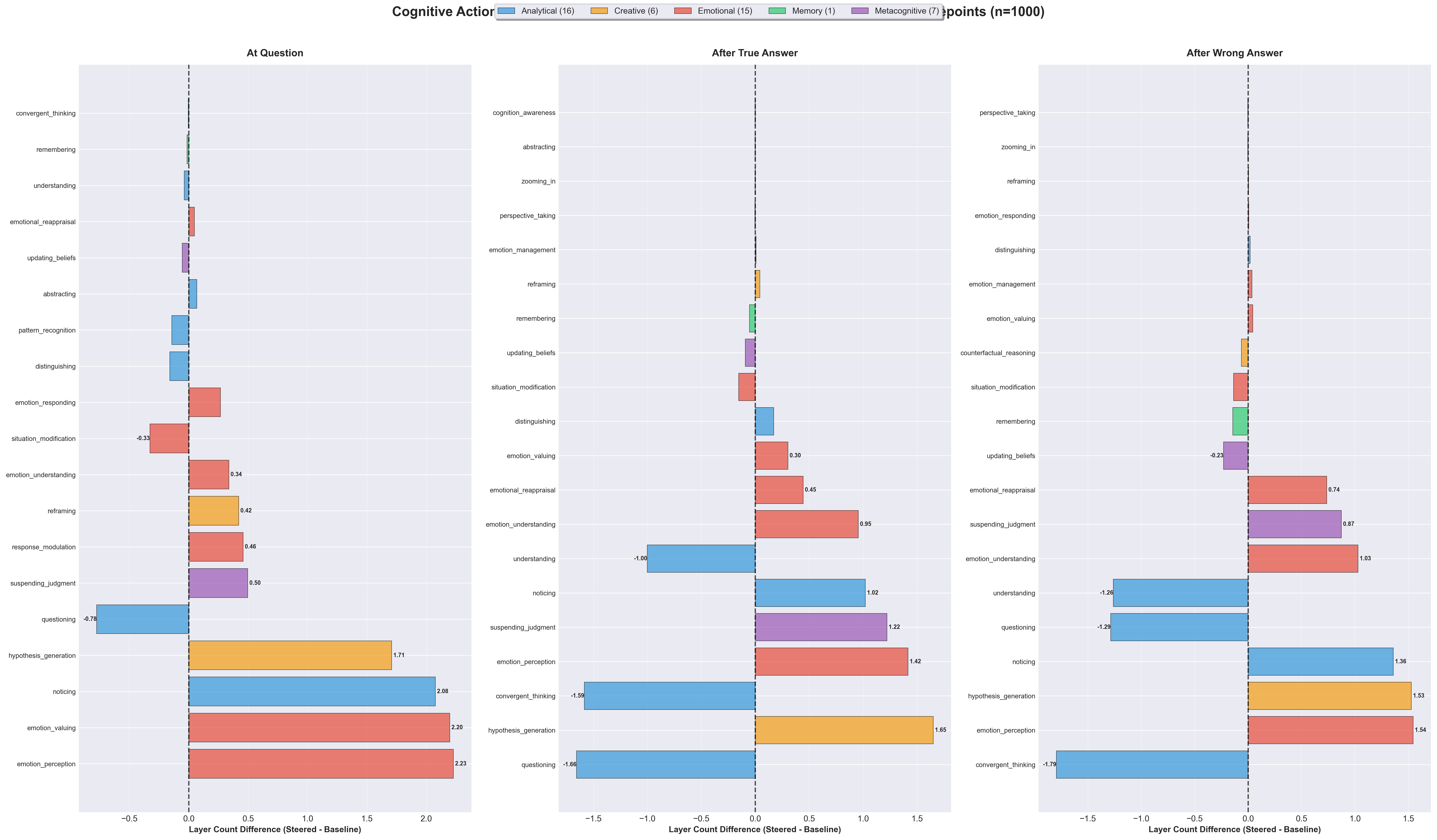
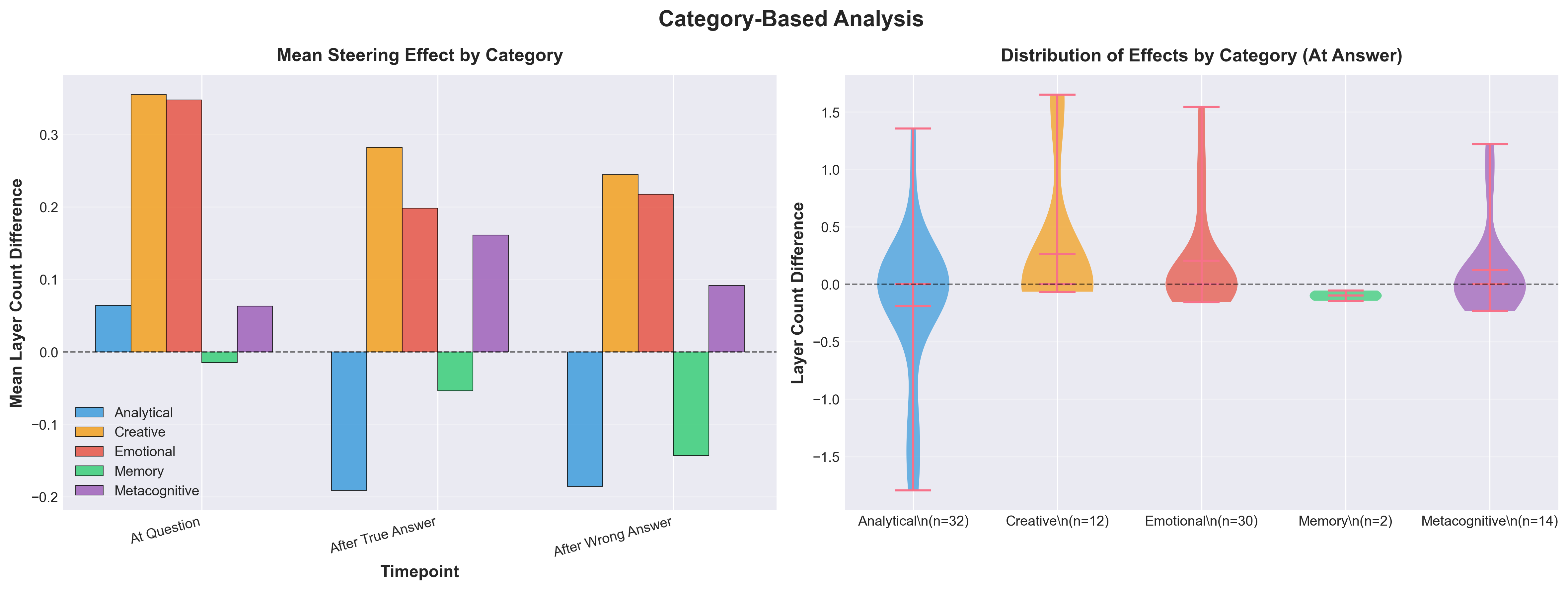
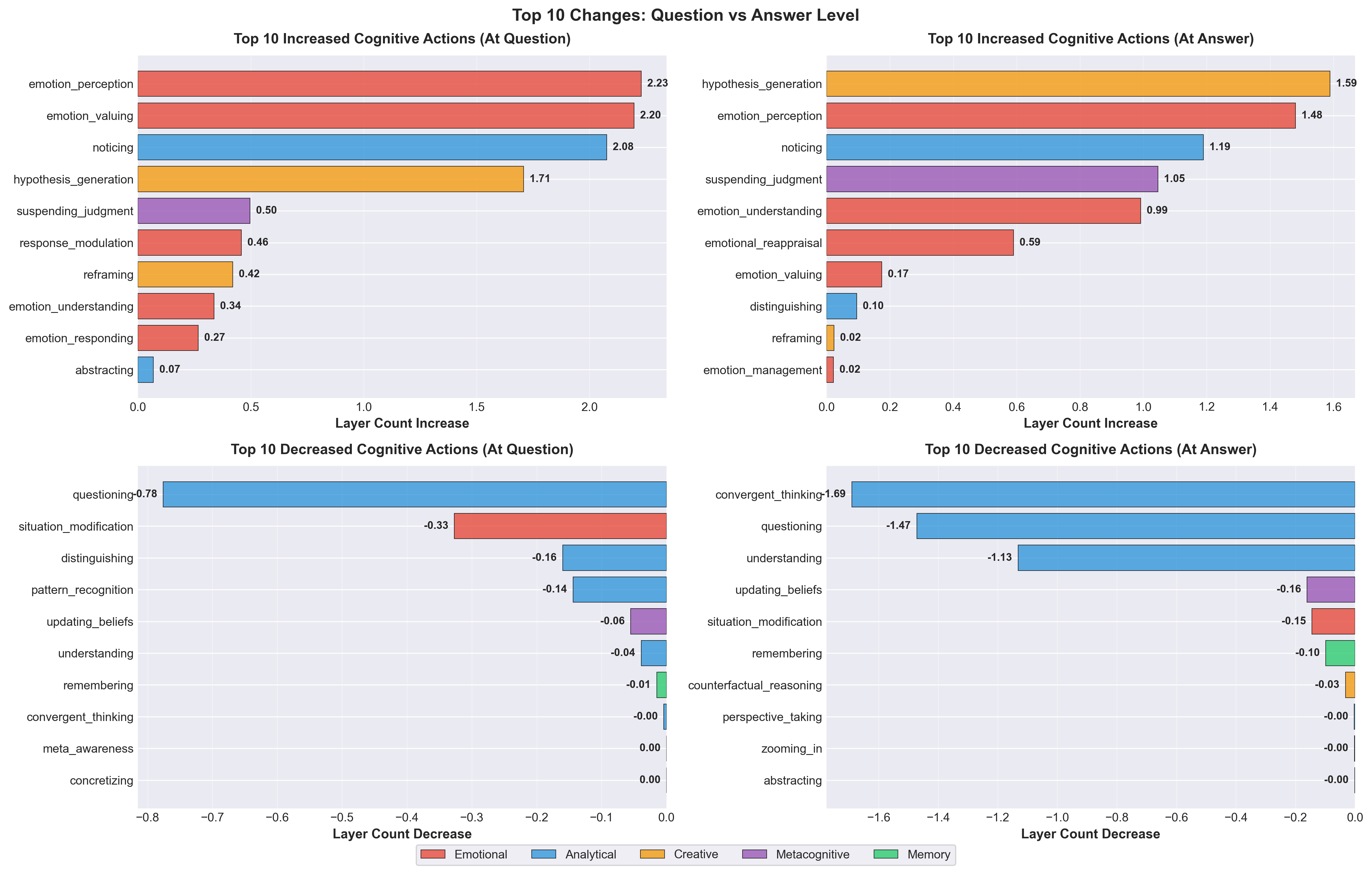
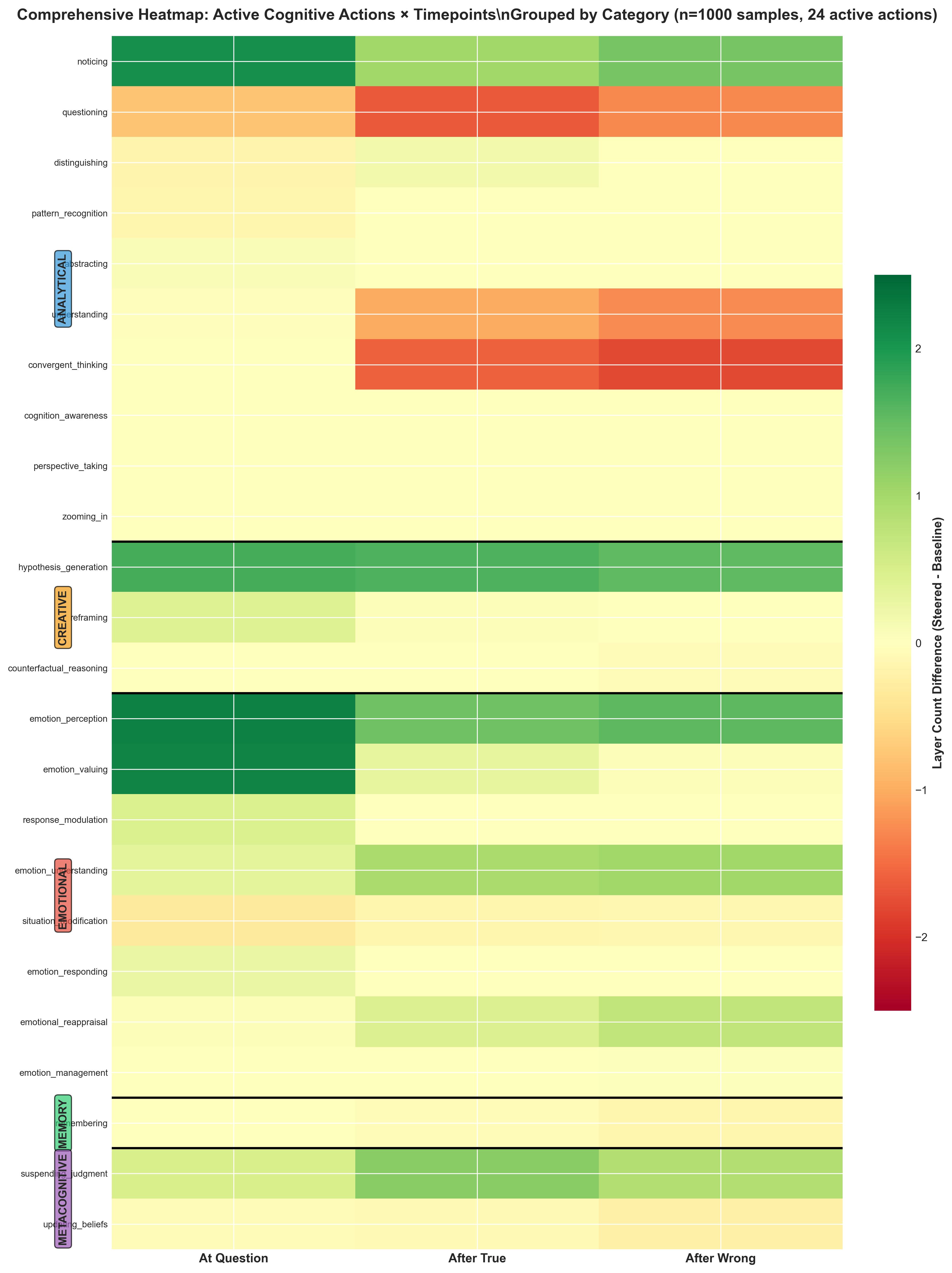
Abstract: Recent work shows activation steering substantially improves LLMs' Theory of Mind (ToM) (Bortoletto et al. 2024), yet the mechanisms of what changes occur internally that leads to different outputs remains unclear. We propose decomposing ToM in LLMs by comparing steered versus baseline LLMs' activations using linear probes trained on 45 cognitive actions. We applied Contrastive Activation Addition (CAA) steering to Gemma-3-4B and evaluated it on 1,000 BigToM forward belief scenarios (Gandhi et al. 2023), we find improved performance on belief attribution tasks (32.5\% to 46.7\% accuracy) is mediated by activations processing emotional content : emotion perception (+2.23), emotion valuing (+2.20), while suppressing analytical processes: questioning (-0.78), convergent thinking (-1.59). This suggests that successful ToM abilities in LLMs are