PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Abstract: A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a LLM, which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces PAN, a smart “world model” that can imagine and simulate what happens next in a video when you tell it what actions to take using normal language. Think of PAN like a very smart and interactive movie director: it watches what has happened so far, understands your instructions (like “turn left,” “pick up the cup,” or “walk to the door”), and then creates the next part of the video showing what would realistically happen. Unlike many video tools that make short, one-off clips from a prompt, PAN is designed to keep the story consistent over long periods and let you interact with it step by step.
Key Questions the Paper Tries to Answer
- How can we build a general-purpose simulator that can predict the future of a world (shown as video) based on actions written in human language?
- Can this simulator stay consistent over long time spans, not just a few seconds?
- Can it be interactive, meaning you can give it new actions at each step and it responds appropriately?
- How do we connect “imagination” (hidden reasoning about the world) to “reality” (detailed video frames you can watch) in a stable and reliable way?
How PAN Works (Explained Simply)
PAN uses a design called Generative Latent Prediction (GLP). Here’s the idea in everyday terms:
- Imagine you’re playing a sandbox game. Inside your head, you picture what will happen next when you move or interact, before you actually see it. That hidden mental picture is like a “latent state”—a compact summary of the world that’s easier to reason about than raw pixels.
- Then, to show it on screen, the game engine turns your inner picture into actual graphics and animations. That’s the “decoder” making visible frames.
PAN splits its job into three parts. This separation makes it more stable and realistic.
Here is a short list to introduce the three core parts of PAN:
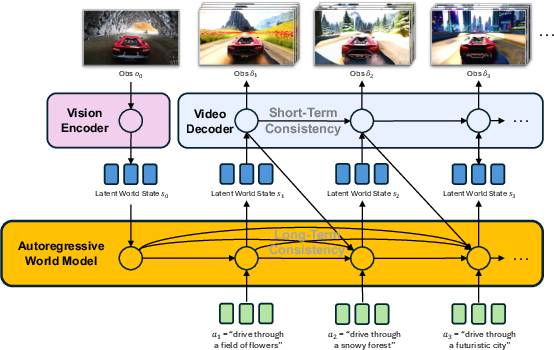
- Vision Encoder: This is like a careful note-taker. It watches the current video frame(s) and turns them into a neat summary (a “latent state”) the rest of the system can think about. It uses a Vision-LLM so it understands both images and text.
- Autoregressive World Model (Backbone): This is the “imagination” and memory. It predicts the next hidden state based on the history and the action you give in natural language. It relies on a LLM, so it can use real-world knowledge from text—like understanding what “open the door” means.
- Video Diffusion Decoder: This is the “film crew.” It takes the hidden state and paints the next chunk of video frames with high visual quality and smooth motion.
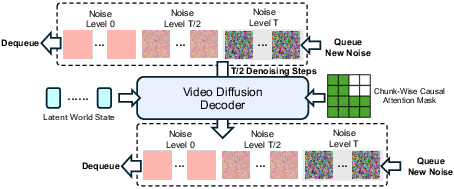
PAN also adds a special technique called “Causal Shift-Window Denoising Process Model” (Causal Swin-DPM) in the decoder. Here’s a simple analogy:
- When you stitch video clips together, there can be awkward jumps or drifting mistakes that pile up over time.
- Causal Swin-DPM is like overlapping two scenes while fading between them, and gently smoothing the transition so they connect naturally. It also slightly “blurs” past frames during generation to avoid copying tiny errors forward, which helps keep the whole movie consistent over long periods.
Finally, PAN is trained on lots of paired video-and-action data from many domains (everyday scenes, human-object interactions, etc.). That variety helps it generalize to different environments and types of instructions.
