Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Abstract: We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for AI models to turn text (and sometimes a reference image) into high-quality pictures. The authors call their method “Mixture of States” (MoS). It’s like a smart “traffic controller” that decides, at every moment, which pieces of information from a LLM should guide the image-making process. This makes the model better at matching words to visuals and doing precise edits.
What goals or questions did the researchers have?
The paper focuses on solving three main problems in text-to-image and image editing:
- Can we make the model pick the best information from different layers of the LLM, instead of always using a fixed layer?
- Can the guidance from text change over time to match the image’s step-by-step creation process (which cleans noise gradually)?
- Can each word (token) get its own custom guidance, instead of using one shared setting for the whole sentence?
In simple terms: they wanted the model to be flexible, time-aware, and specific to each word.
How did they do it?
To explain the approach, here’s a simple breakdown with everyday analogies:
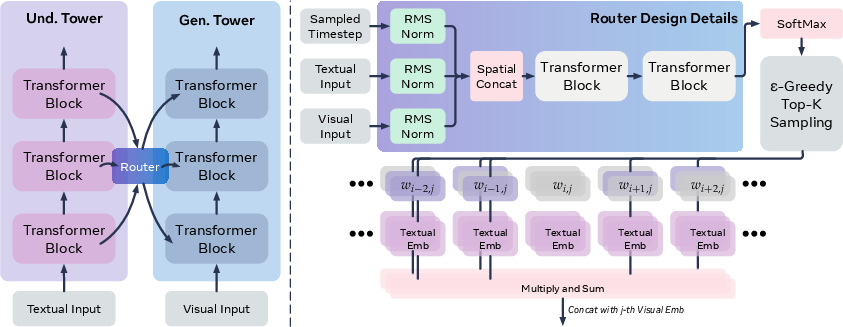
- Two towers:
- The “Understanding” tower reads the text (and the reference image, if editing). Think of it like a reader that builds detailed notes at many levels.
- The “Generation” tower makes the picture step by step, starting from noisy “static” and slowly cleaning it up into a clear image (this is how diffusion works).
- Hidden states:
- As the understanding tower reads your prompt, it creates “hidden states” at each layer—like snapshots of what it thinks the words mean at different depths.
- Tokens:
- Tokens are the little chunks that make up the text (like words or pieces of words).
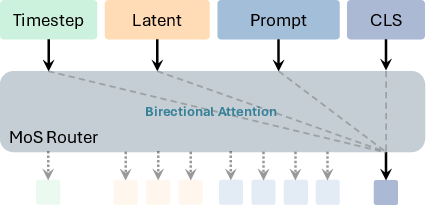
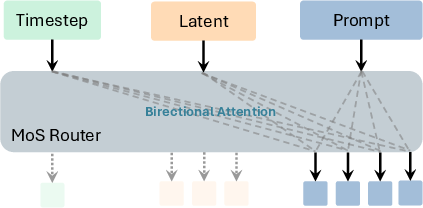
- The router (MoS):
- The router is a small, smart module that decides, for each token and at each step of image creation, which layers of understanding are most helpful for the current image-making layer.
- It looks at three things: the text prompt, the current “noisy” image state, and the current step (time) in the cleaning process.
- It outputs a score matrix that says: “For this token, send information from these text layers to these image-making layers.”
- Top-k selection: Instead of mixing everything, it picks only a few of the most useful layers (“top-k”)—like choosing the best lanes in traffic.
- ε-greedy (epsilon-greedy): During training, it sometimes explores random choices to avoid getting stuck in a bad habit—like trying a new route occasionally.
- Training:
- The generation tower is trained to turn noise into a picture that matches the text. The understanding tower is usually frozen (not changed), which saves a lot of compute.
- The training teaches the router to pick the right guidance at the right time, so the image lines up better with the prompt.
Quick glossary of key terms
- Diffusion: A method where the model starts with a noisy image and cleans it step by step to produce a clear picture.
- Token: A small piece of text, like a word or sub-word.
- Hidden state: The model’s internal “note” about tokens at different layers.
- Router: A small module that decides how to combine information across models, layers, and tokens.
- Top-k: Pick only the best few options, not all.
- ε-greedy: Sometimes explore random choices during training to learn better.
What did they find, and why is it important?
