MoGA: Mixture-of-Groups Attention for End-to-End Long Video Generation
Abstract: Long video generation with Diffusion Transformers (DiTs) is bottlenecked by the quadratic scaling of full attention with sequence length. Since attention is highly redundant, outputs are dominated by a small subset of query-key pairs. Existing sparse methods rely on blockwise coarse estimation, whose accuracy-efficiency trade-offs are constrained by block size. This paper introduces Mixture-of-Groups Attention (MoGA), an efficient sparse attention that uses a lightweight, learnable token router to precisely match tokens without blockwise estimation. Through semantic-aware routing, MoGA enables effective long-range interactions. As a kernel-free method, MoGA integrates seamlessly with modern attention stacks, including FlashAttention and sequence parallelism. Building on MoGA, we develop an efficient long video generation model that end-to-end produces minute-level, multi-shot, 480p videos at 24 fps, with a context length of approximately 580k. Comprehensive experiments on various video generation tasks validate the effectiveness of our approach.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MoGA: Making Long, Consistent Videos Faster and Smarter
What is this paper about?
This paper introduces a new way to make long, high‑quality videos using AI. The method is called Mixture‑of‑Groups Attention (MoGA). It helps AI models focus on the most important parts of a video so they can create minute‑long videos that stay consistent (same characters, clothes, backgrounds) without using huge amounts of computing power.
What problems are the authors trying to solve?
- Modern video AIs use a technique called “attention” to decide which parts of a video matter most. But regular attention compares everything with everything else, which is extremely slow for long videos.
- Previous shortcuts grouped video pieces into big blocks and guessed which blocks were important. That’s faster but often misses details or long‑range connections (like the same character across different scenes).
- The goal: keep the video consistent over time (especially across multiple shots), keep quality high, and make the process efficient enough to handle very long videos.
How does their approach work? (In simple terms)
Think of the AI making a video like a huge group conversation:
- Regular attention = everyone talks to everyone at once. That gets messy and slow.
- Old sparse methods = people are seated at big tables (blocks), and you only talk within the top few tables. Fast, but you might miss talking to the right people.
- MoGA = a smart “router” assigns each person to a small, relevant group based on what they’re talking about. Then people talk only within their group. This keeps the important conversations happening without the chaos.
Here’s what they do under the hood:
- Tokens: The video is broken into many tiny pieces of information (tokens). Think of tokens as puzzle pieces that represent small parts of frames across time.
- Router: A very lightweight tool (just a simple linear layer) looks at each token and assigns it to one of several groups. Tokens with similar meaning (like the same character’s face or hand across frames) tend to go to the same group.
- Group attention: The model runs full attention within each group only (not across all tokens). This cuts computing cost dramatically while keeping the right long‑range connections.
- Balancing: They add a small “group balancing loss” so the router doesn’t send almost everything to one group. It’s like making sure each table has a fair number of people.
- Local detail too: Alongside MoGA’s long‑range grouping, they also use local spatiotemporal windows (nearby pixels and nearby frames) to keep sharp details and smooth motion. This combo gives both global consistency and local clarity.
- Shot‑level text control: For multi‑shot videos (like mini‑movies), they let each shot have its own short text instruction. That helps the model know when and how to change scenes or actions at the right time.
They also built a data pipeline:
- They collect and clean long videos, split them into shots, remove watermarks/subtitles, and generate captions.
- Then they merge shots into multi‑shot training samples (up to about a minute) so the model learns cross‑shot consistency.
What did they test and how?
- They plugged MoGA into two strong video transformer backbones and trained them end‑to‑end.
- They measured things like:
- Subject consistency: does the same person look the same across frames/shots?
- Background consistency: do environments stay consistent?
- Motion smoothness: is movement fluid or jittery?
- Aesthetic/image quality: does it look good and clean?
- Cross‑shot similarity: are features consistent across different shots?
They compared MoGA to:
- Full attention (the standard but expensive method),
- Other sparse attention methods,
- Multi‑stage pipelines (that first make key frames, then fill in the rest).
What are the main results?
- Longer videos, end‑to‑end: The MoGA systems can generate minute‑level, multi‑shot, 480p videos at 24 fps, with extremely long context (about 580,000 tokens).
- Better or on‑par quality with much less compute: Even with high sparsity (over 70% fewer attention connections), MoGA matches or beats full attention and other sparse methods on many metrics.
