URaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Abstract: Recent multimodal LLMs (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI model to read very long documents made of many pages (like PDFs with text, tables, and images) more quickly and accurately. The authors introduce a method called URaG that helps the AI “skim first, read carefully later,” just like people do, so it focuses only on the pages that matter.
What questions did the researchers ask?
They explored two simple questions:
- How can we help AI models avoid getting distracted by lots of irrelevant pages in long documents?
- Can we make these models both faster and more accurate by letting them find the right pages on their own, while they think about the answer?
How did they do it?
First, a quick background: A “multimodal LLM” (MLLM) is an AI that can handle both text and images. A “Transformer” is a common AI architecture for understanding sequences (like words or image tokens). When you feed a very long document into a Transformer, the computing cost grows very quickly as the document gets longer.
The authors noticed something interesting: inside these models, the early layers act like skimming—they look broadly at many pages—while the deeper layers act like careful reading—they focus on the right pages. They turned this natural behavior into a feature.
Here’s their approach, URaG, in everyday terms:
- They add a tiny “retrieval” module inside the model’s early layers. Think of it as a smart highlighter.
- This module matches the user’s question with each page’s content (text and visuals) to score which pages are most relevant.
- The model then keeps only the top few pages (for example, the best 5) and throws out the rest for the next steps.
- With fewer, more relevant pages, the deeper layers can concentrate on understanding and answering the question.
To train it well, they use two steps:
- Step 1: Teach the tiny retrieval module to pick relevant pages (while keeping the rest of the big model frozen).
- Step 2: Fine-tune both the retrieval part and the main model together so they work smoothly as one system.
What did they find?
Their results show several clear wins. Here are the main takeaways:
- Better accuracy on tough benchmarks: URaG achieves state-of-the-art results on long-document tasks like MPDocVQA, DUDE, SlideVQA, MMLongBench-Doc, and LongDocURL.
- Much faster: It cuts the heavy computation by about 44–56% on long inputs, because it stops processing irrelevant pages early.
- Smarter reading behavior: Measurements confirm the model naturally “skims first, then zooms in,” similar to how people read.
- Tiny add-on, big impact: The retrieval module is extremely small (well under 1% of total parameters) but noticeably boosts performance.
- Best placed early: Putting the retrieval step in the early layers works best—early enough to filter pages, leaving deeper layers to reason over the right content.
Why does it matter?
This work shows a practical way to make AI truly useful for long documents in the real world—things like contracts, reports, scientific PDFs, or slide decks:
- It’s more accurate because the model focuses on the right evidence.
- It’s faster and cheaper because it doesn’t waste effort on irrelevant pages.
- It’s simpler to deploy because retrieval and answer generation happen inside one model, trained end-to-end (no separate retrieval system required).
In short, URaG helps AI read like a careful student: skim to find the right pages, then read those closely to give a better answer—quickly and efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of gaps and open issues left unresolved by the paper, formulated to be concrete and actionable for future research.
- Generalization across backbones: URaG is only validated on Qwen2.5-VL (3B/7B). It remains unclear how the approach performs or needs adapting for other MLLMs (e.g., LLaVA, InternVL, Idefics, PaliGemma) with different vision encoders, tokenization schemes, and layer dynamics.
- Layer selection policy: The retrieval module is inserted at a fixed early layer (e.g., layer 6), with limited ablation. A principled, backbone-agnostic method to select or learn the optimal insertion layer(s) across architectures and sequence lengths is missing.
- Fixed top-k selection: Evidence selection defaults to top-5 pages. There is no analysis of adaptive k (per-query or per-document), nor of scenarios where evidence spans more than 5 pages, potentially discarding needed context for cross-page reasoning.
- Single-pass retrieval: URaG performs one retrieval step. Given the observed “final rechecking” attention behavior, it is unknown if iterative or multi-stage retrieval (e.g., early coarse selection followed by late refinement or second-pass expansion) would improve accuracy and robustness.