The main discoveries:
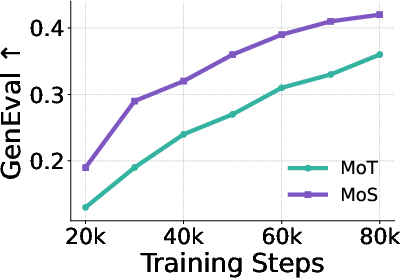
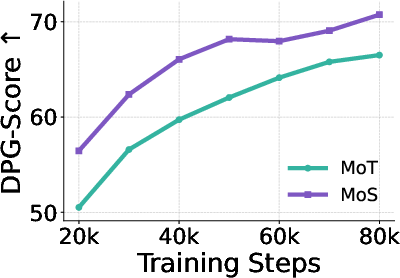
- Adaptive layer selection beats fixed rules: Letting the router pick different text layers for different image-making layers works better than rigid designs that always use the final text layer or match layers one-to-one.
- Time-aware guidance helps a lot: Making the router consider the current denoising step (how noisy the image is) improves results. Static text features don’t match a dynamic image process as well.
- Token-specific routing matters: Each word gets its own guidance plan, which improves accuracy (for example, “red hat on the left person” vs. “blue shirt on the right person”).
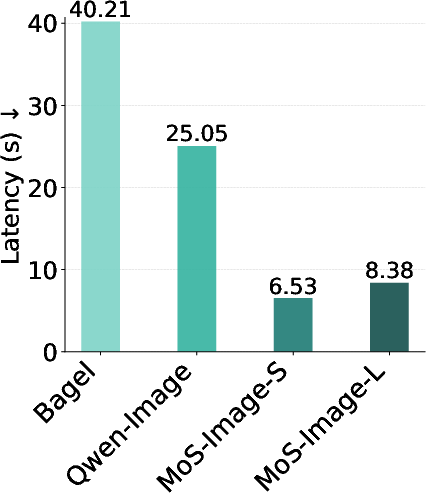
- Strong performance with fewer parameters: With around 3–5 billion learnable parameters, MoS matches or beats some models that are up to 4× larger (like 20B). That means better efficiency.
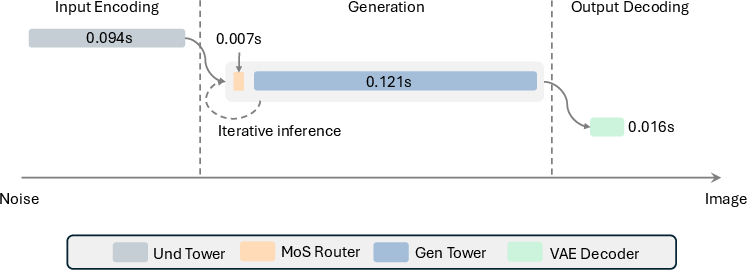
- Fast and light: The router adds almost no extra delay during image generation, but boosts quality and control.
On standard tests (like GenEval, DPG, WISE, and OneIG), MoS often reaches state-of-the-art scores. In image editing benchmarks (ImgEdit, GEdit), it also does extremely well, producing precise edits that follow instructions closely. Training uses roughly half the compute of some earlier large models, showing its efficiency.
What could this change?
- More accurate and controllable image generation: Better alignment between words and visuals means models that follow prompts more precisely (e.g., colors, counts, positions, styles).
- Smarter, scalable multimodal systems: The router lets different models (text and vision) work together even if they don’t have the same size or shape. This flexibility makes building future AI systems easier and cheaper.
- Strong editing tools: Because MoS can combine text and reference images well, it can make fine, guided changes without losing the original style or content.
- Efficient progress: High-quality results with fewer parameters and less training compute can help more teams build capable models responsibly.
A note on limitations and future ideas
- The paper mostly uses one-way routing (from understanding to generation). Two-way cooperation could make future systems even better.
- It doesn’t focus on preference tuning (like making images that people consistently prefer). Adding methods like reinforcement learning or better instructions could help.
- Further speed-ups (like quantization or distillation) could make it even faster.
- The router’s choices could help explain what the model is doing, but deeper analysis is left for future work.
- Like other models, it can still produce artifacts in very small or complex objects—an ongoing challenge in generative AI.
Overall, Mixture of States shows a simple but powerful idea: let the model flexibly choose the right information at the right time, for each token, during image creation. That makes multimodal generation sharper, more reliable, and more efficient.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is framed to guide actionable future research.
