- The paper demonstrates a strong correlation (r = 0.75, p < .001) between citation count and the factual accuracy of generated bibliographic entries.
- The study identifies threshold behaviors, with reliable memory emerging around 90 citations and near-perfect recall beyond 1,248 citations.
- The research offers actionable insights for enhancing LLM training protocols to reduce hallucinations and improve citation recommendations.
Hallucinate or Memorize? The Two Sides of Probabilistic Learning in LLMs
Introduction
The paper "Hallucinate or Memorize? The Two Sides of Probabilistic Learning in LLMs" (2511.08877) addresses the critical issue of hallucinations in LLMs, particularly concerning bibliographic references. Through empirical investigation, the study elucidates how the memorization capacity of LLMs is influenced by citation frequency, which serves as a proxy for the redundancy of data in the training corpus. The research hypothesizes a correlation between citation count and the accuracy of generated bibliographic entries, revealing insights into how frequently cited papers are more reliably recalled by LLMs.
Citation Frequency and Memorization
The core of the study is the exploration of how citation frequency impacts the generation fidelity of bibliographic records. By analyzing 100 bibliographic records across twenty diverse domains, the paper establishes that there is a strong positive correlation between the citation count of a paper and the factual accuracy of its generated metadata. The study indicates that bibliographic records of papers with citation counts exceeding approximately 1,000 are nearly memorized verbatim by LLMs. This phenomenon suggests a threshold beyond which LLMs transition from probabilistic generation to deterministic recall.
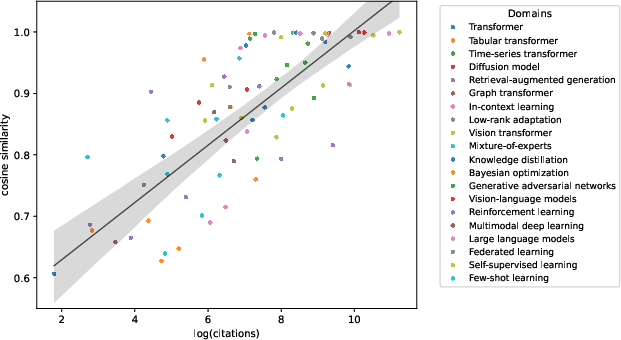
Figure 1: Relationship between citation frequency and generation fidelity. Each dot represents a factual record (score > 0), colored by research domain. The regression line indicates fitted linear regression with 95% confidence interval (gray band). Strong correlation (r = 0.75, p < .001) demonstrates a log-linear scaling relationship.
Experimental Design and Results
The experimental design involved generating bibliographic records using GPT-4.1, structured in JSON format, across several topics in computer science. The generated records were subsequently verified for factual accuracy against sources like Google Scholar. The evaluation revealed that while high citation counts minimize hallucination risks, even papers with lower citation frequencies can show variability in memorization. The paper further identifies threshold behaviors in citation recommendation, with two critical citation frequency points: approximately 90 citations mark the beginning of more reliable recall, and saturation occurs beyond 1,248 citations where near-perfect recall is observed.
Implications and Future Work
The paper's findings underscore a systematic relationship between training data redundancy and LLM hallucination and memorization tendencies, impacting the design and utilization of LLMs for citation recommendations. Practically, the study's insights could influence the development of LLM architectures and training protocols, enhancing their reliability in academic settings. Future work should investigate the behavior across different models and domains, consider larger sample sizes for more nuanced insights, and explore multilingual contexts to understand cross-linguistic dynamics in LLM memorization.
Conclusion
The research sheds light on the probabilistic nature of LLMs in generating academic references, indicating that hallucinations and memorization are facets of the same underlying probabilistic process. While highly cited papers benefit from redundant exposure leading to accurate recall, less cited works face significant challenges. Addressing these challenges involves leveraging insights from this study to improve LLM training methodologies and mechanisms to mitigate hallucinations, thus enhancing the integrity and utility of LLMs in citation recommendation systems.