- Hard gating and differentiability: Discarding non-retrieved pages is a hard, non-differentiable decision. The paper does not explore soft gating, continuous sparsification, or differentiable selection mechanisms that could allow gradient flow to suppressed content and potentially reduce error propagation.
- Page-level granularity: Retrieval operates at the page level. It is unclear how URaG performs on tasks requiring fine-grained region or snippet-level localization (tables cells, chart regions, small text boxes), and whether adding region-level retrieval improves precision without large compute costs.
- Cross-page reasoning limitations: URaG shows weaker performance on multi-page (MUL) questions than single-page (SIN). The failure modes and remedies (e.g., adaptive k, region-level retrieval, cross-page linking tokens) are not analyzed.
- Unanswerable questions handling: Although MMLongBench-Doc includes unanswerable (UNA) cases, URaG does not include explicit mechanisms for abstention, confidence calibration, or retrieval-aware uncertainty estimation for detecting unanswerable queries.
- Domain shift and fine-tuning instability: Fine-tuning degrades performance on LongDocURL, indicating sensitivity to domain shifts. There is no systematic analysis of why (e.g., distribution mismatch, annotation style, layout/domain characteristics) or of strategies to mitigate (e.g., domain adaptation, robust training, calibration).
- Robustness to document noise: The paper does not evaluate robustness to low-quality scans, skew, rotation, compression artifacts, handwriting, or OCR errors—common in real-world documents.
- Multilingual and non-Latin scripts: URaG is not evaluated on multilingual documents or non-Latin scripts, leaving its cross-language retrieval and generation capabilities untested.
- Task generality beyond VQA: URaG is evaluated primarily on VQA-style tasks. It is unclear how well the unified retrieval-generation paradigm transfers to information extraction, summarization, contract analysis, or question-driven workflows with multi-step reasoning.
- Efficiency metrics coverage: Compute efficiency is reported via FLOPs. Memory footprint, latency (end-to-end inference time), throughput under batch processing, and energy consumption are not measured, limiting system-level deployment insights.
- Scaling beyond 100 pages: FLOPs gains are measured up to 100 pages by duplicating inputs. The behavior and stability of URaG on real documents with hundreds to thousands of pages (and diverse layouts/resolutions) remain unknown.
- Evidence supervision dependency: Training relies on ground-truth evidence pages to always retain them. Many datasets lack page-level evidence annotations; methods for weakly supervised or self-supervised retrieval training without explicit evidence labels are absent.
- Similarity function design: The retrieval uses contextualized late interaction (ColBERT-style dot-product maxima). There is no comparison to alternatives (e.g., cross-attention scoring, margin-based metric learning, temperature-scaled cosine similarity) or to hybrid text-vision retrievers inside the MLLM.
- Token compression synergy: URaG is compared against token compression, but not combined with it. Whether hybrid approaches (retrieval + compression) yield superior efficiency-accuracy trade-offs is unexplored.
- Training regimen sufficiency: Retrieval pretraining and joint fine-tuning are each conducted for only one epoch with LoRA adapters. The sensitivity to training duration, adapter rank, alpha, dropout, and loss-weight schedules is not studied.
- Error analysis of dropped evidence: There is no detailed analysis of cases where relevant pages are wrongly discarded, nor of recovery strategies (e.g., dynamic expansion, fallback requery, confidence-triggered second-pass).
- Calibration of retrieval scores: The paper lacks score calibration, thresholds, or confidence estimation to guide adaptive decisions (e.g., k selection, abstention, iterative retrieval), which could improve reliability.
- Interpretability of selections: While top-1/top-5 retrieval accuracy is reported, tools to inspect, visualize, and explain why pages are selected or dropped are not provided, limiting debuggability and trust in evidence localization.
- Interaction with final-layer “recheck” behavior: The analysis suggests deeper layers revisit all pages before answering. URaG discards pages early, potentially conflicting with this natural behavior; whether a late-stage expansion or reintroduction improves correctness is untested.
- Hybrid systems with external retrievers: Although URaG aims to avoid external retrievers, the potential benefits of hybrid designs (e.g., coarse external retriever feeding URaG’s fine in-model selection) are not studied.
