- The paper presents a diffusion forcing sampler that enables parallel token generation, bridging recurrent-depth models and diffusion processes to accelerate inference.
- It introduces adaptive techniques such as convergence detection via normalized distance thresholds and KV cache sharing to optimize computational efficiency and memory usage.
- Empirical evaluations on reasoning and coding benchmarks show up to a 5x speedup with under 1% accuracy loss, highlighting the sampler’s practical deployment potential.
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion LLMs
Introduction and Motivation
This paper investigates the intersection of recurrent-depth LLMs and diffusion-based generative modeling, proposing a novel parallel sampling algorithm—diffusion forcing—for recurrent-depth transformers. The motivation stems from the observation that while recurrent-depth models (universal/looped transformers) offer increased expressiveness and reasoning capabilities compared to fixed-depth architectures, their autoregressive generation is inherently slow due to sequential recurrence. By leveraging principles from diffusion models, the authors introduce a sampler that enables parallel generation along the sequence dimension, substantially accelerating inference without sacrificing theoretical expressiveness.
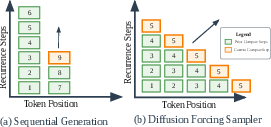
Figure 1: Comparison of standard sequential generation and diagonal parallelization via diffusion forcing in recurrent-depth models.
Architectural Foundations and Sampler Design
The recurrent-depth model architecture under consideration consists of three blocks: a prelude for input embedding, a recurrent block for iterative latent refinement, and a coda for token prediction. The key insight is that the iterative refinement of latent states in recurrent-depth models is structurally analogous to the denoising process in diffusion models. This analogy enables the adaptation of diffusion forcing sampling, which iteratively refines candidate tokens in parallel across the sequence, rather than strictly sequentially.
The sampler operates by decoding new tokens at every forward pass, with latent states for each token position refined in parallel. Crucially, the sampler incorporates input injection (conditioning on embeddings), robust recurrence (intermediate states are decodable), and KV cache sharing (memory efficiency), making it broadly applicable to recurrent-depth architectures that satisfy these properties.

Figure 2: Example of text sequence generation with diffusion forcing, showing rapid parallel commitment of multiple tokens compared to standard recurrence.
Algorithmic Details and Adaptive Computation
The core algorithm (see Algorithm 1 in the paper) advances the generation wavefront by at least one token per recurrence step, freezing tokens whose latent states have converged according to a normalized distance threshold in latent space. This adaptive exit criterion ensures that computation is not wasted on already-converged positions and prevents premature freezing of unresolved states, which could degrade output quality.
The sampler supports additional stabilizing mechanisms inspired by diffusion literature, such as momentum in input conditioning and scheduled noise injection into latent states. These components further enhance convergence and robustness, especially for challenging sequences.
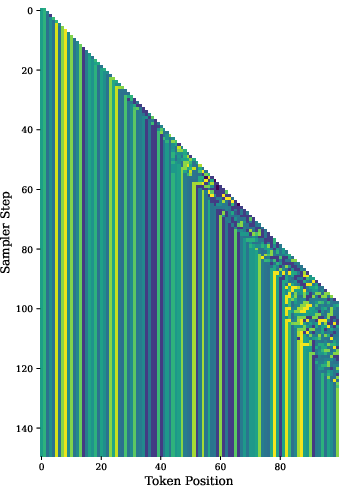
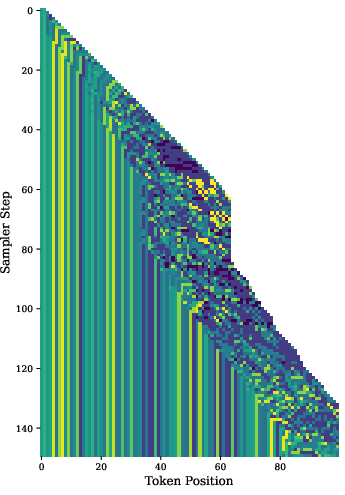
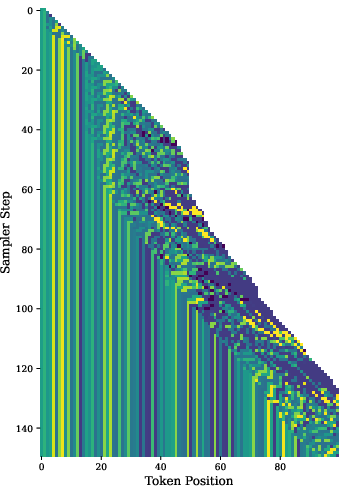
Figure 3: Visualization of adaptive sampler behavior under different hyperparameter settings, illustrating dynamic wavefront stalling and resolution.
Theoretical Analysis: Depth vs. Width Scaling
The paper provides a formal analysis of the trade-offs between depth and width scaling in recurrent-depth models. During prefilling, depth scaling (increasing recurrence) is shown to be more expressive and efficient than width scaling (sequence replication), except for very short prompts. During decoding, however, width scaling via diffusion forcing enables greater parallelism and expressiveness under identical runtime constraints, as the sampler can process multiple tokens in parallel without increasing model parameters or memory footprint (due to KV cache sharing).
