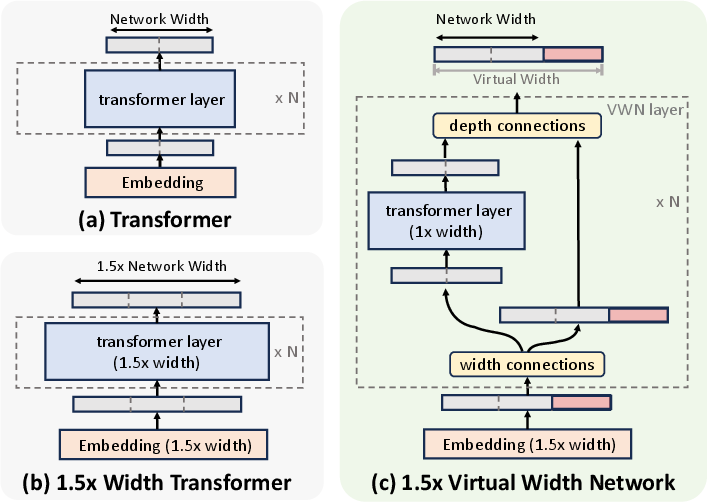
Virtual Width Networks
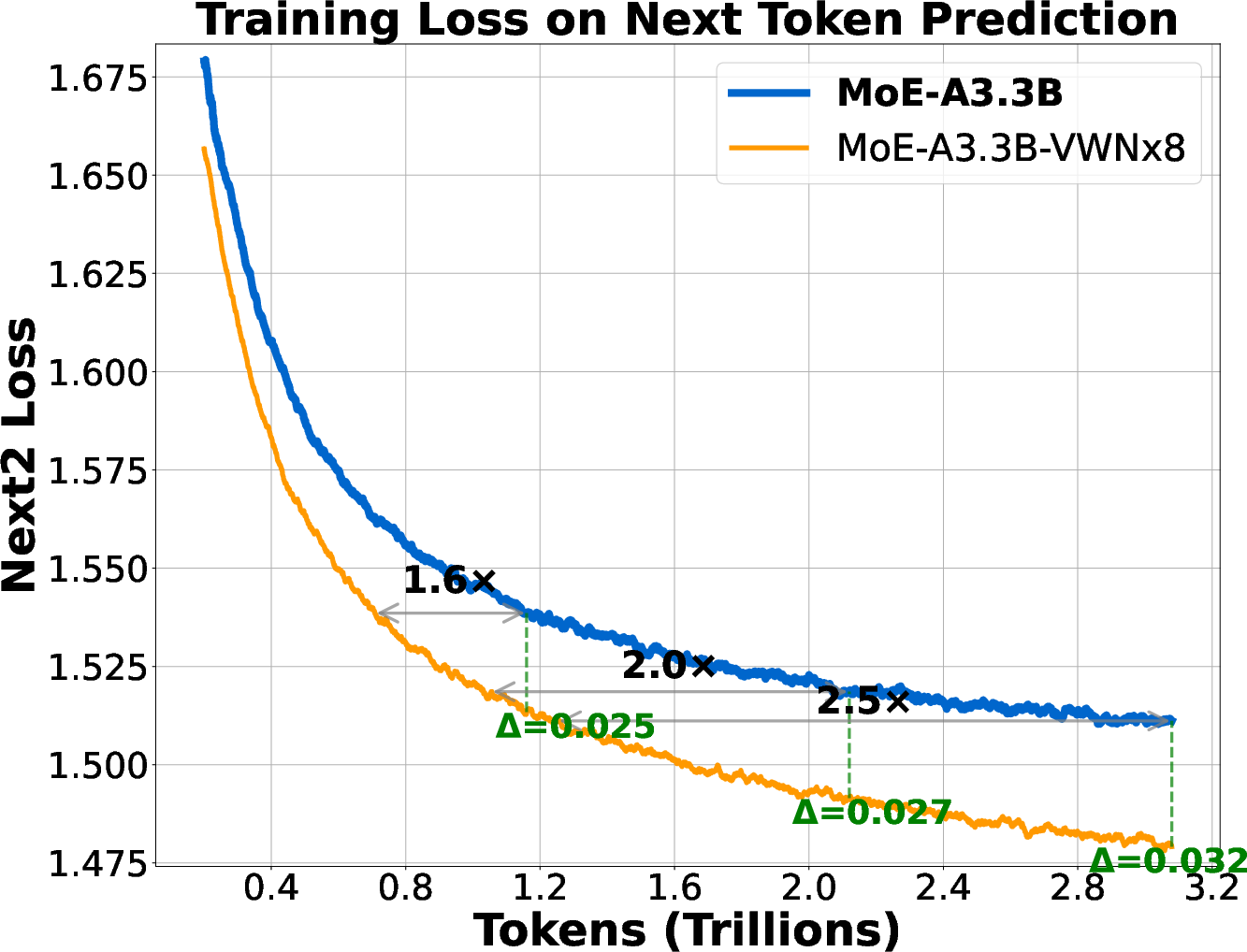
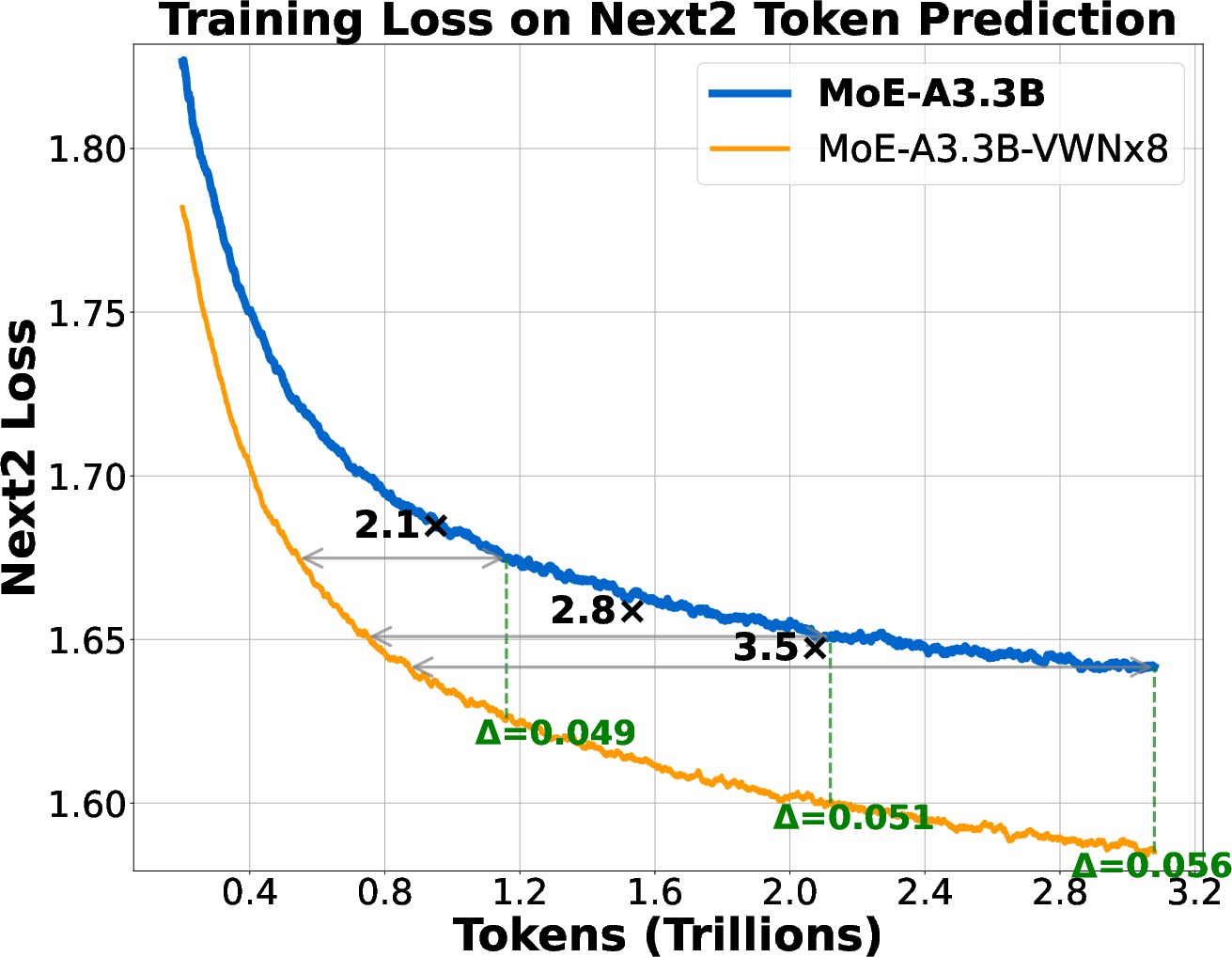
Abstract: We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make LLMs smarter without making them much more expensive to run. The idea is called Virtual Width Networks (VWN). It lets the model use “wider” word representations (more information per word) while keeping the main part of the model roughly the same size. This helps the model learn faster and perform better, especially when predicting the next word or short phrases.
What questions did the researchers try to answer?
In simple terms, they asked:
- Can we give models the benefits of “wider” thinking (richer word representations) without paying the usual heavy cost in speed and memory?
- Can we increase the width of the model’s word representations separately from the width of the model’s core (the “backbone”)?
- Does making these word representations wider help the model learn faster and do better on real tasks?
- Is there a predictable relationship between how much we widen and how much the model improves?
How does it work? (Methods explained with analogies)
Think of a Transformer (a common type of LLM) like a factory:
- The “embedding” is how a word is turned into a vector (a bundle of numbers). It’s like packing a word’s meaning into a suitcase before sending it into the factory.
- The “backbone” is the main conveyor belt and machines inside the factory that process those suitcases.
- “Wider” means the suitcase holds more detailed stuff—more features about the word. Normally, making everything wider makes the factory larger and much more expensive to run.
The problem: If you make the whole factory wider (bigger embeddings AND bigger backbone), costs go up fast (roughly quadratically), which is often too expensive.
The solution: VWN widens the suitcase (embedding) but keeps the factory machines the same size. To make that work, they add smart adapters called Generalized Hyper-Connections (GHC):
- GHC is like a funnel and a pump combined:
- Funnel: It compresses the wide suitcase down to the normal size so the factory can process it.
- Pump: After the factory does its job, it expands the processed result back to the wider size so the suitcase stays rich with information.
- This “compress-then-expand” step happens at each layer, letting the model carry more information per token without making the backbone wider.
They also pair VWN with Multi-Token Prediction (MTP):
- MTP trains the model to predict not just the next word, but the next two (or more) words. Think of it as practicing short phrases, not just single words.
- This gives denser feedback, which helps use the wider representations more effectively.
In short: VWN = wider embeddings + smart connections (GHC) + optional MTP, all while keeping the core model width the same. It’s like giving the model a bigger notebook for each word, and adding a translator that fits those bigger notes into the same-sized machine, then expands them back after processing.
What did they find and why is it important?
