- The paper introduces a two-phase framework where the model autonomously decides between direct response and invoking external tools for specialized audio tasks.
- The methodology boosts accuracy, evidenced by performance improvements on benchmarks (e.g., Gemini-2.5-flash from 67.4% to 72.1%).
- The framework enhances interpretability by integrating low-level acoustic analysis with high-level semantic reasoning, despite challenges in tool output accuracy.
Audio-Maestro: Enhancing Large Audio-LLMs
Introduction
The paper explores the limitations of current large multimodal models (LMMs) in audio understanding, particularly their reliance on end-to-end reasoning methods that reduce accuracy and interpretability for certain tasks. It proposes Audio-Maestro, a framework that augments LMMs by integrating tool-augmented reasoning, allowing these models to autonomously invoke external tools for analysis and integrate their outputs. This new approach aims to blend low-level acoustic analysis with high-level semantic understanding, improving both the performance and interpretability of audio reasoning tasks.
Framework Overview
Audio-Maestro introduces a novel two-phase framework designed to enhance the reasoning capabilities of large audio-LLMs (LALMs). In the first phase, the LALM autonomously decides whether to respond directly to a query or invoke external tools for specialized tasks such as chord recognition or speaker diarization.
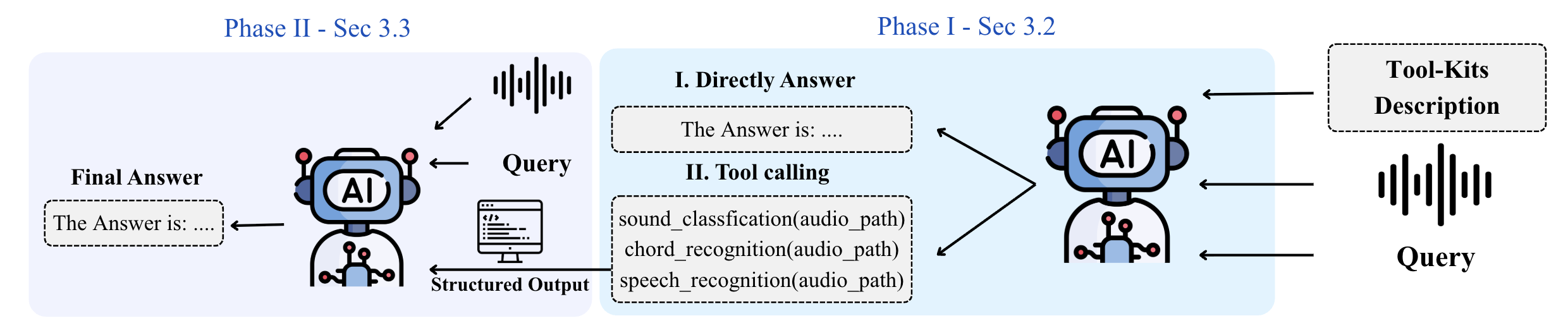
Figure 1: Overview of the Audio-Maestro framework. Given an audio input, query, and toolkit, the LALM first decides whether to answer directly or call tools in Phase 1. In Phase 2, selected tools are executed on the audio, producing structured, timestamped outputs that are integrated with the query and audio for final inference.
In the second phase, these tools operate on the audio input to produce structured, timestamped outputs, which are integrated back into the reasoning process, allowing the model to perform more precise and grounded symbolic reasoning.
Implementation Details
The Audio-Maestro framework operates under a zero-shot setting, meaning it relies on structured prompts without task-specific fine-tuning. The use of prompts includes defining the model's role as an audio expert, describing available tools, and providing the user’s query. If tools are invoked, their outputs are serialized into JSON format and integrated with the original audio and query data to form an enriched context for final inference. This method enhances the interpretability and context-awareness of the model's reasoning process.