- Multi-document scenarios: Retrieval is page-scoped within a single document. URaG’s ability to retrieve across multiple documents (e.g., a corpus of PDFs) and maintain coherent cross-document reasoning is not evaluated.
- Structured evidence types: While improvements are reported for charts and images, specialized handling for complex tables, forms, and math-heavy pages (e.g., structural parsing or layout-aware retrieval features) is not addressed.
- Reproducibility details: The paper lacks fine-grained disclosure of preprocessing (e.g., page resolution, normalization), batching and interleaving strategies for multi-page inputs, and exact dataset splits, which can hamper exact replication and fair comparison.
- Privacy and security: The implications of in-model retrieval for sensitive documents (e.g., compliance, auditability, leakage in memory states) and defenses against adversarial or poisoned pages are not discussed.
- Adaptive token-level sparsification within pages: URaG discards entire pages but retains all tokens within selected pages. Methods to sparsify within-page visual tokens (e.g., layout-aware masking) to further reduce compute without losing fine detail are unexplored.
Practical Applications
Practical Applications of URaG: Unified Retrieval and Generation for Long Document Understanding
The following applications translate the paper’s findings and innovations into concrete use cases across industry, academia, policy, and daily life. Each item is categorized by readiness and linked to relevant sectors. Dependencies and assumptions that may affect feasibility are noted inline.
Immediate Applications
These can be piloted or deployed now with current MLLM stacks (e.g., Qwen2.5-VL) and the lightweight URaG module.
- Enterprise contract and compliance copilot (Legal, Finance)
- Use case: Ask detailed questions about multi-clause contracts, SLAs, NDAs, or compliance policies and receive answers with the top-k evidence pages retained.
- Tools/workflow: DMS integration; “Answer + Evidence Pages” UI; LoRA-adapted URaG module on top of existing MLLMs.
- Assumptions/dependencies: Domain-specific fine-tuning improves accuracy; secure on-prem or VPC deployment for sensitive content; evidence is mostly single-page or limited cross-page.
- Financial filings and earnings-report assistant (Finance)
- Use case: Rapid Q&A over 10-K/10-Q, earnings call transcripts, prospectuses with evidence highlighting and reduced inference cost.
- Tools/workflow: Analyst portal plugin; API for automated report triage and KPI extraction.
- Assumptions/dependencies: Consistent PDF formatting; tuning for financial terminology; governance for audit trails.
- Health administration document intake and triage (Healthcare)
- Use case: Process multipage scanned forms (claims, referrals, prior auths) without OCR and route cases based on retrieved evidence pages.
- Tools/workflow: URaG integrated with hospital intake systems; PHI-safe deployment; human-in-the-loop verification.
- Assumptions/dependencies: Administrative—not clinical—use; strict privacy/compliance (HIPAA/GDPR); domain adaptation to form layouts.
- Insurance claims packet analysis (Insurance)
- Use case: Identify relevant pages across claim forms, estimates, photos; expedite adjuster workflows with evidence localization.
- Tools/workflow: Claims processing pipeline; evidence heatmap; triage prioritization.
- Assumptions/dependencies: Variable document quality; occasional cross-page evidence may require raising k beyond the default 5.
- Technical manual and product support assistant (Software, Consumer Electronics, Manufacturing)
- Use case: Customer or agent Q&A over long product manuals with page-level evidence; faster, cheaper inference than baseline MLLMs.
- Tools/workflow: Chatbot integration; “show-relevant-pages” widget; offline manual indexing.
- Assumptions/dependencies: Access to updated manuals; multilingual support may need additional tuning.
- Academic literature assistant (Academia)
- Use case: Question answering across multi-article PDFs or long dissertations with explicit evidence pages.
- Tools/workflow: Library/research portal plugin; citation-aware response generation within URaG.
- Assumptions/dependencies: Generalization to scholarly domains; handling figures/tables relies on strong vision tokens.