- Validate bidirectional routing: MoS is currently one-way (understanding → generation); the effectiveness and design of dual-way or fully bidirectional routing between asymmetric towers remains untested, including how to project generation states back into the understanding tower and how to avoid destabilizing joint training.
- Early-fusion joint training: The paper freezes the understanding tower; it is unknown how MoS performs when both towers are trained jointly (early fusion), what schedules are stable, and whether catastrophic interference or gradient dominance occurs.
- Router gating alternatives: Top-k selection with ε-greedy exploration lacks comparison to differentiable sparse gating (e.g., Gumbel-Softmax, sparsemax/entmax), RL-based routing, load-balancing penalties, or stochastic routers; it is unclear which yields better stability, sparsity, and performance.
- Theoretical analysis: There is no formal characterization of router convergence, gradient flow through hard selection, or guarantees on sparsity/selection optimality; analyses of bias/variance trade-offs introduced by ε-greedy sampling are missing.
- Hyperparameter sensitivity: The choice of k, ε, annealing schedules, and per-block vs global-k are not systematically studied across scales/tasks; robust guidelines and automatic tuning strategies are lacking.
- Memory and compute scaling: While latency is profiled, peak memory and per-token routing cost (producing an m×n logit matrix per token) are not analyzed for long prompts or deeper towers; scaling behavior with sequence length, tower depths, and batch size needs measurement and mitigation strategies.
- Routing granularity: The router aggregates full hidden states; alternatives such as routing key–value caches, subspace components (e.g., low-rank directions), or token substructures (e.g., heads/channels) are unexplored.
- Router inputs: The router conditions on c, z_t, t; the value of including additional dynamic signals (e.g., current block activations, predicted velocity v_t, guidance scale, or cross-step memory) is untested.
- Step-dependent behavior: Beyond visualizations, there is limited analysis of learned timestep-specific routing policies (e.g., early vs late steps) and whether explicit curricula or monotonicity constraints improve performance.
- Load balancing and layer utilization: It is unclear whether routing collapses onto a small subset of layers or achieves healthy layer coverage; diagnostics and regularization for balanced utilization are missing.
- Robustness and OOD prompts: Performance under long, compositional, multilingual, or adversarial prompts, and highly structured input constraints (e.g., programmatic specs) is not evaluated; failure modes and robustness interventions remain unknown.
- Multilingual conditioning: The understanding towers suggest multilingual capability, but MoS’s performance on non-English prompts and cross-lingual editing/generation is not reported.
- Compositional and small-object fidelity: The paper notes artifacts for very small objects; targeted evaluations and architectural remedies (e.g., multi-scale routing, local attention, supervision for small-object accuracy) are not provided.
- Identity and attribute preservation in editing: Systematic evaluation of identity preservation across sequential edits, fine-grained attribute consistency, and localized edits (mask-based, region-aware routing) is missing.
- Human evaluation: Editing scores rely on GPT-4o judgments; controlled human A/B testing, inter-rater reliability, and cross-demographic preference alignment assessments are absent.
- Safety, bias, and data governance: Dataset composition, licensing, demographic coverage, and potential biases are not detailed; safety alignment (harmful content, jailbreak prompts) and fairness auditing are not addressed.
- Reproducibility and data transparency: Precise data sources, filtering criteria, and release plans for training/evaluation datasets and model checkpoints are not provided, impeding reproducibility and controlled comparisons.
- Controlled baselines: Many comparisons differ in data/compute; tightly controlled experiments (same data budget, same compute, same VAE/backbone) are needed to isolate MoS’s contribution from underlying components.
- Generalization to other modalities: MoS is motivated as a general multimodal paradigm but tested only on text–image/image-editing; extensions to video, audio, 3D, or multi-image conditioning and their timestep analogs (e.g., per-frame routing) remain unexplored.
- Larger-scale scaling laws: Ablations are done at small scales; it is unclear if token-specific routing and step-aware conditioning benefits persist or saturate at larger towers and datasets.
- Inference-time behavior: Deterministic top-k at inference may be brittle; calibration (e.g., temperature, entropy constraints), uncertainty estimation, and routing ensembles are not studied.
- Caching and efficiency: Feature/state caching across timesteps, dynamic skipping, or partial recomputation strategies for the router are not explored; end-to-end throughput under typical batch sizes and multi-GPU settings is unreported.