Empirical Evaluation
Extensive experiments on reasoning and coding benchmarks (GSM8K, MATH500, HumanEval, MBPP) demonstrate that the diffusion forcing sampler achieves up to 5x speedup in tokens/second compared to optimized autoregressive baselines, with negligible loss in accuracy (typically <1%). The sampler also outperforms speculative decoding approaches, and its performance is robust across different model variants and hyperparameter choices.
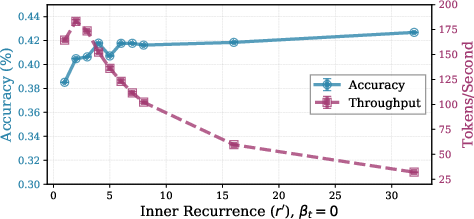
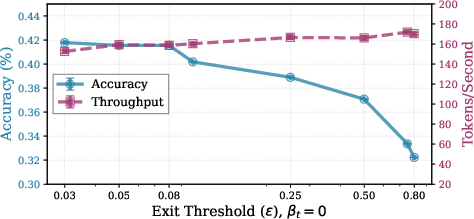
Figure 4: Trade-off between accuracy and speed on GSM8K as a function of inner recurrence and exit threshold.
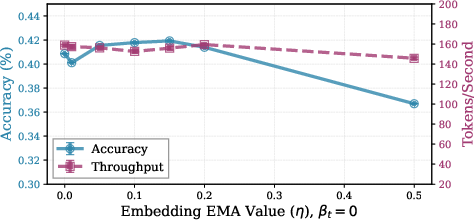
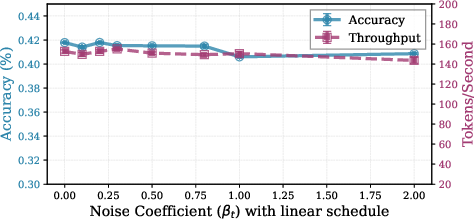
Figure 5: Ablation of momentum and noise hyperparameters, showing optimality of small nonzero momentum and limited benefit of noise at moderate recurrence.
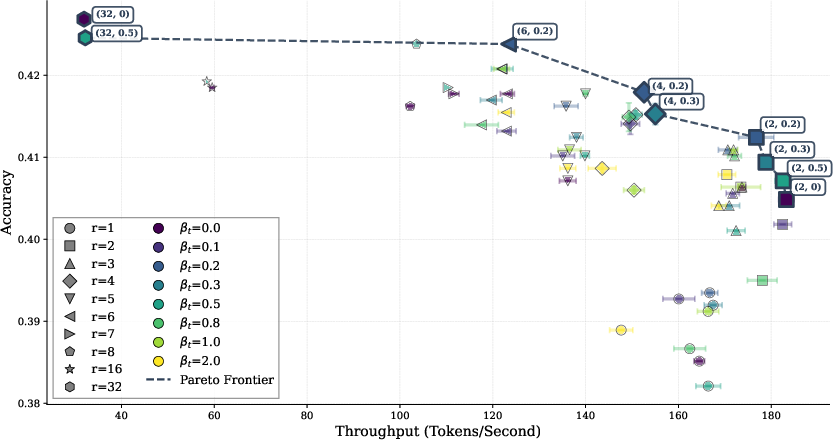
Figure 6: Pareto frontier of accuracy vs. throughput for various inner recurrence and noise settings, with moderate noise dominating no-noise runs.
Hyperparameter Sensitivity and Deployment Considerations
The sampler's performance is stable across a wide range of hyperparameters, including inner recurrence steps, exit thresholds, wavefront size, and headway. Optimal wavefront sizes are accelerator-dependent, with values between 64 and 128 tokens yielding maximal parallelization on A100 GPUs. Advancing the sampler by more than one token per step (headway > 1) does not yield practical speedups for the studied model, due to causality constraints.
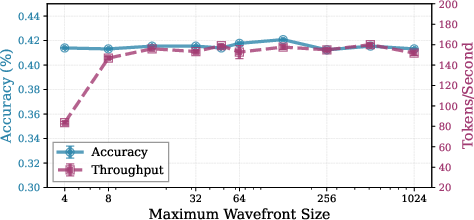
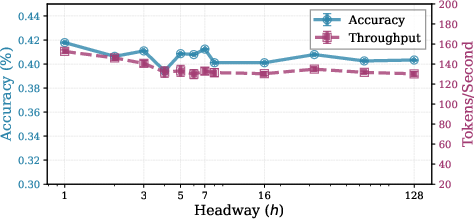
Figure 7: Impact of wavefront size and headway on GSM8K performance, highlighting optimal parallelization and limited benefit of increased headway.
