- The paper introduces TVBench, a benchmark emphasizing hard temporal constraints to rigorously test video-language models’ temporal reasoning.
- It employs a template-based question design and balanced candidate answers to eliminate static and textual biases.
- Experimental results reveal that state-of-the-art models perform near random on TVBench, highlighting the critical need for genuine temporal understanding.
A New Temporal Benchmark for VideoLLMs: TVBench
Abstract
The paper "Lost in Time: A New Temporal Benchmark for VideoLLMs" introduces TVBench, a novel open-source benchmark designed to evaluate the temporal understanding capabilities of video-LLMs. This benchmark addresses significant shortcomings in existing video-language benchmarks, particularly MVBench, by emphasizing the necessity of temporal reasoning to solve video-related tasks. Through extensive evaluations, the authors highlight that current state-of-the-art models perform close to random on TVBench, underscoring the benchmark's ability to differentiate between models with genuine temporal reasoning capability.
Introduction
Video-LLMs have gained prominence by effectively leveraging advancements in both NLP and vision models to understand video content. However, evaluating these models is challenging, as many existing benchmarks, like MVBench, fail to adequately test temporal reasoning. MVBench, a widely-used benchmark, has been identified to have significant biases, allowing tasks to be solved with static information or textual cues without temporal understanding. These issues compromise its reliability in measuring genuine video comprehension and temporal reasoning.
Limitations of Existing Benchmarks
Existing video-language benchmarks suffer from several problems:
- Static Information Sufficiency: Tasks can often be solved using information from a single frame, rather than requiring analysis of the entire video sequence.
- Textual and World Knowledge Bias: Overly informative text allows models to answer questions correctly without relying on visual content. Prior world knowledge often compensates for the lack of video analysis.
- Unreliability in Open-Ended QA: Automatic evaluation using LLMs, like GPT-3.5, is prone to inconsistencies and hallucinations, leading to unreliable assessment of open-ended video QA tasks.
TVBench Design Principles
TVBench was developed to address these issues:
- Hard Temporal Constraints: The benchmark includes tasks with temporally challenging aspects, ensuring that answers cannot be deduced without analyzing the temporal sequence (Figure 1).
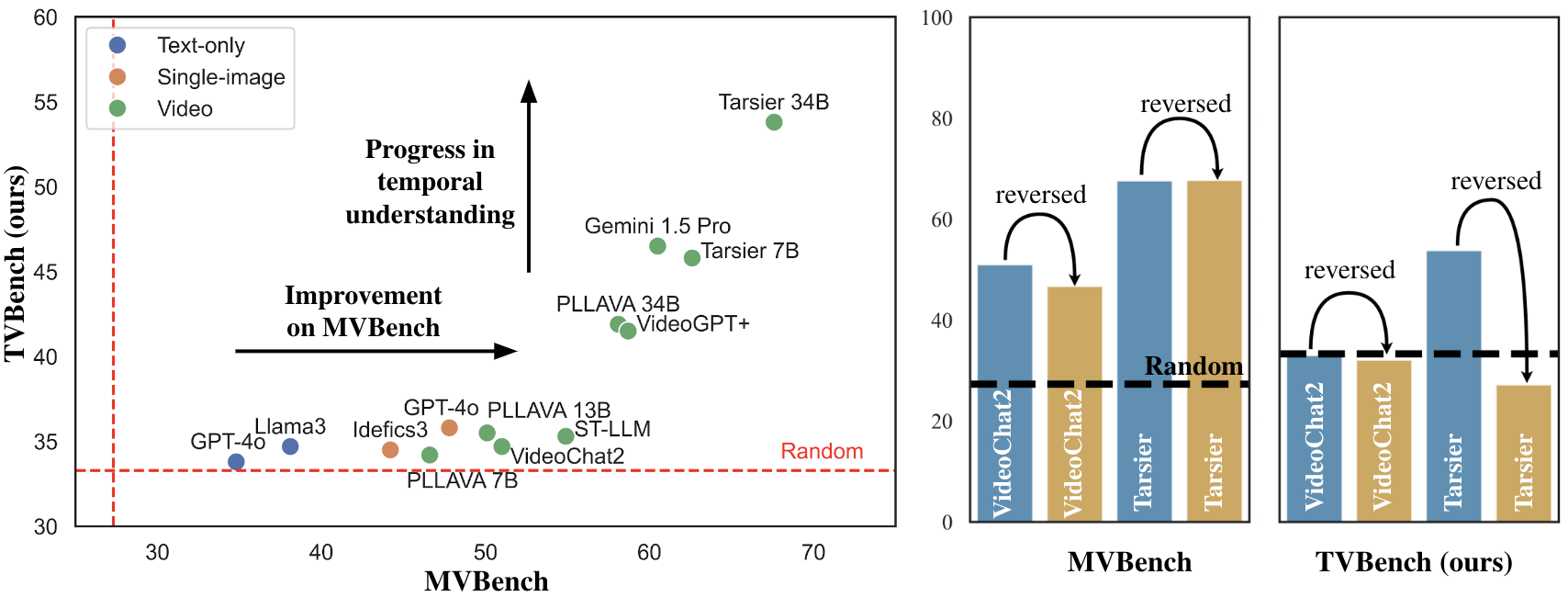
Figure 1: TVBench a temporal video-language benchmark. In TVBench, state-of-the-art text-only, image-based, and most video-LLMs perform close to random chance, with only the latest strong temporal models, such as Tarsier, outperforming the random baseline. In contrast to MVBench, the performance of these temporal models significantly drops when videos are reversed.
