- The paper proposes VisAlign, a method that fuses average-pooled visual embeddings with textual tokens to reduce hallucinations in LVLMs.
- It demonstrates improved multimodal attention by rebalancing text and visual cues, yielding a +9.33% accuracy boost on the MMVP-MLLM benchmark.
- The approach integrates seamlessly with existing LVLM pipelines while incurring minimal computational overhead for robust visual grounding.
Mitigating Hallucinations in Large Vision-LLMs through Refined Textual Embeddings
Introduction and Motivation
Large Vision-LLMs (LVLMs), such as Video-LLaVA, extend LLMs to multimodal reasoning by fusing visual and textual representations, yet remain vulnerable to hallucinations—outputs that are linguistically fluent but not visually grounded. Prominent failure cases (Figure 1) reveal that LVLMs frequently fabricate objects, actions, or attributes absent from the input visual context, undermining trustworthiness in domains like healthcare, education, and autonomous systems.
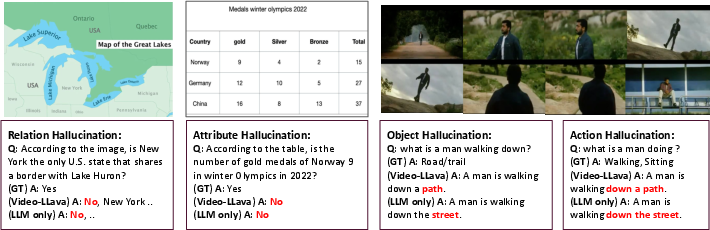
Figure 1: Hallucinations in Video-LLaVA illustrate object and action misinterpretations due to insufficient multimodal integration.
A core source of these errors is the modal imbalance endemic to current LVLM architectures. Pre-trained LLMs, when extended with appended visual features, exhibit a structural bias favoring text over visual cues, leading to underutilization of visual evidence during both attention and reasoning. Systematic analysis indicates this imbalance propagates through transformer attention layers and exacerbates hallucination phenomena.
Architecture and Method: VisAlign for Multimodal Alignment
The paper proposes VisAlign, a minimally invasive architectural modification that directly integrates visual context into textual embeddings before input to the backbone LLM. This contrasts with baseline strategies that simply concatenate projected visual tokens after a block of text, compounding language-driven bias.
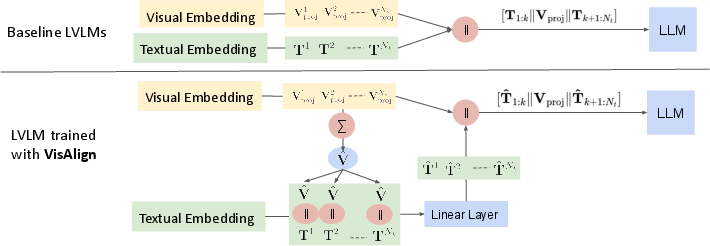
Figure 2: Top: Baseline Video-LLaVA concatenates textual and visual embeddings in fixed order; Bottom: VisAlign fuses average-pooled visual embeddings into each textual token followed by projection.
VisAlign Technical Implementation
- Visual Feature Aggregation: Projected visual embeddings Vproj∈RNv×dt are average-pooled to form a summary vector V^∈R1×dt.
- Textual Embedding Refinement: Each textual token embedding T1:Nt∈RNt×dt is concatenated with V^, yielding fused embeddings TV∈RNt×2dt.
- Dimensionality Restoration: A linear layer Wd reduces the fused representation back to dt, producing visually-informed token embeddings T^.
- Concatenation and Input Sequence: The sequence fed to the LLM is [T^1:k,V^,T^k+1:Nt], encouraging balanced multimodal attention across the input stream.
The training protocol mirrors the baseline: first, pretrain the projection and fusion layers with the LLM frozen, then fine-tune end-to-end on multimodal datasets.
Attention Dynamics and Empirical Self-Attention Analysis
Quantitative analysis of self-attention patterns reveals stark modality imbalance in baseline LVLMs:
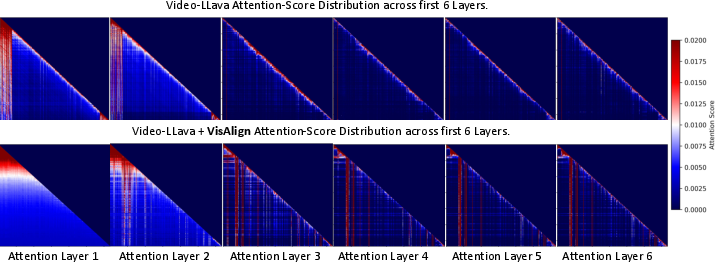
Figure 3: Video-LLaVA (top) attention layers concentrate on textual tokens, under-attending visual ones; VisAlign (bottom) yields more balanced and structured attention spanning both modalities.