The researchers tested VWN on large mixture-of-experts (MoE) models (these are models with multiple “specialists” that handle different inputs). Key results:
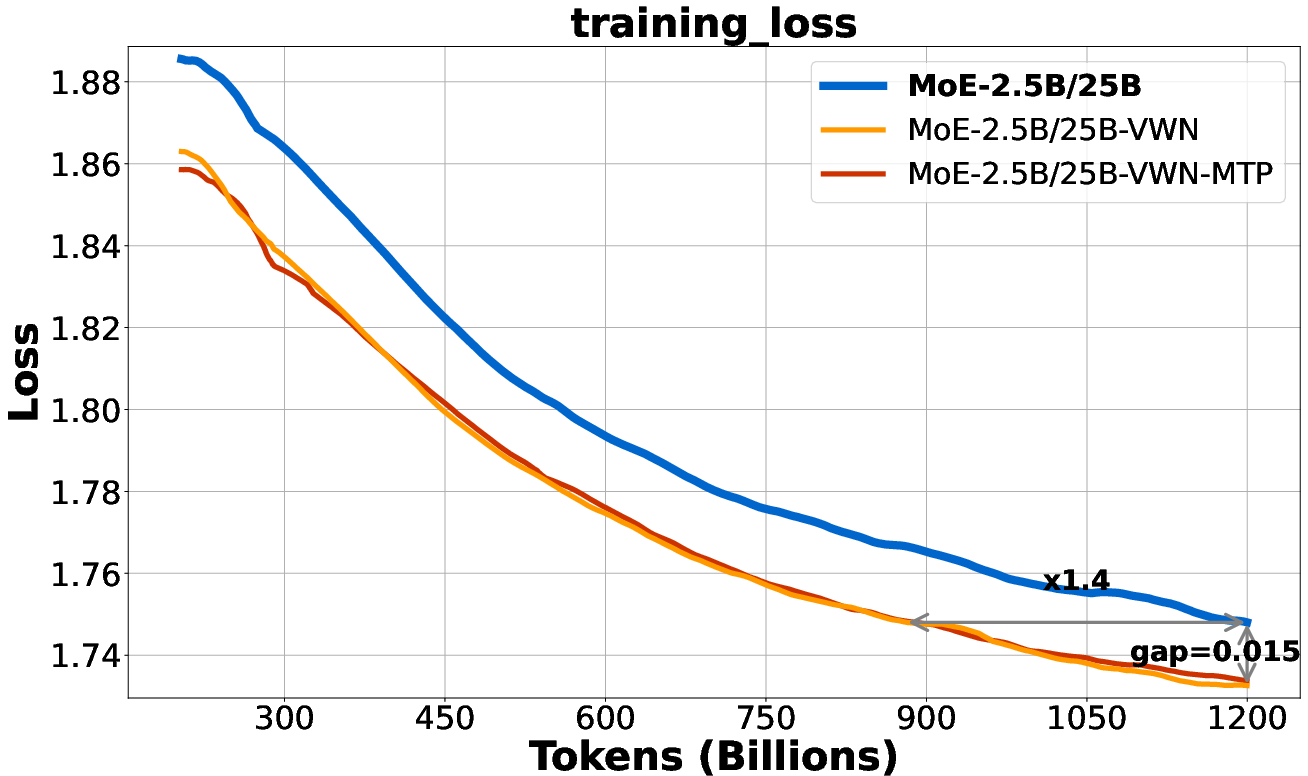
- Faster learning with the same backbone:
- With an 8× wider embedding space (they call this “virtual width factor” r=8), the model reached the same next-word loss as the baseline using about 2.5× fewer training tokens.
- For predicting two words ahead, it reached the same loss using about 3.5× fewer tokens.