- Projection design: The linear projection from routed states to generation hidden size lacks sensitivity analysis (initialization, capacity, nonlinearity choices) and alternatives (e.g., adapter stacks, gated fusion).
- Integration with preference optimization: The paper notes SFT-only post-training; whether GRPO/RLHF, instruction distillation, or CoT-based captioning integrated during training improves alignment systematically is open.
- Interpretability tooling: Although MoS affords interpretable layer/token routing, there is no framework to quantify or visualize cross-modal information flow, causal attributions, or how routing correlates with semantic roles.
- Failure taxonomy: Beyond small-object artifacts, a comprehensive error taxonomy (e.g., text rendering, spatial relations, world knowledge hallucination, occlusions, long-range dependencies) and targeted remedies is missing.
- Privacy risks: Potential memorization of training data and mitigation strategies (e.g., DP training, watermarking, retrieval filters) are not addressed.
- Open-source and ecosystem: Code/weights availability, inference APIs, and standard benchmarks/prompt suites for MoS-specific evaluation are not announced, limiting community validation and extension.
Glossary
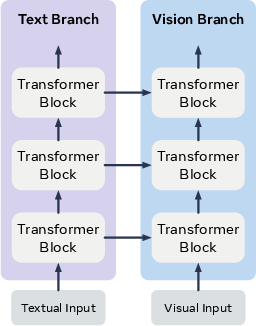
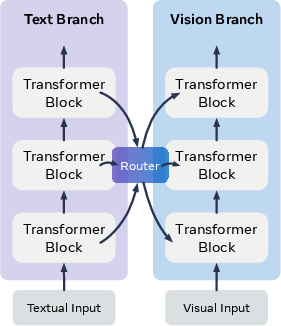
- Asymmetric transformers: Transformers with differing depths or hidden sizes used across modalities, requiring flexible interaction mechanisms. "We replace the rigid global attention mechanism with a learnable, sparse router, which removes the identical-size constraint and enables adaptive, effective interactions between {\it asymmetric} transformers."
- Bidirectional self-attention: Attention that allows tokens to attend to each other in both directions within a sequence. "We then apply two transformer blocks with bidirectional self-attention to capture in-context semantics."
- CLIP: A text–image model/score used to evaluate semantic alignment between captions and generated images. "We adopt FID \citep{heusel2017gans} and CLIP scores \citep{radford2021learning}, GenEval \citep{ghosh2023geneval} and DPG \citep{hu2024ella}, following a similar setup to \cite{esser2024scaling}."
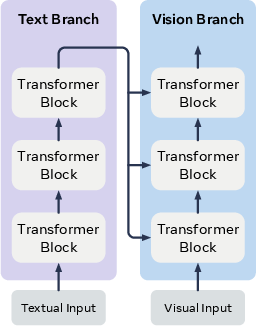
- Cross-attention: A mechanism where one modality’s queries attend to another modality’s key–value vectors to fuse information. "Cross-attention methods \citep{rombach2022high,vaswani2017transformer,chen2023pixart,xie2024sana} insert new attention blocks into the visual model, projecting text embeddings onto key-value vectors to enable cross-modal token interactions."
- DiT (Diffusion Transformer): Transformer architectures tailored for diffusion-based generative modeling. "our model still faces issues similar to other DiT or unified models, such as producing artifacts when the generated objects are very small (see our visualizations)."
- Denoising timestep: The discrete time index in diffusion indicating the noise level and stage of the denoising trajectory. "a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states"
- DPG: A benchmark evaluating text-to-image grounding and prompt-following quality. "We adopt FID \citep{heusel2017gans} and CLIP scores \citep{radford2021learning}, GenEval \citep{ghosh2023geneval} and DPG \citep{hu2024ella}, following a similar setup to \cite{esser2024scaling}."
- Dual-tower architecture: A design with separate towers for understanding context and generating outputs. "MoS adopts a dual-tower architecture design for multimodal generation:"
- ε-greedy strategy: A training-time exploration technique that randomly selects actions with probability ε to avoid suboptimal convergence. "and is trained with an -greedy strategy"
- FID (Fréchet Inception Distance): A metric quantifying image quality by comparing feature distributions of real and generated images. "We adopt FID \citep{heusel2017gans} and CLIP scores \citep{radford2021learning}, GenEval \citep{ghosh2023geneval} and DPG \citep{hu2024ella}, following a similar setup to \cite{esser2024scaling}."