Main Findings and Why They Matter
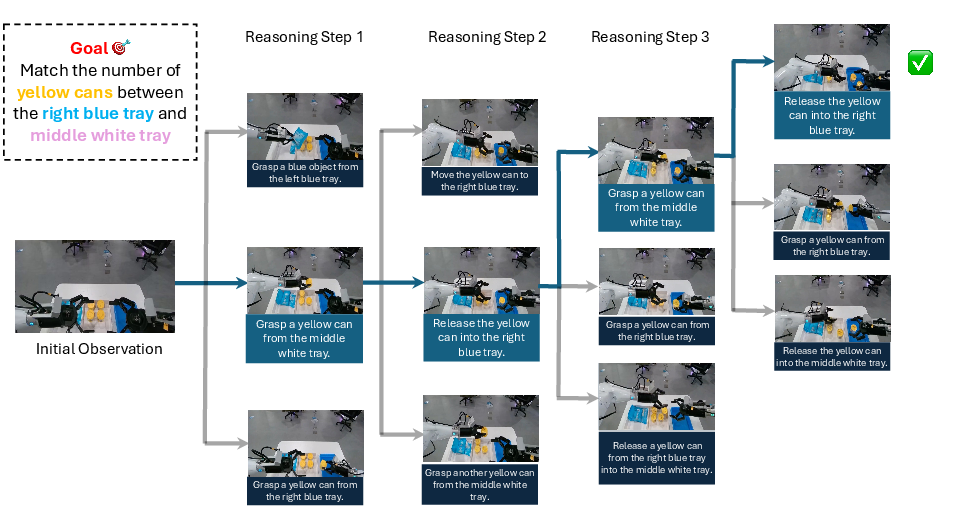
- PAN can simulate future video frames based on your language actions, not just spit out a single, non-interactive video from a prompt. This makes it useful for step-by-step planning and testing “what if” scenarios.
- It stays coherent over long time horizons. In other words, it doesn’t quickly lose track of objects or drift into messy motion after a few seconds. This is crucial for realistic simulations.
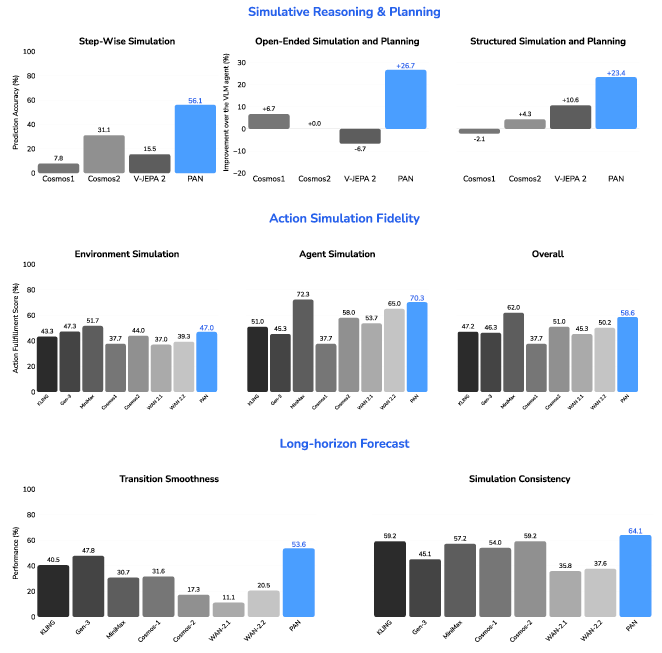
- It shows strong performance compared to other video generators and earlier “world models,” especially for action-conditioned simulation (where the next scene depends on your actions) and long-term forecasting.
- The GLP design helps connect hidden reasoning to visible results, reducing the risk that the model’s “imagined” states become unrealistic or ungrounded.
- The Causal Swin-DPM decoder reduces error build-up, making long rollouts more stable.
These results are important because most video models today are like one-shot artists: they can paint a pretty scene from a prompt but can’t consistently keep a story going or let you interact causally as events unfold. PAN moves beyond that, toward systems that can reason, plan, and act within a simulated world.
What This Could Mean in the Future
- Better planning and training for robots and virtual agents: You can test actions in a realistic simulated world before doing them in real life, which is safer and cheaper.
- Smarter assistants and tutoring: Interactive, long-term simulations could help explain processes—like how a machine works or how an ecosystem changes—step by step with visuals.
- Game and film prototyping: Creators could rapidly explore stories and scenes by describing actions and seeing the simulation play out with consistent visuals.