- Better performance over time:
- The advantage grew throughout training. The loss gap (how much lower the VWN loss was) got bigger as training continued.
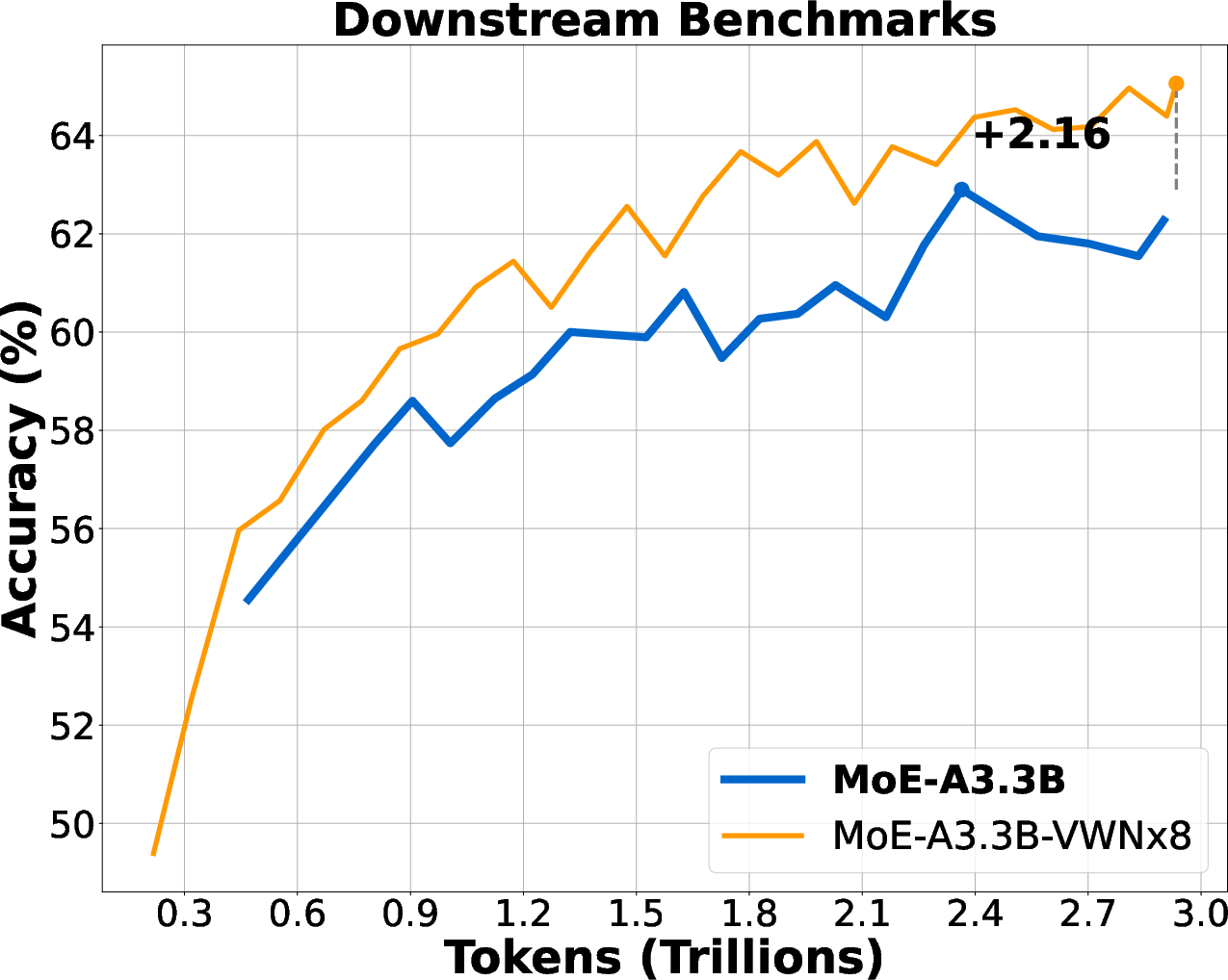
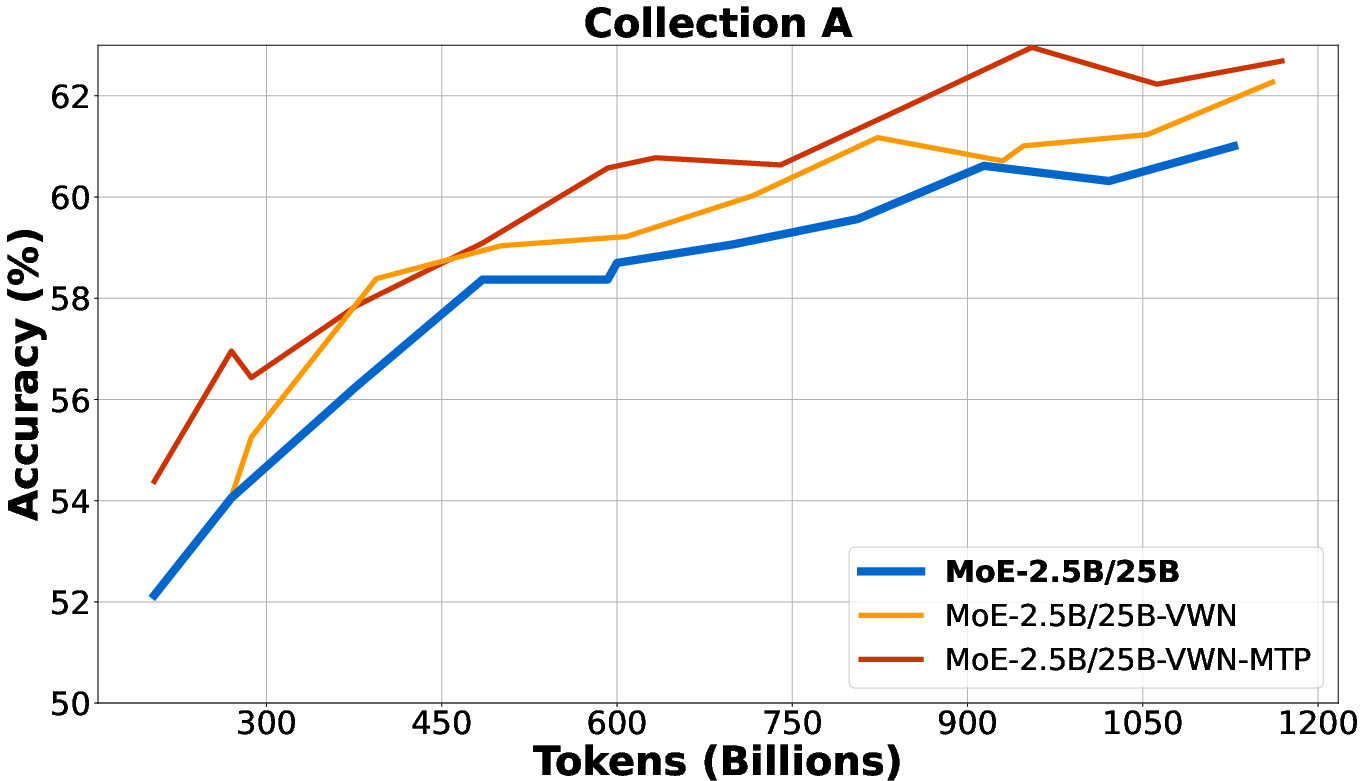
- Improved accuracy on benchmarks:
- On internal collections of tasks, VWN models scored noticeably higher (for example, +2.16 points on a large setup, and up to +4.16 points in smaller ablations). In their system, a 1-point gain is already a meaningful difference.