- Public records and FOIA analysis (Government/Policy)
- Use case: Policymakers and journalists query meeting minutes, reports, legislative documents; URaG retains evidence for accountability.
- Tools/workflow: Evidence-traceable Q&A dashboards; exportable audit trails.
- Assumptions/dependencies: Document heterogeneity; unanswerable detection needs configuration to avoid false positives.
- Corporate knowledge management (Enterprise IT)
- Use case: Internal PDFs, handbooks, SOPs—search and Q&A with evidence retention; lower FLOPs reduce cloud spend.
- Tools/workflow: Intranet chatbot; MLLM gateway with URaG module; logging of retrieval decisions.
- Assumptions/dependencies: Access controls and identity; document lifecycle metadata to boost retrieval.
- PDF viewer plugin with “Evidence-Aware Q&A” (Software)
- Use case: End users ask questions within a PDF app; receive answers and page pointers with coarse-to-fine reasoning.
- Tools/workflow: Local or cloud inference; small parameter overhead (≈0.05–0.07%); UI highlights of retained pages.
- Assumptions/dependencies: GPU/CPU optimization for desktop/mobile; license compliance for MLLM backbone.
- Cost-optimized MLLM inference service (Software Infrastructure)
- Use case: Reduce FLOPs by 44–56% for long-document tasks vs baseline, improving throughput and costs.
- Tools/workflow: URaG as a service; autoscaling; billing tied to retained pages count.
- Assumptions/dependencies: Backbone support (e.g., Qwen2.5-VL 3B/7B); quantization and caching strategies for production.
Long-Term Applications
These require further research, scaling, productization, or ecosystem standardization.
- Cross-page synthesis at scale and dynamic k selection (All sectors)
- Use case: Robust reasoning over multi-evidence spread across many pages; adaptive retention beyond fixed top-5.
- Tools/workflow: Dynamic retrieval thresholds; iterative evidence aggregation; uncertainty estimation.
- Assumptions/dependencies: Improved training for multi-page evidence chains; better unanswerable detection.
- Edge/mobile document copilots (Healthcare, Logistics, Field Services)
- Use case: Run URaG-like models on scanners/MFPs or mobile devices for on-site triage and extraction.
- Tools/workflow: Quantized/optimized models; streaming inference; limited memory execution.
- Assumptions/dependencies: Hardware acceleration; compression without losing key visual details.
- RegTech and audit-grade “Evidence-First AI” (Finance, Insurance, Government)
- Use case: Regulatory submissions with verifiable evidence traces; standardized retrieval logs for compliance.
- Tools/workflow: Evidence provenance ledger; certification frameworks; auditor dashboards.
- Assumptions/dependencies: Industry standards for AI evidence trails; third-party validation; model governance.
- Real-time streaming document processing (Operations, Digitization)
- Use case: Progressive retrieval as pages arrive from scanners or feeds; immediate triage before full document is available.
- Tools/workflow: Streaming coarse-to-fine modules; early-layer checkpoints; incremental computation.
- Assumptions/dependencies: New training paradigms for streaming inputs; robust partial-context reasoning.
- Multimodal extensions to long videos, CAD, and code (Media, Engineering, Software)
- Use case: Coarse-to-fine retrieval over long timelines or complex artifacts (e.g., video manuals, design specs, repositories).
- Tools/workflow: Domain-specific encoders; cross-modal evidence matching; temporal retrieval mechanisms.
- Assumptions/dependencies: New benchmarks; specialized tokenization and late interaction designs.
- Autonomous document workflow agents (Enterprise Automation)
- Use case: Agents that read, extract, validate, and update systems with minimal human oversight, using evidence-aware retrieval.
- Tools/workflow: Orchestration with BPM/RPA; exception handling; policy-safe actions.
- Assumptions/dependencies: High reliability thresholds; auditability; integration with ERP/CRM.
- Risk scoring and unanswerable detection (Legal, Policy, Customer Support)
- Use case: Flag uncertain answers or missing evidence; route to humans or trigger additional retrieval passes.
- Tools/workflow: Confidence calibration; risk-aware response policies; hybrid retrieval-generation loops.
