DynaAct: Large Language Model Reasoning with Dynamic Action Spaces
Abstract: In modern sequential decision-making systems, the construction of an optimal candidate action space is critical to efficient inference. However, existing approaches either rely on manually defined action spaces that lack scalability or utilize unstructured spaces that render exhaustive search computationally prohibitive. In this paper, we propose a novel framework named \textsc{DynaAct} for automatically constructing a compact action space to enhance sequential reasoning in complex problem-solving scenarios. Our method first estimates a proxy for the complete action space by extracting general sketches observed in a corpus covering diverse complex reasoning problems using LLMs. We then formulate a submodular function that jointly evaluates candidate actions based on their utility to the current state and their diversity, and employ a greedy algorithm to select an optimal candidate set. Extensive experiments on six diverse standard benchmarks demonstrate that our approach significantly improves overall performance, while maintaining efficient inference without introducing substantial latency. The implementation is available at https://github.com/zhaoxlpku/DynaAct.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to help LLMs think through complex problems step by step. The authors call their approach “DynaAct.” The big idea is to automatically pick a small, smart set of “actions” (like planning steps or moves) at each point in the reasoning process, so the model doesn’t waste time searching through endless possibilities.
Think of solving a hard math or logic puzzle: at every step, you can choose different things to do (calculate something, recall a rule, break the problem into parts, etc.). DynaAct helps the model pick a compact set of the best next moves, balancing being useful and being different enough from each other to cover the important options.
What questions are the authors trying to answer?
- How can we build an “action space” (a set of possible moves) that is both:
- scalable (learned from data, not hand-crafted) and
- compact (small but still powerful)?
- How can we choose the best actions at each step so the model reasons more effectively and efficiently?
- Does this approach actually improve performance on tough benchmarks without slowing the model down too much?
How does their method work?
The authors design a three-stage approach. Here’s the everyday version of each part:
1) Build a “toolbox” of actions from real examples
- They collect many problems from different domains (like math and science) and ask a strong LLM to extract common “reasoning sketches” — simple, reusable steps like “define key terms,” “set up an equation,” or “check edge cases.”
- These sketches form a proxy for the full action space. Think of it as building a universal toolbox of reasoning moves seen in real problem-solving.
2) Score actions with a smart function that balances usefulness and variety
- They define a submodular function. In plain terms: it’s a scoring rule designed to prevent adding too many similar actions and to favor actions that add new, unique value to the set.
- Two parts make up the score:
- Utility: How helpful is an action for the current state of the problem?
- Diversity: Are the actions different enough from each other to cover several good directions?
- Analogy: If you’re forming a team for a challenge, you want players who are individually strong (utility) and who have different skills (diversity). Adding yet another striker isn’t as helpful as adding a defender or a goalkeeper.
To estimate “utility,” they use an embedding model (a small neural network) that maps problem states and actions into numbers capturing meaning. The dot product between these embeddings acts like a “usefulness score.” They train this small model with a Q-learning style objective so it learns which actions tend to lead to better outcomes.
3) Pick the top actions and search the best path forward
- They use a greedy algorithm (fast and simple) to select a small number m of actions that maximize the utility+diversity score. This creates a compact action set for the current step.
- Then they run Monte Carlo Tree Search (MCTS) to estimate which action is best. MCTS is like trying out different paths in a maze many times, keeping track of which paths look promising.
- The base LLM (the main model) is not retrained; only the small embedding model is trained. This keeps things efficient.
Overall process at each step:
- Build a small, diverse, high-utility action set.
- Evaluate these actions by simulating possible future steps (MCTS).
- Choose the best action and continue reasoning.
What did they find?
The method was tested on six standard benchmarks across general knowledge, reasoning, and math:
- General: MMLU, MMLU-Pro
- Reasoning: GPQA, ARC-Challenge
- Math: GSM8K, MATH-500
Main results:
- DynaAct beat several strong baselines across all benchmarks.
- It was especially good on hard math (MATH-500), showing a large improvement over a strong model (rStar) by about 6.8 percentage points.
- It increased accuracy while keeping inference time reasonable. Compared to methods that either use fixed, hand-crafted actions or search the entire language space, DynaAct’s dynamic and compact action sets made search more effective without big slowdowns.
Why this matters:
- Compact, smart action sets guide the model’s thinking better than searching chaotically or relying on a few hand-picked actions.
