- The paper introduces a unified table lookup for low-bit LLM inference that eliminates CPU fallback and improves NPU efficiency.
- It fuses dequantization, GEMM, and GEMV operations into a pipelined process that achieves up to 15× speedup and 84% energy savings.
- The approach supports flexible quantization formats while maintaining high accuracy, outperforming previous state-of-the-art methods.
T-MAN: Unified Table-Lookup for Low-Bit LLM Inference on NPUs
Introduction and Motivation
The T-MAN system addresses the inefficiencies encountered when deploying low-bit quantized LLMs on consumer devices equipped with Neural Processing Units (NPUs). Although NPUs promise high throughput for matrix operations, existing LLM inference workflows often resort to hybrid solutions—using the NPU for prompt processing (prefill) and the CPU for token generation (decoding). This is due to NPUs’ hardware specialization, which optimizes dense high-precision GEMMs but lacks efficient support for the memory-bound, element-wise operations (notably dequantization) inherent to low-bit decoding. T-MAN proposes a software solution leveraging unified table-lookup operations to enable efficient, accurate, end-to-end low-bit LLM execution entirely on NPUs, supporting state-of-the-art quantization formats without compromise on accuracy or energy.
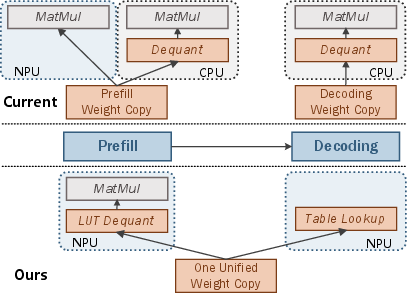
Figure 1: T-MAN eliminates redundant weight copies and enables both prefill and decoding on the NPU via table lookup, avoiding CPU fallback and additional memory use.
System Design: Unified Table Lookup and Execution Pipeline
Challenges in NPU-based Low-Bit Inference
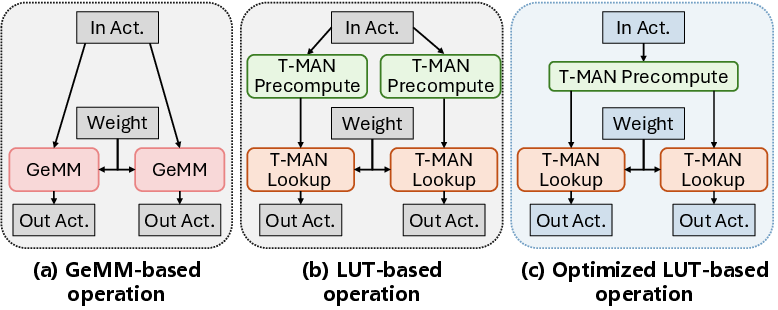
Current practices either (a) align quantization with NPU-native formats (e.g., per-channel INT4) at the cost of significant accuracy loss, or (b) partition workload across CPU and NPU, incurring excessive energy, memory overhead, and complexity due to duplicated weights (Figure 1). Existing bit-serial table-lookup solutions succeed in eliminating dequantization, yet suffer from suboptimal utilization of NPU memory hierarchies and vector/matrix units (cf. [t-mac], [luttensorcore]).
T-MAN’s Unified Table-Lookup Abstraction
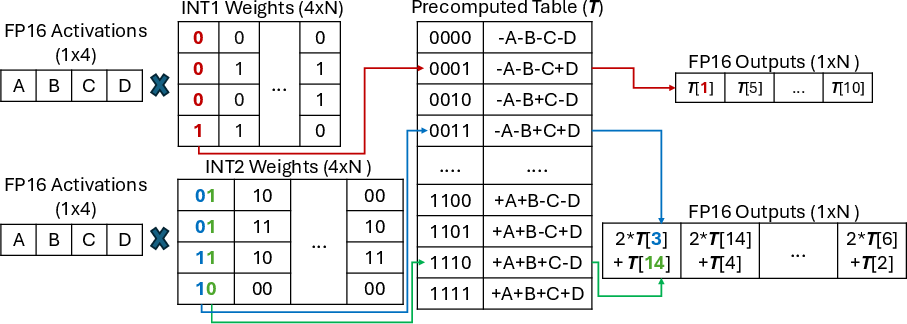
The central insight of T-MAN is that in low-bit regimes, all necessary dequantization and multiplication results can be pre-computed and stored in compact lookup tables (LUTs), so that both prefill (GEMM) and decoding (GEMV) phases can be expressed as table-lookup-dominated computations:
T-MAN unifies these two paradigms with a single weight layout and precomputed tables, avoiding both data duplication and costly bit-shuffling or repacking.