- Scientific exploration and education: Students and researchers could run “what if” experiments visually—like changing conditions in a physics demo—and see plausible results.
The paper suggests that with more training data and continued scaling, PAN-like models could become general-purpose simulators that help AI understand cause and effect, plan ahead, and act more intelligently. In short, PAN is a step toward AI that can imagine and interact with the future in a realistic, controllable way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to validate, stress-test, and extend PAN.
- Lack of rigorous, standardized evaluation for “world modeling”: no clearly defined benchmarks or metrics for causal compliance, counterfactual fidelity, and long-horizon consistency across diverse domains and interaction formats.
- Absence of quantitative results in the text provided: no reported numbers for forecasting accuracy, action-conditioned controllability, temporal drift, or error accumulation compared to baselines.
- No causal validity tests: the model’s adherence to physical laws (e.g., conservation, collision handling, object permanence) and causal interventions remains unverified beyond qualitative intuition.
- Unclear uncertainty modeling: how multi-modal futures are represented, sampled, and calibrated (e.g., entropy, sharpness vs diversity trade-offs) is not quantified or validated.
- Exposure bias not addressed: the backbone is teacher-forced during training but rolled out open-loop at inference; there is no analysis of scheduled sampling or techniques to mitigate train–inference mismatch.
- Limited memory horizon: backbone history is truncated to 10 rounds during training; effects on very long-horizon rollouts, recall of distant events, and stability are not studied.
- Markov vs non-Markov dynamics: the paper mentions non-Markov extensions but does not implement or evaluate augmented state representations or long-context memory mechanisms.
- Latent state interpretability: the 256-token latent state is not linked to explicit entities/objects; there is no mechanism or analysis for entity tracking, object permanence, or editable, interpretable state variables.
- Action semantics are underspecified: reliance on natural language actions raises ambiguity (temporal scope, granularity, grounding); no analysis of disambiguation, temporal alignment, or robustness to noisy/underspecified commands.
- No mapping to low-level control: how text actions translate to fine-grained actuation or environment-specific interfaces (robotics, game engines) is not demonstrated.
- No cross-modal actions: action formats beyond text (e.g., continuous control vectors, high-level API calls) are not explored.
- Counterfactual evaluation is missing: no protocols to verify that simulated interventions produce consistent, coherent counterfactuals distinct from observed trajectories.
- Physical and 3D consistency: there is no explicit 3D representation or multi-view consistency; camera dynamics and geometry aren’t constrained or evaluated.
- Distribution shift robustness: generalization to out-of-domain scenes, rare events, and adversarial or contradictory actions is not assessed.
- No safety guardrails: there is no discussion of safety constraints, refusal behavior for impossible/unsafe actions, or content moderation in open-domain simulation.
- Data provenance and alignment are unclear: sources of “publicly accessible” videos, licensing, privacy, and bias concerns are not laid out; the process for aligning video segments with language actions is not specified or validated for causal correctness (risk of spurious correlations).
- Action–outcome confounding: no method to disentangle actions from co-occurring events in video-only supervision; lack of interventional or controlled datasets to identify action effects.
- Missing ablations: no studies on the contribution of each component (LLM backbone, Causal Swin-DPM, query embeddings, noise augmentation, flow-matching vs other objectives) to performance and stability.
- Frozen VLM limitations: freezing the vision–language backbone may cap performance; whether fine-tuning improves grounding, dynamics modeling, or reduces hallucinations is not explored.
- GLP claims lack formal guarantees: there is no theoretical identifiability or convergence analysis showing that generatively supervised latent transitions correspond to true causal world dynamics.
- Causal Swin-DPM training–inference mismatch: inference masks future actions; training conditions for the same masking regime and its effect on performance are not clearly established or ablated.
- Chunking side effects: how chunk length, window size, and the k=0.055 conditioning noise affect temporal drift, boundary artifacts, and long-range coherence is not analyzed.
- Latency and scalability: while accelerations are described, there is no end-to-end latency/throughput report under interactive settings, nor a resource–quality Pareto analysis for deployment.
