The Learning Dynamics of Subword Segmentation for Morphologically Diverse Languages
Abstract: Subword segmentation is typically applied in preprocessing and stays fixed during training. Alternatively, it can be learned during training to optimise the training objective. In this paper we study the learning dynamics of subword segmentation: if a LLM can dynamically optimise tokenisation, how do its subwords evolve during pretraining and finetuning? To explore this, we extend the subword segmental LLM (SSLM), a framework for learning subwords during training, to support pretraining and finetuning. We train models for three typologically diverse languages to study learning dynamics across the morphological spectrum: Isi-Xhosa is conjunctive (long word forms composed of many morphemes), Setswana is disjunctive (morphemes written as separate words), and English represents a typological middle ground. We analyse subword dynamics from a linguistic perspective, tracking morphology, productivity, and fertility. We identify four stages of subword learning, with the morphologically complex isi-Xhosa exhibiting greater instability. During finetuning, subword boundaries shift to become finer-grained. Lastly, we show that learnable subwords offers a promising approach to improve text generation and cross-lingual transfer for low-resource, morphologically complex languages.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Plain‑English Summary of “The Learning Dynamics of Subword Segmentation for Morphologically Diverse Languages”
What is this paper about?
This paper looks at how computers decide where to “cut” words into smaller pieces (called subwords) while learning a language. Instead of fixing these cuts before training, the authors let a LLM learn the best way to cut words as it trains. They watch how these subword choices change over time for three different languages: isiXhosa, Setswana, and English.