- Strong consistency across shots: Characters and scenes stay coherent from shot to shot, which is hard for long videos.
- Big speedups and efficiency: For example, on 30‑second videos, they report around 1.7× faster training/inference and much lower FLOPs (a measure of computational work), without extra memory overhead.
- Plays nicely with modern tools: MoGA integrates with fast attention kernels like FlashAttention and with sequence parallelism, so it fits into current high‑performance training setups.
Why is this important?
- Long video generation is tough because keeping the story, characters, and environments consistent over time is hard and expensive. MoGA makes this feasible by being smart about who “talks” to whom inside the model.
- It avoids the weaknesses of block‑based guessing by precisely routing tokens to semantic groups, which leads to better long‑range understanding.
- It scales: MoGA’s design means as videos get longer, compute doesn’t explode uncontrollably.
- It improves control: Shot‑level prompts help direct scene changes at the right times, enabling more realistic, story‑like videos.
What could this lead to?
- More reliable AI tools for filmmaking, advertising, education, and animation where multi‑scene stories matter.
- Longer, coherent videos created directly from text instructions, without stitching together multiple stages.
- A general recipe for efficient attention in other long‑sequence tasks, like long documents, music, or 3D simulations.
In short: MoGA groups related video pieces so the model focuses on the right connections. That makes long videos both more consistent and much faster to produce—bringing AI‑generated mini‑movies a big step closer to reality.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open problems the paper leaves unresolved, framed to guide future research:
- Differentiability of routing: The method uses hard argmax group assignment; how are gradients handled through routing (e.g., straight-through, soft routing, or Gumbel-softmax)? What are the stability and convergence implications?
- Cross-group information flow: MoGA restricts attention to intra-group interactions; what mechanisms (e.g., top-2 gating, periodic cross-group mixing, low-rank cross-group attention, or learned inter-group bridges) best restore critical long-range dependencies missed by hard partitioning?
- Adaptive group count and placement: The number of groups M is static and globally set; can M be adapted per layer, head, shot, or timestep (noise level), or learned online to match token distribution and content complexity?
- Load balancing loss design: Sensitivity of the balancing weight α, layer-wise weighting, and risk of over-uniform routing that harms semantics are not analyzed; what regularization schedules or temperature annealing minimize collapse without erasing meaningful clusters?
- Temporal routing consistency: Group assignments may fluctuate across frames and diffusion timesteps; can temporal smoothness constraints, routing caches, or consistency losses reduce routing “thrashing” without degrading adaptability?
- Router capacity and conditioning: Only a single linear projection is explored; how do deeper routers, residual MLPs, or conditioning on timestep/noise level, shot index, text embeddings, or motion features affect quality vs. overhead?
- Soft and multi-group routing: Tokens are routed to a single group; does soft assignment or top-k multi-group routing (with load-aware caps) improve recall of long-range relations and reduce failure cases?
- Worst-case complexity and tail latency: Theoretical bounds assume uniform assignment; what are the worst-case FLOPs/memory under imbalanced routing, and how do they affect tail latency and stability in practice?
- Sequence-parallel communication overhead: The permutation/re-permutation and gather/scatter operations under sequence parallelism are not profiled; what is the communication cost relative to attention savings across GPUs and kernels?
- Cross-modal attention sparsity: Visual attention is sparsified, but cross-modal attention remains dense; is cross-modal sparsification (e.g., grouped or retrieval-style conditioning) a bottleneck and how does it impact controllability?
- Long-duration quantitative evaluation: Results beyond 30 seconds are mainly qualitative; provide objective metrics (e.g., per-minute drift, identity persistence curves, failure rates) for 60+ seconds and stress tests near the 580k context limit.
- Scaling to higher resolution and durations: Feasibility and resource scaling for 1080p/4K and multi-minute or hour-long generation are not addressed; what are the memory/compute trade-offs and quality inflection points?
- Compute- and data-matched baselines: Several comparisons use differing backbones, training regimes, or compute; include FLOPs- and data-matched baselines (e.g., MoBA/VMoBA/SVG variants) across durations for fair attribution of gains.
- Quantitative ablation of MoGA vs. STGA: The interplay is shown qualitatively; provide controlled, metric-based ablations isolating MoGA and STGA contributions (local fidelity vs. cross-shot consistency) under equal compute.
