- The paper introduces a joint optimization framework that synchronizes camera pose estimation and 3D Gaussian Splatting, reducing pose drift in long videos.
- It employs adaptive octree-based anchor formation to efficiently manage memory while preserving detailed scene geometry.
- Experimental results show state-of-the-art rendering quality and fast training speeds with high PSNR, SSIM, and low pose errors.
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Introduction and Motivation
LongSplat introduces a robust framework for novel view synthesis (NVS) from casually captured long videos, addressing the challenges of irregular camera motion, unknown poses, and large-scale scene complexity. Existing NVS methods relying on Structure-from-Motion (SfM) preprocessing (e.g., COLMAP) frequently fail in casual scenarios due to pose drift and incomplete geometry, while COLMAP-free approaches suffer from memory bottlenecks and fragmented reconstructions. LongSplat circumvents these limitations by jointly optimizing camera poses and 3D Gaussian Splatting (3DGS) in an incremental, correspondence-guided manner, leveraging learned 3D priors and adaptive octree-based anchor formation.

Figure 1: Novel view synthesis for casual long videos. Existing methods fail due to pose drift, memory constraints, and fragmented geometry; LongSplat robustly reconstructs scenes and synthesizes novel views.
Methodology
3D Gaussian Splatting and Anchor-Based Representation
LongSplat builds upon 3DGS, representing scenes as sets of 3D Gaussians parameterized by position, covariance, color, scale, rotation, and opacity. For memory efficiency and scalability, it employs anchor-based 3DGS, where anchors are spatially distributed voxels, each emitting k Gaussians via lightweight MLPs. This structure enables efficient densification and pruning, adapting Gaussian density to local scene complexity.
A key innovation is the Octree Anchor Formation strategy, which adaptively subdivides space based on local point cloud density. Starting from MASt3R-generated dense point clouds, voxels exceeding a density threshold are recursively split, while low-density voxels are pruned. This results in a hierarchical, duplication-free anchor structure that compresses memory usage while preserving geometric detail.
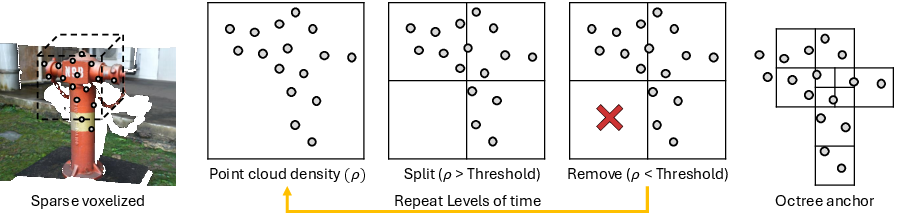
Figure 2: Octree Anchor Formation adaptively splits/prunes voxels by density, yielding efficient, scalable anchor representation for large scenes.
Pose Estimation Module
Camera pose estimation is performed incrementally for each frame using 2D-3D correspondences from MASt3R. Initial pose is solved via PnP with RANSAC, followed by photometric refinement against the current 3DGS scene to minimize reprojection error. Depth scale drift is corrected by aligning rendered and predicted depths. Newly visible regions are detected via occlusion masks and unprojected into 3D, expanding the anchor set via octree formation.
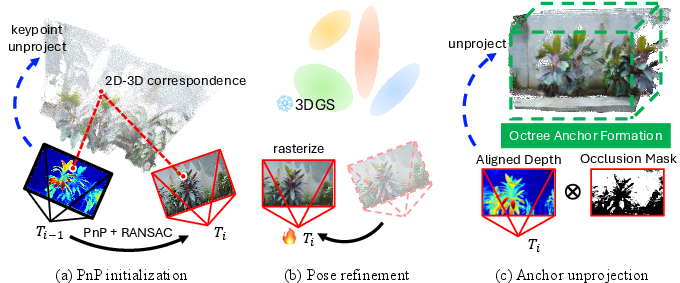
Figure 3: Camera pose estimation combines PnP initialization, photometric refinement, and anchor unprojection for robust tracking and scene expansion.