What questions did the researchers ask?
- Can a LLM learn its own way to split words into subwords while it trains?
- How do these learned subwords change during different stages of training (pretraining and finetuning)?
- Do languages with different word-building styles (like isiXhosa and Setswana) lead to different subword learning patterns?
- Does letting subwords be learned (instead of fixed) help the model write better text, especially in low‑resource languages?
How did they study it?
Think of words as Lego builds and subwords as the bricks. Many models decide on the bricks before training and never change them. This team built a model that can change its bricks as it learns, choosing cuts that help it understand and generate text better.
Here’s their approach in everyday terms:
- They extended an earlier model (SSLM) to a modern Transformer version called T‑SSLM. This model:
- Reads text character by character.
- Considers many possible ways to split the text into subwords.
- Picks the splits that make the most sense for predicting the next part of the text.
- They trained separate models on:
- isiXhosa (a “conjunctive” language where many meaningful pieces are glued into long words),
- Setswana (a “disjunctive” language where meaningful pieces are often written as separate words),
- English (somewhere in between).
- They trained in two phases:
- Pretraining: general language learning from text.
- Finetuning: focusing on a specific task (here, generating isiXhosa text from facts and making headlines).
- They tracked what kinds of subwords the model learned at checkpoints during training using three simple ideas:
- Morphological alignment: Do the subword cuts line up with real “morphemes” (the meaningful parts of words, like “un-” or “-ing”)?
- Productivity: How reusable is a subword? Does it appear in many different words?
- Fertility: On average, how many subwords does each word get cut into? (Lower fertility = bigger chunks; higher fertility = finer cuts.)
In short: the model keeps trying different ways to split words, scores them, and settles on the splits that help it learn and generate better text. The team then measures how sensible and useful those splits are.
What did they find, and why is it important?
Here are the main takeaways, explained simply:
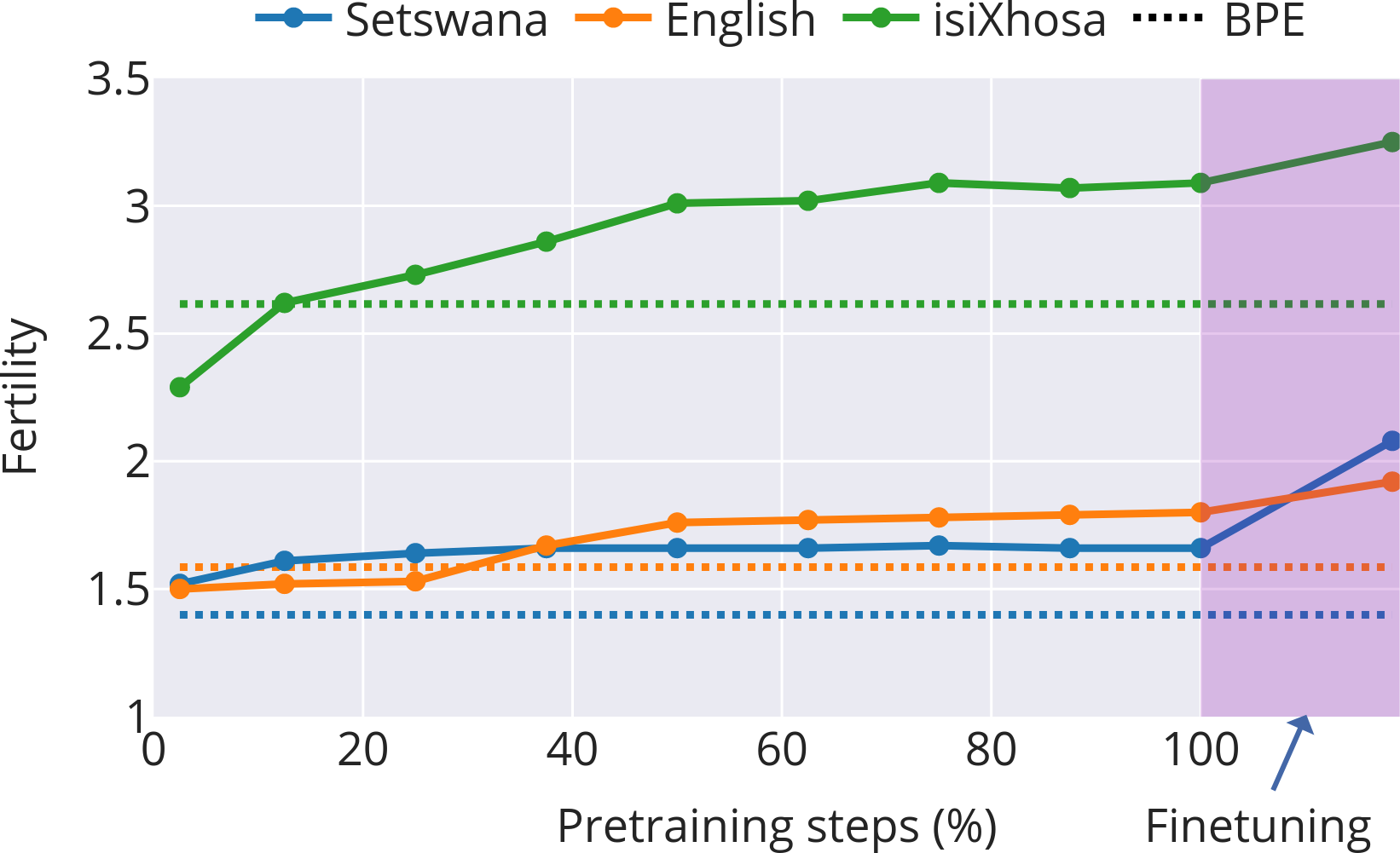
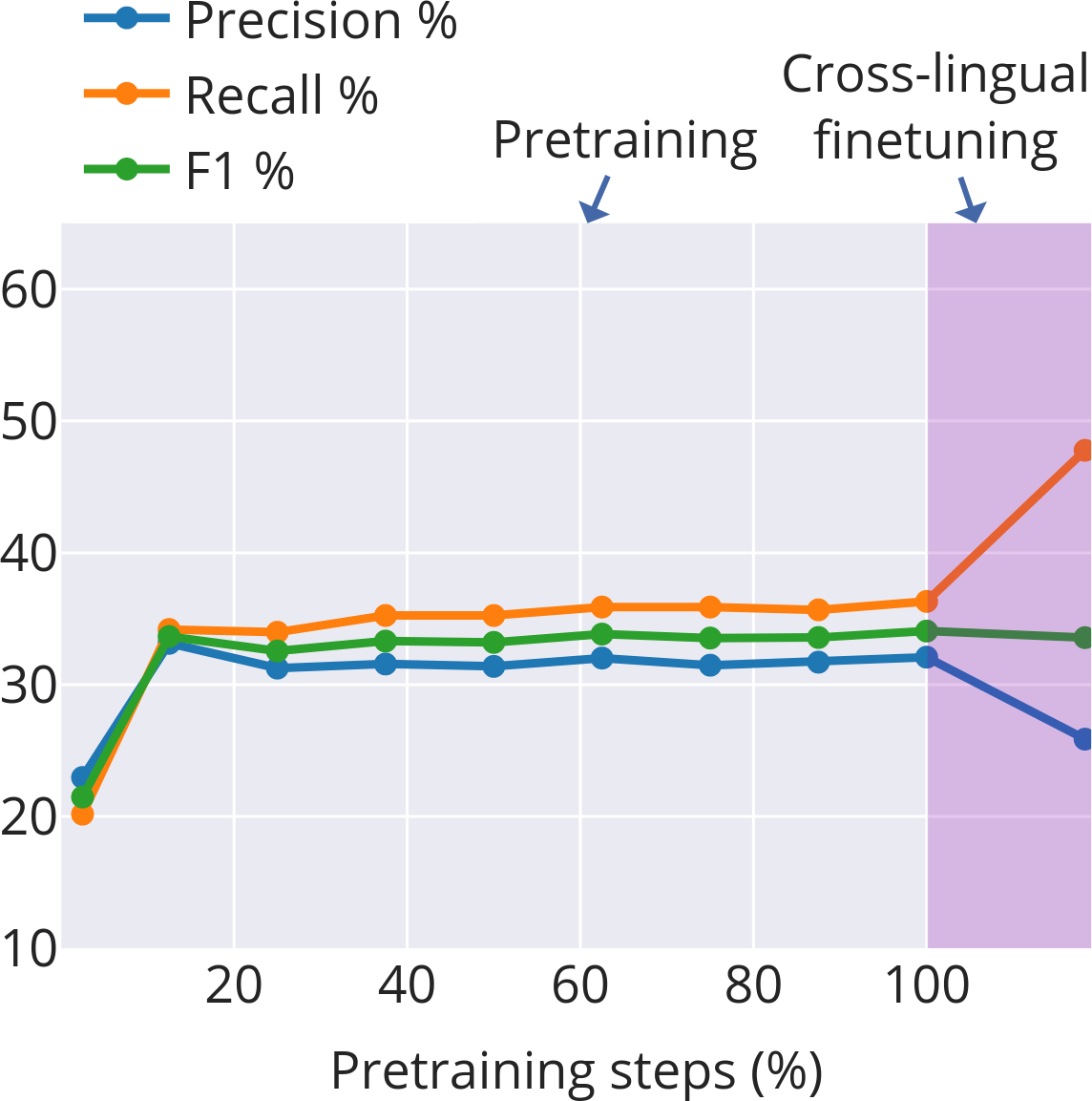
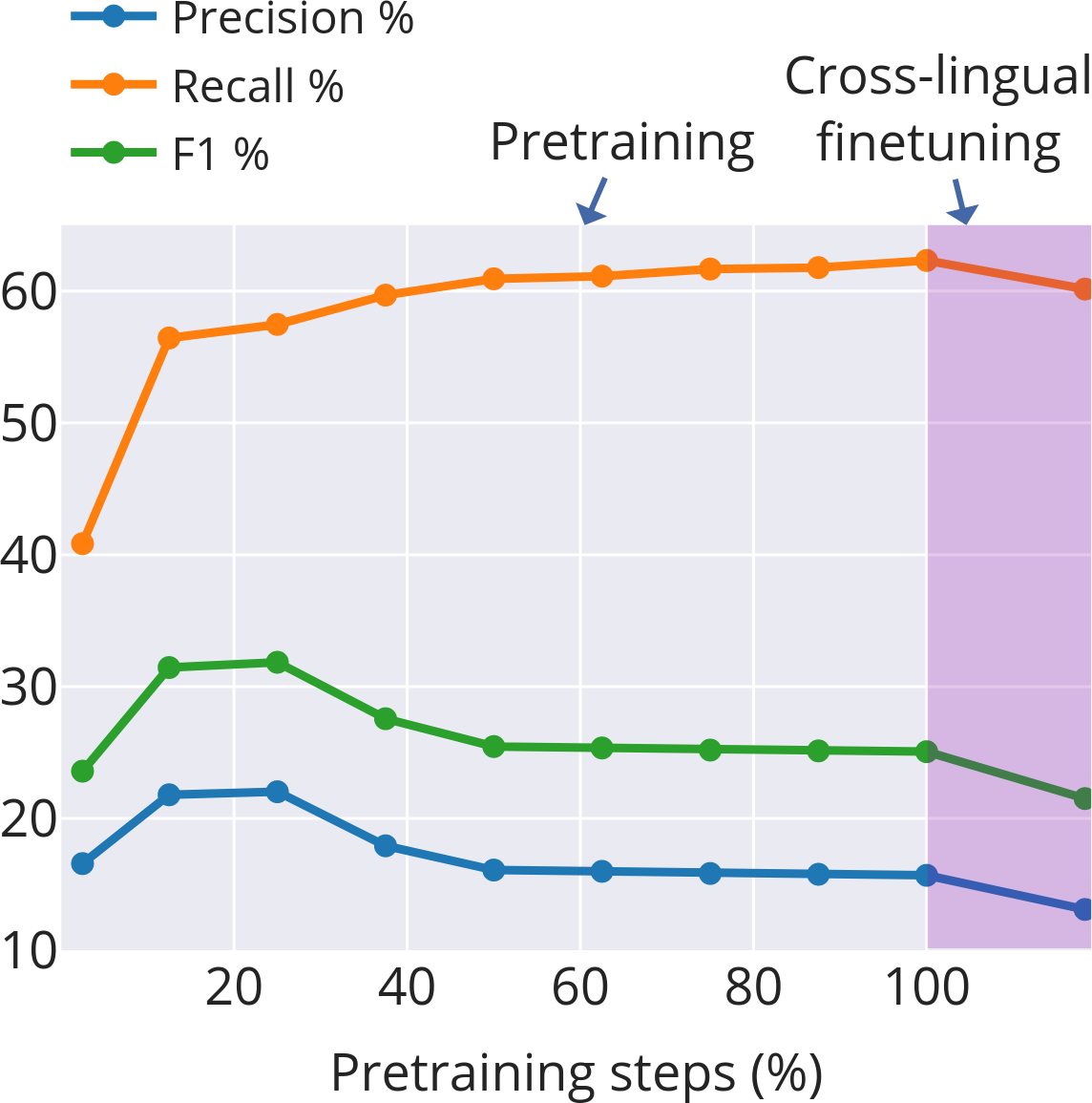
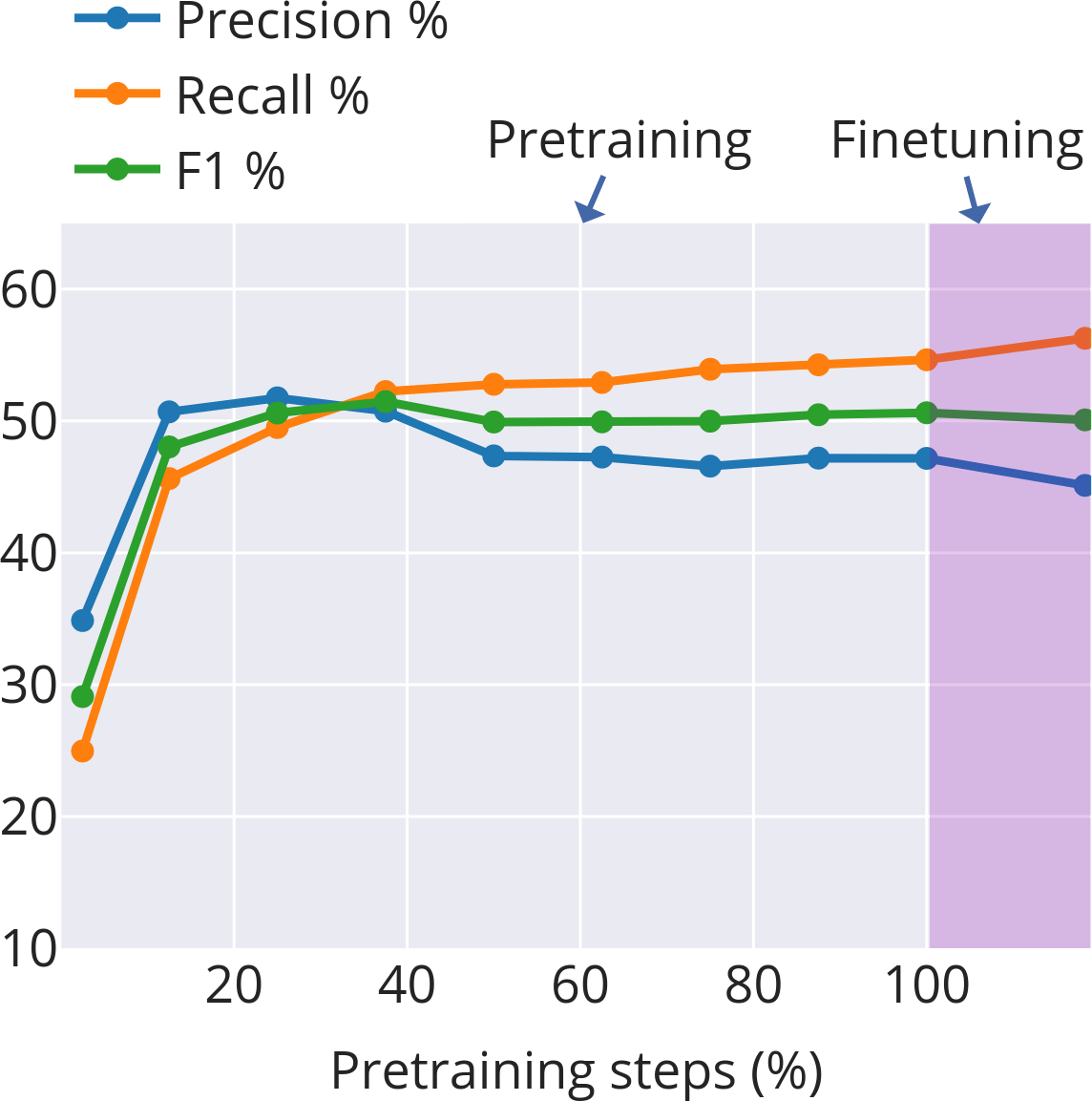
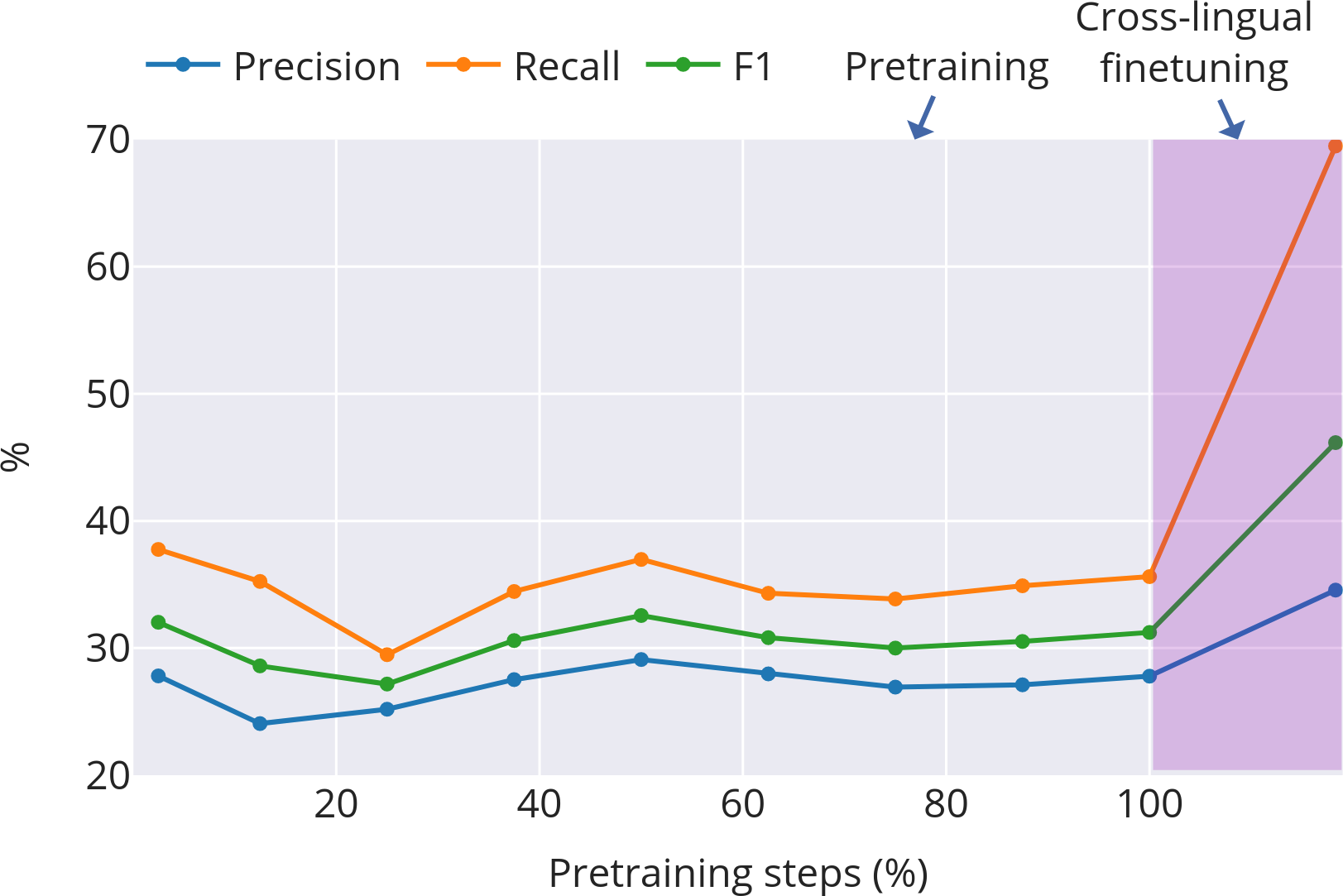
- Four stages of learning subwords: 1) Early chaos: At the start, subword boundaries change quickly. The model is figuring out basic, useful pieces—often close to real morphemes. 2) Mid-course correction (English and isiXhosa): After some training, the model shifts strategy—breaking words into slightly smaller, more reusable pieces to generalize better. 3) Stabilization: Things settle down. In Setswana (with simpler word-building), this happens early. English settles somewhat later. isiXhosa (with more complex words) stays more unsettled for longer. 4) Task focus during finetuning: When the model is tuned to a specific job (like data-to-text generation), it cuts words into smaller pieces more often. This is helpful for handling names and rare words that don’t have neat morphemes. For example, “Los Angeles” gets split mostly into characters, which is sensible because it’s a name and doesn’t follow normal word rules.