- Balancing utility and diversity avoids redundancy and helps cover key reasoning moves, especially in complex, multi-step problems.
Why is this important?
This research shows a practical way to improve LLM reasoning at test time (when the model is solving a problem), without needing huge retraining or massive computation. It:
- Makes reasoning more focused by selecting a small set of good next moves.
- Scales across domains because the action space is learned from data, not manually defined.
- Improves performance on tough tasks (especially advanced math) while keeping inference smooth.
Potential impact:
- Better tutoring systems that reason through student questions step-by-step.
- More reliable AI assistants for science, engineering, and coding tasks.
- A general framework for guiding long-term reasoning in LLMs by choosing smart “what to do next” actions on the fly.
In short: DynaAct helps LLMs think more clearly by giving them the right small set of tools at each step, making complex problem-solving faster and more accurate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper; each point is framed to enable concrete follow-up work.
- Proxy action space construction
- Sensitivity to the source corpus and extraction setup is unquantified: no analysis of how the choice of dataset (e.g., Open-Platypus), grouping parameter k, prompt design, or the extraction LLM (Llama-3.1-70B) affects the quality and coverage of the proxy action space.
- Coverage and redundancy of the 40,822 extracted actions are not characterized: no metrics for domain coverage, synonym/near-duplicate collapse, or how many actions are actually used during inference across tasks.
- Cost and reproducibility of the offline extraction step are not reported (e.g., token count, GPU hours, prompt templates, sampling settings), making it difficult to reproduce or optimize this stage.
- Action semantics are under-specified: there are no concrete examples or a taxonomy/ontology of “observation sketches” that clarifies what constitutes an action and how generalizable these actions are across domains.
- Submodular objective design and guarantees
- Fixed trade-off weights α and β are not learned or adapted per state/task; no sensitivity study or principled scheme to adjust them based on uncertainty, difficulty, or performance feedback.
- The diversity term uses a nearest-neighbor “min-distance” heuristic; alternatives (e.g., facility location, determinantal point processes, mutual information proxies) and their effects on coverage/utility are not explored.
- Monotonicity of F is not established; the standard 1−1/e greedy approximation guarantee requires monotone submodularity, but the paper only states submodularity without proving monotonicity conditions.
- Computational scaling is under-examined: greedy selection incurs O(m2|A|) per step with dense similarity computation. There is no study of scalability when |A| grows (e.g., 100k–1M actions), nor exploration of approximate nearest-neighbor indexing, clustering, or pruning to keep selection tractable.
- No analysis of how the submodular selection interacts with multi-step planning: cross-step diversity, avoidance of repeated actions across time, or state-dependent action de-duplication are not modeled.
- Embedding model and Q-learning surrogate
- The Q-learning objective uses pseudo-rewards from offline sketches (r=1 for a single “ground-truth” action, r=0 otherwise), which may penalize equally valid alternative actions and induce label bias; multi-action validity is not accounted for.
- Calibration between the embedding similarity e(s)T e(a) and the realized MCTS Q(s,a) is unmeasured: no correlation or calibration study to verify that the learned surrogate prioritizes actions that actually yield higher downstream returns.
- Training details are incomplete and the objective contains typographical inconsistencies (missing parentheses), hindering exact reproduction; specifics such as negative sampling, temperature/scale, target networks, and stabilization tricks are not provided.
- State construction for training from sketches is unclear: how s_t (prefix state) is represented, how s_{t+1} is formed, and how these map to the runtime state representation used in MCTS are not described.
- No online or semi-online adaptation of embeddings: the model does not leverage test-time rollouts or feedback to refine e(·), leaving potential performance on new domains untapped.
- Integration with MCTS and action conditioning
- The mechanism by which a selected action conditions the world model (prompting format, control tokens, constraints) is not specified; compliance of the LLM to follow action directives is not measured.
- Reward shaping and MCTS hyperparameters are under-specified: whether rewards are purely terminal or include step-level signals, and sensitivity to UCB/exploration constants and rollout depth/width are not reported.
- The candidate budget m is fixed (m=5) across steps and tasks; there is no exploration of adaptive m (e.g., increasing candidates under high uncertainty or for harder states).
- Evaluation scope and baselines
- Generalization is only tested with a single 8B backbone on English QA/math; no results on stronger/smaller models, multilingual settings, code generation, or multimodal tasks despite the method’s general framing.