- Assumptions/dependencies: Improved calibration metrics; labeled datasets for unanswerable cases.
- Domain-specific pretraining and datasets (Legal, Medical, Finance)
- Use case: Tailored URaG variants that excel on sector-specific document structures and jargon.
- Tools/workflow: Evidence-annotated corpora; joint retrieval-generation fine-tuning; privacy-preserving training.
- Assumptions/dependencies: Access to high-quality labeled data; legal permissions; synthetic data augmentation for coverage.
- Federated/on-prem private deployments (Sensitive Sectors)
- Use case: Keep data local while leveraging URaG’s efficiency; cross-site learning without centralizing documents.
- Tools/workflow: Federated fine-tuning of retrieval modules; secure aggregation; policy-compliant logging.
- Assumptions/dependencies: Infrastructure maturity; privacy-preserving protocols; organizational buy-in.
- Standardized SDKs and APIs for “RAG-less” evidence-aware document AI (Software Ecosystem)
- Use case: Community adoption of unified retrieval-generation patterns to reduce system complexity vs external retrievers.
- Tools/workflow: Open SDK; model-agnostic adapters; monitoring and explainability tools.
- Assumptions/dependencies: Broad developer support; compatibility across MLLM backbones; governance for responsible use.
Notes on general dependencies and assumptions across applications:
- Backbone MLLM quality and licensing (e.g., Qwen2.5-VL 3B/7B) impact accuracy and deployability.
- Page retention defaults (k=5) may need tuning for heavy cross-page evidence tasks.
- Privacy, compliance, and audit requirements vary by sector and may necessitate on-prem/VPC deployments.
- Document quality (scans, layout complexity) influences retrieval effectiveness; some domains benefit from optional OCR augmentation.
- Human-in-the-loop validation is advisable for high-stakes contexts until robust unanswerable detection and calibration are in place.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update in Adam to improve generalization. "with AdamW optimizer."
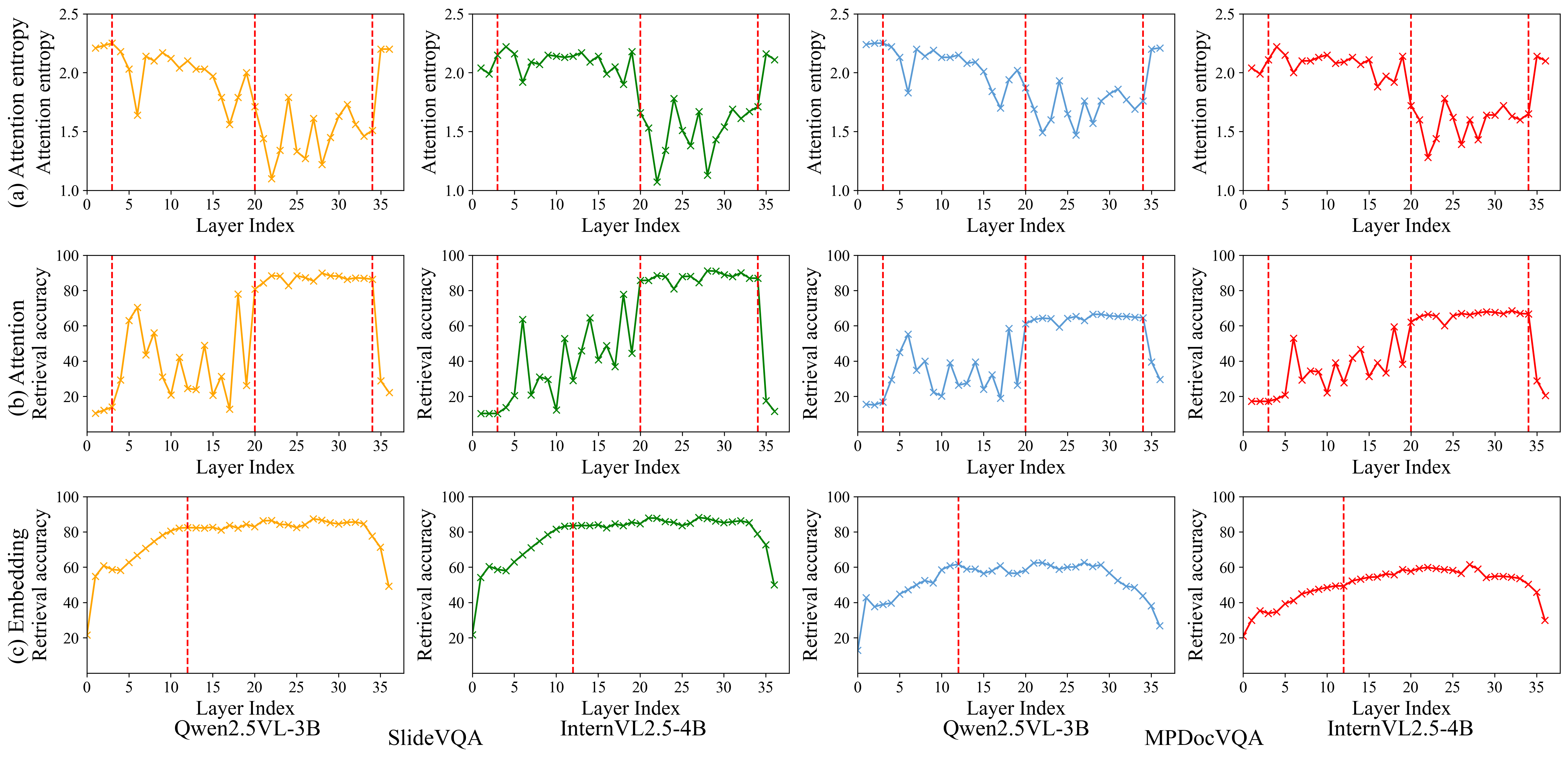
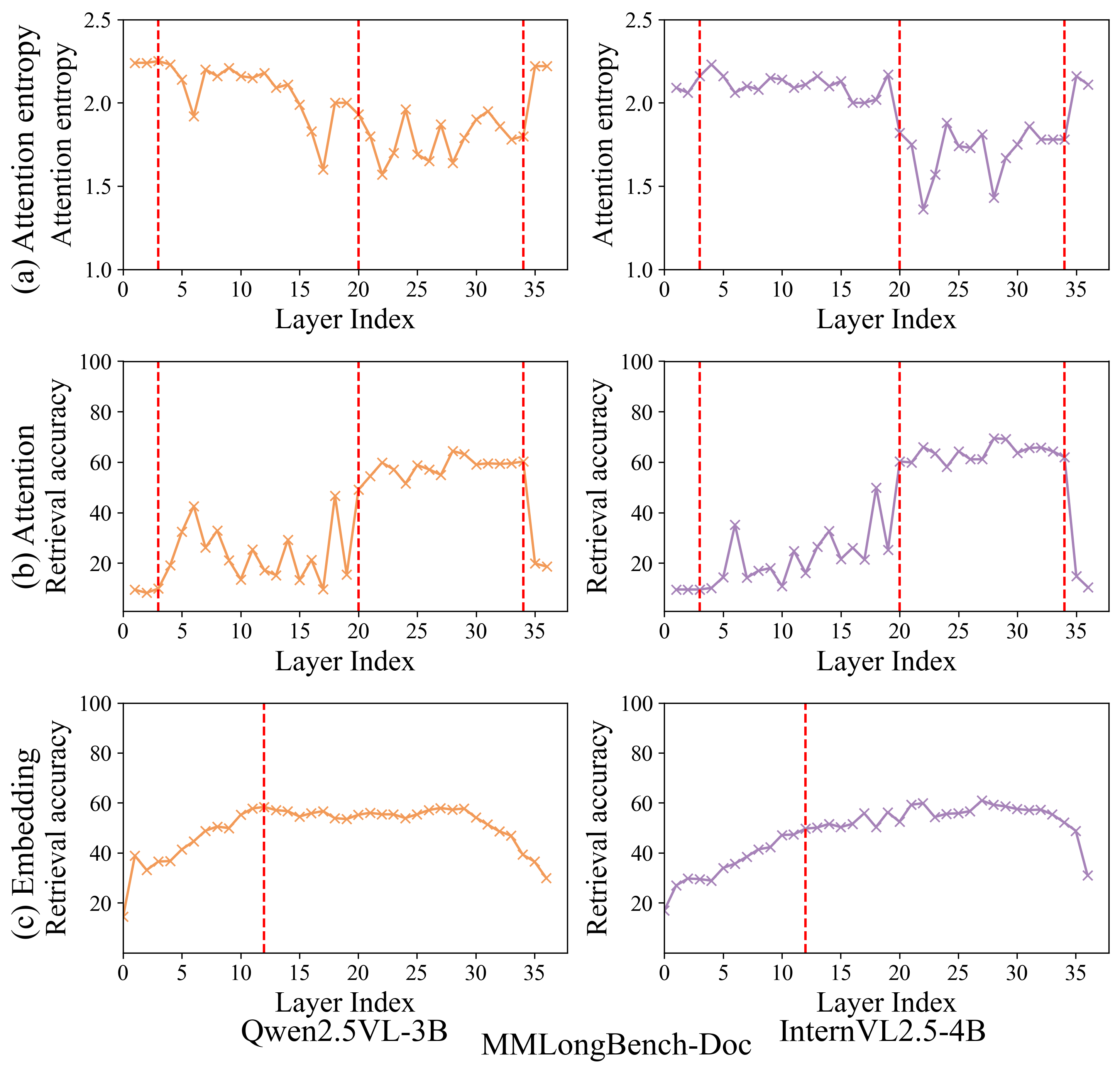
- Attention entropy: A measure of how spread out the attention distribution is across inputs; higher entropy indicates more uniform attention. "we visualize the attention entropy across LLM layers"
- Attention-based retrieval: Evidence selection that uses attention weights as retrieval scores to rank relevant pages. "attention-based retrieval accuracy shows a corresponding upward trend."