Baseline models allocate high attention to text blocks at sequence boundaries and neglect the central block of visual tokens, limiting cross-modal propagation of crucial visual signals. VisAlign prompts sharper, more frequent vertical bands in the attention distribution, signifying improved focus on semantic visual anchors and smoother, context-rich attention gradients—critical for robust visual grounding.
Object, Action, and Fine-Grained Hallucination Reduction
Across challenging benchmarks, VisAlign delivers consistent and sometimes substantial gains:
- MMVP-MLLM: +9.33% accuracy improvement over base Video-LLaVA. The strict criteria of MMVP-MLLM, requiring correct identification of subtle visual distinctions, underscore the method’s impact on factual visual grounding.
- POPE-AOKVQA: Precision and F1-score rises demonstrate fewer false positives and better object-level grounding.
- MERLIN: Substantial improvements in both positive and negative cases, especially in identifying object absence in synthetic image edits, highlight VisAlign’s efficacy for fine-grained object verification.
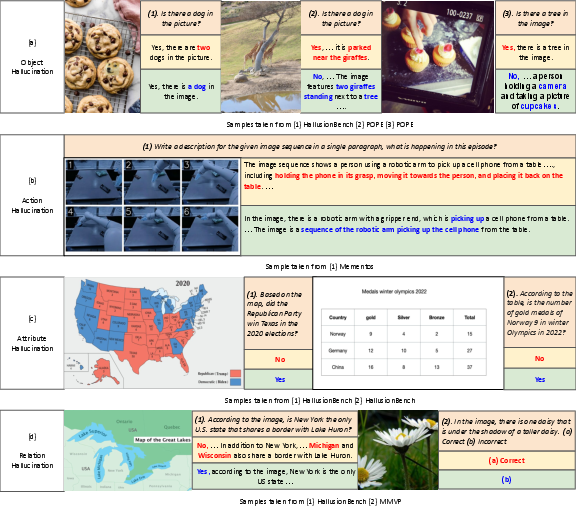
Figure 4: Qualitative examples spanning POPE, HallusionBench, MMVP, and Mementos benchmarks exhibit consistent hallucination mitigation across object, action, attribute, and relational errors.
Sequential and Contextual Reasoning
Trade-Offs, Generalization, and Integration with SOTA
VisAlign’s embedding-level refinement operates orthogonally to inference-time methods (e.g., Visual Contrastive Decoding). Combination yields additive gains, as shown empirically in POPE and generic benchmarks, without interference. While performance on abstract knowledge or scene-based tasks may see minor regression due to decreased language prior influence, core visual grounding improves markedly.
VisAlign applies seamlessly to alternative LVLMs (e.g., LLaVA 1.5) and outperforms strong inference-based mitigation techniques in generalizability. The trade-off profile favors visual fidelity over world-knowledge memorization—a desirable attribute for safety-critical or truth-sensitive applications.
Theoretical and Practical Implications
The study substantiates that modality imbalance—structural and representational—remains a primary impediment to reliable multimodal generation. Addressing this at the representation construction level yields more robust attention utilization and visual grounding, outperforming post-hoc correction heuristics. The approach invites future exploration of more sophisticated modality fusion (beyond average pooling), dynamic attention steering, and context-aware embedding architectures.
In practice, integrating VisAlign entails minimal computational overhead and fits existing LVLM pipelines with minor modifications, making it viable for deployment in privacy-sensitive, regulated, or real-time multimodal environments.
Conclusion
The paper provides compelling empirical and architectural evidence that hallucinations in LVLMs predominantly arise from modality imbalance rooted in text-prior overuse. By enriching textual embeddings with visual context through a principled and parameter-efficient fusion approach, cross-modal attention becomes more balanced, greatly reducing hallucinations and improving factual grounding. Integrating such representation-level refinements enhances model reliability and sets a foundation for further advances in scalable multimodal alignment.