- Flow matching: A generative modeling objective that aligns data and noise flows without the full diffusion SDE. "visual models often adopt diffusion-based generation \citep{ho2020denoising,neal2001annealed,jarzynski1997equilibrium} or flow matching \citep{lipman2023flow,esser2024sd3}."
- GenEval: A benchmark for evaluating compositionality and instruction-following in text-to-image generation. "In Table \ref{tab:summary}, we report its performance on GenEval \citep{ghosh2023geneval}, DPG \citep{hu2024ella}, WISE \citep{niu2025wise}, and oneIG-EN \citep{chang2025oneig}."
- Generation tower: The transformer branch responsible for iteratively denoising and synthesizing visual outputs. "MoS adopts a dual-tower architecture design for multimodal generation: an {\it understanding} tower and a {\it generation} tower ."
- GRPO: A reinforcement learning method (Group Relative Policy Optimization) used to align model outputs with human preferences. "or employing GRPO \citep{shao2024deepseekmath} to better align generated samples with human preferences \citep{liu2025flow}."
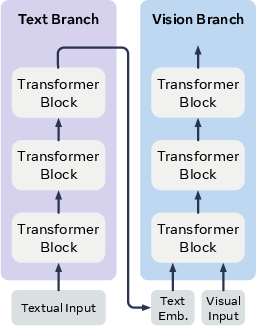
- In-context tokens: Tokens provided to a transformer block as conditioning alongside the main sequence to guide processing. "The projected features, , are then concatenated with ... along the sequence dimension and jointly processed as in-context tokens within the block."
- Key–value vectors: The key and value components used in attention mechanisms to parameterize what and how information is attended to. "projecting text embeddings onto key-value vectors to enable cross-modal token interactions."
- Latent diffusion framework: A diffusion approach operating in a compressed latent space (via a VAE) to enable efficient image generation. "we build our MoS-Image model upon the standard latent diffusion framework \citep{rombach2022high}"
- Logit matrix: An unnormalized score matrix whose entries control routing/selection decisions across layers. "the router generates a corresponding logit matrix "
- Mixture of States (MoS): A fusion paradigm with a learnable router that selects token-level hidden states across modalities and timesteps. "We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions."
- Mixture of Transformers (MoT): A multimodal architecture coupling separate transformers via shared attention at each corresponding block. "MoS is conceptually related to the Mixture of Transformers (MoT) architecture \citep{liang2025mixtureoftransformers}."
- Mixture-of-Depths (MoD): A dynamic architecture that allocates compute across tokens and layers adaptively. "Recent advances have explored other forms of dynamic computation, such as Mixture-of-Depths (MoD) \citep{raposo2024mixture}, which dynamically allocates compute across tokens and layers,"
- Mixture-of-Experts (MoE): A sparse routing approach that sends tokens to different expert sub-networks within a transformer. "A prominent example is the Mixture-of-Experts (MoE) \citep{hampshire1989connectionist,eigen2013learning,shazeer2017outrageously,lepikhin2020gshard,fedus2022switch,liu2023prismer,jiang2024mixtral,csordas2024moeut}, where tokens are adaptively processed by different "expert" sub-networks within each transformer block."
- Mixture-of-Recursions (MoR): A mechanism that reuses layers recursively with variable depth controlled by routing. "and Mixture-of-Recursions (MoR) \citep{bae2025mixture}, which reuses layers recursively with variable-depth routing."
- oneIG-EN: A text-to-image benchmark variant (English) assessing instruction-following and fidelity. "In Table \ref{tab:summary}, we report its performance on GenEval \citep{ghosh2023geneval}, DPG \citep{hu2024ella}, WISE \citep{niu2025wise}, and oneIG-EN \citep{chang2025oneig}."
- Patchify layer: A preprocessing layer that converts images into patch tokens for transformer processing. "The latent shares ’s patchify layer and is subsequently projected to the target dimensionality."
- Rectified flow matching: A training objective that matches velocities along a linear interpolation path between noise and data latents. "Following standard practice, the entire model is trained end-to-end with rectified flow matching:"
- Self-attention: Attention within a single sequence where tokens attend to each other, enabling contextual integration. "Self-attention methods \citep{esser2024scaling,chen2025dit,qin2025lumina} instead concatenate text and visual tokens into a unified sequence, processed by shared attention layers."