Data Layout, Tiling, and Pipelining
Two-Level LUT-based Dequantization and Layout
T-MAN supports per-group and per-block quantization, critical for SOTA LLM inference accuracy. Its design fuses bit-repacking, integer-to-float conversion, and scaling/zero-point application into two sequential table lookups. This approach drastically reduces per-token dequantization overhead, as expensive floating-point math is replaced by LUT retrieval.
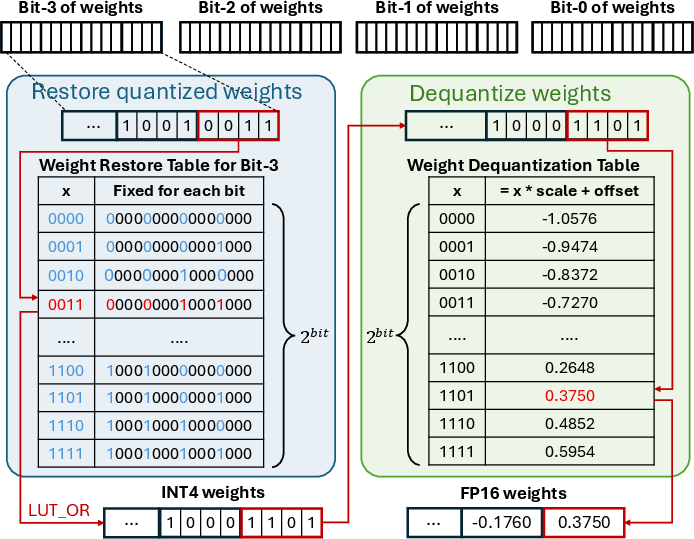
Figure 4: Fused two-level LUT dequantization enables a single memory-efficient table lookup to substitute for multiple bitwise and floating-point operations.
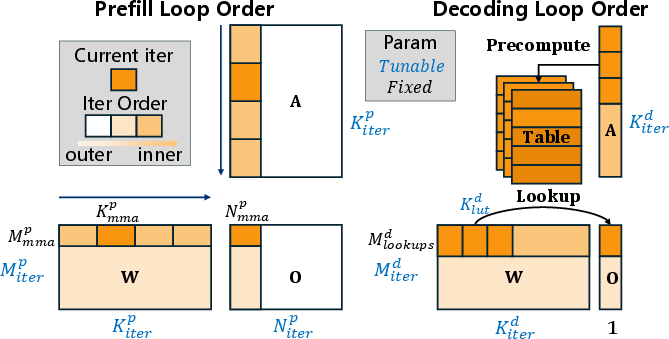
Unified Concurrency-Aware Tiling
T-MAN discovers a unified memory/compute tiling configuration efficient for both prefill (matrix core, GEMM) and decoding (vector core, GEMV):
Pipelined Execution to Amortize Overhead
T-MAN employs a three-stage pipeline: asynchronous DMA fetch, vector-core dequantization via LUT, and matrix-core multiplication. This design effectively overlaps communication and computation, minimizing NPU idle time.
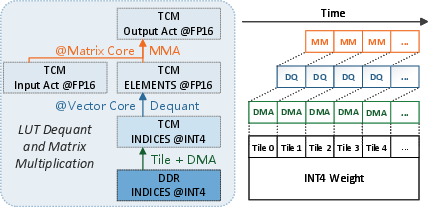
Figure 8: DMA, vector dequantization, and matrix multiplication pipeline stages overlap to maximize NPU utilization and mask slow memory or dequantization steps.