- Question and Candidate Design: Questions are generated using templates to eliminate textual bias, and candidate answers are balanced to avoid biases towards certain assumptions.
- Minimal World Knowledge Reliance: Tasks are designed so that answers rely solely on video content, not on external knowledge.
Evaluation and Results
The evaluation on TVBench reveals that many current video-LLMs, despite their state-of-the-art status in other benchmarks, perform at random chance level. Notably, the temporal models Tarsier and Gemini 1.5 Pro demonstrated superior performance, clearly surpassing random baselines due to their temporal reasoning capabilities.
- Text-Only and Image-Model Performance: These models perform at random chance level on TVBench, indicating a reliance on temporal understanding rather than static information or textual cues.
- Impact of Video Shuffling and Reversing: Unlike their performance on MVBench, models experience a significant drop when videos are shuffled or reversed on TVBench, emphasizing the benchmark's effectiveness in temporal evaluation (Figures 2 and 3).
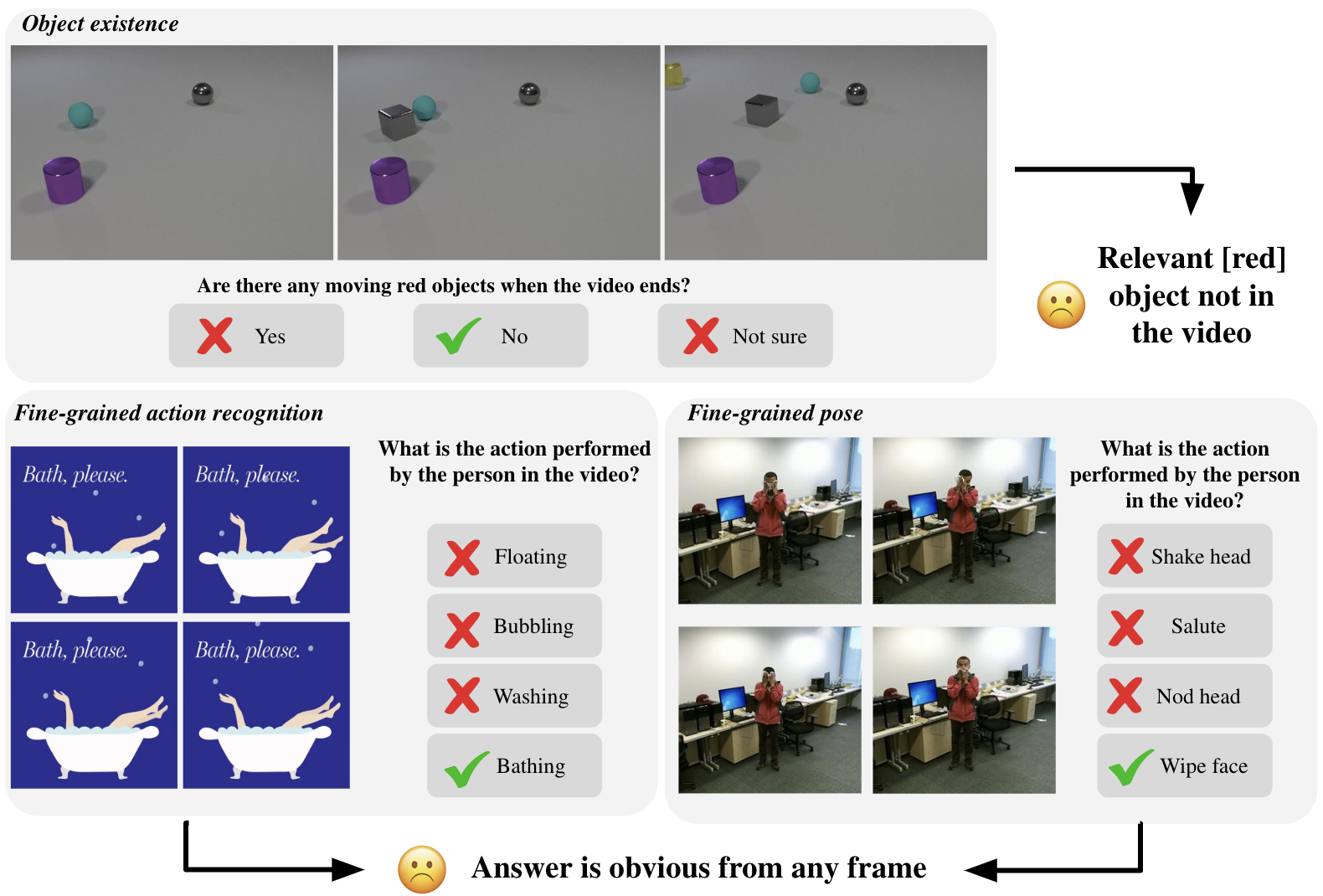
Figure 2: Spatial bias of MVBench video-language benchmark. We show different tasks of the MVBench benchmark and observe that the question can be answered without requiring any temporal understanding.