- Different languages need different subword strategies:
- Setswana converges early with relatively few cuts per word.
- English needs some fine-tuning of cuts.
- isiXhosa, with its long and complex words, keeps adjusting its cuts through training. This shows that languages with rich word structure need more flexible subword choices.
- Learned subwords beat fixed tokenization on real tasks:
- On isiXhosa text generation, the learned-subword model (T‑SSLM) produced better results than models that used fixed subword rules like BPE, and it reduced nonsense/repetitive outputs.
- Even when pretrained on English or Setswana and then finetuned on isiXhosa, the learned-subword model adapted its cuts to match isiXhosa’s structure and improved performance.
Why this matters: Many current models freeze subword rules before training. This study shows those rules should change as the model learns and as tasks change—especially for languages with complex word formation or limited data.
What does this mean for the future?
- Smarter tokenization: Letting models learn and adapt subwords over time can make them better at understanding and generating text, particularly for low‑resource and morphologically complex languages.
- Better cross‑lingual transfer: Models can adjust their subwords when switching to a new language, which helps when there’s not much training data in that language.
- Practical note: This approach costs more compute time, but it gives valuable insights into how models learn and can lead to higher‑quality outputs with fewer errors or repetitions.
Overall, the paper suggests a simple message: don’t lock in the “word pieces” too early. Let the model learn the best pieces while it learns the language and the task. This flexibility can make a real difference, especially for languages that are often underserved by today’s AI tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights concrete gaps and open questions left unresolved by the paper, prioritizing issues future researchers can directly act on:
- Scaling feasibility: How to reduce the ~10× training-time overhead from marginalizing over segmentations (e.g., through variational bounds, importance sampling over segmentations, constrained DP windows, pruning, or caching) without degrading segmentation quality and downstream performance.
- Memory/latency profile: Lack of quantitative analysis of memory use and decoding latency for T-SSLM, especially on long sequences and morphologically long words (conjunctive orthographies); need profiling and optimization strategies.
- Lexicon design sensitivity: No ablation on subword lexicon size, construction, and update policy (e.g., fixed vs. dynamically refreshed lexicon); unclear trade-offs with productivity, fertility, and downstream metrics.
- Cross-word subwords: The DP forbids subwords crossing whitespace; unexplored whether allowing multi-word units (e.g., clitics or function-word sequences in disjunctive languages) could improve modeling or transfer.
- Generalization beyond three languages: Results are limited to English, Setswana, and isiXhosa; open to testing fusional, polysynthetic, templatic, and non-alphabetic scripts (e.g., Arabic, Turkish, Finnish, Inuktitut, Chinese, Japanese) to assess typological coverage.
- Domain and corpus effects: Unknown robustness of learning dynamics to domain shifts, noisy web data, or code-switching; need controlled corpus/domain ablations and noise-robustness studies.
- Data scale sensitivity: No systematic scaling laws or data-size ablations (e.g., 100k–1B tokens) for segmentation dynamics and downstream gains; need to map regime boundaries where T-SSLM is most beneficial.
- Model size sensitivity: Unclear whether dynamics and gains hold for larger Transformers; need parameter-scaling ablations (e.g., base→large) and interaction with depth/width.
- Stability and seed variance: No analysis of variance across random seeds; open whether the four-stage dynamics and checkpoints are reproducible and where stage boundaries occur statistically.
- Loss–dynamics coupling: Missing correlation analyses between changes in segmentation metrics (fertility/precision/recall/productivity) and training losses or perplexity; causality remains unclear.
- Downstream breadth: Evaluation limited to two isiXhosa generation tasks; need tests on other tasks (MT, summarization, QA, tagging) and languages to assess generality of finetuning benefits.
- Human evaluation and broader quality metrics: Reliance on BLEU/chrF and a narrow degeneration definition; need human judgments and complementary metrics (e.g., COMET, BLEURT, MAUVE, distinct-n, factuality/hallucination rates).
- Decoding algorithm analysis: Custom decoding is introduced but not benchmarked for speed/quality trade-offs versus standard beam search or nucleus sampling; need ablations on decoding hyperparameters and robustness.
- Comparative baselines: Missing comparisons with other dynamic tokenization or character-/byte-centric architectures at similar scales (e.g., CANINE, ByT5, Charformer, tokenization-as-a-layer) beyond the five fixed-tokenization baselines.
- Finetuning strategies: No exploration of strategies such as freezing segmentation post-pretraining vs. joint finetuning, scheduled unfreezing, or task-adaptive priors over segmentations.
- Regularization/priors for segmentation: No investigation of priors or constraints (e.g., sparsity, morphology-aware priors, length penalties) that could stabilize segmentation or improve morphological alignment.
- Morphological alignment metrics: Boundary overlap is the main alignment metric; need complementary measures (e.g., morpheme-level F1, MI-based analyses, unsupervised segmentation baselines like Morfessor) and error typologies.
- Named-entity handling: Finetuning leads to character-level segmentation of names; open to principled mechanisms (e.g., NE-aware segmentation, entity caches, copy mechanisms) that avoid over-fragmentation without harming generalization.
- Cross-lingual transfer factors: Only English/Setswana→isiXhosa is tested; need a systematic study of linguistic distance, script differences, and pretraining language mix on segmentation adaptation and transfer.
- Robustness to orthographic conventions: For disjunctive languages, modeling independent morphemes as separate words may hide subword dynamics; need experiments with normalized or alternative tokenization of whitespace.
- Pretraining–finetuning mismatch: The paper shows finetuning drives finer-grained units; unclear if a curriculum (coarse→fine) or staged segmentation schedules improve performance or stability.
- Interpretability of “four stages”: The stage taxonomy is descriptive; need formal change-point detection, statistical tests, and cross-run consistency to validate stage transitions.
- Open-source reproducibility gaps: While code is released, detailed compute budgets, training durations per language/task, and hyperparameter sensitivity analyses are missing for faithful replication.
These gaps define concrete next steps to assess scalability, robustness, typological coverage, architectural design choices, and evaluation rigor for learnable subword segmentation in language modeling.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s T-SSML method (Transformer-based Subword Segmental Language Modeling), its finetuning procedure for learnable subword segmentation, and the empirical insights into subword learning dynamics across typologically diverse languages.
- Sector: Public sector, media, NGOs (Healthcare, Agriculture, Civic information)
- Use case: Low-resource data-to-text generation in local languages (e.g., isiXhosa), such as generating public health bulletins, vaccination/clinic schedules, agriculture advisories, or news headlines and summaries.
- Tools/products/workflows:
- Fine-tune T-SSLM on small, curated task datasets (e.g., triples-to-text, headline generation).
- Integrate the paper’s custom decoding and conditional likelihood DP into existing inference services.
- Deploy as a microservice in content pipelines (newsrooms, government info portals).
- Assumptions/dependencies: Clean domain-specific parallel data; moderate compute (≈10× training cost vs tokenized LMs); engineering to integrate custom decoding; quality assurance to prevent hallucinations.
- Sector: Localization, customer support, fintech, e-commerce
- Use case: Cross-lingual bootstrapping to rapidly spin up chatbots and SMS assistants in under-resourced languages by pretraining on English or related languages and finetuning with learnable subwords on target languages.
- Tools/products/workflows:
- Cross-lingual T-SSLM finetune pipelines with morphology-aware monitoring (morphological alignment, fertility, productivity dashboards).
- Entity-heavy domain tuning (names, product SKUs) with finer-grained post-finetune segmentation to reduce OOVs.
- Assumptions/dependencies: Small but representative target-language data; infrastructure to track degeneracy and morphology metrics; domain adaptation evaluation.
