What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Abstract: AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of the Paper: What Makes a Good AI Research Agent?
1) What is this paper about?
This paper studies a new type of AI system called an “AI research agent.” These agents are computer programs that can plan experiments, write code, train models, and test their ideas—much like a junior scientist. The authors ask a simple question: do agents do better when they try a wider variety of ideas? They call this “ideation diversity,” and they show that having more diverse ideas helps agents perform better.
2) What questions are the researchers trying to answer?
The paper focuses on three easy-to-understand questions:
- Do agents that consider a wider mix of ideas (like different model types) perform better on real machine-learning tasks?
- Can we intentionally increase or decrease how diverse an agent’s ideas are—and does that change performance?
- Are the results true no matter how we measure success (not just with one score)?
3) How did they study it?
To make this clear, here are the main parts of their approach, explained in everyday language:
- What’s an AI research agent?
- comes up with ideas for how to solve a task,
- writes and runs code,
- checks results,
- and improves its work step by step.
- What is “ideation diversity”? It means how varied the agent’s ideas are at the start, especially the types of models it plans to try. For example, in the first batch of ideas, does it suggest a CNN, a Transformer, a decision tree, and a gradient-boosted model—or just the same kind of model over and over?
- How did they measure diversity? They used a simple “variety score” (Shannon entropy). Imagine a box of chocolates: if all pieces are the same flavor, variety is low; if you have many different flavors, variety is high. The authors look at the mix of model architectures in the agent’s first few ideas and give it a variety score.
- What tasks did the agents work on? They used MLE-bench, a set of 75 real Kaggle-style machine-learning challenges (things like image classification, text tasks, time series, and tabular data). This simulates real-world ML work.
- What kinds of agents did they test?
- Greedy search (pick the next best-looking step),
- MCTS (Monte Carlo Tree Search—a strategy that tries many possible paths, a bit like exploring different moves in a game),
- and AIDE (another structured agent design).
- They also tried different “brains” (LLMs) behind the agents.
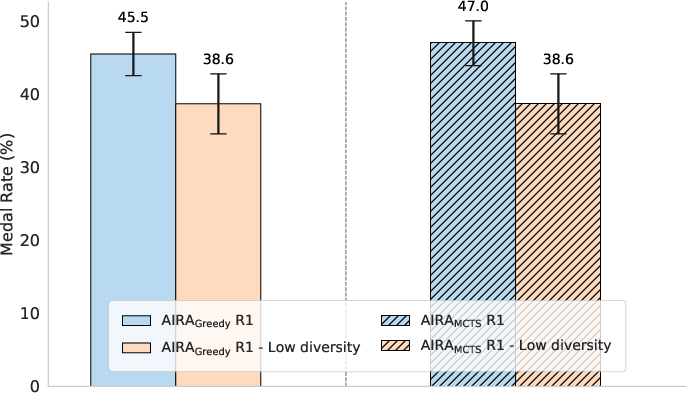
- The controlled experiment: To test cause and effect, they ran a clean experiment where they changed the agent’s instructions to reduce idea diversity on purpose. In one setup, the agent is encouraged to propose different kinds of ideas; in the other, it’s nudged to suggest similar ideas. Everything else stays the same. Then they compared the results.
- How did they measure success?
- Valid submission rate (can it submit something that runs?),
- Average normalized score (how good the scores are, scaled fairly),
- Percentile (how it ranks versus humans),
- ELO-style ranking (head-to-head comparisons between agents).
4) What did they find, and why does it matter?
