- The paper proposes MEGAMI, a generative framework that models mixing as a conditional diffusion process over effect embeddings.
- The approach integrates latent effect and content embeddings to enable multimodal, permutation-equivariant mixing outcomes, surpassing deterministic baselines.
- Evaluation shows MEGAMI achieves lower distributional distances and subjective quality close to or exceeding human-engineered mixes.
Automatic Music Mixing using a Generative Model of Effect Embeddings
Automatic music mixing involves blending isolated tracks using audio effects to yield a cohesive mixture. This task is inherently multimodal: for any set of input tracks, a variety of valid mixes exist that represent different artistic decisions. Prior deep learning systems typically frame mixing as a deterministic regression problem, forcing the model to learn an “average” mix and resulting in outputs that are generally conservative and lack expressiveness. The proposed MEGAMI (Multitrack Embedding Generative Auto MIxing) framework addresses these limitations by adopting a conditional diffusion model over a learned effect embedding space, enabling a generative, multimodal solution that disentangles mixing choices from underlying musical content.
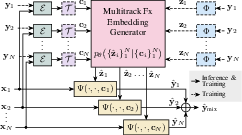
Figure 1: System diagram of MEGAMI illustrating conditional diffusion over effect embeddings, permutation-equivariant handling of arbitrary track sets, and the domain adaptation pipeline.
Methodology
Latent Effect Embedding and Conditional Diffusion Modeling
MEGAMI models p(ymix∣X), where X={xi}i=1N are unprocessed tracks. To disentangle mixing style from musical content, each wet (processed) track is projected via FxEncoder++ into an effect embedding zi, designed through contrastive learning to be injective with respect to production style and agnostic to musical content. Simultaneously, a content embedding ci is extracted from the dry track via CLAP, capturing semantic features like instrument identity without explicit labels.
A core innovation is to sample diverse mixing decisions by modeling the conditional distribution over effect embeddings Z^={z^i}i=1N using a diffusion process parameterized by a score-based transformer architecture. This model is permutation-equivariant, supporting arbitrary ordering and numbers of tracks; track identity is injected via concatenated one-hot vectors. Dynamic and stereo descriptors (log-RMS, crest factor, spread, width, etc.) are standardized, transformed into Fourier features, and concatenated to the main embedding.
Domain Adaptation for Wet-Only Training
A major practical challenge is the limited availability of paired dry/wet multitrack datasets. MEGAMI circumvents this by introducing a learned domain adaptor T, implemented as a shallow MLP, that projects the wet CLAP embedding toward the distribution of dry embeddings. The adaptor is trained with L2 loss on a small dry/wet paired dataset and smoothed by adding Gaussian noise, facilitating model training on large sets of unpaired wet stems. This strategy removes traces of applied effects from content conditioning, mitigating leakage and improving generative diversity.
Effect Processing
Each output track is reconstructed deterministically via a track-agnostic effect processor Ψ (a TCN), mapping (xi,z^i,ci)→y^i. Ψ receives concatenated effect and content embeddings, injected via feature-wise linear modulation. EQ normalization and RMS normalization stabilize training, and stereo information is inferred from the embedding, allowing mono inputs while targets are stereo. Training is supervised by multi-scale spectral loss and deep feature loss (via cosine distance between FxEncoder++ outputs of the reference and predicted track).
Objective Metrics
MEGAMI’s generative outputs are evaluated using Kernel Audio Distance (KAD), a distributional metric based on the Maximum Mean Discrepancy over various embedding spaces (AFxRep, FxEncoder, FxEncoder++, CLAP). Unlike pairwise metrics, this approach properly accounts for multimodality in mixing outcomes.
MEGAMI consistently achieves the lowest distributional distances to human mixes, outperforming all deterministic and end-to-end deep baselines. When trained on a larger, wet-only dataset with domain adaptation (I-L), results improve further, demonstrating the scaling potential of the generative effect embedding approach. Oracle variants (with ground-truth effect embeddings) set an upper bound on effect processor performance, and MEGAMI approaches these results within a narrow margin.
Subjective Metrics
A listening test was conducted in controlled acoustic conditions. Participants rated production quality across genres for mixes produced by MEGAMI, several baselines, and human engineers. MEGAMI approaches human-level quality on average, and on multiple examples was rated superior to the human reference mix. Acoustic artifacts present in baselines (especially FxNorm-AutoMix and E2E-Flow) were penalized. Equal Loudness performed unexpectedly well for certain genres, highlighting nontrivial interactions between content distribution and perceived mix quality.
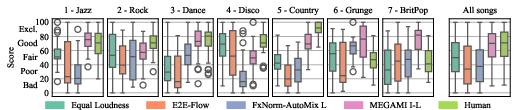
Figure 2: Boxplots of subjective test scores per-song and aggregated, MEGAMI matches or exceeds human mixing on several examples.
Architectural and Implementation Details
The core score model comprises a 70M parameter transformer, supporting permutation-equivariant attention and dynamic track count (zero padding and mask-based attention). The effect processor (Ψ) is a 9M parameter TCN. Data pipeline supports stereo at 44.1 kHz, with segments of 11.9s. Embedding extractors (FxEncoder++, CLAP) operate on mono, while effect processor outputs are stereo. For public variants, dry/wet pairs are synthetically generated using randomized effect chains and public IR datasets. All code is to be released for reproducibility and further research.
Implications and Future Directions
MEGAMI demonstrates that factorizing mixing decisions into effect embedding space, combined with a generative diffusion model, enables modeling the complex, multimodal nature of professional music mixing. Domain adaptation in representation space permits leveraging vast wet-only datasets, which dramatically expands applicability beyond prior art. The qualitative and quantitative results indicate the potential for systems that yield mixes at or above human engineer quality, raising important questions about the future role of AI in creative audio production.
Opportunities for future work include:
- Training on larger and more diverse datasets, leveraging synthetic mixes to boost data scale.
- Replacing the black-box effect processor with explicit parameter estimation networks for interpretability and user control.
- Introducing time-varying embeddings for dynamic mix automation (e.g., varying effects by section or over song progression).
- Extending modeling to album-level consistency for mastering workflows.
Conclusion
The generative, effect-embedding-based MEGAMI system constitutes a decisive advance in automatic music mixing by enabling one-to-many, multimodal modeling of mixing decisions. The framework’s domain adaptation and permutation-equivariant transformer design support robust training on challenging datasets and arbitrary track sets. Empirical results demonstrate superior objective and subjective performance relative to leading baselines, with outputs that approach or even surpass human engineering. This methodology sets the stage for scalable, controllable, and expressive AI-based music mixing.