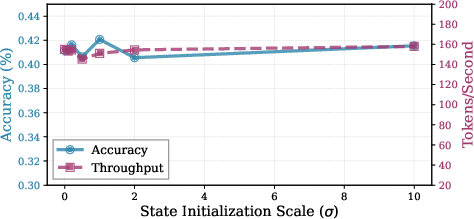
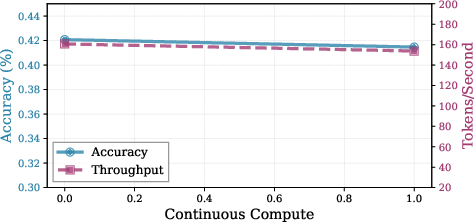
Figure 8: Minor effect of initialization scale and limited benefit of continuous compute initialization for new states.
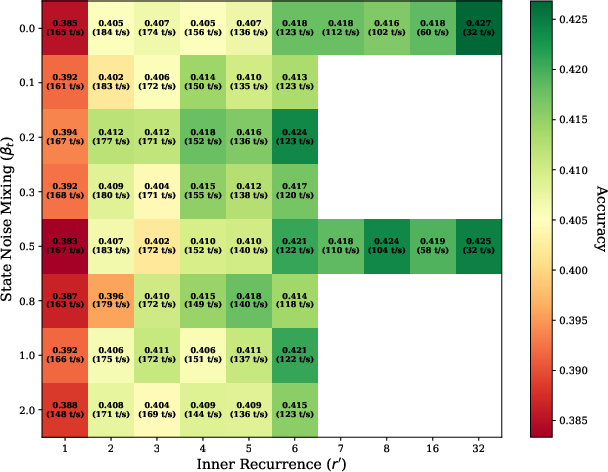
Figure 9: Heatmap of accuracy and throughput across noise and inner recurrence hyperparameter space.
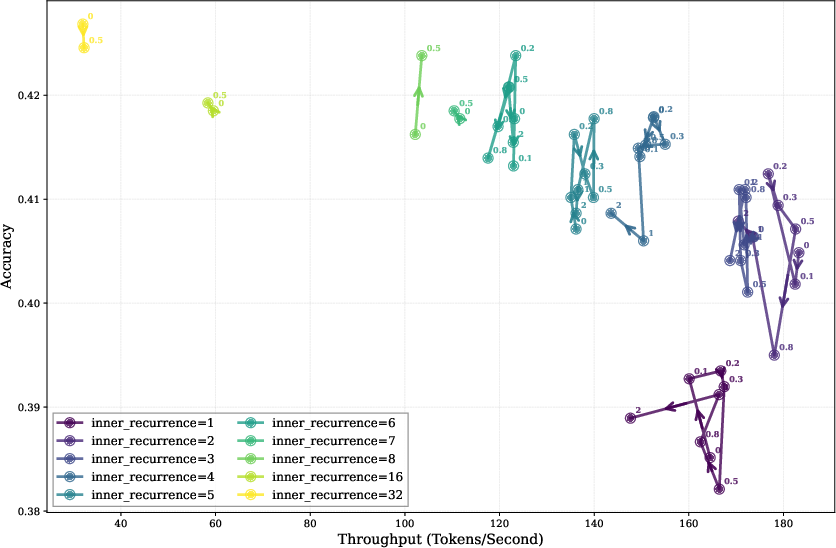
Figure 10: Additional visualizations of the trade-off between noise and inner recurrence.
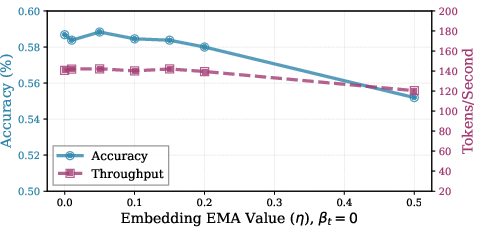
Figure 11: Hyperparameter robustness for a math-finetuned model, showing consistent behavior across model capabilities.
Practical Implications and Future Directions
The proposed diffusion forcing sampler enables efficient, parallelized inference for recurrent-depth LLMs, making them viable for deployment in latency-sensitive applications. The approach is compatible with existing architectures and does not require retraining, provided input injection and robust recurrence are present. The connection to diffusion models suggests that recurrent-depth transformers can be interpreted as continuous latent diffusion models, opening avenues for hybrid training objectives and further integration of diffusion-based techniques in language modeling.
Theoretical and empirical results indicate that parallel samplers can unlock the computational advantages of recurrent-depth models, especially for long-form generation and complex reasoning tasks. Future work may explore batched inference engines, more sophisticated adaptive exit criteria, and the design of architectures that further unify recurrent and diffusion modeling paradigms.
Conclusion
This work establishes a principled and practical framework for parallelizing inference in recurrent-depth LLMs via diffusion forcing sampling. The approach delivers substantial speedups with minimal accuracy trade-offs, is theoretically justified, and empirically validated across multiple benchmarks and model variants. The findings suggest a deep connection between recurrent-depth and diffusion models, with implications for both model design and efficient deployment in real-world systems.