Here are the key takeaways:
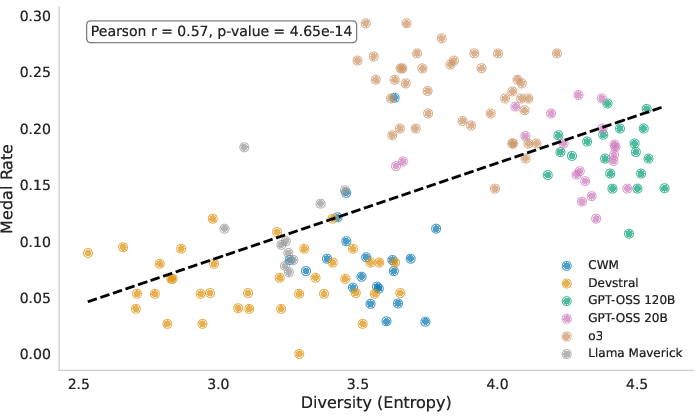
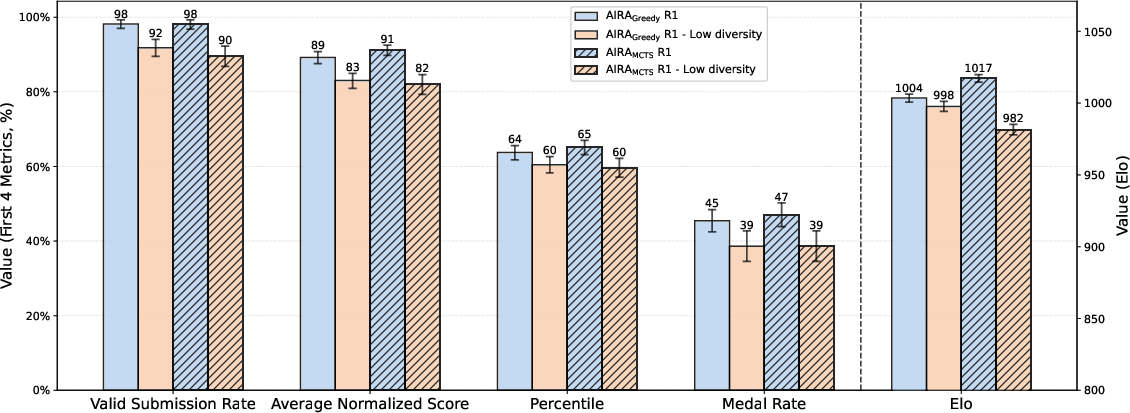
- More diverse ideas → better performance: Agents that propose a wider range of model types early on tend to do better across many tasks. This isn’t just a coincidence: when the researchers forced agents to be less diverse, performance dropped.
- The way you build the agent matters: Different agent “scaffolds” lead to different levels of idea diversity. Some designs naturally encourage trying varied approaches; others repeat the same style too often. The more balanced designs did better.
- Diversity helps avoid getting stuck: Low-diversity agents sometimes kept trying the same tricky model (like T5) and repeatedly failed to get a working submission. Diverse agents tried different options and were more likely to get something working and competitive.
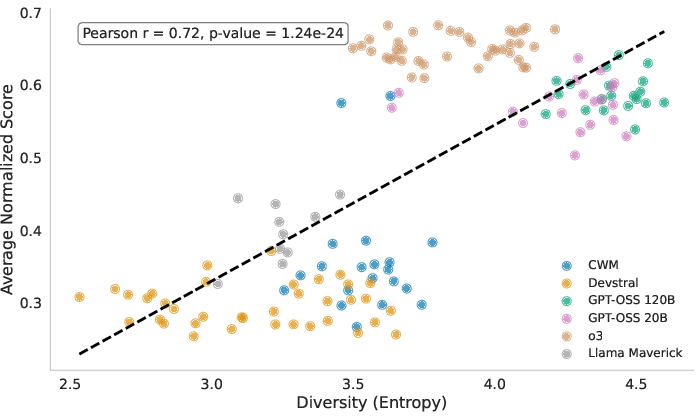
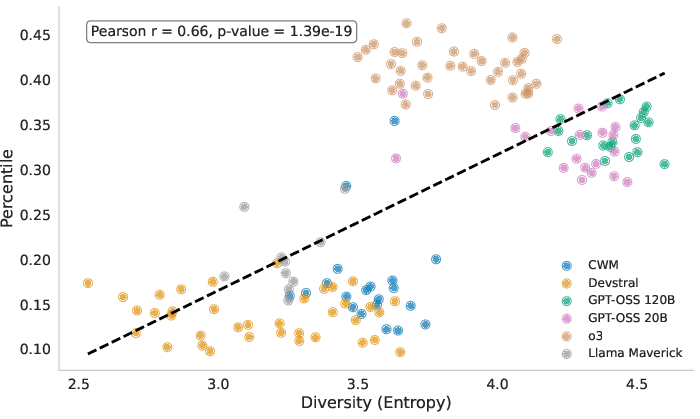
- Results hold across many metrics: It wasn’t just the medal rate. Other measures (like valid submissions, normalized score, percentile, and ELO) told the same story: diversity improves outcomes.
- There’s also an “implementation bottleneck”: Being able to write and run more complex code also matters a lot. Agents that could successfully implement and train more advanced models tended to earn more medals. Still, even with imperfect coding, diversity made a clear positive difference.
5) What’s the bigger picture?
- For building better AI agents now: Encourage variety. Design agents (and their prompts) so they try meaningfully different ideas, not just small tweaks of the same plan. This lowers the risk of getting stuck and raises the chances of success.