- Baselines omit simple yet informative alternatives: top-m by utility only (nearest neighbors), ANN-based retrieval from A, or hybrid retrieval+diversity methods; the ablation “−div” is not benchmarked against strong retrieval baselines with efficient indexing.
- Statistical rigor is limited: no variance over multiple seeds, confidence intervals, or significance tests; per-category error breakdowns and robustness analyses are minimal.
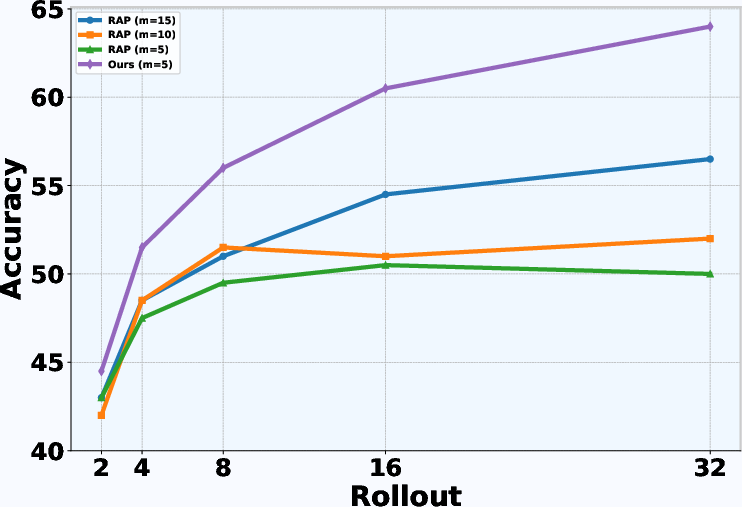
- Latency is reported only on MATH-500 with m=5 and 16 rollouts; absolute runtimes, hardware details, memory footprint, and scaling behavior as |A| increases are not provided.
- Failure cases and qualitative analyses are scarce: the paper lacks case studies showing when action selection harms performance, typical mis-selections, or instances where actions are ignored by the world model.
- Robustness, safety, and reliability
- Robustness to low-quality or adversarially extracted actions in A is not tested; no mechanisms for filtering harmful, off-policy, or domain-mismatched actions are discussed.
- There is no action-history awareness to discourage repeated or stale actions across steps; cross-step diversity and redundancy control remain open.
- No safeguards or audits addressing safety issues when action texts may steer the model toward unsafe content or undesired tool calls.
- Extensibility and system design
- Tool use and interactive environments are not considered: it remains open how dynamic action spaces interplay with external tools/APIs, execution feedback, or environment state beyond text-only contexts.
- The action space A is static and precomputed; methods to expand/prune A online, personalize to a domain, or specialize per task without re-running the expensive extraction pipeline are unexplored.
- Portability across backbones is unclear: whether e(·) and the action inventory transfer when swapping the world model or moving across domains has not been studied.
- Theoretical and empirical guarantees
- There are no end-to-end guarantees that improved candidate-set quality via submodular selection translates to better sample efficiency, faster convergence, or bounded regret in the induced MDP.
- No learning-theoretic analysis (e.g., data requirements vs. |A|, generalization bounds for the embedding scorer, or convergence properties when combined with MCTS) is provided.
- Reproducibility artifacts
- Precise prompts, the full extracted action list, and the procedure to derive training triples from sketches are not included in the main text; full replication depends on artifacts relegated to the appendix/GitHub, which are not summarized in sufficient detail here.
Practical Applications
Immediate Applications
Below are deployable use cases that can leverage the paper’s dynamic action space construction and submodular selection (utility + diversity) with minimal changes to current LLM workflows, given the findings of accuracy gains, compact candidate sets (e.g., m=5), and efficient inference with a frozen base model.
- LLM Reasoning Optimizer for Enterprise Inference
- Description: A drop-in middleware that builds a domain-specific proxy action space (from internal corpora), selects compact step-level action candidates via the submodular function, and routes the LLM’s next reasoning step using MCTS-evaluated Q-values.
- Sector: Software/AI platforms
- Tools/Products/Workflows: “Action Space Builder” (corpus ingestion + observation sketch extraction), “Submodular Action Selector” microservice, logging of Q-values and selected actions, caching for action embeddings
- Assumptions/Dependencies: Access to domain corpora; base LLM sufficiently capable; small embedding model training; rollout budget; alignment of utility term with task rewards
- Code Generation with Planning (“Plan then Code”)
- Description: Code assistants that prioritize diverse, high-utility steps (e.g., “design interface,” “write test,” “refactor,” “search docs”) to reduce dead-ends and improve correctness.