- Sector: Software/ML platforms (MLOps, model training)
- Use case: “Adaptive tokenization” modules for low-resource finetunes to cut repetition and incoherence in generation.
- Tools/products/workflows:
- A plug-in that swaps fixed BPE/Unigram tokenization for learnable subword finetuning (or a practical proxy: increase fertility via character fallback for entities).
- A tokenization policy scheduler that automatically shifts to finer-grained units during finetuning (as the paper shows fertility increases help).
- Assumptions/dependencies: Compatibility with existing training stacks (e.g., Hugging Face); acceptance of extra training time; ops support for custom DP/decoding.
- Sector: Academic research, NLP diagnostics
- Use case: Morphology-aware LM analysis and benchmarking across typologies using the paper’s three metrics (morphological alignment, productivity, fertility) and four-stage learning trajectory.
- Tools/products/workflows:
- Open-source T-SSLM as a research instrument to study segmentation dynamics in new languages.
- Dashboards to monitor subword boundary shift across checkpoints; Viterbi extraction of preferred segmentations.
- Assumptions/dependencies: Availability of morphologically annotated wordlists or heuristics; reproducible compute.
- Sector: News/media workflows
- Use case: Headline generation and short summarization for local-language newsrooms with reduced degeneracy and better handling of named entities.
- Tools/products/workflows:
- Fine-tune newsroom models on MasakhaNEWS-like data with learnable subwords; deploy as a “headline suggestion” tool in editorial CMS.
- Automatic character-level fallback for rare names/entities during decoding.
- Assumptions/dependencies: Editorial oversight; dataset licensing; safety and style constraints.
- Sector: Education and cultural heritage
- Use case: Rapid creation of primers, glossaries, and morphology-aware reading exercises in under-resourced languages.
- Tools/products/workflows:
- T-SSLM fine-tuned on curricular texts; generate cloze tests and morphological segmentation exercises using extracted preferred subwords.
- Assumptions/dependencies: Teacher-in-the-loop review; small curated corpora; safeguards against errors for learners.
- Sector: Data curation and annotation
- Use case: Assisted corpus building for morphologically rich languages by using learned segmentations as weak labels to guide morpheme boundary annotation and lexicon growth.
- Tools/products/workflows:
- Active-learning loops where T-SSLM’s preferred segmentations flag uncertain boundaries for annotator review.
- Assumptions/dependencies: Annotation budget; basic morphological resources for bootstrapping; governance of linguistic IP.
- Sector: Product engineering (NLP components)
- Use case: Named-entity–aware tokenization for any generator (templating engines, rule-based systems, LMs) to reduce OOV errors and garbling.
- Tools/products/workflows:
- Drop-in module that segments names into characters at generation time; apply to forms, IDs, addresses.
- Assumptions/dependencies: Tolerating character-level decoding where semantics are minimal; QA for formatting conventions.
Long-Term Applications
These opportunities require further research, scaling, or engineering, including efficiency improvements (marginalization costs), broader language coverage, and safety/evaluation standardization.
- Sector: Foundation models, multilingual AI
- Use case: Large-scale multilingual LMs with learnable tokenization that adapt segmentation across pretraining and downstream tasks, improving performance in hundreds of low-resource languages.
- Tools/products/workflows:
- “AutoTok” at scale: streaming/approximate marginalization, GPU kernels for DP, mixture-of-lexicon+char at billion-token scales.
- Assumptions/dependencies: Algorithmic/accelerator advances to reduce ≈10× cost; large, clean multilingual corpora; scalable decoding.
- Sector: Government digital services and language inclusion (policy)
- Use case: National e-services chat/voice agents that support morphologically diverse local languages with robust generation and fewer repetition artifacts.
- Tools/products/workflows:
- Procurement templates that require morphology-aware evaluation (degeneracy %, morphological alignment).
- Continuous finetuning with learnable subwords as new domains (tax, social services) are added.
- Assumptions/dependencies: Policy mandates, budget, privacy/security reviews; ongoing data stewardship; human review loops.
- Sector: Mobile keyboards/IME and on-device personalization
- Use case: Morphology-aware predictive text and auto-complete that adapt tokenization per user dialect or domain while preserving privacy.
- Tools/products/workflows:
- On-device fine-tuning of subword segmentation with federated learning; dynamic char fallback for names.
- Assumptions/dependencies: Efficient inference/training on edge; personalization safety; power/latency constraints.
- Sector: Speech technologies (ASR/TTS) and text normalization
- Use case: Better grapheme-to-phoneme and text normalization for agglutinative languages by aligning subwords with morphemes dynamically.
- Tools/products/workflows:
- Joint pipelines where T-SSLM-informed segmentation guides lexicon building and pronunciation modeling.
- Assumptions/dependencies: Paired speech–text data; integration with ASR/TTS toolchains; evaluation protocols.
- Sector: Healthcare communication and safety-critical NLG
- Use case: Patient-facing instructions and reminders in local languages with controlled generation and improved handling of entities (drug names, clinics).
- Tools/products/workflows:
- Constrained decoding with morphology-aware segmentation; domain lexicons integrated into T-SSLM’s lexicon mixture.
- Assumptions/dependencies: Regulatory validation; clinical review; robust factuality controls.
- Sector: Machine translation and cross-lingual transfer learning
- Use case: Seq2seq models with learnable tokenization on both source and target to improve translation for morphologically rich languages.
- Tools/products/workflows:
- Encoder–decoder extensions of SSLM with joint marginalization; curriculum that mirrors the four learning stages found in the paper.
- Assumptions/dependencies: Algorithmic extensions to bilingual settings; parallel corpora; decoding stability.
- Sector: Continual/online learning for rapidly changing domains
- Use case: Models that update segmentation as new entities and patterns emerge (e.g., elections, disasters), minimizing OOV errors without full retraining.
- Tools/products/workflows:
- Lightweight subword-lexicon updates; streaming DP approximations for near-real-time adaptation.
- Assumptions/dependencies: Catastrophic forgetting mitigation; data versioning; governance.
- Sector: MLOps and training science
- Use case: Training schedulers that adjust tokenization strategy according to the four subword-learning stages (e.g., early exploration, mid inflection, stabilization, task-oriented realignment).
- Tools/products/workflows:
- Automated monitors that trigger segmentation refinements (fertility targets, productivity/precision–recall trade-offs).
- Assumptions/dependencies: Reliable stage detection signals; reproducibility across languages and domains.
- Sector: Standards and evaluation (policy, industry consortia)
- Use case: Benchmarks and audits for morphology-aware generation quality in low-resource languages.
- Tools/products/workflows:
- Standard metrics bundles (degeneration %, morphological boundary F1, productivity/fertility) and model cards that report segmentation dynamics during pretraining/finetuning.
- Assumptions/dependencies: Community consensus; dataset availability; incentives in procurement/compliance.
- Sector: Cultural preservation and lexicography
- Use case: Semi-automatic morphological analyzers and lexicon expansion for under-documented languages using learned subword proposals.
- Tools/products/workflows:
- Human-in-the-loop interfaces that surface high-confidence morpheme candidates and highlight over-segmentation risks.
- Assumptions/dependencies: Expert linguist involvement; ethical data sourcing; long-term archival support.
- Sector: Enterprise content generation
- Use case: Large-scale templated content (product descriptions, notifications) in local languages with higher robustness to rare entities and fewer repetitions.
- Tools/products/workflows:
- Hybrid template+T-SSLM systems with entity-aware segmentation; domain lexicon management.
- Assumptions/dependencies: Domain-specific evaluation; governance to prevent bias/harmful content; integration with CMS/CRM systems.
Cross-cutting assumptions and dependencies
- Compute and engineering: Current T-SSLM imposes ≈10× training cost vs fixed tokenization; practical deployment at scale needs algorithmic and systems optimizations (e.g., approximate marginalization, accelerator kernels).