- Resource and reproducibility concerns: training requires 960 H200 GPUs; reproducibility (seeds, configs), carbon footprint, and accessibility for the research community are not addressed.
- Planning and control integration: PAN’s utility within closed-loop decision-making (e.g., MPC/RL), sample efficiency, and planning under uncertainty are not demonstrated.
- Failure mode taxonomy is missing: no systematic analysis of collapse modes, repetitive loops, identity swapping, causal incoherence, or recovery strategies after drift.
- Uncertainty–control interface: how to guide the model to choose among diverse plausible futures for planning or to expose calibrated uncertainty to downstream agents is not specified.
- Multi-agent dynamics: claims of multi-agent capability are not supported with identity persistence, role modeling, collision avoidance, or coordination metrics.
- Multimodal sensory grounding: audio, depth, proprioception, and tactile signals are not modeled; benefits/limitations of purely visual grounding are not evaluated.
- Ethics and misuse risks: no discussion of potential harms (e.g., deepfake-like simulations, misinformation) or mitigations in open-domain generative “world” simulators.
- Dataset design: video segmentation, filtering, and captioning pipelines are incomplete in the text; selection biases and their impact on dynamics learning are not quantified.
- Action timing alignment: the temporal alignment between actions and their visual effects across chunks (duration, delay, persistence) is not defined or evaluated.
- Robustness to language variability: no experiments on multilingual actions, paraphrase robustness, pronoun resolution, or compositional instructions.
- Calibration and scoring: no likelihood or scoring mechanism for comparing simulated rollouts against ground-truth futures; evaluation is not grounded in probabilistic calibration.
- Bridging to 3D/physics priors: no exploration of hybrid training with differentiable physics or 3D supervision to improve causal and geometric fidelity.
- Long-term state persistence across sessions: no mechanism for persistent world memory or editable “world save” states enabling incremental simulation over days/weeks.
- Open-source status: code, weights, and datasets are not confirmed as available; lack of release impedes verification and extension by the community.
Practical Applications
Below are practical applications that flow from PAN’s core contributions: an LLM-grounded latent dynamics backbone, action-conditioned video simulation, and the Causal Swin-DPM decoder for long-horizon coherence. Each item lists sectors, concrete use cases or product/workflow ideas, and key dependencies/assumptions.
Immediate Applications
- Media and Entertainment — Action-conditioned previsualization and shot planning
- Use cases: Interactive storyboarding; stunt and camera-blocking previews; continuity planning across scenes; quickly iterating “what-if” scene variants by typing action directives.
- Product/workflow: “Action-Conditioned Previz Studio” that ingests rough footage or stills, then simulates multi-shot sequences under natural-language actions with long-horizon transitions.
- Dependencies/assumptions: Adequate compute for video diffusion; license-compliant use of base models; domain fine-tuning on cinematic motion; human-in-the-loop QA for safety and narrative consistency.
- Game Development — Prototyping mechanics and NPC behaviors
- Use cases: Simulating level dynamics or enemy patterns from textual action prompts; testing emergent behavior and pacing; pre-tuning interactions before engine integration.
- Product/workflow: “Simulation Sandbox for Designers” that converts design intents (language actions) into playable video scenarios to de-risk mechanics early.
- Dependencies/assumptions: Domain adaptation to target art style and physics; integration into build pipelines; acceptance that video sims are non-interactive renderings (not engine physics).
- Robotics (Sim-to-Sim and Offline) — Policy debugging and scenario generation
- Use cases: Generating diverse, action-conditioned video rollouts to stress-test perception and planning modules; visualizing failure modes and counterfactuals (“What if the robot turns left behind the cart?”).
- Product/workflow: “World-Model Scenario Generator” for synthetic action-conditioned evaluation datasets; offline policy analysis by sweeping action scripts and observing long-horizon effects.
- Dependencies/assumptions: Not a replacement for physics simulators; requires domain adaptation to robot morphology/tasks; sim-to-real gap persists; use as a qualitative complement to quantitative physics sims.
- RL and Embodied AI Research — Model-based planning and simulative reasoning
- Use cases: Training agents to plan via imagined rollouts; testing counterfactual actions; benchmarking generative latent prediction (GLP) versus encoder-only approaches (JEPA, etc.).
