- The paper introduces Over-Encoding to expand input vocabularies, revealing a log-linear relationship between vocabulary size and training loss.
- It decouples input and output vocabularies using n-gram embeddings, improving efficiency without incurring extra computational costs.
- The methodology employs tensor parallelism to handle large embedding tables, achieving faster convergence with minimal overhead.
The paper "Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling" (2501.16975) investigates the impact of tokenization on the performance and scalability of LLMs. It introduces the Over-Tokenized Transformer framework, proposing a novel approach to decouple input and output vocabularies to enhance LLM efficiency and efficacy.
Introduction
The research highlights that while tokenization is crucial in LLMs, its effects on scaling laws and performance are underexplored. The study reveals that expanding the input vocabulary size through multi-gram token embeddings can significantly improve model scalability. It establishes a log-linear relationship between input vocabulary size and training loss, suggesting that larger vocabularies enhance model performance without additional computational costs. Decoupling input and output vocabularies allows the model to leverage larger vocabularies more effectively for input while avoiding the computational penalties of expanding output vocabularies for smaller models.
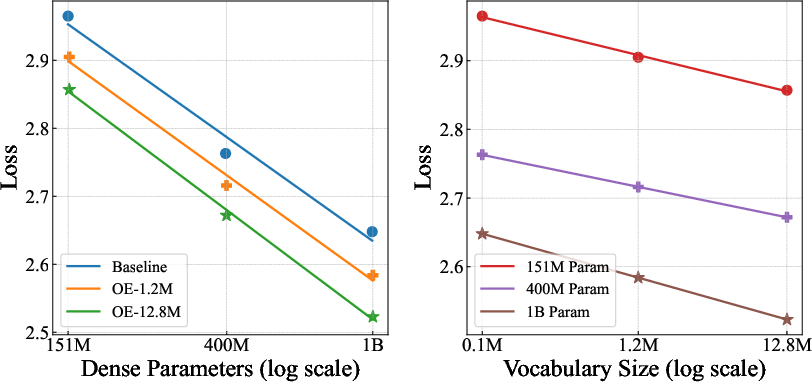
Figure 1: Scaling trend for Over-Encoded models and baselines on OLMo2 during 400B tokens' training.
Tokenization Design and Scaling Vocabulary
The research examines various tokenization strategies, such as Byte-Pair Encoding (BPE) and n-gram modeling, concluding that larger tokenizer vocabularies benefit LLMs by reducing sequence length and enhancing training efficiency. The paper also emphasizes separate considerations for embedding and unembedding (input and output vocabularies), noting that they exhibit distinct scaling behaviors.
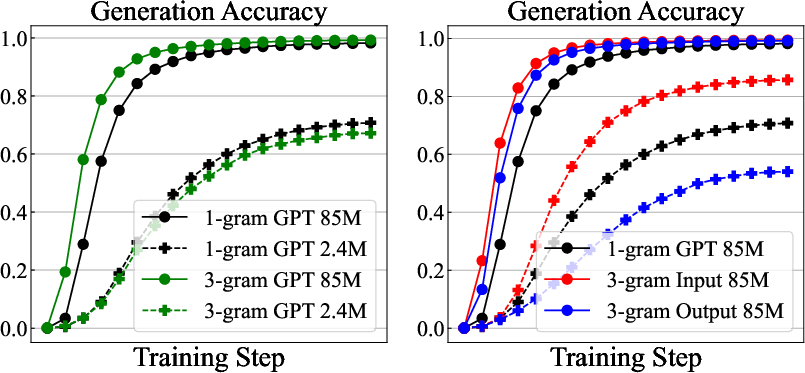
Figure 2: Performance comparison for models trained on CFG data, showing the impact of 1-gram and 3-gram tokenizers.
Over-Encoding (OE)
The study introduces Over-Encoding (OE) to scale input vocabularies using large hierarchical n-gram embeddings. OE is shown to bring significant performance improvements, enabling smaller models to match larger baseline models without additional costs. The technique involves creating a configurable vocabulary size extendable via matrix decompositions, allowing efficient embedding lookups.