- Data availability and quality: Clean, representative corpora are crucial; small, domain-specific finetuning sets must be curated; for many languages, corpus creation is a precondition.
- Safety and evaluation: Degeneration, hallucination, and fairness require task-specific guardrails; morphology-aware metrics should be incorporated into QA.
- Generalization: Findings are strongest for English, Setswana, isiXhosa; broader typological coverage and tasks (beyond NLG) need validation.
- Integration: Custom decoding and DP for conditional likelihood must be integrated into existing pipelines; licensing and maintenance of open-source codebases matter.
Glossary
- Agglutinative: A morphological type where words are formed by stringing together morphemes, each typically expressing a single grammatical function. "Both are classified as agglutinative, but they differ in how orthographic (written) words are constructed"
- Beam search: A heuristic search algorithm that explores a graph by expanding the most promising nodes; commonly used in decoding sequences for text generation. "since standard beam search implementations are incompatible with the mixture model described above."
- BLEU: A reference-based metric that evaluates generated text by measuring n-gram overlap with reference texts. "We evaluate performance with BLEU \citep{papineni-etal-2002-bleu} and chrF \citep{popovic-2015-chrf}"
- BPE (Byte Pair Encoding): A subword tokenization algorithm that iteratively merges frequent character pairs to build a vocabulary of subword units. "Subword tokenisers like BPE \citep{sennrich-etal-2016-neural} and ULM \citep{kudo-2018-subword}"
- BPE-dropout: A stochastic variant of BPE that randomly drops merges during tokenization to introduce variability and improve robustness. "and (3) BPE-dropout \citep{provilkov-etal-2020-bpe}."
- Byte-based modelling: Representing text as sequences of bytes rather than characters or subwords, often robust for multilingual or low-resource settings. "and (5) byte-based modelling, both of which have been shown to outperform subword-based LMs on low-resource languages"
- Chain rule: A probability decomposition principle that expresses the joint probability of a sequence as the product of conditional probabilities. "computed using the chain rule as"
- Character-level segmentation: Tokenization that treats each character as an atomic unit rather than subwords or words. "Additionally, we use (4) character-level segmentation and (5) byte-based modelling"
- Character-level Transformer: A Transformer architecture that operates over sequences of characters instead of subword tokens. "we use a character-level Transformer for this encoding instead of an LSTM."
- chrF: A character n-gram F-score metric for evaluating generated text, capturing subword-level similarity. "We evaluate performance with BLEU \citep{papineni-etal-2002-bleu} and chrF \citep{popovic-2015-chrf}"
- Conditional likelihood: The probability of outputs given inputs, optimized in tasks like prompt-based finetuning. "prompt-based finetuning requires maximising the conditional likelihood "