mediated by emotional understanding, not analytical reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to help an AI better understand what other people think and believe—something called “Theory of Mind” (ToM). The authors don’t just measure whether the AI gets ToM questions right; they try to peek inside the AI to see which kinds of thinking become stronger or weaker when the AI does better. Their big takeaway: when the AI improves at ToM, it seems to rely more on emotional understanding and less on pure step-by-step analytical reasoning.
What questions did the researchers ask?
The paper focuses on three simple questions:
- If we use a known technique to boost an AI’s ToM, what changes inside the AI’s “thinking”?
- Do some types of mental processes—like noticing emotions—become more active when the AI gets ToM questions right?
- Are more logical, puzzle-solving processes actually less active when the AI succeeds at perspective-taking?
How did they do the research?
Think of a LLM like Gemma-3-4B as a huge text-predicting machine with many layers that process words step by step—like pages in a notebook where each page adds more detail.
The team used two main tools:
- “Activation steering” (Contrastive Activation Addition, or CAA)
- Analogy: Imagine turning a knob inside the AI to push it toward answers that match correct perspective-taking and away from answers that match incorrect perspective-taking.
- They trained this “steering knob” using pairs of examples where one answer shows good ToM (understanding what someone believes) and the other shows poor ToM.
- “Probes” to read internal signals for 45 cognitive actions
- Analogy: A probe is like a detector that lights up when a certain type of thinking is active—such as “questioning,” “hypothesis generation,” or “emotion perception.”
- They created short, first-person stories that strongly show one specific mental action (like “I realized my friend was sad from their tone”). Then they trained simple detectors to recognize those actions in the AI’s internal activity.