- Product/workflow: “GLP Planning Benchmark Suite” that measures long-horizon prediction quality and action-conditional consistency; “PAN Gym” interface for research.
- Dependencies/assumptions: Fast batched inference; careful metrics beyond pixel match (causal/temporal coherence); governance to mitigate reward hacking on video realism.
- Software and UX — Interactive UI flows and onboarding simulations
- Use cases: Prototyping UI flows or IoT interactions in a “world-like” video sim driven by user action scripts; training materials that visualize consequences of choices.
- Product/workflow: “Action-to-Scenario Explainer” that turns “click/drag/confirm” instructions into a narrated, visualized session for support or onboarding.
- Dependencies/assumptions: Domain prompts mapping UI actions to visual metaphors; ensuring no personally identifiable or sensitive content is introduced.
- Education — Safe, visual labs for procedural skills
- Use cases: Demonstrating multi-step lab procedures (chemistry, electronics) with action-conditioned branching; exploring counterfactuals (“What if I increase voltage?”) safely in video form.
- Product/workflow: “Interactive Video Lab” modules where students type actions and observe long-horizon outcomes with continuity across steps.
- Dependencies/assumptions: Domain curation to avoid unsafe instructions; disclaimers that outputs are didactic visuals, not ground-truth physics.
- Safety and Compliance Training — Incident replay and root-cause exploration
- Use cases: Reconstructing incidents from reports and exploring alternative action paths; standard operating procedures (SOP) training with long-horizon consistency.
- Product/workflow: “Causal Video Trainer” for OSHA/aviation/industrial safety to visualize how actions propagate over time.
- Dependencies/assumptions: Accurate, context-specific prompts; oversight to prevent misinterpretation as factual reenactments; legal review of incident reconstruction usage.
- Content Operations — Synthetic, labeled, action-conditioned datasets
- Use cases: Generating action-tagged videos for training action recognition, video QA, and temporal localization models; diversity augmentation with controlled long-horizon dynamics.
- Product/workflow: “Action-Conditioned Data Factory” that outputs curated video-action pairs with metadata for ML pipelines.
- Dependencies/assumptions: Clear data provenance; bias/coverage analysis; compute budget; quality filters for drift and artifacts.
- HCI and Agent Evaluation — Controlled benchmarks for causal understanding
- Use cases: Creating standardized “what-if” suites to test agents’ causal reasoning and temporal grounding under language-specified actions.
- Product/workflow: “Causal Cohesion Benchmark” with metrics for cross-chunk continuity, action adherence, and drift.
- Dependencies/assumptions: Agreed-upon metrics for simulation coherence; annotation protocols; community adoption.
- Advertising and Marketing — Scenario-based creative exploration
- Use cases: Rapidly prototyping campaign stories under different consumer actions (“user skips,” “user taps product,” “user revisits store”) to visualize outcomes.
- Product/workflow: “Scenario Explorer” for creative teams to iterate on long-form narrative arcs with interactive beats.
- Dependencies/assumptions: Brand safety filtering; IP/licensing; disclosure when synthetic content informs decisions.
Long-Term Applications
- Autonomous Systems and Robotics — Closed-loop planning and control
- Use cases: Using PAN as a world model for on-device or edge planning under language or high-level task intents; hierarchical control where latent predictions guide low-level policies.
- Product/workflow: “World-Model Co-Pilot” embedded in robots/vehicles that anticipates multi-step consequences and adapts actions.
- Dependencies/assumptions: Significant improvements in real-time inference latency; tighter coupling to physics; robust sim-to-real transfer; safety certification.
- Digital Twins (Manufacturing, Energy, Smart Cities) — Actionable scenario testing
- Use cases: Long-horizon “what-if” testing for factory line changes, grid operations, or traffic policy interventions using action-conditioned narratives.
- Product/workflow: “Interactive Twin Orchestrator” where planners type interventions and receive coherent video simulations of system evolution.
- Dependencies/assumptions: Integration with telemetry and physics/agent-based models; sector-specific calibration; governance to prevent overreliance on visually plausible but inaccurate dynamics.