- Self-CoT: A self-generated chain-of-thought approach to produce reasoning-based captions for conditioning generation. "For instance, with self-CoT \citep{deng2025emerging}, the understanding model progressively generates a reasoning-based caption, which then serves as contextual guidance for the generation tower to synthesize images."
- Sinusoidal embeddings: Periodic embeddings used to represent continuous variables (e.g., timesteps) in a fixed-dimensional space. "The timestep is represented using sinusoidal embeddings \citep{ho2020denoising} and projected into the same latent space."
- SFT (Supervised Fine-Tuning): Post-training by supervised learning to refine model behavior. "In this paper, we primarily adopt SFT as the post-training strategy for our models."
- Softmax: A normalization function converting logits into probabilities across choices. "Specifically, in each forward pass, the predicted logits (for ) are normalized using softmax."
- Token-wise router: A routing module that makes selection decisions independently for each token. "The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states"
- Top- routing: Selecting the k highest-weighted options to enforce sparse computation and focus. "we implement a sparse top- routing strategy."
- Understanding tower: The transformer branch that processes context (text and/or image) to produce guidance states. "MoS adopts a dual-tower architecture design for multimodal generation: an {\it understanding} tower and a {\it generation} tower ."
- VAE encoder: The encoder of a Variational Autoencoder that maps images into a latent space. "The target latent is obtained from the VAE encoder ."
- Velocity (diffusion): The target derivative of the latent trajectory used in rectified flow matching training. "where $v_t=\nicefrac{dz_t}{dt}= z_1 - z_0$ denotes the target velocity at denoising step ."
- WISE: A benchmark emphasizing world knowledge reasoning in text-to-image generation. "In Table \ref{tab:summary}, we report its performance on GenEval \citep{ghosh2023geneval}, DPG \citep{hu2024ella}, WISE \citep{niu2025wise}, and oneIG-EN \citep{chang2025oneig}."
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging MoS’s token-wise, timestep-aware routing, asymmetric tower fusion, and compute-efficient training/inference.
- Creative industries (media, entertainment, gaming)
- Text-to-image ideation at 1K–2K resolution with tighter prompt adherence
- Tools/workflows: an in-house “MoS-Image” creative assistant; a Diffusers-compatible MoS plug-in to swap cross-attn with MoS routing; batch generation with self-CoT prompt expansion for higher WISE-style knowledge tasks.
- Dependencies/assumptions: access to a frozen understanding tower (e.g., InternVL-14B) under a permissive license; content safety filters; GPU with sufficient VRAM (consumer 24–48GB for 1024–2048 px).
- High-fidelity layout and text-in-image rendering for posters, covers, and title cards
- Tools/workflows: InDesign/Photoshop/Figma plug-ins that exploit token-specific routing for accurate typography placement and attribute control.
- Dependencies/assumptions: prompt templates and QA checks for typography; brand safety guardrails.
- Advertising and marketing
- Brand-consistent ad creative and variant generation (colorways, backgrounds, seasonal motifs)
- Tools/workflows: “Brandboard-to-Ad” pipeline: ingest a style guide into the understanding tower; route style tokens dynamically per denoising step to preserve identity while altering context.
- Dependencies/assumptions: brand asset ingestion; approval workflows; content moderation.
- Multilingual prompt-to-visuals with improved attribute control
- Tools/workflows: localized campaign generator that couples a multilingual frozen VLM with a small MoS generator.
- Dependencies/assumptions: language coverage and quality in the understanding tower; localized compliance rules.
- Product design, fashion, CPG, and industrial design
- Rapid design iteration and material/finish swaps from a single reference image (instruction-based editing)
- Tools/workflows: “MoS-Edit API” for internal PDM/PLM systems to preview finishes, patterns, and trims; CAD-to-render moodboards.
- Dependencies/assumptions: curated reference photos; IP compliance for textures/patterns; human review before downstream manufacturing decisions.
- Photoreal synthetic product shots for e-commerce pages
- Tools/workflows: SKU-to-variant pipeline with batch MoS-Edit (lighting/background/staging changes) to reduce studio costs.
- Dependencies/assumptions: clear labeling of synthetic media; adherence to platform policies.