- Robustness to data pipeline noise: Shot detection errors and caption noise are likely; quantify sensitivity to mis-segmentation, transition overlaps, and caption inaccuracies, and test robustness strategies.
- Data transparency and reproducibility: Details on data composition, licensing, release of shot-level annotations/captions, and filtering thresholds are limited; provide artifacts and protocols to ensure reproducibility.
- Human evaluation for narrative coherence: Current metrics (VBench, CLIP/DINO) may not capture story flow or temporal logic; add human studies and narrative coherence/continuity scales tailored to long-form video.
- Identity re-identification metrics: Subject consistency is reported via VBench; include face/body re-ID metrics across shots to more directly assess identity preservation and confusion in multi-character scenes.
- Control over shot timing and transitions: The method uses shot-level text but lacks explicit timeline/transition control (e.g., cuts, fades, match cuts); design interfaces and losses for precise temporal editing/alignment.
- Routing reuse and caching across diffusion steps: Routing is likely recomputed each denoising step; can routing caches or gradual updates reduce overhead and stabilize attention patterns across timesteps?
- Training from scratch vs. fine-tuning: The approach is evaluated via fine-tuning pre-trained models; what data/compute are required for training-from-scratch, and how do learning curves and router emergence behave?
- Failure case taxonomy: Provide systematic analysis (with examples) of when MoGA harms local detail, misses cross-shot links, or over-regularizes, and diagnostics to detect/mitigate misrouting.
- Safety and bias assessment: VQA/OCR filtering may bias content; evaluate demographic fairness, sensitive content risks, and domain biases in long-form outputs, and propose mitigation strategies.
- Kernel and hardware portability: Integration is shown with FlashAttention; characterize performance across different kernels, hardware (A100/H100/TPU), and quantization/memory-optimization settings, including permutation overheads.
- Task and modality generalization: Claims of general sparse attention are not validated beyond video; test MoGA on audio-video synchronization, video-language tasks, 3D/NeRF video, or long-context text/image generation.
Practical Applications
Overview
The paper introduces MoGA (Mixture-of-Groups Attention), a kernel-free sparse attention mechanism that uses a lightweight, learnable token router to assign tokens into semantically coherent groups and applies full attention within each group. This design reduces attention complexity from O(N²) to approximately O(N²/M), scales end-to-end Diffusion Transformer video generators to minute-level, multi-shot outputs (480p, 24 fps, ~580k context length), and remains compatible with FlashAttention and sequence parallelism. The method is coupled with spatiotemporal windowed attention (STGA) for local fidelity and a data pipeline for dense multi-shot captions and clean shot segmentation. Experiments demonstrate improved cross-shot consistency, motion smoothness, and visual quality at high sparsity levels.
Below are actionable, sector-linked applications and workflows derived from the paper, grouped into immediate and long-term opportunities. Each item includes assumptions and dependencies that may affect feasibility.
Immediate Applications
These can be piloted or deployed now, especially by organizations with access to GPU infrastructure and existing DiT-based video pipelines.
- Media & Entertainment: end-to-end multi-shot previsualization and storyboarding
- Use case: Rapid generation of minute-level sequences for directors and game designers to iterate on narratives, shot lists, and scene transitions.
- Workflow/tools: “MoGA-enabled DiT engine” integrated into existing tools (e.g., Wan2.1, MMDiT), “Shot-level Prompt Scheduler” for per-shot text conditioning, “ContinuityGuard” metrics dashboard (VBench, Cross-Shot CLIP/DINO).
- Assumptions/dependencies: Access to GPU clusters; shot-level prompt authoring; clean shot segmentation; model licensing for commercial use; staff familiarity with diffusion transformers.
- Advertising & Marketing: brand asset continuity across multi-shot campaigns
- Use case: Generate coherent minute-long ads preserving identities (logos, mascots, actors) and background continuity across cuts.
- Workflow/tools: “Brand Consistency Studio” plugin that leverages router group outputs to track and preserve brand elements across shots; batch prompt templating for regional variants.
- Assumptions/dependencies: Curated brand asset libraries; rights management; review pipelines for factual correctness and compliance.
- Post-production & Editing: routing-aware continuity checks and assistive editing
- Use case: Detect identity/background drift and suggest edits at shot boundaries using router assignments and STGA group outputs.