- Average Normalized Levenshtein Similarity (ANLS): A text similarity metric that normalizes Levenshtein distance, commonly used to evaluate VQA outputs. "The generation metrics include Average Normalized Levenshtein Similarity (ANLS)~\cite{tito2023hierarchical} for MPDocVQA and DUDE"
- Contextualized late interaction: A retrieval scoring scheme that computes token-level maximum similarities after contextual encoding for fine-grained matching. "Using a contextualized late interaction mechanism~\cite{khattab2020colbert}, it computes relevance scores"
- Cosine decay schedule: A learning rate schedule that decays the rate following a cosine curve over training. "followed by a cosine decay schedule."
- Cross-entropy loss: A standard objective for training generative or classification models by penalizing deviations from target distributions. "is the cross-entropy loss for answer generation."
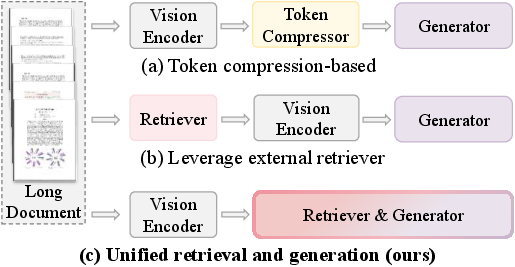
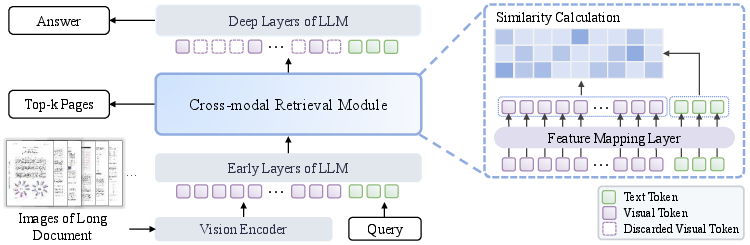
- Cross-modal retrieval module: A lightweight component that aligns text queries with visual page features to select relevant content. "URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content."