- As coding AIs get stronger: If agents keep getting better at implementing code, then planning and ideation will matter even more. Being smart about exploring many promising paths will likely be a key advantage.
- For fair evaluation: Relying on only one score (like medals) can be misleading, because different competitions and splits vary. Using multiple metrics gives a clearer picture of an agent’s real ability.
- Likely to generalize: While the study used MLE-bench, the logic behind “try a range of good ideas, not just one” should apply to many kinds of scientific and engineering problems.
In short: Good AI research agents don’t just think hard—they think wide. Trying a diverse set of solid ideas at the start makes them more reliable, more successful, and better at solving real-world machine-learning tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. These items are intended to guide future research.
- Validating the measurement of ideation diversity: The paper operationalizes diversity using Shannon entropy over model architectures in the first five ideas. It does not validate that this proxy reflects meaningful diversity across other critical dimensions (data preprocessing, feature engineering, loss functions, training regimes, augmentation, hyperparameter strategies, evaluation choices, tool chains).
- Diversity beyond initial drafts: The analysis focuses on the first five initial ideas. It leaves unexplored how diversity evolves over subsequent Improve/Debug steps, deeper tree levels, and across entire trajectories, and whether later-stage diversity is more predictive of performance.
- Granularity of “architecture” categories: The mapping from agent plans to “architecture” and “model family” categories is not audited for accuracy, inter-rater reliability, or ambiguity (e.g., hybrids, pipelines, and multi-stage systems). The classification procedure and its error rates are not evaluated.
- Task- and modality-specific effects: The paper does not disaggregate the diversity–performance relationship by domain (CV, NLP, tabular, time series, multimodal) or task archetype (small data vs. large data, imbalanced labels, structured text). It is unclear where diversity helps most, is neutral, or hurts.
- Confounding by LLM capability and scaffold design: Correlations between diversity and performance may be driven by backbone differences (o3 vs. open-source models), prompt quality, operator design, memory scope, or search policy (Greedy vs. MCTS). A multivariate analysis or matched comparisons controlling for these confounders are missing.
- Causal manipulation specificity: The controlled experiment alters the system prompt (removing prompt-adaptive complexity and diversity mentions), which may affect implementation behaviors and code quality indirectly. The study does not isolate ideation-only effects (e.g., via a separate ideation LLM or decoupled modules).
- Incremental vs. excessive diversity: The paper shows benefits of reducing diversity to “low,” but does not explore whether increasing diversity beyond baseline continues to help, saturates, or backfires (breadth–depth trade-offs). The optimal diversity level under fixed compute budgets is unknown.
- Cost–efficiency trade-offs: The compute price of diversity (e.g., more breadth, more dead-ends) versus performance gains is not quantified. Methods for compute-aware diversity scheduling or adaptive breadth–depth balancing remain unexplored.
- Implementation competence alignment: Diversity may help by steering into models the agent can implement; however, the paper does not quantify per-architecture implementability rates, error modes, or the match/mismatch between ideation and agent coding competence across model families.
- Mechanism attribution: The baseline includes three diversity mechanisms (sibling memory, prompt-adaptive complexity, explicit diversity instruction). The ablation removes two at once. Which mechanism contributes most to effective diversity is unknown; targeted, single-factor ablations are not provided.
- Alternate diversity controls: Temperature-based control is deferred to the appendix and not analyzed in the main text. Other controls (top-k/p sampling, stochastic operators, ensemble ideation, novelty search, diversity-aware RL objectives, Determinantal Point Processes) are not investigated.
- Measuring diversity of experimental design: Diversity in data splits, validation schemes, feature pipelines, objective functions, optimization strategies, and training curricula is not captured. Future work needs metrics that represent full ML engineering plan diversity, not just model architectures.
- Robustness across benchmarks and time: Findings are limited to MLE-bench. Generalization to newer, harder, or non-Kaggle ML tasks, other agent benchmarks (e.g., MLAgentBench, RE-Bench, ML Gym), software engineering tasks, or real-world research settings is untested.
- Medal-rate limitations and statistical rigor: While alternative metrics are reported, the study does not provide significance testing for diversity–performance correlations, nor regression models controlling for confounds. ELO construction details and robustness checks (e.g., transitivity, variance across seeds) are limited.
- Seed sensitivity and variance decomposition: The paper runs multiple seeds but does not analyze seed-induced variance, stability across seeds, or how diversity interacts with stochasticity in exploration policies.
- Memory scoping and operator design: Memory configurations and operator implementations (Draft/Debug/Improve) are acknowledged to impact diversity but are not systematically varied to quantify their effect sizes.