- Workflow/tools: NLE plugins (Adobe Premiere, DaVinci Resolve) reading router group maps for target-aware color correction, stabilization, and continuity verification.
- Assumptions/dependencies: Access to model internals (router outputs); integration with video editors; latency tolerance during review.
- Synthetic Data Generation for Computer Vision (Academia/Industry)
- Use case: Create long, multi-shot synthetic datasets for training re-identification, multi-object tracking, long-range temporal consistency models, and generative evaluation research.
- Workflow/tools: “LongSeqSynth” generator using MoGA+STGA and shot-level prompts; auto-metrics (Cross-Shot CLIP/DINO) to label consistency levels.
- Assumptions/dependencies: Domain gap mitigation; dataset documentation; ethical sourcing; variation in styles (realistic/animated) per target tasks.
- Efficiency Upgrades for Existing Video Gen Stacks (Software/Infrastructure)
- Use case: Reduce PFLOPs and memory pressure in training/inference for DiT-based models while preserving or improving quality.
- Workflow/tools: “MoGA-FlashAttention integration” drop-in module; “Sequence-Parallel MoGA” runtime; group balancing loss tuning recipes; FLOPs/carbon counters.
- Assumptions/dependencies: Compatibility with FlashAttention versions; sequence-parallel infrastructure; tuning M (group count) for trade-offs; maintenance of kernels and drivers.
- Streaming Platforms & Media Ops: automated trailers, recaps, and highlight reels
- Use case: Generate coherent multi-shot summaries of shows/sports events, preserving character/team identities and environments.
- Workflow/tools: Prompt templates linked to program metadata; routing-aware identity preservation; instant metrics to flag drift before publishing.
- Assumptions/dependencies: Rights and compliance; reliable metadata; human-in-the-loop QA.
- Education & Training: minute-long explainers and lab demonstrations
- Use case: Produce multi-shot topic sequences (e.g., physics demonstrations, historical vignettes) where characters and visual settings persist across shots.
- Workflow/tools: “LessonShot” authoring pipeline using multi-shot captions; pre-built domain-specific prompt libraries.
- Assumptions/dependencies: Subject-matter review for accuracy; content safety filters; accessibility features (captions, audio descriptions).
- Energy & Sustainability Reporting (Policy/Operations)
- Use case: Track and reduce compute-related emissions by adopting sparse attention; benchmark quality vs. FLOPs trade-offs.
- Workflow/tools: “Green Video Gen” dashboard that logs PFLOPs, energy use, and consistency metrics per run.
- Assumptions/dependencies: Accurate energy metering; organizational buy-in to measure/report footprint; comparable baselines.
- Platform Compliance & Safety Auditing (Policy)
- Use case: Use consistency and identity metrics to audit long AI-generated videos for labeling/provenance and drift anomalies.
- Workflow/tools: “Consistency Auditor” service using VBench plus cross-shot metrics; policy hooks for disclosure and content moderation.
- Assumptions/dependencies: Clear guidelines; willingness to adopt audit scores; integration with platform policies and labeling standards.
Long-Term Applications
These require further research, scaling, or development (e.g., higher resolution, longer durations, lower latency, advanced controls).
- Feature-length AI-generated films and episodic series (Media & Entertainment)
- Use case: Produce hours-long, narrative-coherent content with persistent characters and environments.
- Tools/products: “AI Director” suite combining MoGA with hierarchical planning and script-level control; advanced shot scheduling; memory retrieval.
- Dependencies: Scale to higher resolution (e.g., 4K), longer contexts (multi-million tokens), robust text-to-scene semantics, significant compute budgets, distribution rights.
- Real-time interactive T2V for VR/AR, live performances, and streaming
- Use case: Low-latency generation of coherent multi-shot sequences with user interaction and dynamic scene transitions.
- Tools/products: “MoGA Live” with streaming memory and sequence parallelism; fast router inference; multimodal control (voice, gestures).
- Dependencies: Hardware acceleration (edge GPUs, custom NPUs), optimized kernels, latency-aware scheduling, safety filters.
- Personalized episodic content at scale (Streaming/Media Tech)
- Use case: Generate individualized recaps, trailers, and mini-episodes based on viewer profiles while maintaining consistency.