- Sector: Software engineering
- Tools/Products/Workflows: Integration with IDEs (VS Code, JetBrains), orchestration via LangChain/AutoGen, tool selection (test runner, linter, doc search) as actions
- Assumptions/Dependencies: Reliable observation extraction from code forums/repos; tool APIs; MCTS rollouts tuned to latency constraints
- Retrieval-Augmented Generation (RAG) Reasoning Router
- Description: Dynamic selection among actions like “retrieve,” “ground,” “critique,” “verify,” and “summarize” to improve factuality and reduce hallucinations.
- Sector: Knowledge management, enterprise search
- Tools/Products/Workflows: RAG pipelines augmented with DynaAct’s candidate-set constructor; precomputed embeddings for common actions; cost-aware scheduling
- Assumptions/Dependencies: Quality retrievers; domain corpora; embedding cache; alpha/beta tuned for utility vs diversity
- Customer Support Troubleshooting Assistant
- Description: Guided diagnostic workflows with compact, diverse candidate actions (e.g., “check configuration,” “verify permissions,” “reproduce issue,” “escalate”), improving first-contact resolution.
- Sector: Customer service/ITSM
- Tools/Products/Workflows: Call-center assistants; ticketing system integration; step-level action logging and analytics
- Assumptions/Dependencies: Up-to-date knowledge bases; mapping actions to escalation policies; human-in-the-loop oversight
- Math Tutoring and Homework Help
- Description: Educational assistants that trigger critical steps efficiently for complex problems (as shown by gains on GSM8K/MATH-500), with compact action sets to manage compute.
- Sector: Education/EdTech; daily life (students)
- Tools/Products/Workflows: Curriculum-specific observation libraries; “critical step coverage” evaluators; step-by-step scaffolding
- Assumptions/Dependencies: High-quality math corpora; safe reasoning prompts; student data privacy
- Compliance and Policy Checklist Assistants
- Description: Systematic, step-driven assessments (e.g., GDPR, SOC 2) using dynamic action selection to avoid redundant checks and ensure coverage of critical steps.
- Sector: Compliance, legal, risk
- Tools/Products/Workflows: Playbook import to build proxy action space; audit trail of chosen actions and Q-values; report generation
- Assumptions/Dependencies: Accurate regulatory corpora; human review; conservative action selection for safety
- Financial Research Notes and Scenario Analysis
- Description: Structured reasoning over company filings/news with action candidates like “aggregate indicators,” “stress test,” “cross-compare peers,” “risk flagging.”
- Sector: Finance (research/analysis)
- Tools/Products/Workflows: Analyst copilots; workflow orchestration; integration with data providers; “verify computations” action to use calculators
- Assumptions/Dependencies: Non-real-time decision-making; robust domain corpora; clear disclaimers; compliance constraints
- Tool-Orchestration Gateways (Calculator, Web Search, Code Executor)
- Description: Action selection among tools guided by utility and diversity; reduces spurious tool calls and increases success rates.
- Sector: Software/automation
- Tools/Products/Workflows: Toolformer-style wrappers; telemetry on tool-use Q-values; throttle policies
- Assumptions/Dependencies: Tool APIs; sandboxing; reward signal for utility learning
- Data Analysis Assistants (Analyst-in-the-Loop)
- Description: Step selection for EDA/modeling/reporting (e.g., “segment,” “feature select,” “fit baseline,” “validate,” “explain”), improving coverage of critical analytic steps.
- Sector: Data science/BI
- Tools/Products/Workflows: Notebook plugins; auto-generated analysis pipelines; action diversity checks to avoid redundant steps
- Assumptions/Dependencies: Domain datasets; appropriate reward proxies (accuracy, coverage); governance for data privacy
- Academic Evaluation and Benchmarking
- Description: Research tooling to measure “critical step coverage,” analyze action utility/diversity trade-offs, and compare inference scaling strategies.
- Sector: Academia/ML research
- Tools/Products/Workflows: Benchmark harnesses; ablation frameworks; open-source SDK wrapping DynaAct
- Assumptions/Dependencies: Annotated datasets for critical steps; reproducible evaluation; model access consistent with the paper’s setup
Long-Term Applications
Below are use cases that require further research, scaling, or domain grounding beyond language-only reasoning, often including safety, regulatory, and integration challenges.