- Conjunctive (orthography): An orthographic system that writes multiple morphemes together as a single word form. "Isi-Xhosa is conjunctive (long word forms composed of many morphemes)"
- Cross-lingual transfer: Leveraging knowledge learned in one language to improve performance in another language. "and cross-lingual transfer for low-resource, morphologically complex languages."
- Data-to-text: A text generation task where structured data (e.g., triples) are converted into natural language sentences. "isiXhosa data-to-text BLEU gains of 6.25"
- Disjunctive (orthography): An orthographic system that writes morphemes as separate, space-delimited words. "Setswana is disjunctive (morphemes written as separate words)"
- Dynamic programming algorithm: An approach that breaks problems into overlapping subproblems to compute results efficiently. "propose a dynamic programming algorithm to compute Eq.~\ref{marginalised_formula} efficiently."
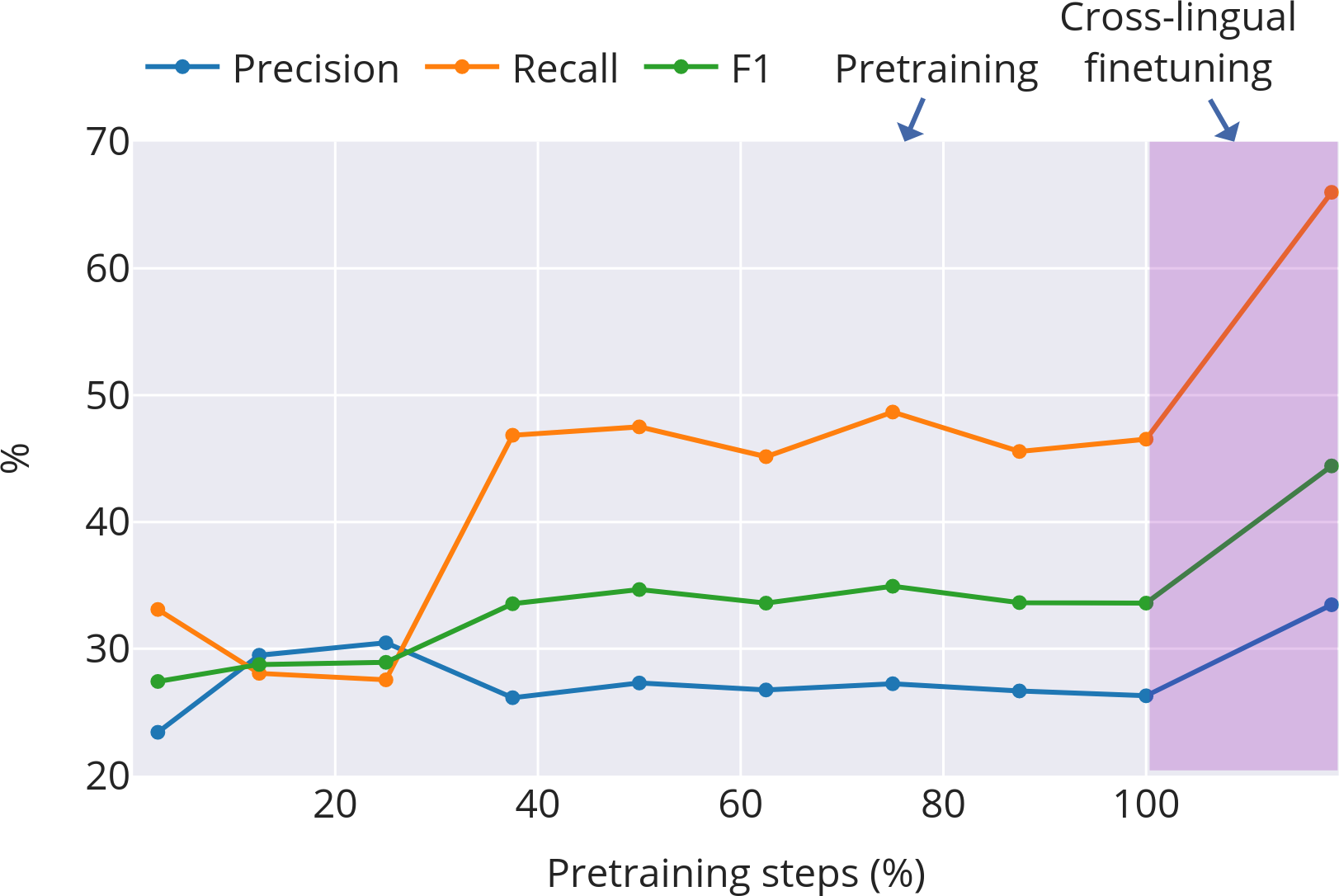
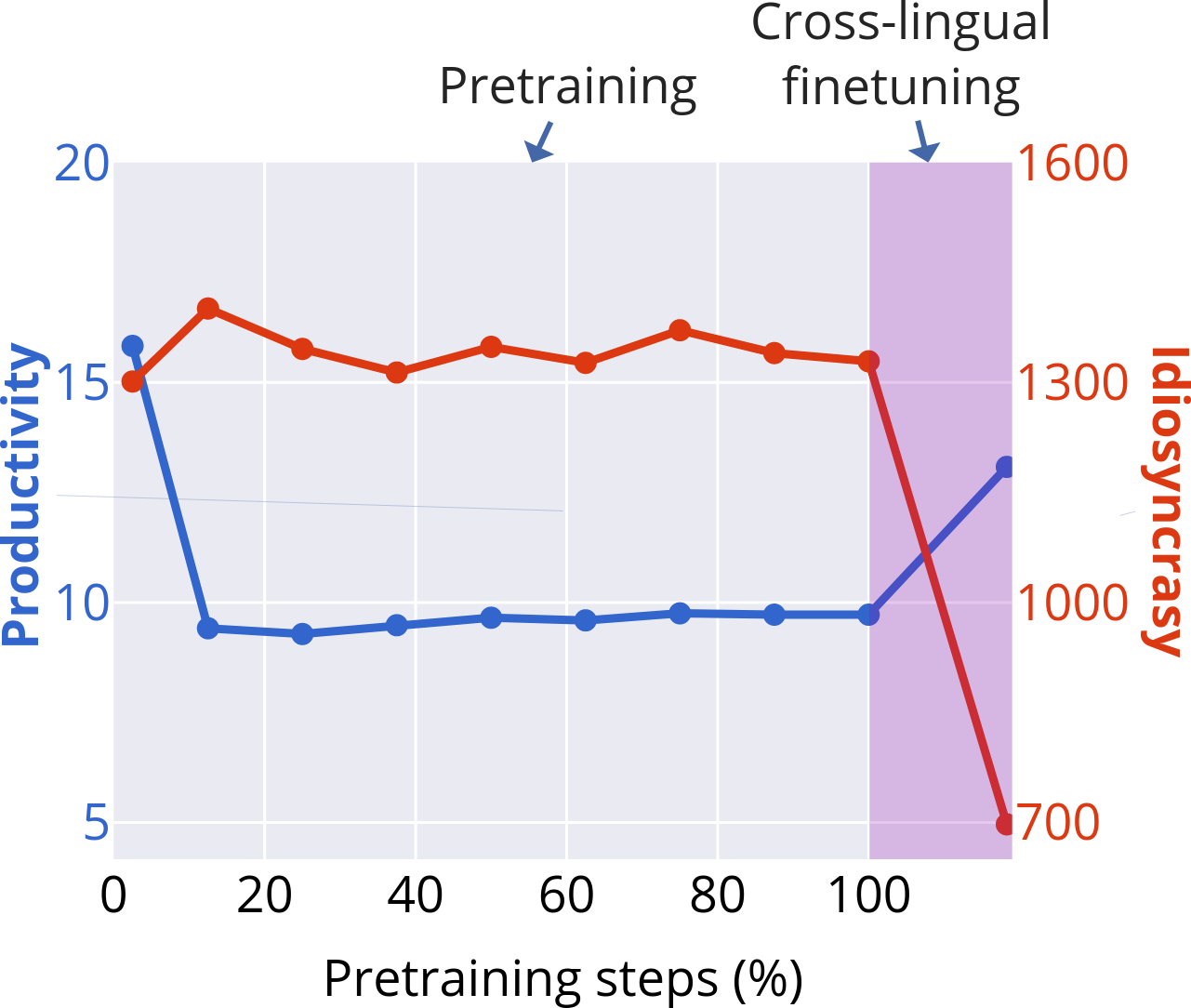
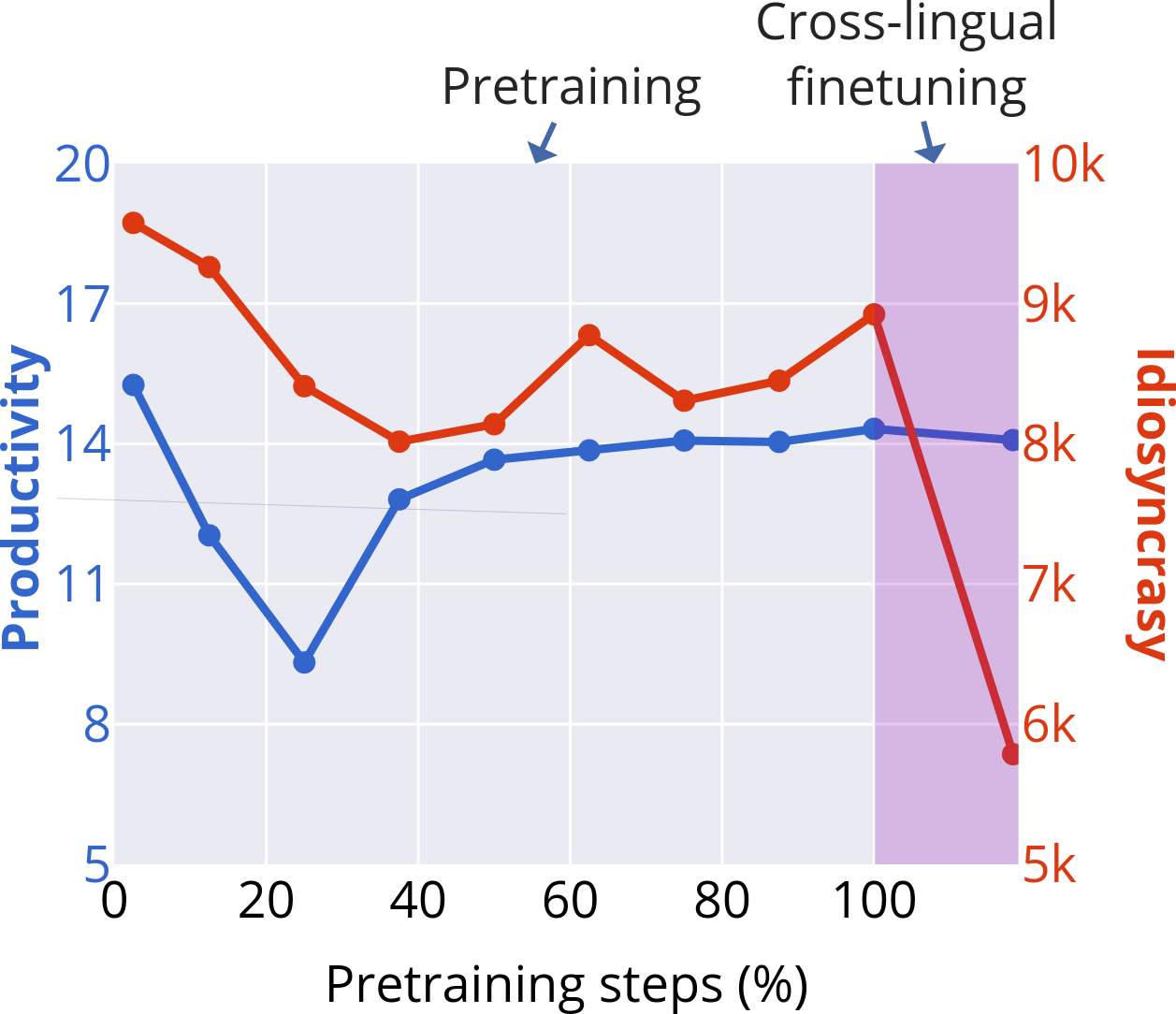
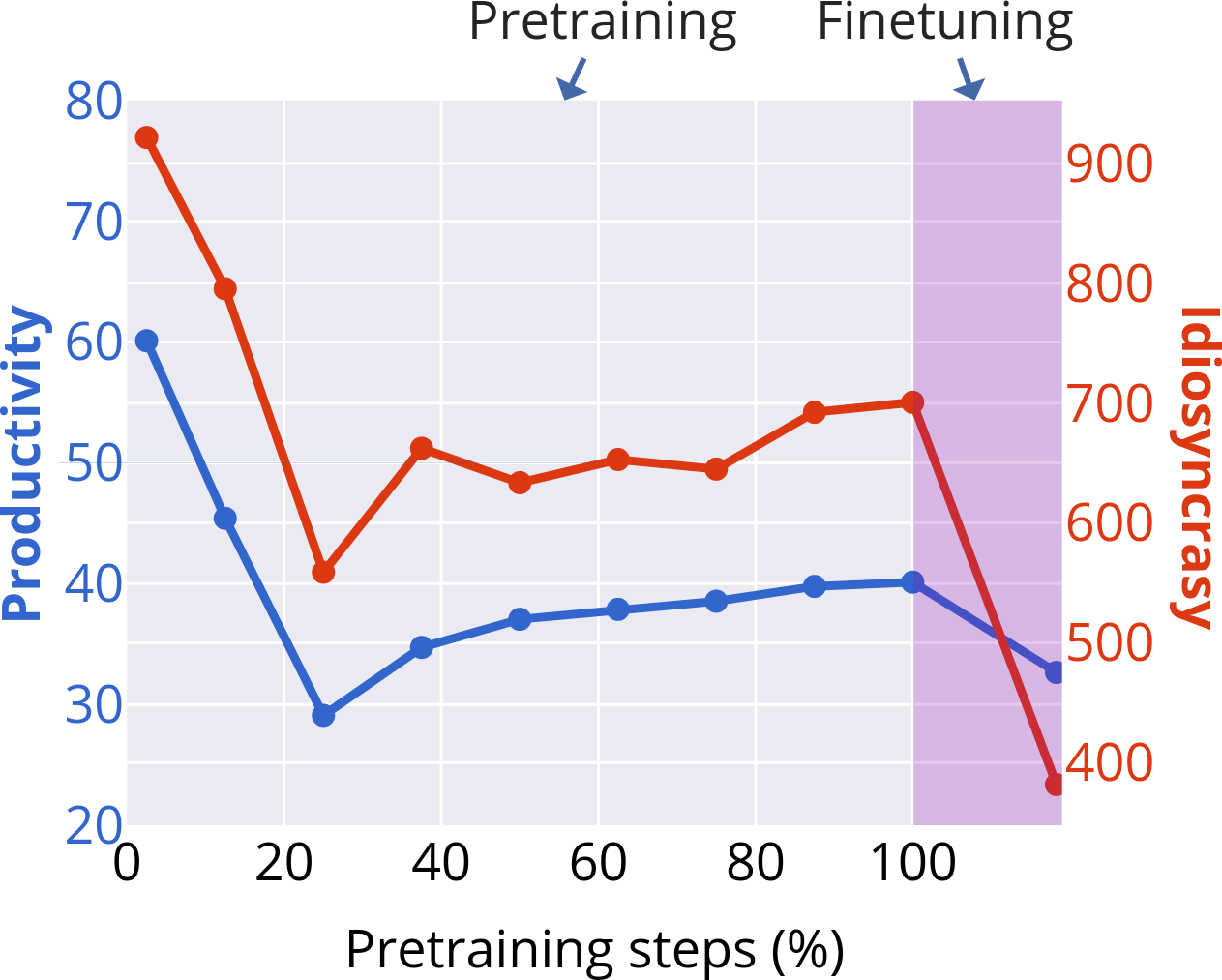
- Fertility (tokenisation): The average number of subword tokens per word; higher fertility indicates finer-grained segmentation. "Subword fertility (average subwords per word) gradually plateaus for isiXhosa, while converging early for English and Setswana."
- Forward scores: Intermediate dynamic programming values that represent cumulative probabilities up to a position in a sequence. "where and are forward scores computed as"
- Headline generation: A text generation task where a concise headline is generated from an article body. "For headline generation from the body of a news article we use MasakhaNEWS"
- Idiosyncrasy (of subwords): A measure of how frequently the words containing a subword occur, capturing token frequency concentration. "idiosyncrasy is the average token frequency of types containing a subword."
- Inflectional morphology: Morphological changes (e.g., tense, number) that modify a word to express grammatical features. "English, with its limited inflectional morphology, serves as a typological middle ground."
- Lexical coverage: The extent to which a tokenization’s vocabulary can represent whole words without splitting. "Fertility \citep{acs-2021-exploring} estimates lexical coverage."
- Lexicon (subword lexicon): A predefined set of subword units used by a model to represent text. "The lexicon contains a fixed set of high-frequency subwords"
- LSTM: A recurrent neural network architecture designed to capture long-range dependencies in sequences. "The original SSLM architecture is based on a shallow LSTM."
- Marginal likelihood: The summed probability of a sequence across all possible latent segmentations or structures. "The original formulation of Eq.~\ref{dp} computes the marginal likelihood of a full sequence "
- Marginalisation over segmentations: Summing probabilities across all possible tokenizations of a sequence rather than assuming a fixed one. "SSLM marginalises over all possible subword segmentations during training."
- Mixture model: A probabilistic model that combines multiple distributions, here mixing character and lexicon distributions for subwords. "since standard beam search implementations are incompatible with the mixture model described above."
