- The paper introduces a unified diffusion architecture that processes both text and images with a shared probabilistic formulation.
- It employs mixed long chain-of-thought fine-tuning and a policy-gradient RL algorithm (UniGRPO) to enhance reasoning and generation tasks.
- Experimental results demonstrate that MMaDA surpasses state-of-the-art models in textual reasoning, multimodal understanding, and image synthesis.
MMaDA: A Unified Approach to Multimodal Foundation Models
The paper introduces MMaDA, a novel multimodal diffusion foundation model designed to perform well across textual reasoning, multimodal understanding, and text-to-image generation. MMaDA distinguishes itself through a unified diffusion architecture, a mixed long chain-of-thought (CoT) fine-tuning strategy, and a unified policy-gradient-based reinforcement learning (RL) algorithm called UniGRPO. The results demonstrate MMaDA's strong generalization capabilities, outperforming existing models in various tasks.
Unified Diffusion Architecture
MMaDA employs a unified diffusion architecture with a shared probabilistic formulation and modality-agnostic design. This eliminates the need for modality-specific components, ensuring seamless integration and processing across different data types. Specifically, MMaDA models both textual and visual data using a consistent discrete tokenization strategy, predicting discrete masked tokens for both modalities. An overview of the MMaDA pipeline is shown below.
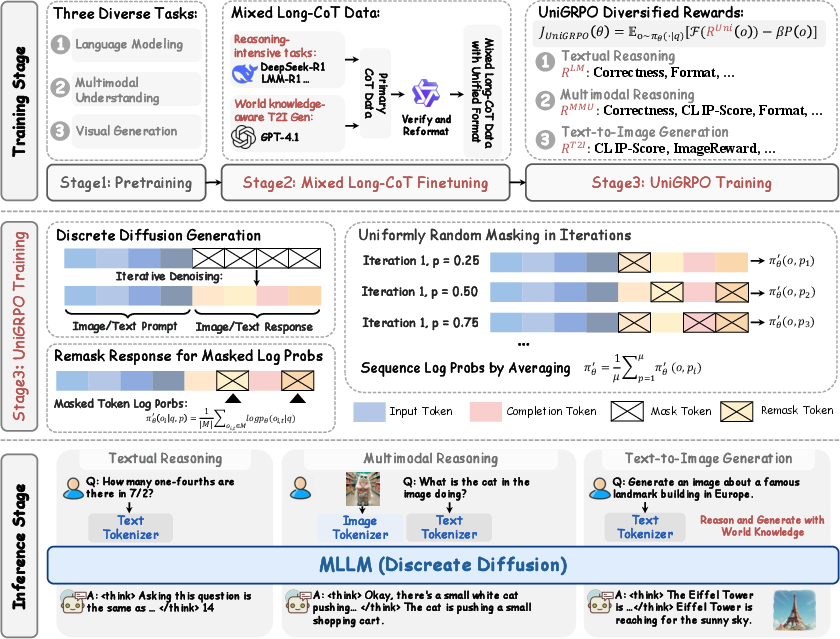
Figure 1: An overview of the MMaDA pipeline, illustrating the flow of data through the pretraining, mixed long-CoT finetuning, and UniGRPO post-training stages.
For text, the tokenizer from LLaDA is used, while for images, a pretrained image quantizer from Show-o, based on the MAGVIT-v2 architecture, converts raw pixels into discrete semantic tokens. The unified probabilistic formulation simplifies the architecture by using a unified diffusion objective to model both visual and textual modalities under a shared probabilistic formulation. The mask token predictor pθ(⋅∣xt) takes xt as input and predicts all masked tokens simultaneously, trained with a unified cross-entropy loss computed only on the masked image/text tokens:
$\mathcal{L}_{\text{unify}(\theta) = - \mathbb{E}_{t, x_0, x_t} \left[\frac{1}{t} \sum_{ i = 1 }^L I[x_t^i = [MASK]] \log p_{\theta}(x_0^i|x_t) \right]$
where x0 is the ground truth, t is the timestep, xt is the noised version of x0, and I[⋅] is the indicator function.
Mixed Long-CoT Fine-Tuning
To enhance post-training, MMaDA utilizes a mixed long chain-of-thought (CoT) fine-tuning strategy, curating a unified CoT format across modalities. The unified CoT format is:
∣<special_token>∣<reasoning_process>∣<special_token>∣<result>.