- Clinical Decision Support and Care Pathways
- Description: Multi-step diagnostic and treatment planning with dynamic action spaces tuned for utility/diversity (e.g., “order test,” “interpret imaging,” “risk stratify,” “confirm guideline”).
- Sector: Healthcare
- Tools/Products/Workflows: EHR integration; physician-in-the-loop; regulated deployment; audit trails of action choices
- Assumptions/Dependencies: Medical corpora; rigorous validation; regulatory approvals; bias and safety controls; formal rewards aligned to outcomes
- Autonomous Robotics and Industrial Automation
- Description: Mapping compact natural-language action sets to grounded, executable skills to improve planning efficiency in complex tasks.
- Sector: Robotics/manufacturing
- Tools/Products/Workflows: Skill libraries; simulation-to-real transfer; submodular selection with physical constraints
- Assumptions/Dependencies: Action grounding; safety certification; real-time control interfaces; multi-modal state embeddings
- Energy Grid Operations and Resource Scheduling
- Description: Dynamic action selection for load balancing, maintenance scheduling, or demand response with compact, high-utility candidate sets.
- Sector: Energy
- Tools/Products/Workflows: Integration with SCADA; decision dashboards; simulators for reward shaping
- Assumptions/Dependencies: Reliable data streams; strict safety constraints; domain-specific rewards; expert validation
- Government Policy Analysis and Crisis Management
- Description: Scenario planning with diverse, utility-aware action sequences across information gathering, stakeholder analysis, and intervention design.
- Sector: Public policy/government
- Tools/Products/Workflows: Transparency toolkits; audit trails; participatory oversight; counterfactual analysis
- Assumptions/Dependencies: Expert-curated corpora; bias evaluation; alignment with democratic processes; explainability requirements
- Automated Trading Strategy Orchestration
- Description: Multi-step strategies that select among diverse analysis and execution actions (e.g., “risk check,” “hedge,” “rebalance,” “monitor signals”) in a compact candidate set.
- Sector: Finance (trading)
- Tools/Products/Workflows: Live data feeds; strict risk controls; compliance gating; backtesting infrastructure
- Assumptions/Dependencies: High-reliability rewards; low-latency embedding; robust out-of-distribution behavior; regulatory compliance
- Scientific Discovery Assistants
- Description: Dynamic proposal and selection of diverse, high-utility experimental actions to avoid redundant trials and accelerate hypothesis testing.
- Sector: Academia/R&D
- Tools/Products/Workflows: Lab automation integration; experiment registries; knowledge graph grounding
- Assumptions/Dependencies: Accurate domain knowledge; physical experiment interfaces; human oversight; reward signals tied to scientific outcomes
- Multi-Agent Systems with Coordinated Action Spaces
- Description: Agents negotiating compact, complementary action sets to improve team performance (e.g., in logistics, disaster response).
- Sector: Software/operations
- Tools/Products/Workflows: Communication protocols; joint submodular objectives; multi-agent MCTS
- Assumptions/Dependencies: Coordination mechanisms; scalable reward modeling; fairness across agents; robustness
- Standardized Cross-Domain “Action Libraries” and DSLs
- Description: Community-driven, versioned repositories of observation sketches and actions for consistent, interoperable reasoning across domains.
- Sector: Software standards/consortia
- Tools/Products/Workflows: Action-DSLs; schema validators; governance boards; compatibility layers
- Assumptions/Dependencies: Agreement on taxonomy; maintenance processes; licensing; benchmarks for coverage/utility
- Hardware Acceleration for Submodular Inference
- Description: Accelerators for fast action embedding, caching, and greedy submodular selection under tight latency budgets.
- Sector: Semiconductors/HPC
- Tools/Products/Workflows: Edge inference devices; approximate algorithms optimized in hardware; model-serving pipelines
- Assumptions/Dependencies: Sufficient demand; stable algorithms; energy efficiency; integration with LLM serving stacks
- Personalized Learning Pathways in LMS
- Description: Learners receive dynamically selected next steps (actions) that balance utility (learning gains) and diversity (skill coverage).
- Sector: Education
- Tools/Products/Workflows: LMS plugins; student modeling; adaptive assessment; step-level analytics
- Assumptions/Dependencies: Student data privacy; reliable learning rewards; educator oversight; fairness and accessibility
Notes on Feasibility and Dependencies Across Applications
- Requires accessible domain corpora to extract observation sketches (proxy action spaces); quality and representativeness of corpora strongly influence utility and diversity.