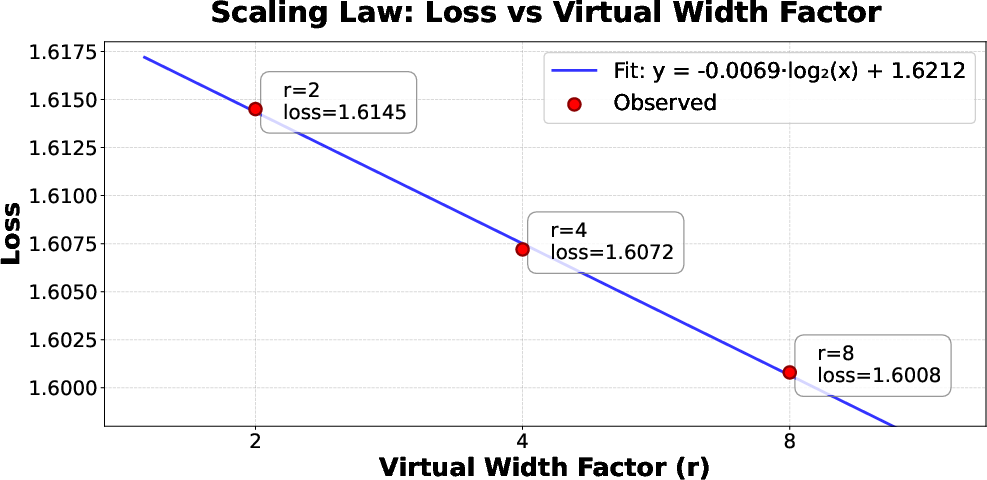
- A simple scaling pattern:
- They found an approximately log-linear relationship between virtual width and loss: every time they doubled the virtual width, the loss dropped by about 0.0069 on their setup. This gives a predictable rule of thumb for how much improvement to expect when widening the embeddings.
Why it matters: Lower loss with fewer tokens means the model learns more efficiently. Higher accuracy means it performs better on real tasks. And having a predictable “scaling law” helps engineers plan how to grow models smartly.
What’s the potential impact?
- A new, efficient way to scale models: VWN adds a “virtual width” knob. Instead of making the whole model bigger (which is expensive), you can widen just the embeddings and use GHC to keep compute low. This offers a practical path to better performance without huge hardware costs.
- Works well with MTP: Training to predict multiple tokens at once uses the wider representations more fully, improving learning and downstream accuracy.
- Token efficiency: VWN reaches the same quality with fewer training tokens, which can save time and money.
- Real-world limits: Extremely wide setups (like 8×) may need better software and hardware support to be easy to deploy. Today, the authors suggest 1.5×–4× widening is the most practical range on typical systems.
Bottom line
Virtual Width Networks let models “think wider” without making their core much bigger. They learn faster, perform better, and follow a simple, useful scaling rule. This could become a standard tool for building more capable LLMs efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, missing analyses, and open questions that future work could address to strengthen and generalize the findings.
- External validity beyond MoE backbones
- VWN is only evaluated on internal Mixture-of-Experts (MoE) models; its effectiveness on dense Transformers, hybrid attention/state-space models, multimodal architectures, and non-autoregressive settings remains untested.
- Transparency and reproducibility of datasets and benchmarks
- Training data sources are internal and not described; downstream results are aggregated via undisclosed task weights (Collections A/B) without per-task breakdowns. Open, reproducible benchmarks and data documentation are needed.
- Formal specification and clarity of GHC/DGHC
- Several equations for GHC/DGHC contain malformed symbols and ambiguous definitions (e.g., hat and circ operators, shapes of A/B blocks). A precise, unambiguous mathematical specification and reference implementation are required for reproducibility.
- Missing end-to-end compute and throughput measurements
- Claims of “minimal compute overhead” are not corroborated by wall-clock throughput, GPU utilization, latency, energy, or cost-per-token metrics. Reported token-efficiency gains may not translate to real compute savings without these measurements.
- Inference-time behavior and serving constraints
- The impact of VWN on autoregressive generation (latency, memory footprint, KV-cache behavior, batch size limits, beam search) is not quantified. Practical serving viability for large r, and behavior under long sequences, are unknown.
- Parameter count and memory trade-offs
- The increase in parameters from over-width embeddings and per-layer routing matrices (A, B, dynamic projections) is not quantified relative to baselines. Memory overhead during inference and implications for model deployment are not measured.
- Stability and hyperparameter sensitivity
- Training stability conditions (e.g., spectral radius of carry operators, normalization strategy, LR schedules) are not analyzed. Sensitivity to learning rates, weight decay on dynamic parameters, τ scaling, and normalization choices needs systematic study.
- Choice of reduce operator and initialization
- The reduce operator (linear projection vs. GroupNorm variants) and initialization are admitted as untuned. A systematic ablation of reduce operators, normalization placements, and initialization strategies is missing.
- Optimal selection of m and n as a function of model scale
- The limited m ablation suggests saturation beyond m≈4 at small scale, but guidance for selecting m and n across depths, widths, and datasets is absent. A principled heuristic or scaling rule is needed.
- Scope and robustness of the scaling law
- The observed log-linear relation between loss and virtual-width factor r is measured only for one backbone (MoE-A0.8B, fixed m=8). Generalization across model sizes, training budgets, optimizers, LR schedules, and tasks is untested. Confidence intervals and statistical robustness are not reported.
- Upper bounds and diminishing returns
- Behavior at very large r (e.g., >8) is unknown. Identifying regimes of saturation, instability, or diminishing returns—and how they depend on D, L, m, n, and data quality—is an open question.
- Fairness of comparisons and training recipes
- Some experiments used a constant learning rate to “control training length”—atypical in LLM training. It is unclear whether observed gains persist under standard LR schedules and well-tuned baseline recipes.
- Multi-Token Prediction (MTP) interplay and configuration
- MTP sometimes hurts next-token loss at smaller scales, and only k=2 is explored. The optimal k, loss weighting, head designs (shared vs. unshared block-level mixing), and impacts on NTP vs. downstream generalization remain to be mapped.