- Tools/products: “Personalized Shot Planner” connected to user models and content catalogs; automatic rights-aware prompt generation.
- Dependencies: Privacy-compliant personalization, scalable compute, robust evaluation and human oversight.
- Simulation for autonomy and robotics (Robotics/Autonomous Systems)
- Use case: Long-horizon, multi-scene synthetic environments to train perception/planning systems (e.g., rare-event chains, persistent landmarks).
- Tools/products: “SimLong” synthetic scenario generator with MoGA for temporal coherence; integration with physics engines.
- Dependencies: Physical realism, sim-to-real transfer, multimodal data (sensor fusion), domain-specific validation.
- Autonomous driving and smart city digital twins (Mobility/Energy)
- Use case: City-scale, temporally consistent simulations for planning, traffic analysis, and infrastructure stress testing.
- Tools/products: “TwinCity Video” long sequence generator; coupling with agent-based simulators; energy demand modeling.
- Dependencies: High-fidelity realism, integration with GIS and traffic models, governance for public-sector use.
- Cross-modality extension: long-context Transformers for text, audio, and time-series
- Use case: Adapt MoGA’s router-based sparse attention to scale LLMs, audio generation, and forecasting with very long contexts.
- Tools/products: “MoGA-L” general sparse attention library for multi-domain Transformers; router training recipes for non-visual tokens.
- Dependencies: Modality-specific routing features, evaluation benchmarks, kernel compatibility beyond vision.
- Provenance, watermarking, and authenticity standards for long AI videos (Policy/Standards)
- Use case: Establish standardized provenance chains and robust watermarks that survive multi-shot edits and post-processing.
- Tools/products: “ProvenanceChain” and secure watermarking layers integrated into MoGA pipelines; regulatory adherence frameworks.
- Dependencies: Cross-industry standards, legal acceptance, reliable watermark resilience.
- Consumer-grade mobile apps for long-form generation (Software/Consumer)
- Use case: On-device or cloud-assisted creation of minute-level coherent videos by individual creators.
- Tools/products: “MinuteGen Mobile” leveraging efficient sparse attention and quantized models; cloud offload for heavy segments.
- Dependencies: Hardware acceleration on mobile (GPU/NPU), efficient kernels, UX for shot-level prompting, cost control.
- Interactive education and therapy scenarios (Healthcare/Education)
- Use case: Persistent characters and environments across sessions for exposure therapy, language learning, and social skills training.
- Tools/products: “TherapyShots” scenario builder with safety constraints; clinician dashboards to monitor consistency and outcomes.
- Dependencies: Clinical validation, ethical guardrails, personalization safeguards, consent and privacy compliance.
- Persistent world simulation and digital humans (Software/Metaverse)
- Use case: Large-scale simulations with consistent identities, evolving story arcs, and memory across episodes.
- Tools/products: “WorldMemory Engine” combining MoGA with retrieval-augmented memory modules; multi-agent coordination.
- Dependencies: Integrations with memory architectures (e.g., world models), governance of simulated behaviors, substantial compute.
Cross-cutting assumptions and dependencies
- Compute and infrastructure: Multi-GPU/TPU clusters; compatibility with FlashAttention and sequence parallelism; kernel maintenance.
- Data quality and licensing: Access to clean, labeled multi-shot datasets; shot segmentation (AutoShot, PySceneDetect); robust captions via MLLMs; rights management.
- Model tuning: Appropriate group counts (M), group balancing loss, spatial window partitioning; evaluation metrics and monitoring.
- Safety and compliance: Content moderation, disclosure of AI-generated media, privacy-preserving personalization, provenance.
- Economics: Cost of long-form generation; energy use and sustainability considerations; ROI in production pipelines.