- Base LLM can remain frozen; only a small embedding model needs training via a Q-learning-like objective; embeddings for actions can be precomputed and cached to control latency.
- Submodular parameters (alpha/beta) and candidate-set size (m) must be tuned per domain; MCTS rollout budgets impact both accuracy and inference time.
- Reward proxies for utility learning are domain-specific; mis-specified rewards can degrade performance or lead to unsafe decisions.
- Safety, compliance, and human-in-the-loop oversight are essential for regulated or high-stakes sectors (healthcare, finance, energy, public policy).
- Generalization beyond the evaluated backbone (e.g., Llama-3.1-8B-Instruct) requires validation; performance may vary with different LLMs or toolchains.
Glossary
- ARC-challenge (ARC-C): A benchmark of science-based multiple-choice questions used to evaluate reasoning. "(4) ARC-challenge (ARC-C)~\citep{clark2018think} is part of the AI2 Reasoning Challenge and contains science-based multiple-choice questions."
- Autoregressive: A generation process where each output token depends on previously generated tokens. "perform reasoning in an autoregressive manner \citep{lightman2023let,guo2025deepseek}."
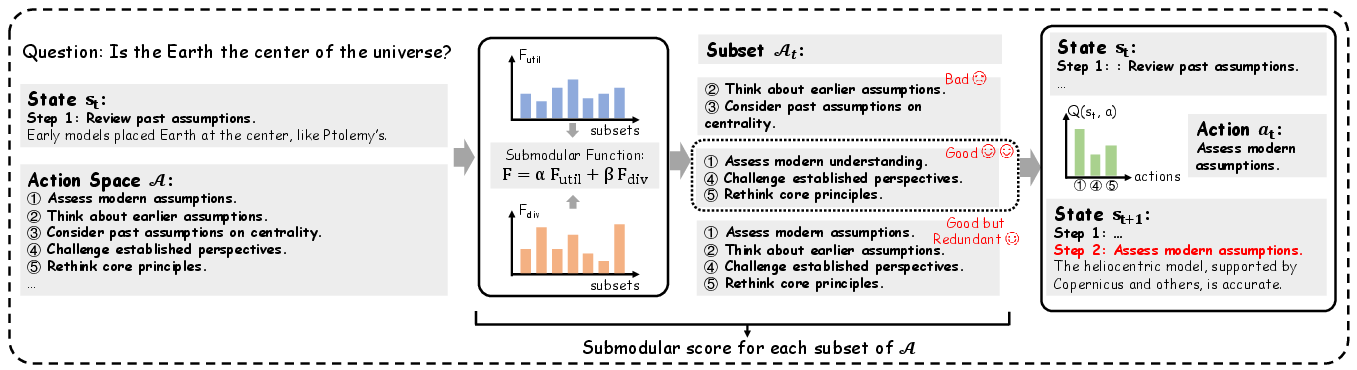
- Candidate action set: The subset of actions available for selection at a given reasoning step. "construct the candidate action set at each step"
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from LLMs. "Zero-shot CoT: This baseline uses Llama 3.1~\citep{dubey2024llama} with zero-shot Chain-of-Thought (CoT) prompting~\citep{wei2022chain}, generating reasoning paths in a single pass;"
- Combinatorial optimization: Optimization over discrete structures, often NP-hard, here approximated greedily. "the combinatorial optimization problem (Eq.~\eqref{eq:combprob}) can be effectively approximated by a greedy algorithm~\citep{nemhauser1978analysis}"
- Critical Step Coverage: A proxy metric measuring how often essential reasoning steps are triggered. "The ratio of solutions containing critical steps (referred to as the Critical Step Coverage) is then used as a proxy metric for utility."
- Discount factor: A scalar in an MDP that balances immediate versus future rewards. "The discount factor balances immediate and future rewards."
- Diminishing returns property: A characteristic of submodular functions where marginal gains decrease as the set grows. "leveraging the diminishing returns property of submodular functions to ensure linear computational complexity."
- Diversity term: A component in the objective that encourages selecting distinct actions to avoid redundancy. "which consists of a utility term and a diversity term."
- Embedding function: A mapping from states and actions to vectors in a shared representation space. "where is an embedding function that maps states and actions to a shared representation space."