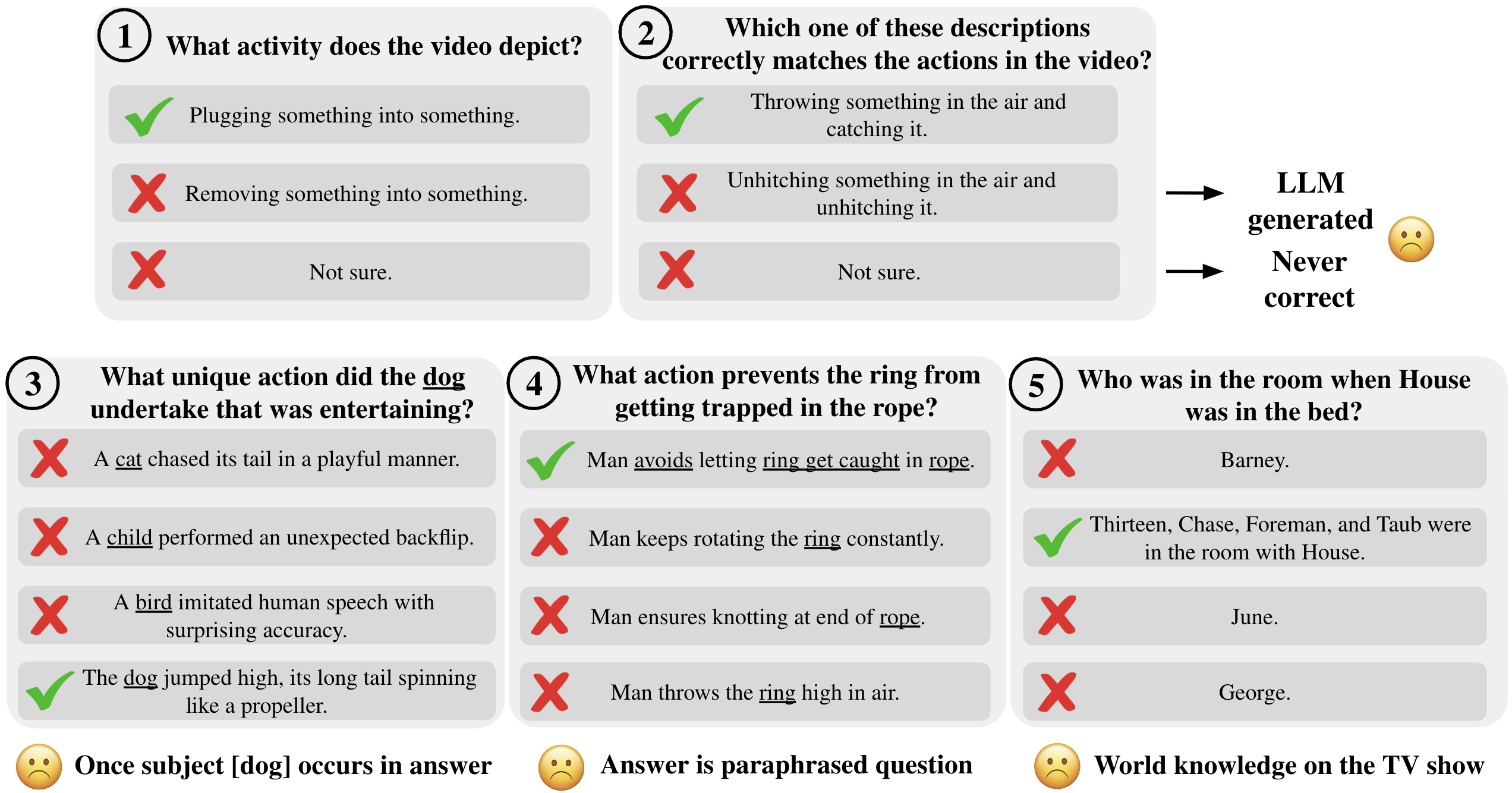
Figure 3: Textual bias of MVBench video-language benchmark. We show different tasks of MVBench and find that questions can be answered without taking the visual part into account.