Optimized Table Lookup Decoding
During decoding, the LUT-based approach is vectorized along the output channel, maximizing per-inference-token throughput by batching table lookups. T-MAN’s register spill buffer maps intermediate results to on-chip TCM, avoiding costly L2 cache spills. This strategy is optimized for wide vectors and deep tiling hierarchies found in modern NPUs.
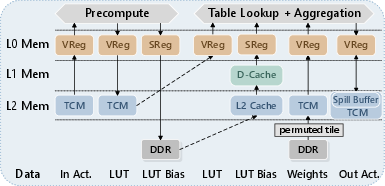
Figure 10: T-MAN’s mapping of memory hierarchy for LUT decoding leverages on-chip memory for spill buffer to avoid slow cache interactions.
Implementation Details
Empirical Evaluation
T-MAN is evaluated on OnePlus smartphones with Snapdragon NPUs using Llama3, Qwen3, and BitNet models at INT2/INT4 precision.
Key results:
- Prefill (GEMM): up to 1.4× speedup vs. prior SOTA (LLM.npu, T-MAC, QNN), matching or exceeding vendor-optimized kernels even for per-block quantization (Figure 12).
- Decoding (GEMV): up to 3.1× speedup (and up to 8× kernel speedup) compared to QNN and 3.8× over LLM.npu, despite supporting richer quantization formats (Figure 13).
- Energy savings: Up to 84% energy reduction compared to hybrid NPU-CPU solutions; 25% lower energy vs QNN for decoding, attributable to faster inference and exclusive use of the efficient NPU cores.
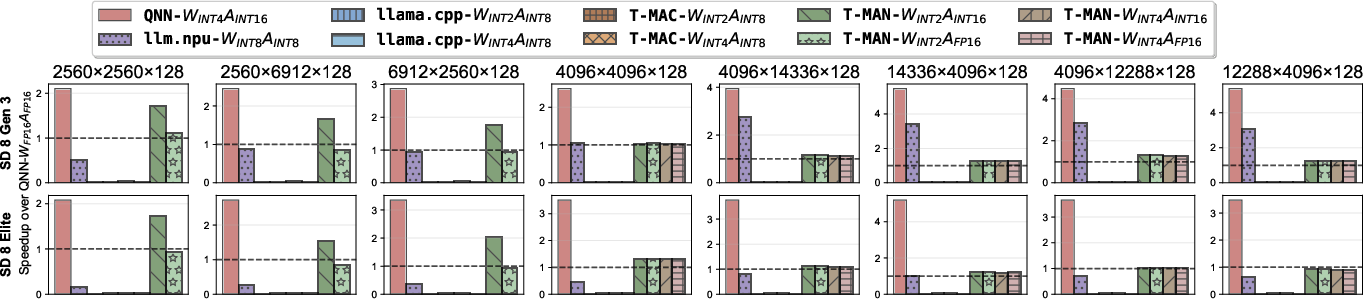
Figure 5: mpGEMM performance: T-MAN achieves comparable or superior throughput to QNN, outperforming NPU-CPU hybrids and CPU-only baselines.
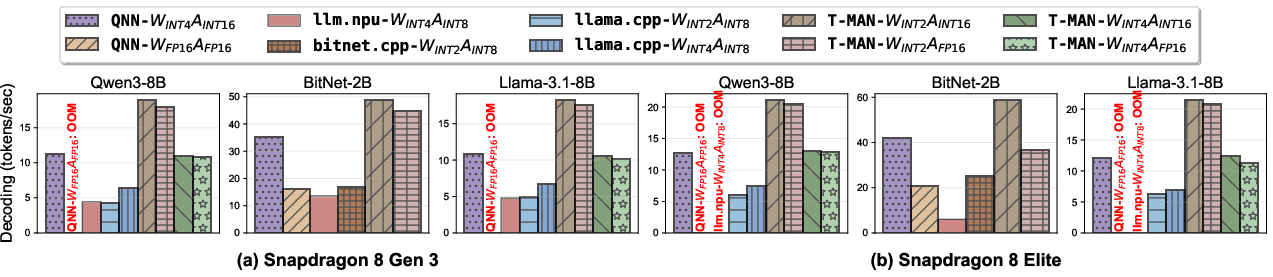
Figure 7: Decoding throughput—T-MAN sustains up to 49.1 tokens/s on BitNet-2B, with substantial speedup over QNN and CPU/NPU baselines.