- Exact match accuracy: A metric that counts a prediction as correct only if it exactly matches the ground truth. "We use exact match accuracy as the primary metric for evaluating the performance of our method."
- Greedy algorithm: An iterative selection strategy that adds the best available item at each step. "and employ a greedy algorithm to select an optimal candidate set."
- GPQA: A benchmark of graduate-level, open-domain problems focused on advanced reasoning. "(3) GPQA~\citep{rein2023gpqa} focuses on evaluating reasoning and problem-solving skills, providing real-world open-domain problems that require advanced reasoning to solve;"
- GSM8K: A benchmark of grade-school math word problems testing step-by-step reasoning. "(5) GSM8K~\citep{cobbe2021training} is a dataset consisting of grade-school level math word problems that require logical reasoning."
- Markov Decision Process (MDP): A formalism for sequential decision-making with states, actions, transitions, and rewards. "We investigate LLM reasoning within the framework of Markov Decision Process (MDP) \citep{hao2023reasoning}"
- Markov process: A process where the next state depends only on the current state and action. "Consequently, reasoning follows a standard Markov process:"
- MATH-500: A benchmark of high school-level math problems for evaluating advanced mathematical reasoning. "and (6) MATH-500~\citep{lightman2023let} is a dataset containing high school-level math problems."
- Monte Carlo Tree Search (MCTS): A simulation-based search method balancing exploration and exploitation to estimate action values. "We employ Monte Carlo Tree Search (MCTS) for estimating ~\citep{silver2016mastering}."
- MMLU: A broad benchmark covering general knowledge and reasoning across many domains. "(1) MMLU~\citep{hendrycks2020measuring} is a benchmark designed to evaluate a model's ability to answer a wide variety of tasks, including reading comprehension, reasoning, and problem-solving, across general domains."
- MMLU-Pro: A more challenging extension of MMLU with professional-level problems. "(2) MMLU-Pro~\citep{wang2024mmlu} is an extension of MMLU, containing more challenging and professional-level problems."
- Observation sketches: Generalized, core-operation cues extracted from problem corpora to guide reasoning. "We then query the LLM to extract general observation sketchs per group that can be applied broadly and focus solely on the core operations."
- Proxy action space: An approximate, automatically constructed set of candidate actions covering general reasoning patterns. "We first estimate an approximation as a proxy of the complete action space, denoted as ."
- Q-function: A function estimating the expected cumulative reward of taking an action in a state. "an action is then chosen according to a Q-function estimated via Monte Carlo tree search"
- Q-learning: A reinforcement learning method that learns action values via temporal-difference updates. "We formalize this requirement through Q-learning"
- Q-value: The expected future reward of executing a specific action in a given state. "approximates the Q-valueâthe expected future reward of executing action in state ."
- Reward function: A mapping that assigns scalar rewards based on the quality of reasoning steps. "while assigns rewards based on the quality of reasoning steps."
- Rollouts: Repeated simulations or generated trajectories used to evaluate or aggregate performance. "We use the SC@maj16 variant, which runs $16$ rollouts to increase the accuracy of reasoning;"
- Self-consistency (SC): An inference technique that generates multiple solutions and selects the most consistent outcome. "This method applies the self-consistency (SC) technique~\citep{wang2022self}"
- Submodular function: A set function with diminishing returns, used here to balance utility and diversity in action selection. "we propose a submodular function "
- Submodularity: The property of a function where adding an element yields less marginal gain as the set grows. "Owing to the submodularity of "
- Subset selection: Choosing a small, high-value subset from a larger candidate set. "can naturally be formalized as a subset selection task, where the goal is to identify a small, high-value subset"
- Test-time scaling: Increasing inference-time computation to improve reasoning performance. "using test time scaling strategies~\citep{snell2024scaling}"
- Transition function: The mapping that defines how states evolve given actions. "The transition function determines how actions transform the reasoning state"
- Utility term: A component measuring the expected benefit of candidate actions given the current state. "which consists of a utility term and a diversity term."
- Value function: A function estimating expected cumulative rewards from a state (often instantiated as Q). "a learnable value function that estimates the expected cumulative reward:"
- World model: A model of environment dynamics used to plan or evaluate reasoning steps. "The method~\citep{hao2023reasoning} integrates a world model and a reasoning agent"
Collections
Sign up for free to add this paper to one or more collections.