- MCTS configuration fairness: MCTS generates “up to five” initial ideas vs. “exactly five” for greedy searches. Potential differences in initial breadth between scaffolds may bias the diversity measure; normalization across scaffolds is not ensured.
- Failure analysis depth: The highlighted failures (e.g., repeated T5 timeouts) are anecdotal. A systematic taxonomy of failure modes (dependency issues, environment/tooling constraints, dataset-specific pitfalls, training instability) by architecture and scaffold is missing.
- Per-task heterogeneity: The paper notes that older Kaggle competitions differ from recent ones, but does not quantify how diversity benefits vary across competition age, participant distribution, or difficulty. A per-task meta-analysis is absent.
- Data and artifacts availability: The large trajectory bank (11,000 trajectories) is not reported as publicly released. Without code, prompts, classifiers for architecture extraction, and logs, reproducibility and independent validation are limited.
- Dynamic complexity cues measurement: The baseline uses prompt-adaptive complexity, but the study does not measure whether the generated ideas actually increase in complexity across drafts, nor how complexity relates to implementability and performance.
- Human-in-the-loop and multi-agent diversity: The paper does not examine whether a population of diverse agents or human-in-the-loop curation of diverse ideas yields larger gains than a single agent with internal diversity mechanisms.
- Diversity–valid submission linkage: The relationship between ideation diversity and valid submission rate is shown for two tasks but not analyzed broadly. A systematic link between diversity, implementation success probability, and downstream performance is not quantified.
- Capability-aware ideation: Methods to bias ideation toward ideas the agent is likely able to implement (capability models, competence priors, curriculum-based idea generation) are proposed conceptually but not tested.
- Tooling and environment dependence: The role of tool availability, package versions, runtime limits, and execution environments in mediating diversity’s effect is not isolated. Cross-environment robustness is unexamined.
- Bias/leakage risks: Potential training data overlap between LLMs and Kaggle content, or prompt leakage of competition specifics, is not assessed. How such leakage might interact with diversity is unknown.
- Safety and ethics of autonomous research agents: The paper does not discuss safety implications of encouraging broad exploration (e.g., risky code execution, data misuse) or guidelines for safe diversity.
- Benchmark update strategy: Given medal system limitations and aging competitions, a concrete plan to update or redesign benchmarks that better reflect modern ML practice—and to re-evaluate diversity’s impact on them—is not provided.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, leveraging the paper’s findings on ideation diversity, its measurement (Shannon entropy over planned model architectures), and prompt/scaffold interventions (sibling memory, prompt-adaptive complexity, explicit diversity cues).
- Diversity-aware orchestration in ML agent platforms
- Sector: Software/ML engineering, AutoML, MLOps
- Application: Add “diversity-first” steps (generate 5 distinct initial plans with complexity cues and sibling memory) to agent scaffolds like AIDE/AIRA; monitor ideation diversity and intervene when it drops.
- Tools/Products/Workflows: Ideation Entropy Monitor; Diversity Governor in agent runners; Prompt-adaptive complexity templates; Sibling-memory configuration
- Assumptions/Dependencies: Access to LLM agents with tool-use; ability to extract model-architecture labels from plans; logging of ideation nodes; moderate compute availability
- Risk mitigation against implementation lock-in
- Sector: Software/ML engineering; Competitive ML (Kaggle-style); Enterprise DS teams
- Application: Use diversity prompts to avoid agents fixating on hard-to-implement models (e.g., repeated T5 failures in text normalization). Gate pipelines with valid-submission-rate checks; auto-branch to alternative architectures when failures persist.
- Tools/Products/Workflows: Failure-triggered brancher; Valid Submission Rate guardrails; Timeout-aware fallback models
- Assumptions/Dependencies: Reliable error detection and timeout monitoring; alternative model families available; organizational acceptance of exploratory branching
- Agent evaluation beyond medal-rate
- Sector: Procurement, vendor management, benchmarking, R&D ops
- Application: Adopt percentile, average normalized score, valid submission rate, and ELO-based agent ranking for vendor/comparator evaluations to get robust performance signals.
- Tools/Products/Workflows: Agent ELO Evaluator; Multi-metric benchmarking dashboards; Stratified bootstrapping with rliable-like tooling
- Assumptions/Dependencies: Access to representative tasks/datasets; consistent score normalization; agreement on evaluation protocols
- Diversity-aware experiment design in research labs
- Sector: Academia, industrial research (AI/ML)
- Application: Require ideation diversity in experiment plans (distinct model families, data-processing strategies); measure diversity via entropy at proposal stage; review pipelines for mode collapse risks.