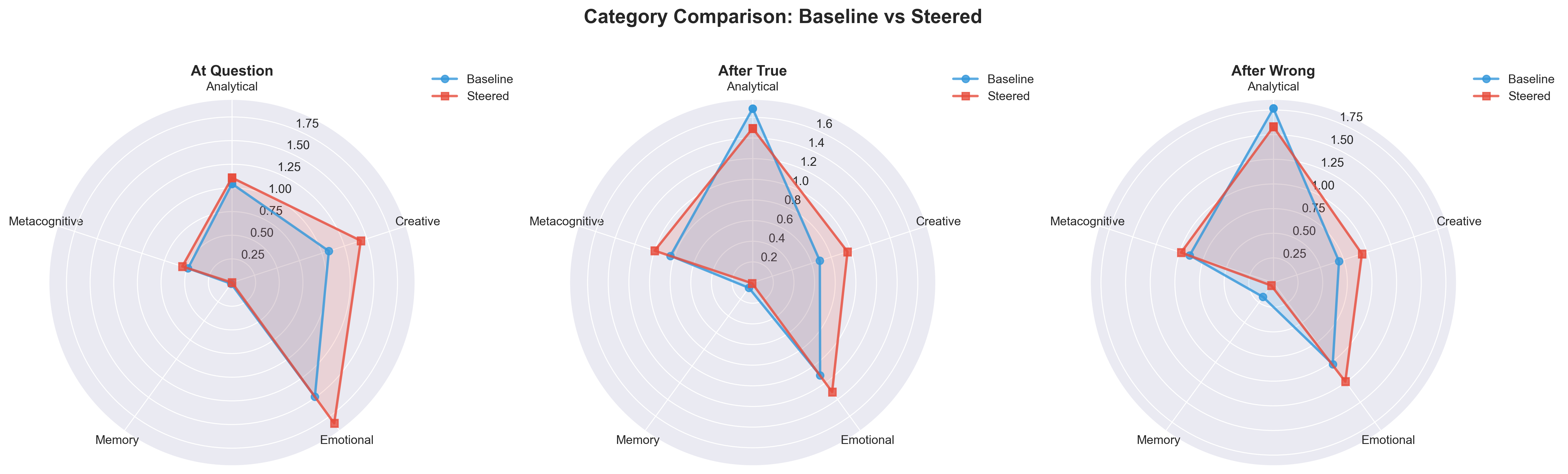
- These detectors were applied to the AI at different layers (like checking different pages in the notebook) and at different moments (at the question, after a correct answer, after a wrong answer).
Testing the AI
- The model answered 1,000 “false-belief” questions (like classic ToM tests: a person believes something that isn’t true because they didn’t see what happened).
- The questions were multiple-choice. Instead of letting the model write anything it wanted, the researchers looked at which choice the model was more likely to pick based on its internal probabilities.
- They compared performance before and after using CAA and checked which “thinking detectors” lit up more or less.
What did they find, and why does it matter?
Here are the main results in plain terms:
- The steering technique made the AI better at ToM. Accuracy rose from 32.5% to 46.7%, meaning the model got 217 more questions right out of 1,000.
- When the AI did better, its “emotional” thinking became more active. Detectors for things like emotion perception (spotting feelings) and emotion valuing (recognizing the importance of feelings) lit up more.
- At the same time, some classic “analytical” thinking decreased. Detectors for questioning, convergent thinking (picking one best answer), and general “understanding” were less active.
- Creative/generative thinking (like hypothesis generation—coming up with possible explanations) also increased.
Why this matters:
- Many people assume that better social reasoning in AI comes from more careful step-by-step logic. But here, success was linked to stronger emotional and generative processing and weaker hard analytic checking.
- This suggests that for perspective-taking, tuning the AI to “feel” the situation—recognize emotions and imagine explanations—may be more helpful than pushing it to do strict logical analysis.
What does this mean for the future?
- Building better social AI: If we want AI that understands people’s beliefs and feelings, we may need to strengthen its emotional and generative representations—not just its logical reasoning.
- Understanding AI “thinking”: Using probes plus steering gives a way to break down complex skills (like ToM) into parts and see which parts actually drive success.
- Limits: The authors don’t claim this is how human brains work. They just show what changes inside one AI model when it gets better at ToM. Future work should test more models and more types of tasks.
- Big picture: Perspective-taking in AI might be more about tuning the model to recognize emotional context and imagine possible beliefs than making it do longer chains of logic. This could guide how we train and evaluate social reasoning in AI going forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Probe training data is entirely synthetic and generated by the same model (Gemma-3-4B), risking circularity and model-specific biases; validate probes with human-annotated corpora and out-of-model data sources.