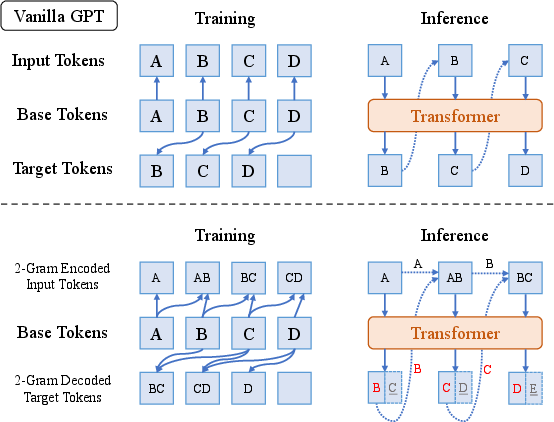
Figure 3: Illustration of 2-gram encoding/decoding GPT, preserving next-token prediction while maintaining inference cost.
Over-Decoding (OD) and OT Integration
Over-Decoding (OD) employs larger output vocabularies for detailed supervision, typically effective for larger models. Combining OE and OD results in the Over-Tokenized Transformer, leveraging advanced multi-token prediction methods to enhance model learning. The integration amplifies the advantages of wide token embeddings and improved supervision for future token predictions, achieving better performance with minimal additional costs.
Engineering Challenges and Solutions
Practical implementation of OE presents memory and computational challenges, particularly with large embedding tables. The paper suggests using tensor parallelism to mitigate overheads and proposing novel training frameworks to optimize embedding lookups and offload management. The implementation demonstrates less than 5% overhead when scaling to very large models.
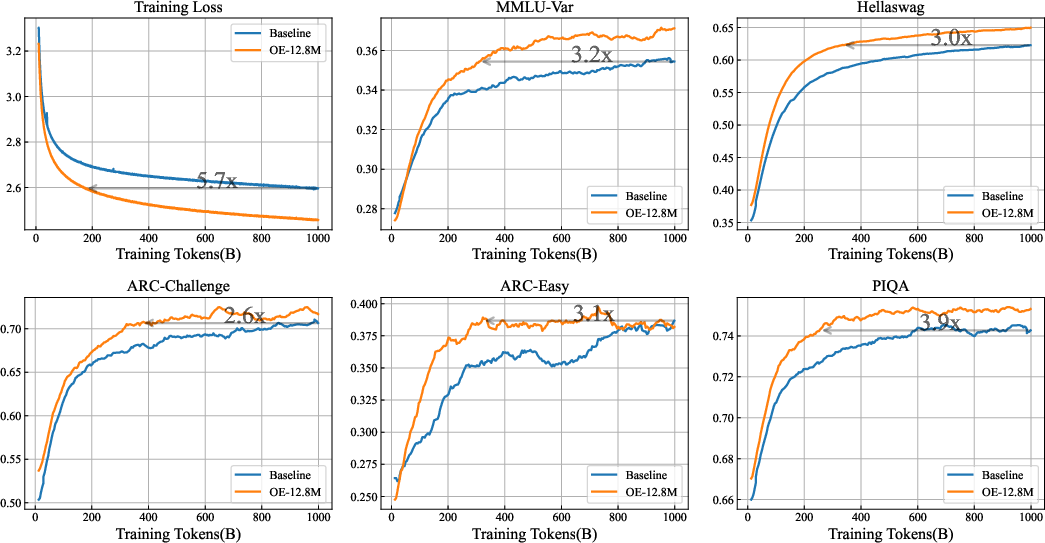
Figure 4: Training curves for OE-12.8M and baseline model on OLMo2-1B, displaying significant convergence acceleration.
Conclusion
The paper emphasizes the importance of tokenization in LLM scaling, proposing strategies to optimize tokenizer design for enhanced performance and efficiency. The introduction of the Over-Tokenized Transformer demonstrates the potential of decoupling vocabularies and leveraging larger input vocabularies to drive the advancements of LLMs. The findings set the stage for further exploration into tokenization strategies and their integration into future models, highlighting independent scaling of vocabularies as a pivotal factor in LLM evolution.