- Tools/Products/Workflows: Pre-experiment diversity checklist; Entropy-based proposal rubric; Lab policy to include minimum distinct approaches
- Assumptions/Dependencies: Cultural shift to value diverse hypotheses; annotation of idea categories; review bandwidth
- Curriculum and training for data scientists and ML engineers
- Sector: Education, corporate upskilling
- Application: Teach diversity-promoting prompts and scaffolds; grade assignments with ideation-entropy and multi-metric evaluation; emphasize exploration vs. exploitation trade-offs.
- Tools/Products/Workflows: Prompt templates for “5 ideas across distinct families”; Entropy-based grading plug-ins; Mini MLE-bench-lite exercises
- Assumptions/Dependencies: LLM access for students; simple instrumentation for ideation capture; alignment with learning objectives
- MLOps integration of diversity signals
- Sector: MLOps/Platform engineering
- Application: Log ideation diversity as a first-class metric (alongside runtime and validation scores); raise alerts when diversity drops; allocate compute adaptively across branches.
- Tools/Products/Workflows: MLflow/Weights & Biases integration for diversity metrics; Compute schedulers that weight diverse branches higher
- Assumptions/Dependencies: Observability in agent orchestrators; data retention policies; resource elasticity
- Portfolio-style model selection in applied domains
- Sector: Finance (quant research), Energy (forecasting), Retail (demand planning)
- Application: Run agents to propose diverse candidate models; select a portfolio of heterogeneous models to hedge implementation and generalization risks.
- Tools/Products/Workflows: Diversity-scored ensembling; Portfolio optimizer balancing performance and diversity; Branch throttling policies
- Assumptions/Dependencies: Access to varied model families; compatibility with production constraints; evaluation on domain-specific metrics
- Rapid issue triage in agent failures
- Sector: Software/ML engineering
- Application: When debug loops or context overload appear, use well-scoped memory and diversity prompts to break loops and pivot to simpler alternatives.
- Tools/Products/Workflows: Memory scope policies; Loop-detection heuristics; Pivot-to-simplicity operator
- Assumptions/Dependencies: Clear operator interfaces (Draft/Debug/Improve); reliable memory scoping; failure pattern detection
- Governance and documentation of agent exploration
- Sector: Policy/Compliance, Enterprise governance
- Application: Require logging of ideation diversity, operator actions, and branch outcomes for auditability and model risk management.
- Tools/Products/Workflows: Exploration transparency reports; Diversity audit trails; Governance dashboards
- Assumptions/Dependencies: Organizational governance standards; retention and privacy policies; alignment with regulatory expectations
- Human-in-the-loop fallback triggers
- Sector: Enterprise AI, safety-critical applications
- Application: If valid submission rate or diversity falls below thresholds, trigger human review or intervention; replace brittle architectures with safer baselines.
- Tools/Products/Workflows: Threshold-based intervention policies; Safe baseline library; Reviewer queueing system
- Assumptions/Dependencies: Clear thresholds; availability of human reviewers; cost budgets
Long-Term Applications
These require further research, scaling, or productization, building on causal evidence that ideation diversity improves agent performance.
- Diversity-aware agent OS
- Sector: Software/ML engineering, agent tooling
- Application: A unified operating system for research agents that automatically measures, optimizes, and governs ideation diversity across planning, coding, and experimentation.
- Tools/Products/Workflows: Diversity optimization loops; Exploration-exploitation controllers; Cross-agent ELO matchmaking
- Assumptions/Dependencies: Stable interfaces between ideation and implementation; scalable logging and control; standardized benchmarks
- Decoupled ideation vs. implementation agents
- Sector: Agent architecture research
- Application: Use one LLM optimized for ideation diversity and another for coding/execution; combine via MCTS or other search policies for better exploration and reliability.
- Tools/Products/Workflows: Dual-agent scaffolds; Role-specialized prompts; Inter-agent negotiation protocols
- Assumptions/Dependencies: Reliable hand-offs; robust tool-use; advances in coding accuracy to reduce implementation bottlenecks
- Diversity-aware reinforcement learning for agents
- Sector: RL, robotics, planning
- Application: Integrate diversity objectives (entropy/novelty) into agent training to systematically improve exploration (B-star-like balance of exploration/exploitation).
- Tools/Products/Workflows: Diversity-shaped rewards; Population-based RL with skill diversity; Trajectory entropy maximization
- Assumptions/Dependencies: Stable training regimes; scalable reward shaping; safe exploration guarantees
- Cross-domain scientific discovery agents
- Sector: Healthcare/biomed, chemistry, materials, energy systems
- Application: Apply ideation diversity controls to wet-lab planning and simulation-driven discovery; hedge against unimplementable protocols; prioritize feasible diverse hypotheses.