Incremental Joint Optimization
LongSplat alternates between local and global optimization. Local optimization updates Gaussians within a visibility-adapted window, dynamically selected based on anchor covisibility (IoU) between frames. Global optimization periodically refines all poses and Gaussians for long-range consistency. The total loss combines photometric, depth, and keypoint reprojection terms, ensuring multi-view coherence and robust geometry.
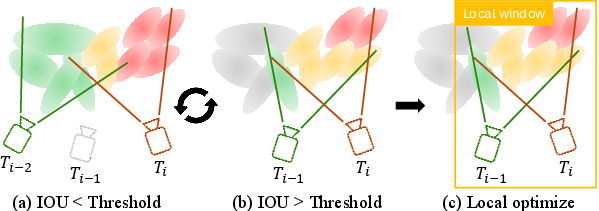
Figure 4: Visibility-Adapted Local Window dynamically selects frames for local optimization, balancing training coverage and reconstruction detail.
Experimental Results
LongSplat is evaluated on Tanks and Temples, Free, and Hike datasets, demonstrating superior rendering quality (PSNR, SSIM, LPIPS) and pose accuracy (ATE, RPE) compared to COLMAP-based and unposed baselines. On the Free dataset, LongSplat achieves an average PSNR of 27.88 dB, SSIM of 0.85, and LPIPS of 0.17, outperforming all baselines. Pose estimation errors are significantly reduced (ATE: 0.004), with stable trajectories even in long, unconstrained sequences.

Figure 5: Qualitative comparison on Free dataset; LongSplat yields sharper, more coherent reconstructions than competing methods.
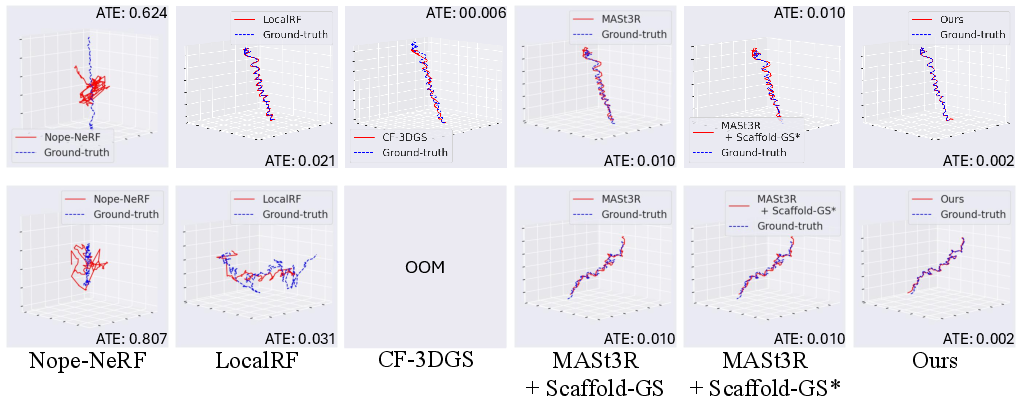
Figure 6: Visualization of camera trajectories; LongSplat maintains stable, accurate pose estimates across long sequences.
On Tanks and Temples, LongSplat achieves state-of-the-art results (PSNR: 32.83 dB, SSIM: 0.94, LPIPS: 0.08), with minimal pose drift.

Figure 7: Qualitative comparison on Tanks and Temples; LongSplat reconstructs fine details and accurate geometry.
On the Hike dataset, LongSplat outperforms LocalRF and MASt3R+Scaffold-GS, achieving PSNR of 25.39 dB and SSIM of 0.81.
