- The paper presents a new MoE architecture combining cross-layer expert sharing with pre-gated routing to reduce parameters and memory footprint for device-native LLMs.
- It details innovative training techniques including a three-stage curriculum on 5T tokens and reinforcement learning with verified rewards to enhance performance.
- Empirical results show Megrez2-Preview outperforming larger models across general, reasoning, and code generation benchmarks while using far fewer parameters.
Megrez2: Efficient Expert Sharing and Pre-Gated Routing for Device-Native LLMs
Introduction
Megrez2 introduces a Mixture-of-Experts (MoE) LLM architecture designed to address the deployment trilemma of speed, accuracy, and cost in device-native AI. The architecture is motivated by the need to deliver high performance on resource-constrained hardware, where traditional scaling of dense LLMs is infeasible due to memory, latency, and power limitations. Megrez2's core innovations—cross-layer expert sharing and pre-gated routing—enable substantial reductions in parameter count and memory footprint while maintaining competitive model capacity and accuracy.
Figure 1: The Impossible Triangle of Device AI, illustrating the trade-off between speed, accuracy, and cost in on-device model deployment.
Architectural Innovations
Cross-Layer Expert Sharing
Megrez2 departs from conventional MoE designs by sharing expert parameters across n consecutive transformer layers. This grouping reduces the total number of unique parameters by a factor of n, while preserving the number of activated parameters per token. Each group of n layers shares a pool of M experts, but each layer retains its own gating network and projection weights. This design maintains the model's representational capacity and specialization, while significantly improving parameter efficiency and hardware utilization.
Pre-Gated Routing
To further optimize for device deployment, Megrez2 incorporates pre-gated routing. Here, the gating decision for layer i is computed in the preceding layer (i−1), allowing the model to prefetch and cache the required expert parameters. This approach reduces memory fragmentation and enables efficient pipelining of computation and parameter loading, which is critical for low-latency inference on memory-constrained devices.
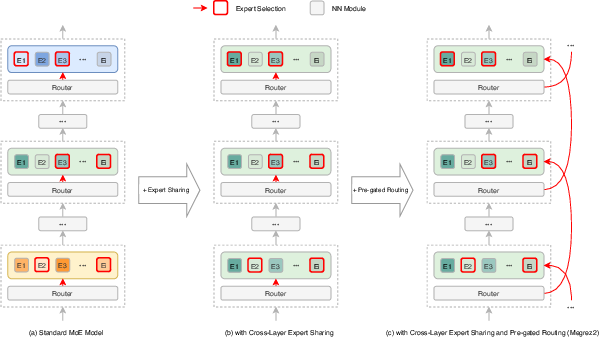
Figure 2: Expert sharing and pre-gated routing in the Megrez2 model, illustrating the reduction in unique parameters and the memory-efficient expert loading pipeline.
Model Configuration
Megrez2-Preview, the first instantiation of this architecture, consists of 31 layers, with the first being dense and the remainder organized into groups of three layers sharing 64 experts per group. Each layer selects the top-6 experts via routing and includes 4 shared experts. The model uses a hidden size of 10,944 for dense layers and 1,408 for each expert, with a total of 3B activated and 7.5B stored parameters.
Training Methodology
Pre-Training
Megrez2-Preview is pre-trained on a 5-trillion-token corpus spanning web text, code, STEM content, books, and synthetic reasoning data. The training follows a three-stage curriculum:
- Foundational Stage: 1.5T tokens, focusing on general language modeling.
- Knowledge and Reasoning Augmentation: 3T tokens, emphasizing high-quality, diverse, and synthesized reasoning data.
- Long-Context Extension: 600B tokens, extending context length to 32K tokens using increased RoPE base frequency and specialized long-context datasets.
Supervised Fine-Tuning
Supervised fine-tuning is performed on millions of curated samples, including distilled and synthesized reasoning data. A novel turn-level loss is introduced for multi-turn dialogue, normalizing loss per conversational turn to improve accuracy in complex conversational settings. Training samples are concatenated into fixed-length sequences (4K or 32K tokens) with attention masks and positional encodings reset to prevent information leakage.
Reinforcement Learning with Verified Reward
Reinforcement learning is applied using a filtered dataset of math and reasoning tasks, with a binary reward function and a modified PPO loss. The training pipeline ensures a balanced difficulty distribution and disables KL regularization to encourage exploration. This stage further enhances the model's reasoning and problem-solving capabilities.
Empirical Results
Megrez2-Preview is evaluated on a comprehensive suite of benchmarks, including general language understanding (C-EVAL, MMLU-Pro), instruction following (IFEval), mathematical reasoning (MATH-500, GSM8K), and code generation (HumanEval, MBPP). The model consistently matches or outperforms larger models such as Qwen2.5-7B, Qwen3-8B, and Gemma-3-4B, despite having significantly fewer activated and stored parameters.
Key findings include:
- General Tasks: Megrez2-Preview achieves 91.7 on C-EVAL and 67.6 on MMLU-Pro, outperforming models with more than double the parameter count.
- Instruction Following: Achieves 80.2 on IFEval, closely tracking or surpassing larger models.
- Mathematical Reasoning: Scores 81.6 on MATH-500 and 83.6 on GSM8K, demonstrating strong numerical and symbolic reasoning.
- Code Generation: Achieves 74.4 on HumanEval and 88.0 on MBPP, outperforming all other models in at least one benchmark.
These results highlight the effectiveness of cross-layer expert sharing and pre-gated routing in achieving a favorable balance between model size, computational efficiency, and task performance.
Practical and Theoretical Implications
Megrez2's architecture provides a scalable and deployable solution for on-device AI, enabling high-quality LLM inference within strict memory and latency budgets. The cross-layer expert sharing mechanism offers a new axis for MoE efficiency, reducing redundancy without sacrificing specialization. Pre-gated routing addresses a critical bottleneck in MoE deployment by aligning expert loading with hardware constraints.
Theoretically, the work demonstrates that parameter sharing across layers can be leveraged to compress model size while maintaining or even enhancing performance, challenging the assumption that layer-wise independence is necessary for expert specialization. The empirical results suggest that careful architectural and training design can close the performance gap between compact and large-scale models.
Future Directions
Potential avenues for further research include:
- Extending cross-layer expert sharing to deeper or more heterogeneous architectures.
- Exploring dynamic group sizes or adaptive expert sharing based on input characteristics.
- Integrating quantization and pruning techniques with the Megrez2 framework for further efficiency gains.
- Investigating the impact of expert sharing on transfer learning and domain adaptation.
Conclusion
Megrez2 presents a practical and effective approach to building high-performance, device-native LLMs. By combining cross-layer expert sharing with pre-gated routing, it achieves strong empirical results across a range of tasks with a compact parameter footprint. The architecture offers a compelling solution for real-world applications where resource constraints are paramount, and sets a foundation for future research in efficient, scalable MoE-based LLMs.