- Tools/Products/Workflows: Lab protocol planners with diversity governors; Multi-modal idea categorization (assays, models, datasets)
- Assumptions/Dependencies: Domain-specific toolchains (lab automation, simulators); safety/compliance; reliable execution environments
- Standards for agent evaluation and procurement
- Sector: Policy, public sector, large enterprises
- Application: Formal standards mandating multi-metric evaluation (percentile, normalized scores, ELO) and diversity logging for agent procurement and certification.
- Tools/Products/Workflows: Certification frameworks; Reporting templates; Third-party audit services
- Assumptions/Dependencies: Policy consensus; interoperability of metrics; acceptance by vendors
- Compute budgeting and scheduling for diverse exploration
- Sector: Cloud/infra, enterprise AI ops
- Application: Resource schedulers that dynamically allocate compute to diverse branches shown to improve expected performance; prune low-yield duplication.
- Tools/Products/Workflows: Diversity-aware schedulers; Expected gain estimators; Pruning heuristics
- Assumptions/Dependencies: Accurate performance predictors; cost-governance; fairness across projects
- Agent marketplaces ranked by ELO and diversity
- Sector: AI platforms, marketplaces
- Application: Marketplaces that list agents by task-specific ELO and diversity performance, enabling buyers to pick agents that explore broadly and execute reliably.
- Tools/Products/Workflows: ELO-ranking APIs; Diversity scorecards; Task-specific leaderboards
- Assumptions/Dependencies: Broad benchmark coverage; anti-gaming measures; standardized task taxonomies
- Education and accreditation for diversity-driven experimentation
- Sector: Education, professional certification
- Application: Certifications requiring demonstration of diversity-aware research design and agent orchestration skills; training on entropy-based evaluation.
- Tools/Products/Workflows: Accreditation syllabi; Practical labs; Graded capstone projects
- Assumptions/Dependencies: Industry alignment; assessable competencies; accessible tools
- Safety frameworks for autonomous experimentation
- Sector: AI safety, compliance
- Application: Safety policies that use diversity to reduce risk concentration (avoid single risky approach); require minimum diversity in high-stakes autonomous experiments.
- Tools/Products/Workflows: Risk concentration monitors; Diversity minimums; Incident postmortem templates
- Assumptions/Dependencies: Clear risk taxonomies; enforcement mechanisms; legal and ethical guidelines
- Domain-general diversity metrics beyond architectures
- Sector: Methodology, metascience
- Application: Extend diversity measurement to preprocessing, features, training regimes, validation splits, and toolchains to capture richer forms of ideation diversity.
- Tools/Products/Workflows: Multi-axis diversity ontology; Composite diversity indices; Cross-domain instrumentation
- Assumptions/Dependencies: Agreement on taxonomies; reliable extraction/annotation; cross-task comparability
Glossary
- AIDE: An LLM-driven research agent that explores code solutions via tree search. "AIDE, an LLM-driven agent that approaches problem-solving as a tree-search over the domain of Python solutions, utilizing a Greedy policy."
- AIRA_Greedy: An agent scaffold using a greedy tree-based search policy. "$\text{AIRA}_{\text{GREEDY}$, another greedy tree-based search policy, with a different design for operators, memory scope, and prompts,"
- AIRA_MCTS: An agent scaffold using Monte Carlo Tree Search as its search policy. "$\text{AIRA}_{\text{MCTS}$, utilizing Monte Carlo Tree Search (MCTS~\citep{mcts1, mcts2, mcts3}) for its search policy, in contrast to its greedy counterparts."
- Agentic framework/scaffold: The outer-loop orchestration that uses an LLM to interface with the environment. "This outer loop orchestrating the LLM actions is usually referred to as agentic frameworks or agentic scaffolds in the literature"
- Average Normalized Score: A performance metric that normalizes each task score to [0,1] using human minimum and maximum. "Average Normalized Score: For each agent attempt at a task, we compute a normalized score: a score of 0 represents the lowest human score achieved on the task, and 1 the highest."
- Context window: The maximum number of tokens an LLM can process in a single prompt. "All of the LLMs above use a 128K-token context window to ensure input coverage without truncation."