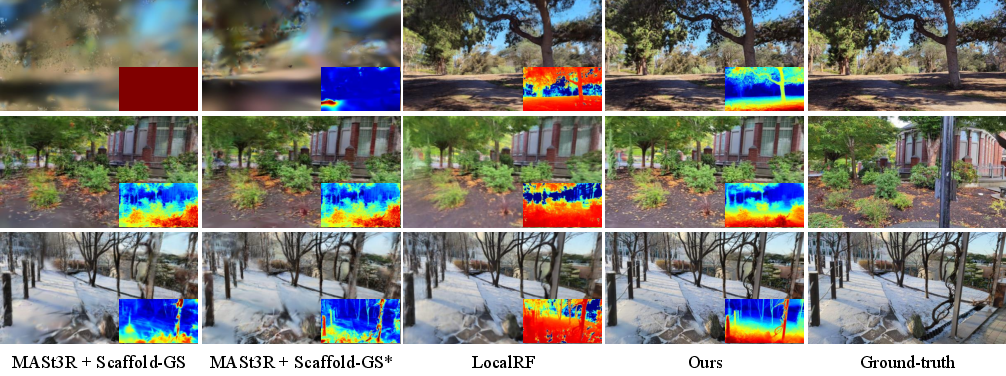
Figure 8: Qualitative results on Hike dataset; LongSplat preserves structural details and reduces artifacts in challenging outdoor scenes.
Ablation Studies
Ablations confirm the necessity of each module. Removing pose estimation, global, or local optimization degrades both rendering and pose accuracy. The visibility-adaptive window outperforms fixed-size or global windows, yielding the best trade-off between local detail and global consistency. Adaptive octree anchor formation achieves 7.92× memory compression over dense unprojection, with no loss in quality.
Efficiency and Robustness
LongSplat achieves 281.71 FPS and trains in 1 hour on a single RTX 4090, dramatically faster than LocalRF and CF-3DGS. Robustness analysis shows consistently lower cumulative pose errors (ATE, RPE) than all baselines.
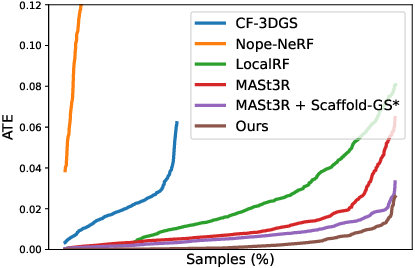
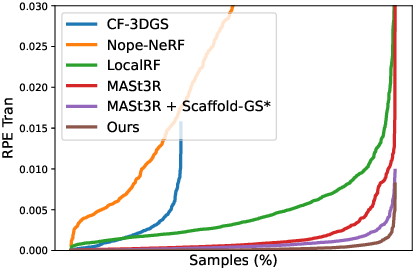
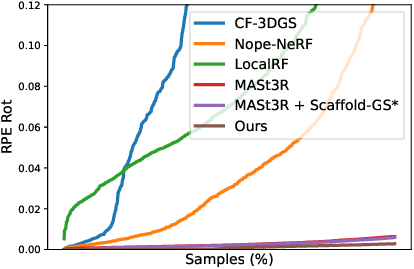
Figure 9: Robustness analysis; LongSplat achieves lower pose errors and reduced drift compared to existing methods.
Implementation Considerations
LongSplat is implemented atop Scaffold-GS, with CUDA-accelerated differentiable rasterization for pose optimization. Octree density thresholds and visibility IoU are tunable for scene complexity. The framework is scalable to thousands of frames and large scenes, with memory usage controlled by adaptive anchor formation. Limitations include static scene assumption and fixed intrinsics; dynamic objects and variable focal lengths are not supported.
Implications and Future Directions
LongSplat advances unposed NVS for casual long videos, enabling robust reconstruction and real-time rendering without SfM or pose priors. The incremental joint optimization and adaptive anchor strategies are extensible to dynamic scenes, multi-camera setups, and online SLAM. Future work may address dynamic object handling, self-calibration of intrinsics, and integration with foundation models for further robustness.
Conclusion
LongSplat provides a robust, scalable solution for unposed 3D Gaussian Splatting in casual long videos, achieving state-of-the-art rendering and pose accuracy with efficient memory usage and training speed. Its incremental optimization and adaptive anchor formation set a new standard for NVS in unconstrained, real-world scenarios.