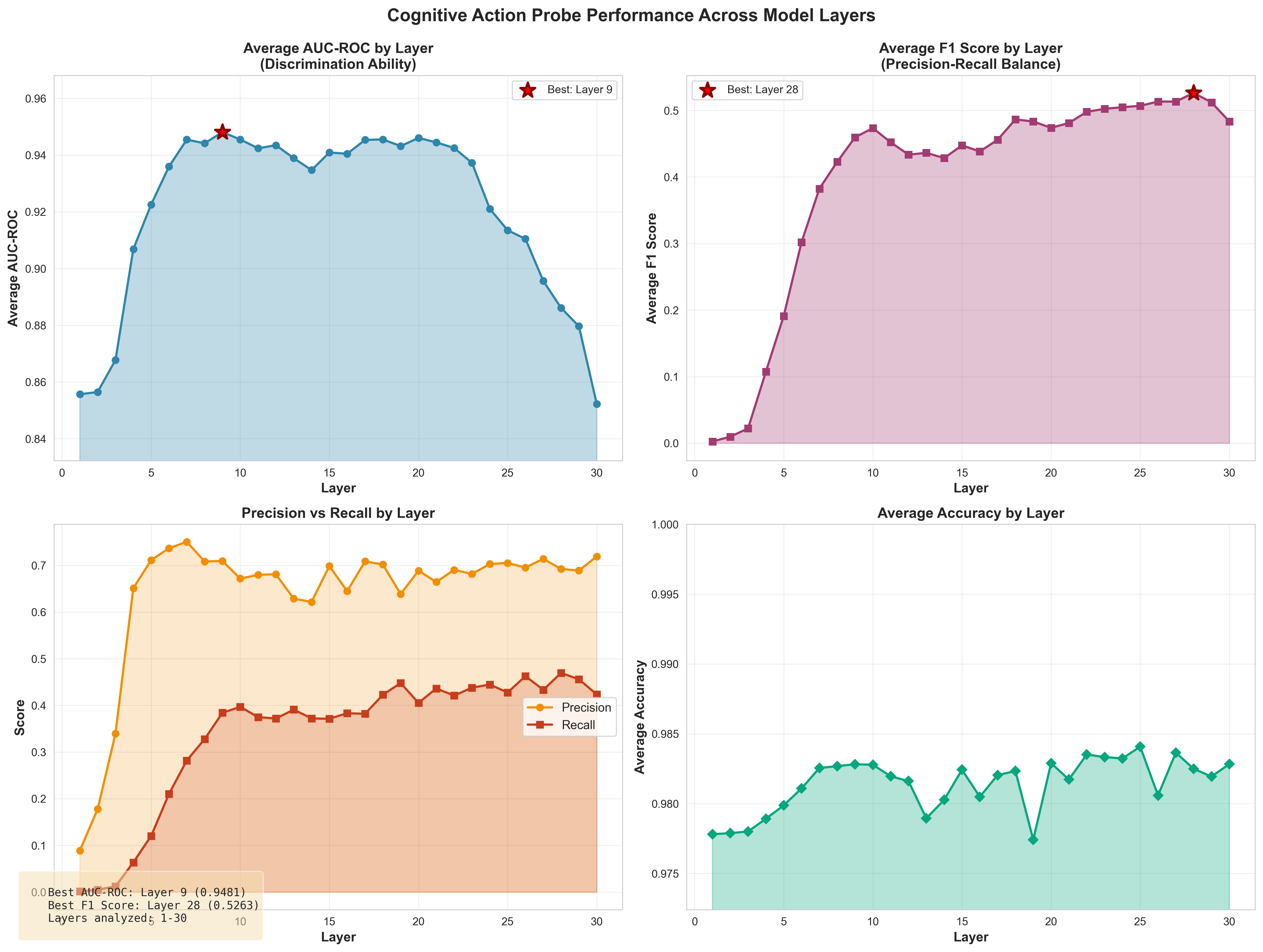
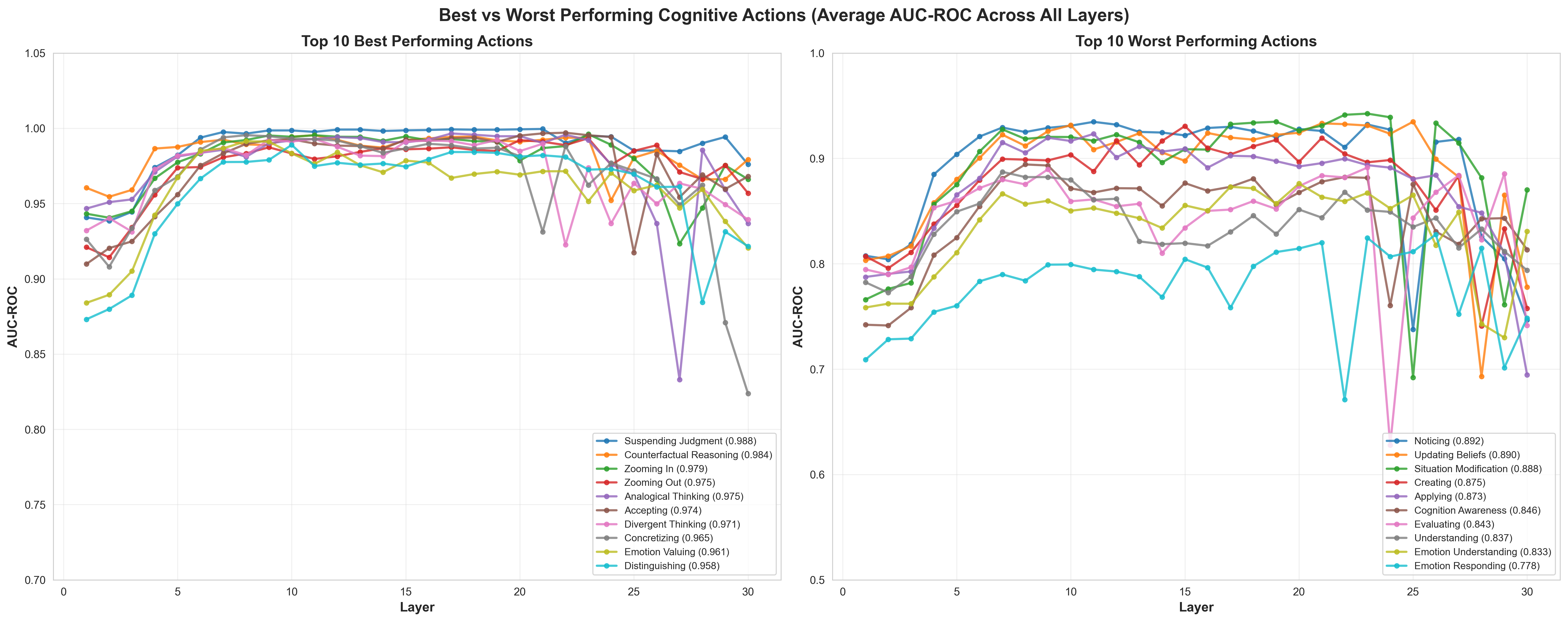
- Linear probes achieve modest average performance (AUC-ROC ≈ 0.78); assess robustness with stronger methods (e.g., non-linear probes, causal tracing, sparse autoencoders) and include sanity checks (random labels, control features).