- E-commerce and retail
- On-the-fly listing images and A/B assets with precise attribute edits (e.g., “add winter scarf,” “change wood to walnut”)
- Tools/workflows: marketplace listing assistant integrating MoS-Edit; routing cache for popular prompts to cut latency.
- Dependencies/assumptions: per-market content policies; audit logs for edits.
- Social media and UGC platforms
- Creator tools for personal photo retouching, object insertion/removal, and stylization without masks
- Tools/workflows: mobile-friendly MoS-Edit endpoints; preset prompt packs (cinematic, magazine, vintage) parameterized by router weights.
- Dependencies/assumptions: mobile GPU/edge inferencing or efficient server endpoints; abuse detection and watermarking.
- Education and training
- Visual asset generation for lesson plans, worksheets, and diagrams from textual instructions
- Tools/workflows: LMS plug-in that drafts figures from curriculum text and iteratively refines visuals via self-CoT + MoS routing.
- Dependencies/assumptions: age-appropriate filters; fact-checking for domain-critical content.
- Accessibility
- Simplified visualizations and alternative image renditions adapted to user instructions
- Tools/workflows: accessibility assistant that converts complex images into high-contrast or simplified compositions via MoS-Edit.
- Dependencies/assumptions: integration with screen readers; user preference profiles.
- Software and ML infrastructure
- Drop-in fusion layer for existing diffusion stacks (compute-efficient upgrade)
- Tools/workflows: “MoS Router SDK” for Diffusers; Route-Inspector dashboard to visualize top-k layer/token routing over timesteps; feature caching for deterministic top-k.
- Dependencies/assumptions: alignment of hidden sizes via lightweight projections; model validation on internal datasets.
- Synthetic data generation for CV tasks (segmentation, OCR-like text rendering in images)
- Tools/workflows: dataset factory scripting dynamic token-wise control to place legible text and rare object combinations.
- Dependencies/assumptions: annotation tooling; careful domain-gap assessment.
- Policy, compliance, and governance
- Lower-compute generative pipelines aligned with sustainability targets
- Tools/workflows: procurement guidelines endorsing smaller generators with frozen understanding towers; carbon reporting tied to GPU hours.
- Dependencies/assumptions: reliable benchmarking of energy/carbon per image; verifiable compute claims.
- Auditable conditioning via router weight logs
- Tools/workflows: compliance dashboards storing routing matrices per sample for post-hoc audit/explanation.
- Dependencies/assumptions: secure logging; privacy-preserving metadata handling.
- Daily life
- Personal photo editing and design (holiday cards, posters, invitations)
- Tools/workflows: consumer app with instruction-only edits; prompt presets tuned for MoS’s timestep-dependent conditioning.
- Dependencies/assumptions: easy-to-use guardrails; compute budget for peak usage.
- Enterprise content ops
- Template-to-variant pipelines at scale (catalog updates, seasonal refreshes)
- Tools/workflows: workflow orchestration (Airflow/Prefect) + MoS-Edit batch jobs; human-in-the-loop QA and rejection sampling.
- Dependencies/assumptions: content rights management; SLA-backed inference.
- Research and academia
- Analysis of cross-modal alignment through router introspection
- Tools/workflows: experiments mapping tokens-to-layers over diffusion timesteps; ablations on ε-greedy/top-k to study exploration vs. convergence.
- Dependencies/assumptions: access to logs and visualization tooling; reproducible seeds and datasets.
Long-Term Applications
These rely on additional research, scaling, safety alignment, or engineering to be production-ready.
- Video generation and editing (media, entertainment, education)
- Frame- and token-aware routing across time for consistent character, layout, and typography in video
- Tools/products: “MoS-Video” with temporal routers; timeline-aware top-k routing; reference-video guided edits.
- Dependencies/assumptions: large-scale, high-quality video-text datasets; temporal consistency losses; memory-efficient training.
- Bidirectional multimodal co-reasoning
- Extending MoS to dual-way routing where generation states can influence understanding computations (early-fusion setups)
- Tools/products: interactive planning loops where the generator proposes visuals and the understanding tower critiques/refines.
- Dependencies/assumptions: architectural extensions for safe feedback; stability studies to avoid oscillations.
- On-device or edge deployment
- Small MoS generators paired with compact understanding towers for offline editing on laptops/phones
- Tools/products: int8/int4 quantized MoS; distillation into hybrid UNet/DiT backbones; feature caching across steps.