- Interaction with tokenization and vocabulary scaling
- Although OE/OD and hierarchical n-gram embeddings are discussed, VWN is not systematically paired with input-side vocabulary expansion. The combined effects and best practices for Over-Encoding with VWN are unexplored.
- Task-specific impacts
- VWN is hypothesized to enhance short-range compositional modeling, but effects on long-context tasks (e.g., long document QA, code completion), reasoning benchmarks, and multilingual settings are not reported.
- Comparative baselines under matched compute
- Head-to-head comparisons against alternative capacity-increasing methods (e.g., depth scaling, wider dense layers, grouped/low-rank projections, adapters/LoRA, tensor-product representations) under matched FLOPs/throughput are missing.
- Hardware and systems co-design
- The paper notes current hardware is unfriendly to very wide activations and cross-device routing. Concrete memory layouts, kernel designs, interconnect strategies, quantization/compression approaches, and pipeline/parallelism plans to support large r are not provided.
- Training-time memory strategies
- The activation checkpointing/recomputation scheme is presented at a high level. Empirical evaluation of memory savings vs. recomputation overhead and the effect on throughput is absent.
- Effects on attention internals and representational dynamics
- How GHC compression/expansion impacts attention head utilization, information bottlenecks, and gradient flow across layers is unknown. Diagnostic analyses (e.g., probing, CKA, representational similarity) could clarify what VWN actually changes.
- Safety, robustness, and fine-tuning
- Behavior under instruction tuning, RLHF/DPO, domain adaptation, and robustness to distribution shift is untested. Potential effects on safety alignment, calibration, and catastrophic forgetting are unexplored.
- Missing algorithmic components in pseudocode
- The forward-pass algorithm lists a compression matrix R but does not use it, and block reshaping semantics are unclear. A corrected pseudocode with all components exercised is needed.
- MoE-specific interactions
- Interactions between VWN routing and MoE gating (e.g., expert selection dynamics, load balancing, and expert specialization) are not analyzed. Potential synergies or conflicts remain an open area.
- Practical guidance for deployment
- Concrete guidelines for selecting r, m, n under real-world latency/memory/throughput constraints—and how to tune VWN for given hardware—are not provided.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, drawing directly from the paper’s findings and implementation guidance.
- Efficiency upgrades in LLM pretraining across industry and academia
- What to do: Integrate VWN into existing Transformer/MoE training stacks with modest virtual width (r ≈ 1.5–4), configure fraction rate m ≈ 4–8, and add the block-level MTP head for multi-token supervision.
- Expected impact: 2–3× token savings to reach equivalent loss (demonstrated up to 3.5× for next-2-token), shorter time-to-quality, improved downstream accuracy at similar backbone compute.
- Sectors: Software (AI SaaS, code assistants), Finance (domain LLMs for compliance/risk), Healthcare (biomedical NLP, EHR summarization), Education (tutoring LLMs, content generation).
- Tools/workflows: PyTorch/Megatron-LM plugins; replace residuals with GHC; expand embeddings via linear projection or multi-gram OE; fuse normalization + width-connection kernels; enable activation recomputation (η ≈ 0.5).
- Assumptions/dependencies: Current hardware stacks support r up to ~4× reliably; benefits measured on MoE backbones and large-scale training; minor FLOPs and memory overhead manageable with kernel fusion and recompute.
- Cost-effective domain adaptation (fine-tuning) with fewer tokens
- What to do: For proprietary or limited datasets, fine-tune with VWN+MTP to achieve target quality with fewer tokens.
- Expected impact: Reduced GPU hours and cost; more feasible specialization for smaller teams.
- Sectors: Finance (specialized regulatory corpora), Healthcare (clinical notes), Legal (contracts), Customer support (FAQ/domain knowledge).
- Assumptions/dependencies: Data pipelines can supply multi-token supervision; frameworks implement the block-level projector to avoid dense mixing cost at width r.
- Immediate deployment of higher-quality models at similar inference cost
- What to do: Swap baseline models for VWN-trained models in production; inference compute remains near-constant while accuracy improves due to enhanced representational capacity.
- Expected impact: Better response quality in chatbots, search, code completion, and content tools without increasing per-token inference costs.
- Sectors: Software (copilots), Search/Ads (ranking, query understanding), Productivity apps (document assistants).
- Assumptions/dependencies: Model serving stacks accommodate the small parameter overhead; no major runtime changes required beyond model replacement.
- Hyperparameter search and training policy optimization using virtual-width scaling
- What to do: Treat r as a new scaling dimension in model selection; leverage the observed log-linear relation between r and loss to optimize budgets and schedules.
- Expected impact: More predictable scaling of quality-per-compute; improved planning of training runs, early stopping, and checkpoint selection.
- Sectors: Academia (scaling law research), Industry (ML Ops, cost governance).
- Assumptions/dependencies: Loss–r relation holds within the tested ranges; internal metrics translate to target benchmarks; monitoring tools track token efficiency.
- Sustainability-oriented procurement and reporting
- What to do: Adopt VWN+MTP recipes to reduce energy and carbon per training milestone; include virtual width in efficiency KPIs.
- Expected impact: Lower training emissions for the same quality; compliance with sustainability targets.
- Sectors: Policy (corporate ESG), Cloud/Compute procurement, Research labs.
- Assumptions/dependencies: Organizational willingness to change training recipes; accurate energy accounting and benchmark alignment.
- Academic benchmarking and replication
- What to do: Reproduce VWN results on public benchmarks; run ablations on m and r; test synergy with MTP across tasks.
- Expected impact: Establish virtual width as a standard efficiency lever; broaden evidence across datasets and modalities.
- Sectors: Academia, Open-source community.
- Assumptions/dependencies: Availability of open-source VWN/GHC implementations; comparable training scales and datasets.