- Debug operator: An operator that identifies and fixes errors in a solution node. "Debug, which identifies and corrects errors within a given node;"
- Draft operator: An operator that generates initial candidate solutions. "Draft, which generates the initial population of solutions;"
- ELO-Based Agent Ranking: A comparative rating system for agents based on head-to-head score matchups. "ELO-Based Agent Ranking: We create an ELO system~\citep{elo} using all possible heads-to-heads between agents' scores."
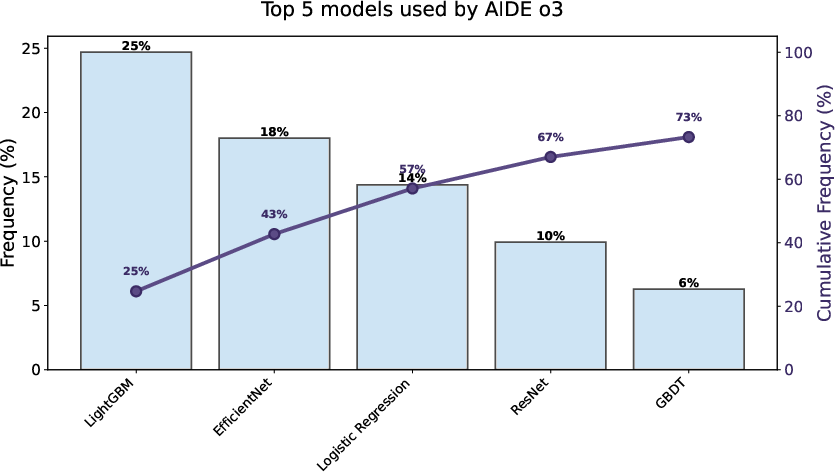
- EfficientNet: A family of CNN architectures optimized for scaling. "LightGBM and EfficientNet represent 43\% of models AIDE agents intend to train in its initial draft nodes,"
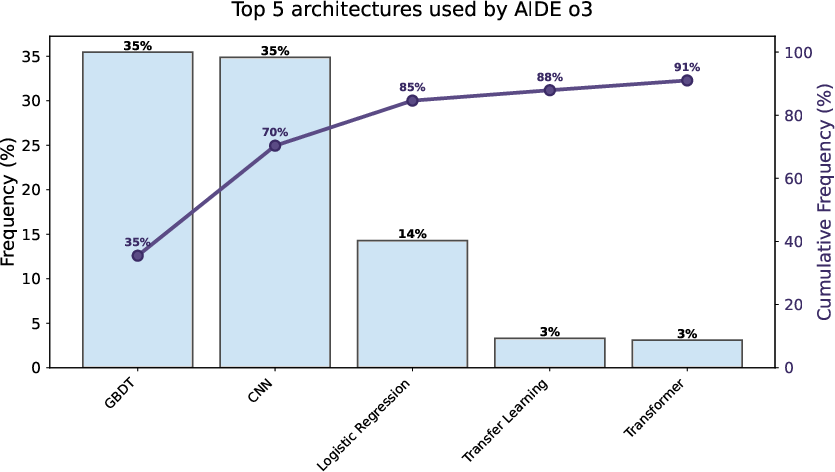
- GBDT (Gradient Boosting Decision Trees): An ensemble learning method using sequential tree boosting. "AIDE agents prefer Gradient Boosting Decision Trees (GBDT) and Convolutional Neural Networks (CNN) in 70\% of the initial draft nodes."
- Greedy policy: A search strategy that selects the locally best option at each step. "utilizing a Greedy policy."
- Kaggle medal system: A percentile-based award framework (bronze/silver/gold) used in Kaggle competitions. "aside from the standard score based on the Kaggle medal system"
- LightGBM: A fast, memory-efficient gradient boosting framework for decision trees. "LightGBM and EfficientNet represent 43\% of models AIDE agents intend to train in its initial draft nodes,"
- Medal rate (Medal Success Rate): The percentage of attempts where an agent earns any medal on a task. "we assess each agentâs performance using the Medal Success Rate (henceforth referred to as medal rate)."
- Memory configuration: The setup that determines which prior artifacts are provided to operators. "Additionally, the memory configuration dictates how each operator is selectively provided with previously produced artifacts,"
- Memory scope: The extent of prior context accessible within the agent’s operations. "with a different design for operators, memory scope, and prompts,"
- Mode collapse: A failure mode where generated solutions lack diversity and converge to similar outputs. "with well-scoped memory preventing issues such as context overload, mode collapse, and debug loops."
- Monte Carlo Tree Search (MCTS): A stochastic tree-search algorithm that balances exploration and exploitation via simulations. "utilizing Monte Carlo Tree Search (MCTS~\citep{mcts1, mcts2, mcts3}) for its search policy"
- Percentile (metric): A performance measure indicating where an agent’s score lies relative to human scores. "Percentile: The metric captures the ability of the agent to outperform humans at machine learning engineering."
