- The paper introduces a self-adaptive framework that dynamically selects GNN experts using a topology-aware sparse attention mechanism.
- It employs a diverse pool of models, including GCN, GAT, and GraphSAGE, and integrates an efficient pruning strategy to optimize computational resources.
- Experiments across 16 benchmarks show that SAGMM achieves competitive performance in node/graph classification and link prediction tasks.
Self-Adaptive Graph Mixture of Models
Introduction
Graph Neural Networks (GNNs) are prominent in handling graph-structured data, yet their performance enhancements are peaking, as traditional models like GCN and GAT achieve comparable results to more sophisticated architectures when optimally tuned. This suggests challenges in selecting suitable models for diverse graph datasets. The Self-Adaptive Graph Mixture of Models (SAGMM) framework proposes a modular approach to dynamically choose and integrate appropriate GNN models by utilizing architectural diversity and topology-aware attention. The approach includes an efficient pruning method, maintaining performance while reducing active experts, and features a training-efficient variant with pretrained experts.
Methodology
Framework Overview
SAGMM stands out by incorporating a diverse array of expert models to exploit varied architectural features, thus enhancing expressiveness. The framework's success lies in dynamically choosing relevant GNN models for graph tasks through a topology-aware sparse attention mechanism, which directs tasks to the most suitable experts at a node level.
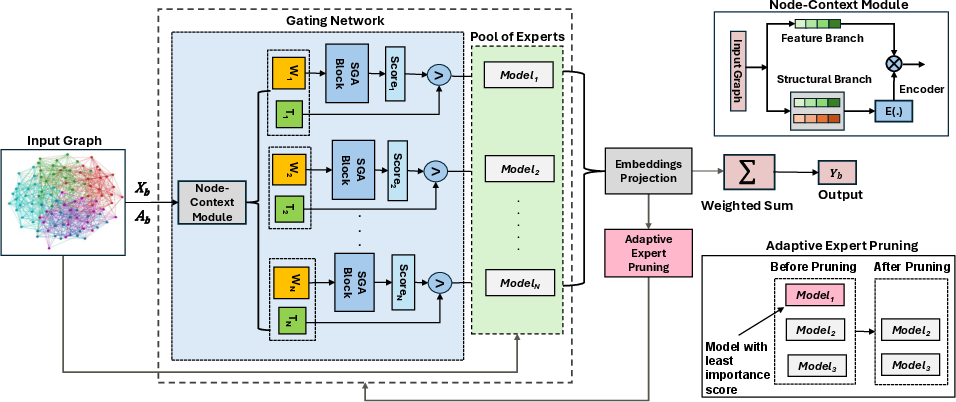
Figure 1: The overall illustration of the SAGMM\ framework. The key components includes the gating network, a pool of experts, and an adaptive expert pruning.
Pool of Experts
SAGMM employs experts like GCN, GAT, and GraphSAGE, capitalizing on their individual strengths related to spectral filtering, attention mechanisms, and inductive capabilities, respectively. The emphasis is on capturing a broad perspective of the graph's structural and statistical characteristics, aligning with the bias-variance tradeoff and the No Free Lunch theorem.
Topology-Aware Attention Gating (TAAG)
The TAAG mechanism surpasses traditional gating by accounting for local and global structural information and adaptively varying activated experts. This mechanism integrates Simple Global Attention to manage large graphs efficiently, emphasizing both immediate and expansive structural attributes.
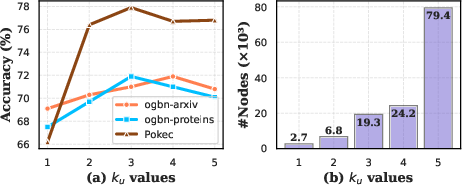
Figure 2: (a) Performance variation across different Top-k values in GMoE-GCN for various datasets. (b) Distribution of expert activation counts by SAGMM for ogbn-proteins dataset, which contains 132,534 nodes.
Experiments
Performance Evaluation
SAGMM's performance was rigorously evaluated on 16 benchmark datasets, revealing its superiority or parity with leading GNN models in tasks including node and graph classification, regression, and link prediction. SAGMM's diverse model exploitation allows it to outperform traditional models as well as other mixture-based methods.
Efficiency
SAGMM manages resources efficiently by employing a pruning strategy that minimizes active experts without sacrificing model efficacy. This approach underlines the framework's prowess in combining diverse insights while economizing computational resources.
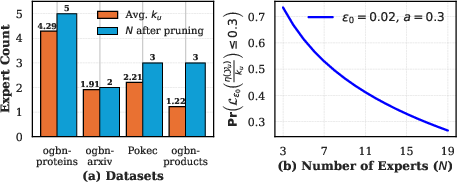
Figure 3: (a) Average number of experts activated per node u (ku) and experts remaining post-pruning (N). (b) Visualization of the Pr {L(kuη(Yu))≤a} (Theorem 1) for ϵ0=0.001,a=0.3.
Conclusion
SAGMM demonstrates significant adaptability and efficiency in utilizing architectural diversity within GNN frameworks to manage complex graph learning tasks, showing potential for further extensions involving dynamic graph handling or expert distillation. The model's ability to integrate pretrained GNNs offers a data-efficient alternative for tasks requiring diverse structural insights. Future iterations may focus on expanding adaptability across different types of graph structures and dynamic graphs, broadening SAGMM's applicability in real-world scenarios.