- Healthcare — Procedure planning and team training with counterfactuals
- Use cases: Visualizing multi-step procedures, complications, and team coordination under different action policies; pre-op planning with scenario exploration.
- Product/workflow: “Procedure Scenario Studio” enabling clinicians to explore branching action trees and watch long-horizon outcomes.
- Dependencies/assumptions: Regulatory compliance (HIPAA/GDPR); validated clinical grounding; domain-specific fine-tuning; rigorous harm mitigation and disclaimers.
- Emergency Response and Policy — Crisis rehearsal and impact assessment
- Use cases: Simulating evacuation strategies, resource allocations, or countermeasures with long-horizon video explainability for decision-makers and the public.
- Product/workflow: “Policy Scenario Lab” for agencies to compare action sequences and communicate trade-offs with causal continuity.
- Dependencies/assumptions: Multi-model fusion (PAN + epidemiological/agent-based/CFD models); transparency about uncertainty; misuse mitigation and ethical guidelines.
- Finance and Operations — Visual scenario planning and risk communication
- Use cases: Explaining operational contingencies (supply chain disruptions, retail floor changes) via action-driven simulations for stakeholders.
- Product/workflow: “Ops Storyboarder” that ties structured action plans to simulated visual narratives for executive briefings.
- Dependencies/assumptions: Careful scoping to operational—not market-prediction—use; data security; alignment with quantitative models.
- Education at Scale — Rich, interactive curricula and personalized coaching
- Use cases: Personalized, multi-step practice scenarios in vocational training (e.g., automotive repair, construction) with branching feedback loops.
- Product/workflow: “Interactive Skills Tutor” that turns lesson plans into action-conditioned, long-horizon visual labs on demand.
- Dependencies/assumptions: Curriculum alignment; safety and fairness audits; accessibility and localization; on-device acceleration for classrooms.
- AR/VR and Spatial Computing — Live mixed-reality co-simulation
- Use cases: In-situ scenario previews in headsets (“What happens if I move this shelf?”), collaborative planning with persistent, action-driven simulations over time.
- Product/workflow: “MR World-Coach” that anchors simulated outcomes to real scenes with voice action prompts.
- Dependencies/assumptions: Real-time performance; precise spatial grounding; robust tracking; safety boundaries in MR.
- Scientific Discovery — Hypothesis rehearsal and experiment design aid
- Use cases: Planning complex, multi-step experiments by visually rehearsing procedures and contingencies; teaching causal chains and experimental control.
- Product/workflow: “Hypothesis Workbench” for researchers and students to explore procedural branches visually before lab time.
- Dependencies/assumptions: PAN simulations are illustrative, not substitutes for physical/chemical models; domain-specific modules needed for fidelity.
- Open-World Games and Agents — Persistent, causally coherent NPC ecosystems
- Use cases: NPCs and environments that evolve coherently under high-level directives and player actions across long horizons.
- Product/workflow: “World-Model Engine Layer” that orchestrates narrative and environmental dynamics beyond scripted events.
- Dependencies/assumptions: Tight integration with game physics/logic; cost controls for long sessions; content safety and moderation.
- Platformization — Simulation-as-a-Service and SDKs
- Use cases: Providing APIs for action-conditioned, long-horizon video rollout; plugins for MLOps, VFX, robotics toolchains.
- Product/workflow: “PAN SDK” (Python/REST) with templates for sector adapters; hosted “Scenario Studio” for teams.
- Dependencies/assumptions: Cost-effective inference (quantization, distillation); monitoring for drift and hallucinations; audit logs and governance.
Notes on overarching assumptions and risks:
- Domain adaptation is pivotal: general open-domain training must be complemented with sector-specific data and validation to avoid misleading plausibility.
- Compute and latency constraints: high-fidelity diffusion decoding is expensive; real-time or on-device use will require aggressive optimization (quantization, caching, smaller decoders).
- Evaluation and metrics: action adherence, temporal coherence, and causal plausibility need standardized metrics beyond pixel quality.