- Dense retrieval: A retrieval approach that uses continuous vector embeddings to match queries and documents semantically. "Dense retrieval methods encode text into continuous vector spaces, enabling semantic similarity matching."
- Embedding-based retrieval: Retrieval based on similarity between learned embeddings from different modalities or layers. "embedding-based retrieval reaches consistently high accuracy (e.g., around layer 12) earlier than attention-based."
- End-to-end optimization: Jointly training all components so gradients flow through the entire system for coordinated learning. "it lacks end-to-end optimization:"
- Exact Match (EM): A strict evaluation metric that requires the predicted answer to exactly match the reference. "Exact Match (EM)~\cite{tanaka2023slidevqa} for SlideVQA"
- Evidence localization: The ability of a model to identify where the answer-supporting information resides in a document. "the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process"
- Evidence selector: A mechanism that filters and retains only the most relevant evidence for downstream reasoning. "an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content."
- Floating-point operations (FLOPs): A measure of computational cost counting arithmetic operations on floating-point numbers. "Model computational cost is measured in floating-point operations (FLOPs)."
- GELU activation: A smooth activation function (Gaussian Error Linear Unit) often used in Transformers and projection layers. "with GELU activation."
- Generalized Accuracy: An evaluation metric that captures correctness across diverse formats and tasks within a benchmark. "Generalized Accuracy and F1-score~\cite{ma2024mmlongbench} for MMLongBench-Doc"
- Gradient accumulation steps: A technique to simulate large batch sizes by accumulating gradients over multiple mini-batches before updating. "The model is trained with a batch size of 4 and 8 gradient accumulation steps with AdamW optimizer."
- Hidden states: Intermediate layer representations produced by the Transformer used for retrieval or generation. "The retrieval module operates on the hidden states from an early layer (the sixth layer in our implementation) of the LLM"
- L2 normalization: Scaling vectors to unit length to stabilize similarity computations and comparisons. "followed by L2 normalization to enhance feature consistency."
- LoRA adapter: A parameter-efficient fine-tuning method that injects low-rank adapters into model layers. "In the second stage, the LoRA~\cite{hu2022lora} adapter is added to both the LLM and retrieval module"
- Multimodal LLM (MLLM): A LLM that processes and reasons over multiple modalities, such as text and images. "Recent multimodal LLMs (MLLMs) still struggle with long document understanding"
- Optical Character Recognition (OCR): Technology that converts images of text into machine-readable text for retrieval and processing. "Text-Based retrieval methods typically rely on Optical Character Recognition (OCR) to extract textual content from documents"
- Projector: A module that maps visual encoder outputs into the token space consumed by the LLM. "each page image is processed by the vision encoder and the projector to obtain a sequence of visual tokens."
- Quadratic computational complexity: The O(n2) scaling of attention with sequence length in Transformers, leading to high costs on long inputs. "due to the quadratic computational complexity of Transformer-based architectures with respect to sequence length"
- Recurrent memory: A mechanism to carry information across steps/pages, enabling sequential propagation of context. "RM-T5~\cite{dong2024multi} employs recurrent memory to propagate information across pages sequentially."
- Retrieval loss: A training objective that encourages higher scores for positive (relevant) items than for negatives. "optimized using the retrieval loss~\cite{khattab2020colbert}:"
- Token compression: Reducing the number of tokens (e.g., visual tokens) to lower computation, potentially losing fine details. "Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details;"
- Top-k: Selecting the k highest-scoring items during retrieval or ranking. "identify the top-k most relevant pages."
- Transformer-based architectures: Neural network models built on self-attention layers used for sequence modeling. "due to the quadratic computational complexity of Transformer-based architectures with respect to sequence length"
- Vision encoder: A neural network that converts images into sequences of visual embeddings (tokens) for the LLM. "each page image is processed by the vision encoder and the projector"
Collections
Sign up for free to add this paper to one or more collections.