- Prompt-adaptive complexity: A prompt mechanism that scales requested solution complexity across drafts. "Prompt-adaptive complexity, which is a dynamic complexity cue within the system prompt aiming to guide the complexity of artifacts generated by the agents."
- Sampling temperature: A parameter controlling randomness in token selection during generation. "we provide additional results where we control diversity via the sampling temperature parameter."
- Shannon entropy: An information-theoretic measure of uncertainty used to quantify ideation diversity. "we propose calculating Shannon entropy \citep{shannon1948mathematical} on the distribution of model architectures that the agent plans to implement in the ideation phase."
- Sibling memory: Providing descriptions of sibling nodes to a new draft to influence ideation. "Sibling memory, which provides to a new draft node the memory of its siblings, by including in the context descriptions of the solutions devised by the sibling nodes."
- Stratified bootstrapping: A resampling method that preserves strata when estimating uncertainty. "Error bars represent 95\% confidence intervals computed using stratified bootstrapping, using the rliable library"
- Stratified sampling: A sampling approach that maintains group proportions for robust evaluation. "The benchmark employs stratified sampling and cross-validation methodologies to ensure robust performance assessment,"
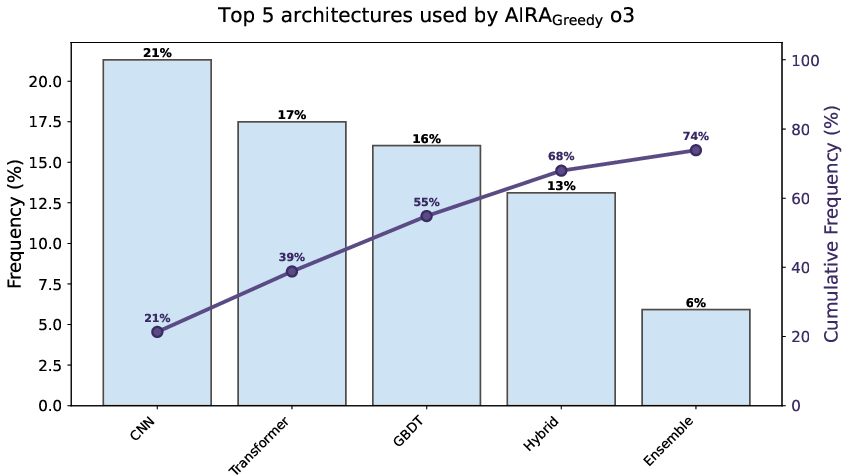
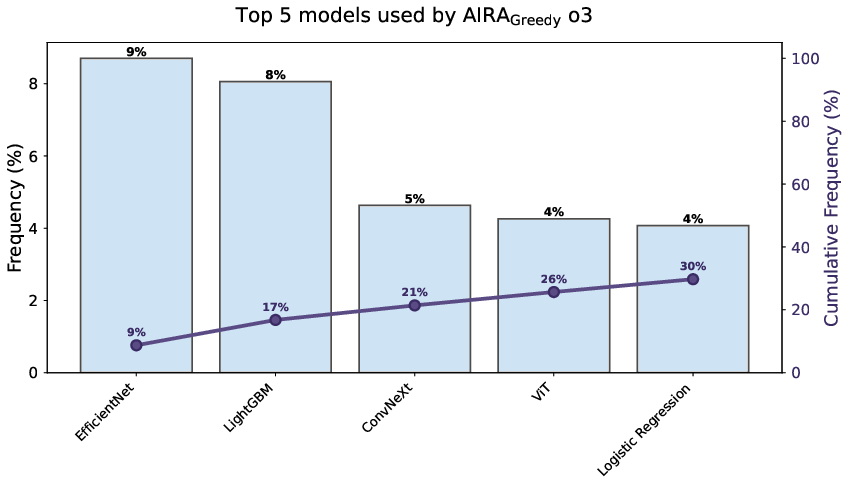
- Tree-level diversity: The count of distinct architectures across initial nodes in the search tree. "a metric we refer to as tree-level diversity."
- Tree-search: Exploration of solutions structured as nodes and edges in a tree. "approaches problem-solving as a tree-search over the domain of Python solutions,"
- Valid Submission Rate: The percentage of tasks where the agent produces at least one valid submission. "Valid Submission Rate: The percentage of tasks in which the agent is able to make a valid submission."
Collections
Sign up for free to add this paper to one or more collections.