Experimental Results
Audio-Maestro demonstrates significant improvements in performance across multiple models on the MMAU benchmark, which tests multimodal audio understanding. For instance, it raised the average accuracy of Gemini-2.5-flash from 67.4% to 72.1%, and similarly improved DeSTA-2.5’s accuracy from 58.3% to 62.8% on complex reasoning tasks.
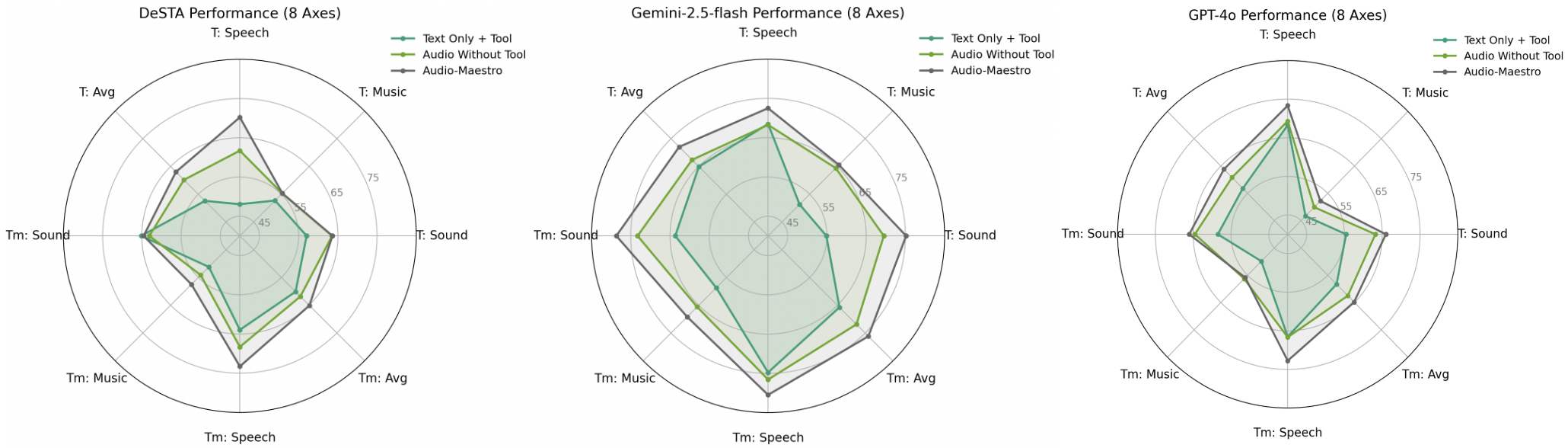
Figure 2: Performance of Gemini-2.5-flash, DeSTA-2.5, and GPT-4o on the MMAU Benchmark. The results are segmented into eight categories, and T denotes MMAU-Test and Tm denotes MMAU-Test-Mini.
The ability of Audio-Maestro to consistently outperform audio models without tool augmentation highlights the efficacy of delegating specialized tasks to external tools, thereby enhancing overall interpretability and robustness.
Manual error analysis reveals that most errors are due to inaccuracies in tool outputs. For example, incorrect or incomplete responses from tools like "chord recognition" suggest a critical need for robust tool support and improved underlying model accuracy. Despite such errors, the use of tools generally leads to performance improvements, indicating that the integration method effectively enhances model capabilities.
Implications and Future Directions
Audio-Maestro elucidates the importance of modular reasoning frameworks where LALMs leverage external tools for low-level acoustic tasks, enhancing performance and interpretability. Future research should focus on improving the robustness and accuracy of these tools to further increase the reliability of the framework. Additionally, optimizing the framework to reduce inference time while maintaining high accuracy will be pivotal for real-time applications.
Conclusion
Audio-Maestro represents a significant step forward in enhancing the reasoning capacities of LALMs by innovatively integrating tool-based analysis within multimodal models. By bridging the gap between low-level acoustic accuracy and high-level semantic understanding, it lays the groundwork for future developments in tool-augmented audio reasoning. Addressing limitations such as tool accuracy and inference speed will be crucial as this framework continues to evolve.