- Safety, ethics, and misuse: simulations may be mistaken for factual reconstructions; disclosure, watermarking, and usage policies are essential.
- Integration with physics and symbolic models: for high-stakes decisions, PAN should augment—not replace—domain simulators; hybrid pipelines improve reliability.
- Data governance: ensure licensing, privacy, and bias controls for training and generated content.
Glossary
- Activation checkpointing: A memory-saving training technique that recomputes intermediate activations during the backward pass to reduce GPU memory use. "We further enable activation checkpointing at the unit of each DiT block."
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve training stability. "the AdamW optimizer~\citep{loshchilov2017decoupled}"
- Associative memory: A representation mechanism that preserves and retrieves related information across time or context. "functioning as a form of associative memory~\citep{suzuki2008associative}"
- Autoregressive: A modeling approach that predicts the next state conditioned on previous states and inputs in a step-by-step fashion. "The Autoregressive World Model Backbone "
- BFloat16 precision: A floating-point format with reduced precision that speeds up training while maintaining model quality. "Training is conducted using BFloat16 precision"
- Causal Swin-DPM: A diffusion decoding mechanism that uses causal, sliding-window denoising to ensure smooth transitions across video chunks. "we introduce the Causal Shift-Window Denoising Process Model (Causal Swin-DPM)"
- Chunk-wise causal attention mask: An attention masking strategy that limits future information leakage across video chunks to preserve causality. "with chunk-wise causal attention mask to ensure smooth transitions between consecutive chunks"
- Classifier-free guidance (CFG): A sampling technique in diffusion models that balances conditional and unconditional outputs to improve adherence to conditioning signals. "we apply classifier-free guidance~\citep[CFG,] []{ho2022classifier} with a guidance scale of 4."
- Closed-loop rollouts: Autoregressive simulation where the model feeds back its own predictions as inputs for future steps. "during inference, it performs {closed-loop} rollouts"
- Cosine decay schedule: A learning rate schedule that gradually decreases using a cosine function to stabilize training. "with a learning rate of , a cosine decay schedule"
- Cross-attention: An attention mechanism that allows a model to attend to conditioning inputs (e.g., text or state) when processing another modality. "fed to a newly added cross-attention stream in each attention block."
- Data Parallelism (DP): A distributed training strategy that replicates the model across devices and splits the data batches among them. "a combination of Data Parallelism (DP) and Fully Sharded Data Parallelism (FSDP)."
- Diffusion Transformer (DiT): A transformer-based architecture designed for diffusion-based generative modeling of images or videos. "The base model is a 14B-parameter Diffusion Transformer (DiT)"
- DINOv2: A self-supervised vision representation model often used as a fixed feature extractor. "DINOv2~\citep{oquabdinov2}"
- Energy-based constraints: Regularization techniques that shape latent-space learning by penalizing unlikely configurations via energy functions. "mutual-information maximization or energy-based constraints"
- FlashAttention-3: A fast attention kernel that improves memory efficiency and throughput for transformer attention. "apply FlashAttention-3~\citep{shah2024flashattention}"
- FlexAttention: A customizable attention kernel used to compile efficient attention operations, including masked variants. "use FlexAttention~\citep{dong2024flex} to compile custom kernels for chunk-wise causal attention."
- Flow matching: A training objective for diffusion-like models that learns a velocity field to map noise to data. "We train the video diffusion decoder using the flow matching objective~\citep{lipman2022flow}"
- Fully Sharded Data Parallelism (FSDP): A distributed training method that shards model parameters, gradients, and optimizer states across devices. "a combination of Data Parallelism (DP) and Fully Sharded Data Parallelism (FSDP)."
- Generative Latent Prediction (GLP): A framework that predicts future latent states and grounds them by reconstructing observable data. "PAN employs the Generative Latent Prediction (GLP) architecture"
- Generative supervision: Training that anchors latent predictions by reconstructing observations rather than only matching latent embeddings. "trained under a generative supervision objective"
- Gradient clipping: A technique that limits the magnitude of gradients to prevent exploding gradients. "Gradients are clipped to a maximum norm of 0.05."