Glossary
- Autoregressive approaches: A generation paradigm where outputs are produced sequentially, conditioning each segment on previous ones. "Autoregressive approaches generate videos through sequential segment synthesis"
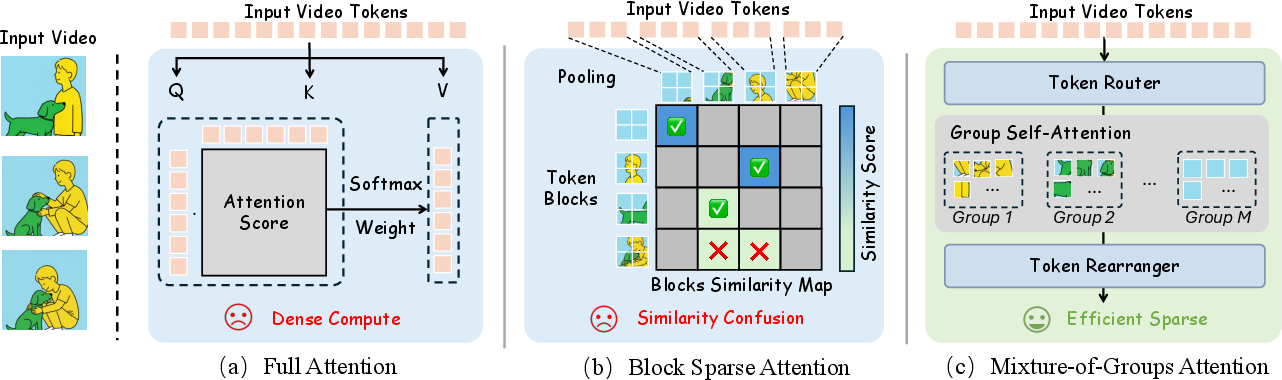
- Block sparse attention: An attention strategy that operates on coarse blocks of tokens to reduce compute, potentially harming accuracy if block similarity is misestimated. "Block sparse attention~\citep{lu2025moba} may fail when block-level similarity is confused, resulting in unreliable attention."
- CLIP: A vision-LLM used to measure semantic similarity between text and images or video frames. "We then compute feature similarities across shots using CLIP"
- Cross-attention: An attention mechanism where one modality’s queries attend to another modality’s keys/values to inject conditioning. "instantiated via either cross-attention~\citep{wan2025wan} or multi-modal attention~\citep{kong2024hunyuanvideo,esser2024scaling}"
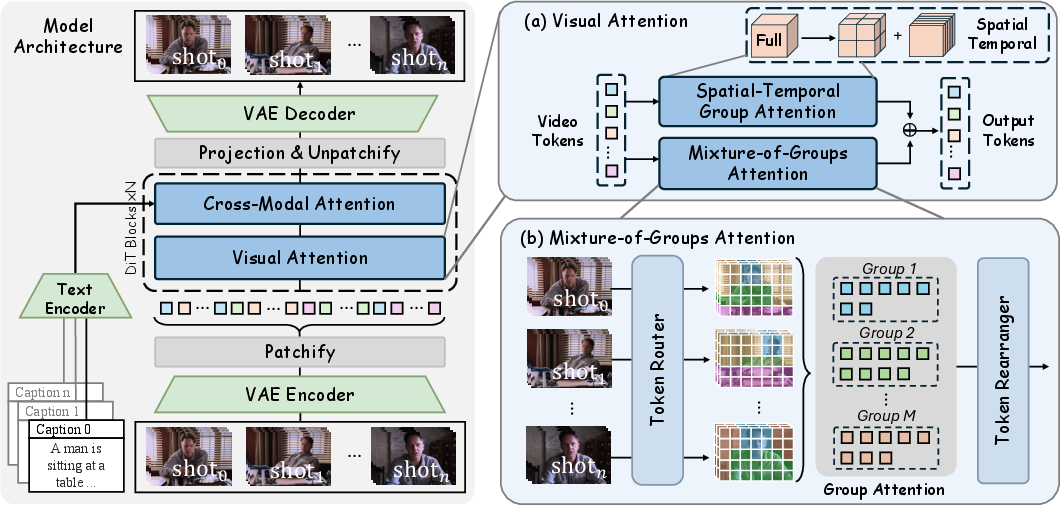
- Cross-modal attention: Attention that integrates information across different modalities, such as text and video. "Cross-Modal Attention enables shot-level text conditioning"
- CrossâShot CLIP: A metric derived from CLIP to quantify semantic consistency across different shots. "referred to as CrossâShot CLIP and CrossâShot DINO"
- CrossâShot DINO: A metric based on DINOv2 to assess visual feature consistency across shots. "referred to as CrossâShot CLIP and CrossâShot DINO"
- DINOv2: A self-supervised vision backbone used for robust image feature extraction and similarity measurement. "and DINOv2~\citep{oquab2023dinov2}, referred to as CrossâShot CLIP and CrossâShot DINO"
- Diffusion Transformers (DiTs): Transformer-based diffusion models that generate images or videos via iterative denoising. "Long video generation with Diffusion Transformers (DiTs) is bottlenecked by the quadratic scaling of full attention with sequence length."