- Morpheme: The smallest meaningful unit in a language’s morphology. "long word forms composed of many morphemes"
- Morphological alignment: The extent to which learned subword boundaries correspond to true morphological boundaries. "Morphological alignment measures how closely subwords align with morphological boundaries."
- Morpho-orthographic spectrum: A continuum describing how languages encode morphology in their writing systems. "represent opposite ends of the morpho-orthographic spectrum."
- Open-ended text generation: Generating unconstrained continuations of text without fixed targets. "enable open-ended text generation with T-SSLM"
- Perplexity: A measure of how well a probability model predicts a sample; lower perplexity indicates better predictive performance. "perplexity-based evaluation demonstrates the potential of SSLM over tokenisation-based LMs."
- Pretraining: An initial training phase on large unlabeled corpora to learn general language representations. "during pretraining and finetuning."
- Productivity (morphology): The degree to which a morpheme combines with others to form many distinct words. "Productivity \citep{gutierrez-vasques-etal-2023-languages} measures the generative capacity of subwords"
- Subword segmentation: Splitting text into smaller units than words (subwords) for modeling and tokenization. "Subword segmentation is typically applied in preprocessing and stays fixed during training."
- Subword Segmental LLM (SSLM): A LLM framework that jointly learns subword segmentation and model parameters by marginalizing over segmentations. "we extend the subword segmental LLM (SSLM), a framework for learning subwords during training, to support pretraining and finetuning."
- T-SSLM (Transformer SSLM): A Transformer-based adaptation of SSLM that scales to modern pretraining and finetuning practices. "We develop a Transformer-based variant, T-SSLM, incorporating learnable subword segmentation into modern LM practices like pretraining, task-specific finetuning, and text generation."
- Text degeneration: Failure mode in generation where outputs become incoherent or repetitive. "and a notable reduction in text degeneration."
- Tokenisation: The process of splitting text into units (tokens) for modeling; here focusing on subwords. "In all these studies (as in most LM research) tokenisation is fixed"
- Transformer: A neural architecture relying on self-attention mechanisms, widely used in language modeling. "We propose T-SSLM, a new variant of SSLM parameterised by a Transformer"
- ULM (Unigram LLM): A subword tokenization method that learns a probabilistic unigram vocabulary. "Subword tokenisers like BPE \citep{sennrich-etal-2016-neural} and ULM \citep{kudo-2018-subword}"
- Viterbi algorithm: A dynamic programming method to find the most probable sequence of hidden states; used here to extract the best tokenization. "we can extract its probability-maximising subword segmentation using the Viterbi algorithm."
Collections
Sign up for free to add this paper to one or more collections.