- Dependencies/assumptions: high-quality quantization recipes; mobile NPUs; battery/thermal constraints.
- Domain-specialized generation (healthcare, AEC, geospatial)
- Radiology-style anonymized synthetic data, architectural concept images, or map-style renderings using domain VLMs as understanding towers
- Tools/products: “Asymmetric Fusion Toolkit” to plug domain VLMs into a general MoS generator; regulatory audit trails via router logs.
- Dependencies/assumptions: strict compliance (HIPAA/GDPR); medical and safety validation; curated domain datasets; clear disclaimers on synthetic content.
- Robotics and embodied AI
- Multisensor fusion for sim-to-real: routing text/scene graphs/LiDAR summaries into a generative world model
- Tools/products: “MoS-Sim” for generating photoreal scenes with controllable affordances; curriculum generation for policy learning.
- Dependencies/assumptions: robust world-modeling objectives; safety constraints; integration with control stacks.
- AR/VR and digital twins
- Instruction-driven scene edits and texture synthesis inside immersive environments
- Tools/products: live MoS-Edit for headset UIs; token-wise edits linked to spatial anchors in 3D.
- Dependencies/assumptions: 3D-consistent diffusion; latency < 50–100 ms for comfort; 3D asset pipelines.
- Finance and insurance (indirect, content ops)
- Automated marketing collateral, document illustrations, and tutorial visuals with tight brand/legal control
- Tools/products: regulated content generator with approval chains, content provenance (C2PA) and router-based explainability.
- Dependencies/assumptions: robust watermarking/provenance; legal review loops; conservative prompt filters.
- Safety and preference alignment
- GRPO/RLHF-style alignment of MoS outputs to human aesthetic and safety preferences
- Tools/products: preference datasets; online A/B platforms; policy-tuned routers (penalize routes that yield unsafe content).
- Dependencies/assumptions: scalable human feedback; bias audits; red-team evaluations.
- Explainability and accountability
- Using routing matrices to build interpretable attributions of “which token/layer influenced which visual region and when”
- Tools/products: heatmap-based attributions over timesteps; compliance reports for regulated industries.
- Dependencies/assumptions: stable mapping from routing weights to spatial attributions; user studies on interpretability.
- Multimodal scientific communication
- Auto-generated figures from manuscripts with instruction-following for axes, annotations, and stylized schematics
- Tools/products: “Paper-to-Figure” assistant with MoS routing tuned on scientific corpora.
- Dependencies/assumptions: domain-correctness verification; citation and data-use policies.
- Content authenticity and provenance
- Router-aware watermarking or provenance signals tied to conditioning patterns
- Tools/products: watermark schemes that encode route signatures; anomaly detection for tampering.
- Dependencies/assumptions: robust, hard-to-remove signals; cross-platform standardization.
- Energy and sustainability
- Systematically replacing large 20B+ generators with asymmetric MoS stacks to reduce carbon/compute without quality loss
- Tools/products: migration playbooks; KPI dashboards on cost/energy per image; autoscaling policies tuned to MoS throughput.
- Dependencies/assumptions: equivalence testing on task KPIs; organizational buy-in.
- Education and tutoring systems
- Multimodal tutors that generate bespoke visuals from step-by-step reasoning traces
- Tools/products: self-CoT + MoS pipelines that convert reasoning to pedagogically aligned images.
- Dependencies/assumptions: pedagogy evaluation; content safety for minors; bias checks.
- Legal and policy tooling
- Public-sector content generation with strict auditability, lower compute budgets, and transparent conditioning
- Tools/products: government-grade MoS deployments with router logs retained for FOIA-style audits.
- Dependencies/assumptions: security accreditation; procurement compliance; privacy-by-design.
Notes on feasibility across applications:
- Data quality and licensing are pivotal: the understanding tower’s pretraining data and rights influence downstream risk.
- Safety, moderation, and provenance must be integrated from the outset for consumer or regulated deployments.
- Performance depends on VRAM/latency targets; 2K outputs may need server-side inference or advanced quantization/distillation.
- For domain-critical uses (e.g., healthcare), human oversight and validation are non-negotiable, and outputs should be labeled as synthetic.
Collections
Sign up for free to add this paper to one or more collections.