- FlashAttention: A high-performance attention kernel that reduces memory access and improves throughput. "as a kernel-free method, MoGA integrates seamlessly with modern attention stacks, including FlashAttention and sequence parallelism."
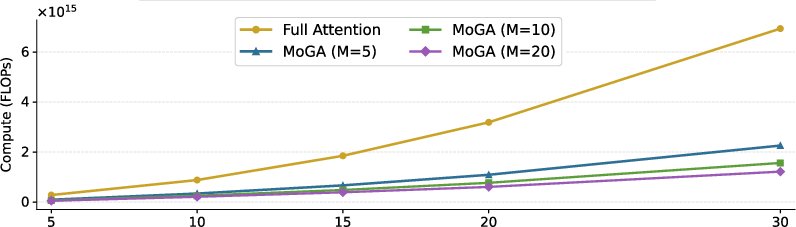
- FLOPs: Floating-point operations, a measure of computational cost. "As the number of groups~() increases, MoGA's FLOPs decrease substantially."
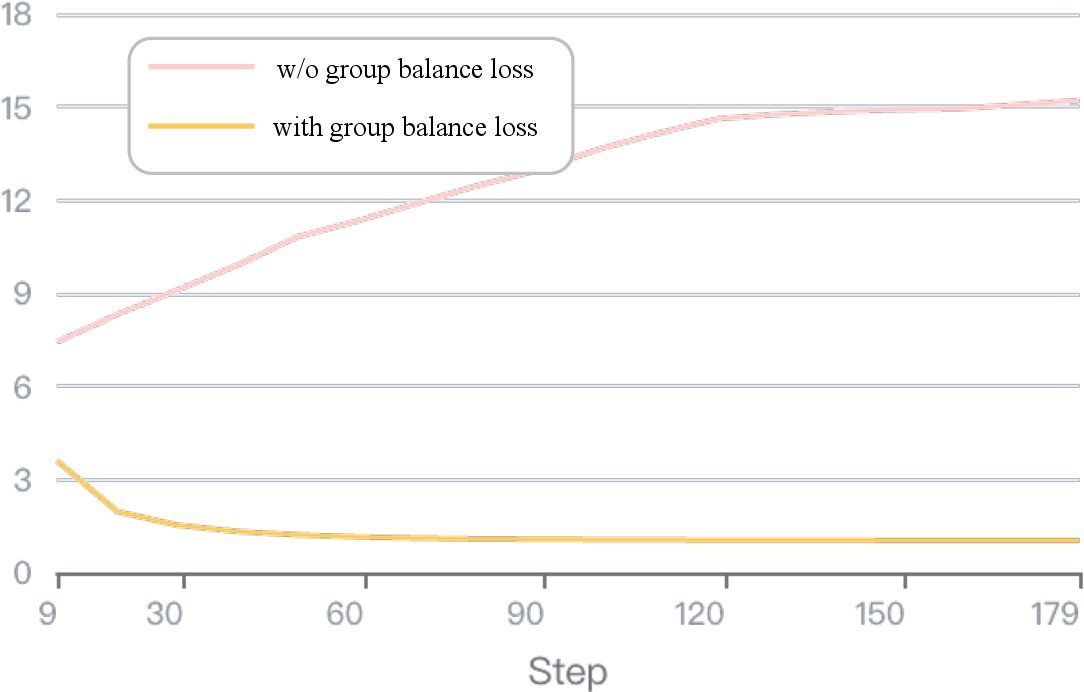
- Group Balancing Loss: An auxiliary objective that discourages routing collapse by encouraging uniform token distribution across groups. "Group Balancing Loss. A potential issue with token assignment is that the router may collapse by routing most tokens to only a few groups, which would degenerate MoGA into full attention"
- Groupwise attention: Performing full attention within semantically or structurally defined token groups to reduce global compute. "where the groupwise attention integrates seamlessly with modern attention kernels, e.g.,~FlashAttention~\citep{dao2023flashattention}"
- Head scatter: A sequence parallelism step that distributes attention heads across devices or partitions. "Before the sequence gather and head scatter step in each attention layer, MoGA computes routing scores over tokens"
- k-means clustering: An unsupervised algorithm to partition tokens into k clusters based on centroids, used for dynamic sparse attention in some baselines. "performs online k-means clustering over tokens during inference"
- Latent video space: The compressed representation domain where video tokens reside during model processing. "restricts selfâattention to local windows in latent video space"
- Load balancing loss: A MoE-inspired objective promoting balanced expert (or group) usage. "inspired by the load balancing loss~\citep{fedus2022switch} used in MoE."