This format aligns reasoning processes between textual and visual domains, facilitating cold-start training for the subsequent RL stage. The mixed-task long-CoT finetuning jointly optimizes the model across heterogeneous tasks, enhancing task-specific capabilities and creating a strong initialization for subsequent reinforcement learning (RL) stages. The training process involves prompt preservation, token masking, joint input, and loss computation. The objective function is defined as:
$\mathcal{L}_{\text{Mixed-SFT} = - \mathbb{E}_{t, p_0, r_0, r_t} \left[\frac{1}{t} \sum_{i=1}^{L'} I[r_t^i = [MASK]] \log p_{\theta}(r_0^i | p_0, r_t) \right]$
where L′ denotes the sequence length and [p0,rt] corresponds to the clean data x0 and its noisy counterpart xt, respectively.
Unified Reinforcement Learning (UniGRPO)
MMaDA introduces UniGRPO, a unified policy-gradient-based RL algorithm tailored for diffusion foundation models. UniGRPO leverages diversified reward modeling to unify post-training across both reasoning and generation tasks, ensuring consistent performance improvements. UniGRPO captures the essential multi-step denoising dynamics of diffusion models and simplifies the optimization objective as follows:
$\mathcal{J}_\text{\normalfont UniGRPO}(\theta) = \mathbb{E}_{o\sim\pi_\theta(\cdot|q)}[\mathcal{F}(R^{\text{\normalfont Uni}(o))-\beta P(o)]$
where RUni(o) denotes the reward obtained from the model-generated response o, and P(⋅) is the penalty term, which denotes the KL divergence. Different rewards are defined under the unified formulation for different tasks, including textual reasoning rewards, multimodal reasoning rewards, and text-to-image generation rewards. This two-pronged approach enables a diffusion-centric RL training framework that unifies task-specific objectives across diverse modalities and reasoning paradigms.
Experimental Results
The experimental results demonstrate MMaDA's capabilities across three critical tasks: textual reasoning, multimodal understanding, and text-to-image generation. MMaDA-8B surpasses powerful models like LLaMA-3-7B and Qwen2-7B in textual reasoning, outperforms Show-o and SEED-X in multimodal understanding, and excels over SDXL and Janus in text-to-image generation. Ablation studies validate the effectiveness of the Mixed Long-CoT fine-tuning and UniGRPO stages. The synergy across modalities is illustrated below.
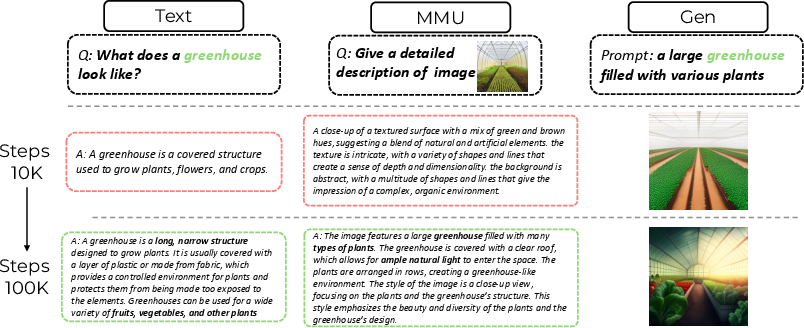
Figure 2: Qualitative Illustration of Synergy Across Modalities, highlighting the mutually beneficial nature of the unified training framework across text generation, multimodal understanding, and image generation.
Furthermore, MMaDA exhibits flexible sampling strategies at inference time, including semi-autoregressive sampling for text generation and parallel non-autoregressive sampling for image generation. Ablation studies demonstrate the impact of different masking strategies and the benefits of uniformly random masking. MMaDA also demonstrates a natural ability to perform inpainting and extrapolation without additional fine-tuning.
Conclusion
The work presents MMaDA, a unified diffusion foundation model that integrates textual reasoning, multimodal understanding, and generation within a single probabilistic framework. MMaDA systematically explores the design space of diffusion-based foundation models and proposes novel post-training strategies. The results highlight the potential of diffusion models as a next-generation foundation paradigm for multimodal intelligence.