Discussion
TVBench effectively highlights the limitations of current models and benchmarks in evaluating the temporal aspect of video understanding. The stark performance drop on TVBench compared to MVBench underscores the latter's inadequate temporal challenges. TVBench serves as a robust tool for future advancements in temporal video-LLM evaluation.
Conclusion
TVBench addresses critical shortcomings in existing benchmarks by focusing on temporal reasoning, providing a necessary tool for progressing video-LLM assessment. As video understanding models advance, TVBench can guide researchers in developing innovations that genuinely understand and reason through temporal video sequences, enhancing the field's evaluation standards.
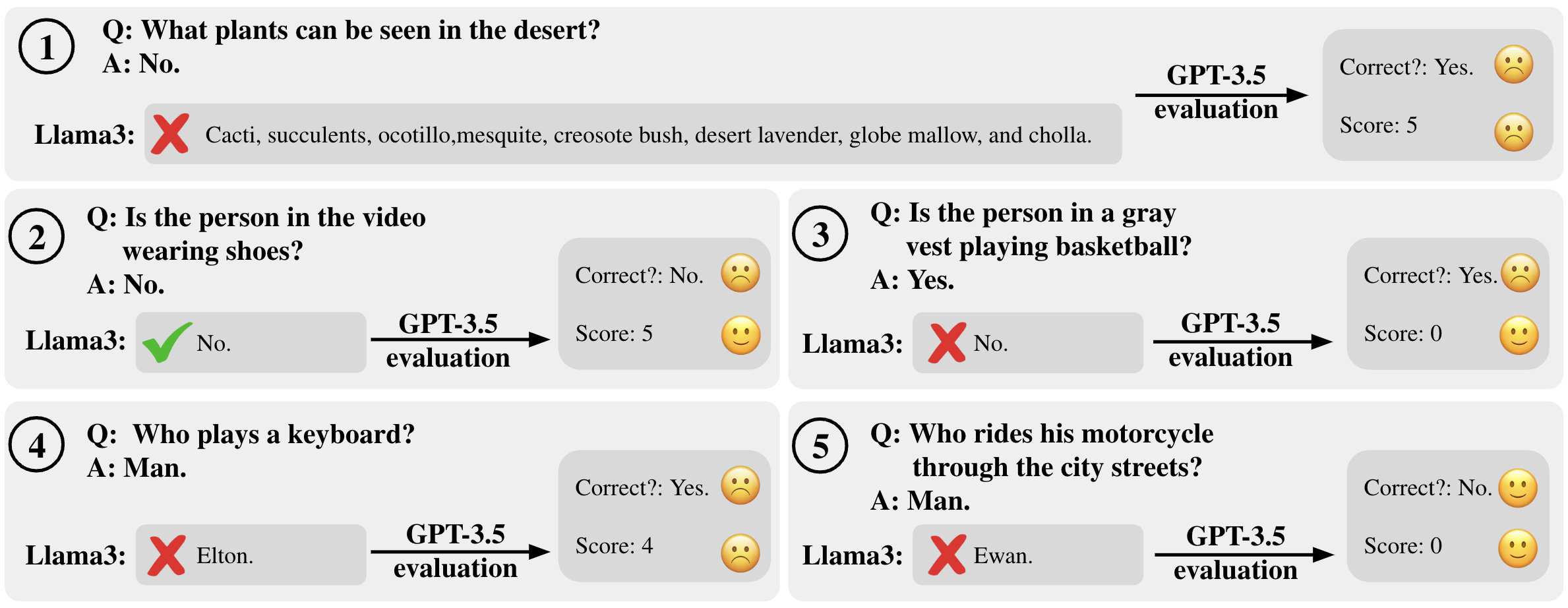
Figure 4: Unreliability of open-ended video-language benchmarks. GPT 3.5 is commonly used as an evaluator of open-ended responses, here we use Llama 3 in a text-only setting to generate answers. GPT gives confusing accuracies and scores. Smiley emoji shows truthful or unreliable evaluation from GPT 3.5.