- Mixture-of-Experts (MoE): A framework that routes inputs to specialized experts via a gating network. "inspired by the Mixture-of-Experts (MoE)~\citep{jacobs1991adaptive}"
- Mixture-of-Groups Attention (MoGA): A sparse attention method that routes tokens into groups for intra-group attention, enabling long-context efficiency. "This paper introduces Mixture-of-Groups Attention (MoGA), an efficient sparse attention that uses a lightweight, learnable token router to precisely match tokens without blockwise estimation."
- MMDiT: A multi-modal Diffusion Transformer variant that replaces cross-attention with unified multimodal attention. "Unlike Wan, this model replaces cross-attention with MMDiT to perform cross-modal attention."
- OCR (Optical Character Recognition): Technology for extracting text from video frames, used in data cleaning and cropping. "We process single-shot clips using VQA and optical character recognition (OCR) models and discard low-quality clips."
- Patchify sizes: The patch dimensions used when tokenizing latent features into fixed-size patches. "and patchify sizes are (1, 2, 2)."
- PFLOPs: Peta floating-point operations, indicating extremely large computational workloads. "MoGA achieves substantial computational savings compared to full attention (2.26 PFLOPs vs. 6.94 PFLOPs)."
- Rectified flow objective: A training objective for diffusion models that improves convergence and scaling. "with the rectified flow objective~\citep{esser2024scaling}"
- Sequence gather: A step in sequence parallelism that consolidates token sequences before attention computation. "Before the sequence gather and head scatter step in each attention layer, MoGA computes routing scores over tokens"
- Sequence parallelism: A parallelization technique that partitions sequences across devices to scale attention efficiently. "Beyond sparse attention, a second pillar of long-context modeling is sequence parallelism~\citep{jacobs2023deepspeed}, with which MoGA is also compatible."
- Shot segmentation: Detecting shot boundaries to create clean, multi-shot training data. "dense, multi-shot captions and reliable shot segmentation"
- Softmax gating: A routing mechanism that uses softmax-normalized scores to assign tokens to groups or experts. "Specifically, the router is a linear projection followed by softmax gating, similar to MoE~\citep{fedus2022switch}."
- Sparse attention: Attention that computes only a subset of query–key interactions to reduce complexity. "A complementary direction exploits sparse attention~\citep{zaheer2020big} by restricting computation to a selected subset of salient queryâkey pairs."
- SpatialâTemporal Group Attention (STGA): A local attention mechanism that operates within spatiotemporal windows to preserve short-range coherence. "We complement it with local spatiotemporal group attention (STGA)~\citep{gao2025seedance, zhang2025waver}"
- Spatiotemporal window attention: Attention restricted to predefined spatial and temporal windows for local fidelity. "we couple MoGA with the spatiotemporal window attention~\citep{gao2025seedance}"
- Token router: A lightweight module that assigns tokens to attention groups based on learned scores. "uses a lightweight, learnable token router to precisely match tokens without blockwise estimation"
- Token routing: The process of directing tokens to specific groups or experts before attention. "MoGA addresses the above challenge via efficient token routing"
- Topâk: Selecting the k highest-scoring blocks or clusters during coarse routing. "routes query tokens to the topâk blocks"
- VAE downsampling factors: The temporal and spatial reduction ratios applied by the video VAE prior to tokenization. "the VAE downsampling factors for (t, h, w) are (4, 8, 8)"
- Visual Quality Assessment (VQA): Automated models that score video frames for aesthetics, clarity, and exposure. "We first analyze raw videos using visual quality assessment (VQA) models (e.g., aesthetics~\citep{schuhmann2022laion5b}, clarity, exposure)"
Collections
Sign up for free to add this paper to one or more collections.