- The fixed suffix and final-token extraction strategy may alter representations; test whether findings persist with native inputs, multi-token probing, and alternative extraction positions.
- “Layer count” as the primary metric for action presence is underdefined (thresholding criteria not specified) and hard to interpret; compare against calibrated continuous scores, effect sizes, and attribution-based measures.
- No statistical significance or uncertainty quantification for reported differences; report confidence intervals, p-values, and variance across random seeds and probe initializations.
- Steering vectors trained on only 752 triplets may be underpowered and dataset-specific; expand training sets, ensure strict disjointness from evaluation items, and test for overfitting/leakage.
- Generalization beyond a single model (Gemma-3-4B) is untested; replicate across architectures (decoder-only vs. encoder-decoder), sizes, and training regimes (pretrain-only vs. RLHF).
- Evaluation scope is narrow (forward belief “false” condition, binary letter selection); extend to full BigToM suite (true beliefs, second-order beliefs, deception), other ToM benchmarks, and free-form generation settings.
- The central conclusion that emotional processing mediates ToM is correlational; perform causal interventions (ablate/amplify emotion-related features) and mediation analyses to test necessity and sufficiency.
- Probes may pick up emotional lexicon rather than latent emotional representations; include lexical controls, counterbalanced stimuli, and adversarial examples to disentangle semantics from surface cues.
- Only CAA steering is examined; compare against alternative interventions (prompting, supervised fine-tuning, other representation engineering methods) to test whether the same cognitive shifts occur.
- Off-target impacts of steering on other capabilities are unmeasured; quantify trade-offs on analytical reasoning, calibration, mathematical tasks, and safety-relevant behaviors.
- Sensitivity to steering hyperparameters (vector magnitude, targeted layers, injection points) is not explored; perform systematic sweeps to map the parameter-performance surface.
- Instance-level links between probe outputs and correctness are not analyzed; compute per-example mediation, partial correlations, and causal path models to determine which actions predict success.
- Results for the “perspective_taking” probe (included in the taxonomy) are not reported; analyze whether changes in this probe directly track accuracy and steering effects.
- Dataset artifacts and shortcut learning risks are unaddressed; profile the 217 improved items to see whether gains cluster in emotionally salient stories or exploit spurious cues.
- Memory and metacognitive dimensions are underrepresented (single “remembering” action; limited reporting on metacognition); expand taxonomy (e.g., working memory, attentional control, planning) and evaluate their roles.
- Temporal dynamics are coarse (three timepoints only); analyze token-level trajectories and attention patterns to capture richer sequencing of cognitive actions during inference.
- Cross-lingual generalization remains unknown; evaluate on non-English ToM datasets to test whether observed patterns depend on English training distributions.
- Reproducibility is limited (artifacts omitted for review); release code, probe weights, steering vectors, prompts, and hyperparameters to enable independent verification.
- Calibration of probability-based answer selection is not examined; test robustness to temperature, logit scaling, option formatting, and positional biases beyond randomization.
- No human baselines or inter-rater comparisons are provided; situate model gains relative to human performance on the same items to contextualize effect magnitude.
- Construct validity of the cognitive-action taxonomy is assumed; conduct convergent/discriminant validity tests and factor analyses to confirm that probes track intended constructs in LLMs.
- Peak probe performance is reported at layer 9, yet analysis focuses on layers 10–20; justify layer selection and test whether conclusions depend on layer window choice.
- Necessity vs. correlation of increased emotional/generative signals is unresolved; design counterfactual steering that increases analytical processes and compare ToM outcomes.
- Safety and ethical implications of amplifying “emotional” processing in LLMs are not discussed; assess risks of anthropomorphism, persuasion/manipulation, and miscalibrated socio-emotional behavior.
Practical Applications
Immediate Applications
Below are actionable, near-term uses that can be built with existing open-weight models and current activation-steering toolchains.