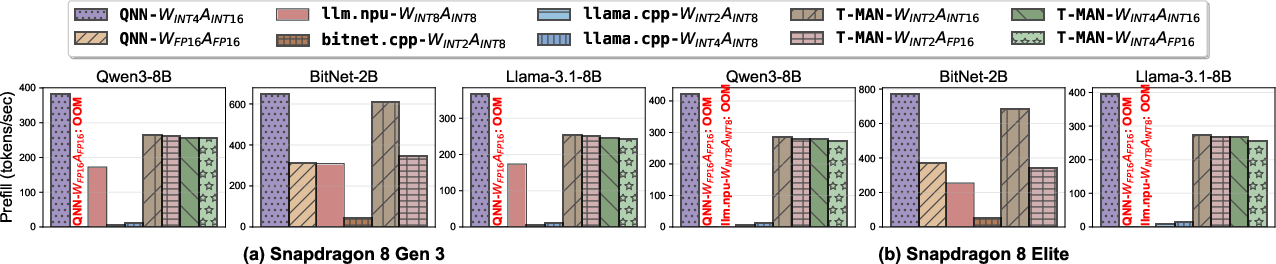
Figure 9: Prefill throughput—end-to-end, T-MAN achieves 15× speedup vs. CPU-only frameworks by leveraging efficient NPU hardware.
Ablation and Accuracy Study
- LUT-dequantization brings 10× speedup over regular float dequant, 4.9× over loading pre-dequantized weights (Figure 15).
- Pipeline execution yields 1.5× performance boost over non-overlapped execution (Figure 16).
- Accuracy: T-MAN with per-block INT2 quantization outperforms QNN with per-channel INT4 in perplexity on standard evaluation datasets—48% perplexity reduction on Qwen3-8B and 32% on Llama-3.1-8B.
Practical Implications and Limitations
T-MAN demonstrates that table-lookup-based low-bit inference can bridge the flexibility-performance gap that has stymied deployment of quantized LLMs on highly specialized NPUs. It enables:
- Unified model formats supporting SOTA quantization without data redundancy
- End-to-end NPU execution for latency and energy improvement
- Flexibility for future quantization research beyond vendor-constrained choices
However, T-MAN’s full benefits rely on programmable NPUs with sufficient register file and on-chip memory capacity. Applicability is reduced on platforms with only opaque high-level interfaces (e.g., Apple NPU family), or those lacking support for low-latency table lookup operations.
Theoretical and Future Directions
T-MAN demonstrates the value of software-hardware co-design, even in the absence of direct hardware support for arbitrary quantization formats. If NPU vendors expose matrix/tensor instructions for 2- and 4-bit formats, further kernel optimizations are possible, including batch-sequential and long-context improvements. As on-chip memory grows and register spills become even more expensive, hierarchical LUT and spill management strategies will become critical.
The demonstrated superiority of per-block/group quantization for LLMs—enabled by T-MAN’s design—should make future NPU architectures favor greater programmability and LUT-friendliness, broadening support for advanced quantization and compression strategies.
Conclusion
T-MAN achieves the first lossless, fully NPU-resident, low-bit LLM inference pipeline that supports arbitrary quantization strategies without loss of performance or accuracy. Its flexible, cue-efficient table-lookup mechanism and unified data management yield strong improvements in throughput and energy relative to vendor and academic baselines, positioning it as an essential reference for the next generation of LLM deployment systems on edge and mobile NPUs.