- Hybrid Sharded Data Parallel (HSDP): A training setup combining data parallelism and sharded approaches within compute nodes. "forming a Hybrid Sharded Data Parallel (HSDP) setup."
- Indefinability problem: A failure mode where latent transitions become unconstrained and may not reflect realizable world dynamics. "This leads to the indefinability problem"
- JEPA (Joint Embedding Predictive Architecture): A predictive model that matches embeddings of future observations but can suffer from collapse without reconstruction. "Joint Embedding Predictive Architecture~\citep[JEPA,] []{assran2023self}"
- LLM: A transformer trained on massive text corpora that provides general world knowledge and reasoning capabilities. "based on a LLM"
- Latent state: A compact internal representation encoding the agent’s belief about the world at a given time. "GLP introduces a latent state that represents the agent’s internal belief of the world"
- Markov model: A dynamics assumption where the next state depends only on the current state and action. "We adopt the Markov model here for clarity"
- Mutual-information maximization: A regularization strategy that encourages informative latent representations by maximizing shared information. "mutual-information maximization"
- Non-Markovian dynamics: Temporal dependencies where future states depend on more than just the current state and action. "represent non-Markovian dynamics"
- Open-loop setting: Generation that produces outputs from fixed prompts without interactive feedback or causal control. "operate in an open-loop setting"
- Optical flow: A technique for estimating motion between frames by tracking pixel intensity changes. "metrics based on optical flow"
- Radiance fields: 3D representations of scenes learned from multi-view data that encode volume density and emitted light. "spatially consistent radiance fields"
- Rectified Flow: A flow-based diffusion formulation that linearly interpolates between noise and data during training. "following the Rectified Flow formulation~\citep{liu2022flow}"
- Rotary positional embeddings: A positional encoding method that injects rotation-based positional information into transformers. "2D rotary positional embeddings"
- SageAttention2++: An efficient attention kernel enabling low-bit computation and quantization to accelerate inference. "We apply the SageAttention2++ \citep{zhang2025sageattention2++} during inference"
- Sequence parallelism (SP): A strategy that shards sequences across GPUs to scale transformer models efficiently. "apply sequence parallelism (SP)~\citep{li2021sequence} to shard hidden states across GPUs along the sequence length dimension."
- Shift-Window Denoising Process Model: A denoising approach that processes overlapping windows to improve temporal coherence in diffusion decoding. "augments the Shift-Window Denoising Process Model~\citep{feng2024matrix} with chunk-wise causal attention"
- Sliding temporal window: A decoding scheme that maintains overlapping windows of frames at different noise levels for smooth transitions. "operates within a sliding temporal window"
- Teacher forcing: A training approach that feeds the model ground-truth states to stabilize autoregressive learning. "the backbone is teacher-forced using ground-truth states"
- Ulysses method: A distributed attention computation technique that uses all-to-all communication for efficient sharding across attention heads. "we adopt the Ulysses method~\citep{jacobs2023deepspeed}"
- umT5: A multilingual T5-based text encoder used to condition the decoder on natural language actions. "the action text is encoded with umT5~\citep{chung2023unimax}"
- Variational Autoencoder (VAE): A generative model that encodes data into a latent space and reconstructs it, often used for compression. "We use the Variational Autoencoder (VAE) from Wan2.1 for video frame compression."
- Video diffusion decoder: A diffusion-based generator that reconstructs temporally coherent video from latent states and actions. "a video diffusion decoder to predict frame-level observations with local visual consistency."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for multimodal understanding and generation. "Qwen2.5-VL-7B-Instruct~\citep{bai2025qwen2}, an open-weight VLM."
- Vision Transformer (ViT): A transformer architecture adapted to images by splitting them into patches and processing them as tokens. "a Vision Transformer~\citep{dosovitskiy2020image}"
- Windowed self-attention: A localized attention mechanism that restricts attention to spatial windows to reduce computation. "applies windowed self-attention for computational efficiency"
- World model: An internal simulation that predicts how the environment evolves with actions, enabling planning and reasoning. "A world model provides this capacity by maintaining an internal simulation of the environmental evolution."
Collections
Sign up for free to add this paper to one or more collections.