- Practical workflow reference for teams upgrading their stacks
- What to do:
- 1) Replace residual connections with GHC (configure m,n; r = n/m),
- 2) Expand input embeddings via linear projection or multi-gram OE,
- 3) Add the block-level shared projector for MTP mixing (per-segment (2D/m)→(D/m)),
- 4) Fuse normalization and width-connection kernels; enable activation recomputation to manage memory,
- 5) Train with a stable LR schedule and monitor token efficiency, adjusting r and m as needed.
- Assumptions/dependencies: Engineering capacity for kernel fusion; compatibility with MoE and transformer backbones; adequate profiling to manage I/O bottlenecks.
Long-Term Applications
The following applications depend on further research, scaling, or co-design with systems and hardware before broad deployment.
- Hardware–software co-design for very wide configurations (r ≥ 8)
- What to build: Memory layouts, interconnect strategies, compilers, and fused kernels optimized for over-width activations and cross-device routing.
- Expected impact: Unlock the full gains observed at r=8 (and beyond), making large virtual width practical at scale.
- Sectors: Cloud/HPC vendors, Accelerator design, Large labs.
- Assumptions/dependencies: Vendor support; coordinated runtime, compiler, and kernel engineering; robust distributed training stacks.
- Extension of VWN to non-language modalities
- What to explore: Vision Transformers, diffusion models, audio/speech, time-series forecasting, graph transformers.
- Expected impact: Wider representations at near-constant backbone width could improve sample efficiency and short-range compositional modeling across modalities.
- Sectors: Robotics (policy learning), Energy (grid/load forecasting), Media (image/video generation), Healthcare (medical imaging), Finance (multimodal risk).
- Assumptions/dependencies: Demonstrations that GHC and virtual width generalize to modality-specific architectures; task-appropriate multi-token or multi-step supervision.
- Virtual-width-aware compilers, schedulers, and AutoML
- What to build:
- Compilers/runtime that optimize activation I/O and fuse VWN operations,
- Cluster schedulers that plan r and m under memory/throughput constraints,
- AutoML “Virtual Width Tuner” to pick r,m per model size and depth.
- Expected impact: Systematic, automated gains in quality-per-compute; fewer engineering cycles per model.
- Sectors: ML platforms, Cloud operations, MLOps tooling.
- Assumptions/dependencies: Stable APIs for VWN modules; telemetry for token efficiency and I/O hotspots.
- Adaptive and task-conditioned virtual width
- What to explore: Dynamic r per layer or per token, input-conditioned GHC, routing that adapts representational width to task complexity.
- Expected impact: Better efficiency on-device or under strict latency budgets; per-request quality tailoring.
- Sectors: Mobile/edge AI, Real-time assistants, Robotics control.
- Assumptions/dependencies: Robust training of dynamic matrices; stable inference with adaptive width; safeguards against instability.
- Multi-token decoding and short-range compositional improvements in production
- What to build: Inference-time strategies that leverage MTP for better next-n predictions without large mixing costs, e.g., block-level decoding policies for code autocomplete and text editing.
- Expected impact: Higher-quality autocompletion and editing suggestions in everyday tools; improved user experience for short-span predictions.
- Sectors: Productivity apps, Developer tools, Search.
- Assumptions/dependencies: Efficient, latency-friendly MTP heads; UX tuning to blend n-gram predictions with standard decoding.
- Policy and standards for energy-efficient foundation models
- What to do: Establish reporting standards that recognize virtual width as an efficiency dimension; incentivize low-emission training practices (including VWN).
- Expected impact: Sector-wide reduction in training-related emissions; wider adoption of efficiency-enhancing algorithms.
- Sectors: Regulators, Standards bodies, Corporate ESG.
- Assumptions/dependencies: Consensus on metrics; industry uptake; auditable disclosures tied to compute budgets and model quality.
- New productized tooling
- What to build:
- “VWN Kit” libraries for major frameworks (PyTorch/JAX) with GHC modules and block-level MTP heads,
- Profilers for “depth connectivity” and activation I/O,
- Configuration assistants for choosing m,n under compute/memory constraints.
- Expected impact: Lower barrier to adoption and repeatable wins across teams.
- Sectors: Open-source ecosystem, Model engineering platforms.
- Assumptions/dependencies: Community/contributor support; clear licensing; integration with common training recipes and MoE layers.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- Activation recomputation: A memory-saving training technique that recomputes certain activations during backpropagation instead of storing them. "employing selective activation recomputation \cite{korthikanti2023reducing}"
- AltUp: A prior method that enhances model expressiveness by cheaply expanding hidden dimensions through compositional links. "Hyper‑Connections (HC)\citep{zhu2024hyper} and AltUp\citep{baykal2023alternating} enhance model expressiveness by expanding the hidden dimension through low‑cost compositional links across layers."
- Block-level linear: A shared small linear projection applied per block/segment to fuse features at wider widths with low cost. "To address this, we perform mixing with a block-level linear."
- Carry operator: A learned mechanism that transports and attenuates information across layers in the widened state slots. "where $\big(\hat{\mathbf{A}^{\,l}\big)^{\intercal}$ transports/attenuates information stored in the slots (a learned carry/forget operator)"
- Conditional computation: Strategies that activate only part of a model per input to increase capacity without proportional compute cost. "conditional computation strategies that expand model capacity without proportionally increasing computational costs."
- Depth receptive field: The effective range of preceding layers whose information influences the current layer under soft routing. "effectively enlarging the ``depth receptive field''."
- Dynamic Generalized Hyper‑Connections (DGHC): An input-conditioned version of GHC where routing matrices are dynamically generated from the representations. "we introduce a dynamic extension of the GHC method, termed Dynamic GHC (DGHC), where the transformation matrices are adaptively conditioned on input representations "
- Feed‑Forward Network (FFN): The per-layer multilayer perceptron component of a Transformer that processes hidden states after attention. "integrates self-attention layers or feed-forward networks within transformers."