- Empathy-mode customer support and sales assistants
- Sectors: software, customer service, retail, finance (collections), telecom
- Tools/workflows: add a Contrastive Activation Addition (CAA) “empathy vector” at inference to increase emotion_perception/valuing during sensitive conversations; expose an “Empathy slider” in the chat UI; monitor cognitive action probes in layers ~10–20 to verify the agent is in the intended regime
- Assumptions/dependencies: access to model activations (open weights or API that allows activation additions), acceptance that reduced analytical interrogation may trade off with strict task accuracy; careful prompt routing so “empathy mode” is used only where appropriate
- Triage and de-escalation bots for grievance handling
- Sectors: government services, healthcare intake, insurance claims, HR
- Tools/workflows: deploy a steered small LLM for first-response triage that prioritizes emotional understanding before escalating to a more analytical agent; use probes as real-time guards to ensure emotional processes are active during intake
- Assumptions/dependencies: ethical policies for vulnerable populations; human-in-the-loop escalation; steer strength must be calibrated to avoid suppressing factual checks
- Emotion-aware educational tutors and feedback generators
- Sectors: education, edtech
- Tools/workflows: enable steering when providing formative feedback to students; probes verify presence of hypothesis_generation and emotion_understanding; route to analytical mode for grading or proof checking
- Assumptions/dependencies: task routing between “emotional” and “analytical” modes; content safety filters; student privacy
- Writing assistants that adapt tone and perspective
- Sectors: productivity software, enterprise collaboration
- Tools/workflows: “Consider-the-reader” rewrite feature that boosts perspective_taking and emotion_perception; cognitive probes supply a dashboard view to authors showing which cognitive actions dominated the draft
- Assumptions/dependencies: user consent for tone-shaping; integration with office suites; quality guardrails to prevent loss of factual precision
- Model evaluation dashboards for social reasoning
- Sectors: AI research, MLOps, model governance
- Tools/workflows: integrate the paper’s 45 cognitive-action probes into observability to track shifts induced by prompts, system messages, or guardrails; correlate probe readouts with ToM benchmark performance (e.g., BigToM)
- Assumptions/dependencies: probe generalization beyond Gemma-3-4B; internal activation access; acceptance that probes are correlational (AUC-ROC ~0.78)
- Safer conversational UX via context-aware steering
- Sectors: consumer apps, healthcare information, mental health support (non-diagnostic)
- Tools/workflows: automatically enable empathy steering for high-affect contexts detected via probes; disable or reduce in tasks requiring exact calculation or legal advice
- Assumptions/dependencies: clear user disclosures; not a substitute for professional care; policy-based routing; adherence to safety guidelines
- Contact-center QA and coaching
- Sectors: BPOs, enterprise operations
- Tools/workflows: analyze call transcripts with probes to quantify presence of emotional vs analytical actions; coach agents on when to shift modes; simulate “better” responses by applying CAA to the same transcript
- Assumptions/dependencies: transcription quality; privacy and consent; domain adaptation of probes to spoken language
- Role-play and scenario simulators for soft-skills training
- Sectors: L&D, HR, sales enablement, healthcare bedside manner training
- Tools/workflows: steer bots toward affective ToM in role-play; use probe readouts to score and explain why a response exhibited good perspective-taking (emotion_perception up, questioning down)
- Assumptions/dependencies: content review for bias; multi-turn stability of steering; evaluation beyond synthetic benchmarks
- Product research and UX testing with empathic agents
- Sectors: consumer research, design
- Tools/workflows: run steered agents to explore customer perspectives; compare outputs with and without steering to surface emotionally salient pain points
- Assumptions/dependencies: representativeness of model’s learned affective priors; triangulation with real user data
- Governance checklists and procurement addenda
- Sectors: public-sector IT, enterprise AI procurement
- Tools/workflows: require vendors to report ToM-relevant probe metrics and steering controls; verify that empathy modes can be toggled, logged, and audited
- Assumptions/dependencies: buyers able to demand activation-level transparency; standardized reporting templates
Long-Term Applications
These opportunities likely require further validation, scaling, cross-model replication, or new APIs that expose internal states safely.
- Context-adaptive “cognitive control layer” for agents
- Sectors: software platforms, multi-agent systems
- Tools/products: middleware that dynamically steers between affective and analytical regimes per task segment; policy engines that bind business rules to cognitive-action targets
- Dependencies: robust, model-agnostic steering APIs; stability across long contexts; meta-controllers that prevent mode oscillation
- Socially adept robotics for care and companionship
- Sectors: healthcare, eldercare, consumer robotics
- Tools/products: onboard LLMs with affective steering for human-robot interaction; probe-based monitors to prevent overfitting to theatrics while maintaining safety
- Dependencies: on-device inference and activation access; certification for safety-critical settings; longitudinal evaluation with humans
- Clinical communication support (not diagnosis)
- Sectors: healthcare
- Tools/products: assistants that draft patient messages or visit summaries tuned for empathy; “bedside manner” simulators for clinician training
- Dependencies: stringent compliance (HIPAA/GDPR), bias audits, domain-tuned probes; evidence that steering doesn’t degrade medical accuracy; human oversight
- Negotiation and mediation copilots
- Sectors: law, HR, enterprise negotiations, diplomacy training
- Tools/products: multi-party assistants that track inferred beliefs and emotions; surface “belief maps” grounded in probe signals; apply CAA for tactful proposals
- Dependencies: validated ToM beyond simple benchmarks; safeguards against manipulation; explainability requirements
- Standardized audits and certifications for affective-ToM claims
- Sectors: policy, standards bodies, insurers
- Tools/products: certification regimes requiring decomposition metrics (probe profiles, steering effects, task trade-offs) before deployment in sensitive contexts
- Dependencies: consensus test suites; independent labs; legal frameworks for disclosure
- Training-time representation shaping for social reasoning
- Sectors: AI model development
- Tools/products: pretraining or finetuning with loss terms that encourage disentangled affective vs analytical circuits; joint training with probe feedback
- Dependencies: scalable training-time interpretability; evidence that such shaping improves generalization without spurious correlations
- Early warning systems for manipulative or deceptive behavior
- Sectors: platform safety, trust & safety
- Tools/products: probe-driven monitors that flag patterns of undue emotional leverage or suppressed analytical scrutiny; automatic throttle or human review triggers
- Dependencies: validated mapping from probe signals to real-world harm; low false-positive rates; governance playbooks
- Emotion-aware RAG and retrieval policies
- Sectors: software, enterprise knowledge, customer success
- Tools/products: retrieval strategies that adapt to user affect (e.g., prioritize supportive guidance before dense technical detail); steer analytical mode back on for final answers
- Dependencies: orchestration frameworks that can read probe states; careful latency management; user testing at scale
- Social science and cognitive modeling at scale
- Sectors: academia
- Tools/products: use steered LLM agents in controlled simulations to test hypotheses about affective vs cognitive ToM interactions; generate synthetic data with annotated “cognitive action” trajectories
- Dependencies: cross-model replication; triangulation with human studies; norms for ethical use of synthetic social data
- Personal agents that learn user-specific empathy profiles
- Sectors: consumer AI, accessibility
- Tools/products: agents that tune steering strengths to individual preferences and contexts (e.g., direct vs supportive communication styles)
- Dependencies: privacy-preserving personalization; user controls and transparency; safeguards against behavioral manipulation
Cross-cutting assumptions and dependencies
- Technical access: most applications require access to intermediate activations (currently feasible with open-weight models or specialized APIs) and the ability to apply CAA during inference.