- FLOPs: Floating-point operations; a standard measure of computational cost. "The normalization operation (e.g. RMSNorm) requires FLOPs, per token."
- Frac‑Connections (FC): A connectivity scheme that partitions hidden dimensions into smaller segments rather than enlarging width. "Frac‑Connections (FC)~\citep{zhu2025frac} take the opposite approach: instead of enlarging the hidden size, they partition the existing hidden dimension into multiple smaller segments"
- Generalized Hyper‑Connections (GHC): The paper’s unifying, lightweight routing mechanism that compresses and expands over‑width states around backbone modules. "We propose Generalized Hyper-Connections (GHC), a novel method to effectively leverage wider token embeddings while maintaining the original hidden dimension during intermediate layer computations."
- GroupNorm: A normalization technique that normalizes groups of channels/features; here used before reducing virtual partitions. "In the setting, group normalization preceding the reduce operator (used to aggregate virtual partitions) is omitted."
- Hyper‑Connections (HC): A prior connectivity method that expands hidden dimensions via low-cost compositional links across layers. "models employing methods such as Hyper‑Connections~\cite{zhu2024hyper} or AltUp~\citep{baykal2023alternating} can be regarded as simplified instances within the broader VWN family."
- KV cache: A cache of key-value representations (here along depth) used to retain and attend to prior layer information. "hidden states act as a ``vertical KV cache''."
- Linear‑attention‑like mechanism: A fixed-cost attention analogue over depth realized via learned routing rather than dot-product attention. "learned, fixed-cost, linear-attention-like mechanism over depth that scales the accessible depth context."
- Log‑linear scaling relation: A relationship where loss reduction scales linearly with the logarithm of a variable (here, virtual width factor). "we identify an approximately log‑linear scaling relation between virtual width and loss reduction"
- Logits: Pre-softmax scores output by a model’s final projection, representing unnormalized log probabilities. "before the unembedding layer to produce the output logits."
- Megatron‑LM: A large-scale training framework for Transformer models with optimized memory and parallelism strategies. "In a typical training framework like Megatron-LM, each token in a vanilla transformer layer requires $34D$ bytes for activation storage"
- Mixture‑of‑Experts (MoE): A conditional computation architecture that routes each token to a subset of specialized expert networks. "mixture-of-experts (MoE) architectures \citep{shazeer2017sparsely, lepikhin2020gshard, fedus2022switch}"
- Multi‑Token Prediction (MTP): An auxiliary objective predicting multiple future tokens to provide denser supervision. "Multi-Token Prediction (MTP) serves as an approximation of -gram decoding."
- n‑gram loss: A training objective that supervises predictions of sequences of n tokens (n‑grams). "optimizing both the standard next-token objective and an auxiliary -gram loss."
- Over‑Decoding (OD): A method that enhances output supervision by supervising multiple token predictions. "Over-Decoding (OD) to enhance output supervision via multi-token prediction objectives."
- Over‑Encoding (OE): A method to scale input representations via multi‑gram tokenization, enriching embeddings. "Over-Encoding (OE) to scale input representations using multi-gram tokenization"
- Over‑Tokenized Transformer: A framework that scales input/output representations through multi‑gram tokenization and multi‑token objectives. "The Over-Tokenized Transformer framework~\citep{huang2025over} introduced Over-Encoding (OE) to scale input representations using multi-gram tokenization and Over-Decoding (OD) to enhance output supervision via multi-token prediction objectives."
- Over‑Width Embedding: A widened token embedding used as input to VWN to increase representational capacity at low compute cost. "To increase the embedding dimensions, we propose the Over-Width Embedding technique."
- Over‑Width Hidden States: The widened intermediate representations maintained across layers within VWN. "the intermediate representations are correspondingly referred to as Over‑Width Hidden States."
- Residual connections: Skip connections that add a layer’s input to its output to ease optimization and maintain information flow. "we replace the standard residual connections with Generalized Hyper‑Connections (GHC)"
- RMSNorm: Root-mean-square normalization; a lightweight normalization variant commonly used in Transformers. "The normalization operation (e.g. RMSNorm) requires FLOPs, per token."
- Routing matrices: The learned matrices in GHC that compress, write, and carry information between over‑width and backbone states. "routing matrices "
- Scaling laws: Empirical laws relating model/data scale to performance, guiding efficient scaling strategies. "According to scaling laws \citep{kaplan2020scaling, hoffmann2022training}, expanding either model parameters or the size of the training corpus yields more capable models."
- Spectral radius: The largest absolute eigenvalue of a matrix; below one implies exponential decay in recurrent contributions. "When the spectral radius of $\big(\hat{\mathbf{A}^{\,l}\big)^{\intercal}$ is below 1, Eq.~\eqref{eq:depth_unroll_explicit} implies exponentially decayed contributions from preceding layers."
- Token efficiency: The extent to which a model achieves lower loss or higher accuracy with fewer training tokens. "We report training dynamics and token efficiency relative to matched non‑VWN baselines"
- Transformer backbone: The fixed-width core Transformer stack (attention and FFN blocks) around which VWN adds virtual width. "keeping the hidden dimensions of the Transformer backbone fixed."
- Unembedding layer: The final projection from hidden states back to vocabulary logits for token prediction. "before the unembedding layer to produce the output logits."
- Virtual width factor r: The ratio by which embedding width is expanded relative to backbone width in VWN. "configured with a virtual width factor of ."
- Virtual Width Networks (VWN): The paper’s framework that widens representations via embeddings while keeping backbone compute nearly constant. "We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size."
Collections
Sign up for free to add this paper to one or more collections.