- Generalization: findings were demonstrated on Gemma-3-4B with BigToM forward-belief tasks; external validity to other models, languages, and richer social contexts must be established.
- Trade-offs: steering increased emotional processes while suppressing analytical ones; tasks demanding precision, compliance, or formal reasoning must incorporate mode routing or post-hoc verification.
- Measurement validity: linear probes (avg AUC-ROC ~0.78) provide correlational signals; they should be treated as indicators, not ground truth of “cognition.”
- Safety and ethics: emotional steering can increase persuasive power; require disclosures, opt-in, and guardrails, especially in healthcare, finance, and youth-facing products.
- Operational concerns: added latency and engineering complexity for hooking layers 10–20, calibration of steer strength, and continuous monitoring to manage distribution shift.
Glossary
- Activation patterns: Distributions of internal neuron activations across layers/tokens that reflect what the model is representing. "comparing steered versus baseline activation patterns could reveal which processes are essential for successful perspective-taking"
- Activation steering: Modulating a model’s internal activations to influence its outputs toward desired behaviors. "Recent work shows activation steering substantially improves LLMs' Theory of Mind (ToM) \cite{Bortoletto2024}"
- AdamW: An optimizer with decoupled weight decay commonly used for training deep neural networks. "with AdamW optimization, cosine annealing, and early stopping based on AUC-ROC."
- Answer position randomization: Randomizing the order of answer options to prevent positional biases in evaluation. "Answer position randomization ensures that the model cannot exploit systematic biases in option ordering."
- Answer ranking by probability: Selecting an answer based on predicted probabilities rather than generating text. "Following the BigToM evaluation protocol, we used answer ranking by probability rather than free-form text generation."
- AUC-ROC: Area under the Receiver Operating Characteristic curve; a metric for binary classifier performance. "binary probes achieved 0.78 average AUC-ROC and 0.68 F1 across 45 actions."
- Belief attribution tasks: Tasks requiring inference of an agent’s beliefs from context. "we find improved performance on belief attribution tasks (32.5\% to 46.7\% accuracy)"
- BigToM: A benchmark dataset for evaluating Theory of Mind in LLMs. "evaluated it on 1,000 BigToM forward belief scenarios \cite{gandhi2023understanding}"
- Contrastive Activation Addition (CAA): A steering method that adds contrastive activation differences to shift model representations toward desired outcomes. "activation steering techniques, particularly Contrastive Activation Addition (CAA), can substantially improve LLMs' ToM performance on belief attribution tasks"
- Cosine annealing: A learning rate schedule that decays according to a cosine function. "with AdamW optimization, cosine annealing, and early stopping based on AUC-ROC."
- Early stopping: Halting training when a validation metric stops improving to avoid overfitting. "with AdamW optimization, cosine annealing, and early stopping based on AUC-ROC."
- Final token position: The last token index used to read off probabilities/logits for classification. "from model logits at the final token position"
- Final-token extraction: Reading activations at the final token to evaluate or probe a representation. "for consistent final-token extraction."
- Forward belief scenarios: ToM tasks where the correct belief tracks the forward (true) state of the world. "We evaluated 1,000 forward belief scenarios from BigToM \cite{gandhi2023understanding} (forward_belief_false)"
- Gemma-3-4B: A 4-billion-parameter Gemma LLM used in experiments. "We applied Contrastive Activation Addition (CAA) steering to Gemma-3-4B"
- Layer count: The number of layers where a probe detects the presence of a target feature/action. "For each action, we computed layer count (layers 10-20 where probe confidence indicated presence)"
- Linear probes: Simple linear classifiers trained on model activations to detect the presence of specific features. "We trained 45 binary linear probes using one-vs-rest classification"
- Logits: Pre-softmax scores output by a model that can be converted to probabilities. "Answers were evaluated by computing p(correct) vs p(incorrect) from model logits."
- Mechanistic interpretability: Methods for understanding a model’s internal mechanisms and representations. "We introduce a decomposition approach using techniques from mechanistic interpretability in LLMs"
- Middle Temporal Gyrus (MTG): A brain region implicated in social cognition and language processing. "patterns in TPJ (Temporoparietal Junction) and MTG (Middle Temporal Gyrus) reflect the same neuronal activity, equally recruited in these two independent conditions."
- nnsight: A tool/library for extracting and inspecting neural network activations. "Activations were extracted from layers 0-30 of Gemma-3-4B using nnsight"
- One-vs-rest classification: A strategy where a separate binary classifier is trained for each class against all others. "We trained 45 binary linear probes using one-vs-rest classification"
- PCA-centered activation differences: Activation differences processed using Principal Component Analysis to center/structure steering vectors. "Vectors were trained across layers 14-30 using PCA-centered activation differences."
- Perspective-taking: Inferring or modeling another agent’s viewpoint or beliefs. "This raises a question:what cognitive processes change when models successfully engage in perspective-taking?"
- Probability-based ranking approach: Selecting answers by comparing their predicted probabilities instead of generating text. "This probability-based ranking approach eliminates confounds from text generation artifacts and provides a more reliable measure of the model's belief attribution capabilities."
- Steering vectors: Directional vectors added to internal activations to guide model behavior. "We investigate how steering vectors modulate cognitive processes during belief attribution tasks."
- Temporoparietal Junction (TPJ): A brain region associated with Theory of Mind and social cognition. "patterns in TPJ (Temporoparietal Junction) and MTG (Middle Temporal Gyrus) reflect the same neuronal activity, equally recruited in these two independent conditions."
- Theory of Mind (ToM): The ability to attribute mental states to oneself and others. "Recent work shows activation steering substantially improves LLMs' Theory of Mind (ToM) \cite{Bortoletto2024}"
Collections
Sign up for free to add this paper to one or more collections.

