VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction (2509.19297v1)
Abstract: Feed-forward 3D Gaussian Splatting (3DGS) has emerged as a highly effective solution for novel view synthesis. Existing methods predominantly rely on a pixel-aligned Gaussian prediction paradigm, where each 2D pixel is mapped to a 3D Gaussian. We rethink this widely adopted formulation and identify several inherent limitations: it renders the reconstructed 3D models heavily dependent on the number of input views, leads to view-biased density distributions, and introduces alignment errors, particularly when source views contain occlusions or low texture. To address these challenges, we introduce VolSplat, a new multi-view feed-forward paradigm that replaces pixel alignment with voxel-aligned Gaussians. By directly predicting Gaussians from a predicted 3D voxel grid, it overcomes pixel alignment's reliance on error-prone 2D feature matching, ensuring robust multi-view consistency. Furthermore, it enables adaptive control over Gaussian density based on 3D scene complexity, yielding more faithful Gaussian point clouds, improved geometric consistency, and enhanced novel-view rendering quality. Experiments on widely used benchmarks including RealEstate10K and ScanNet demonstrate that VolSplat achieves state-of-the-art performance while producing more plausible and view-consistent Gaussian reconstructions. In addition to superior results, our approach establishes a more scalable framework for feed-forward 3D reconstruction with denser and more robust representations, paving the way for further research in wider communities. The video results, code and trained models are available on our project page: https://lhmd.top/volsplat.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
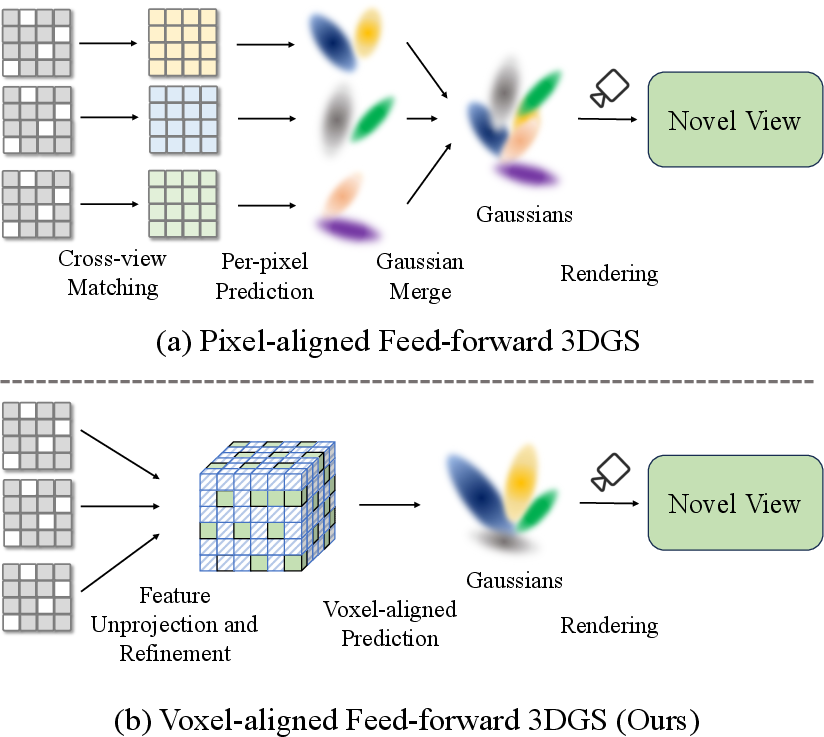
This paper introduces a new way to quickly build 3D scenes from a few photos and then show those scenes from new viewpoints (like moving a camera around a room you’ve never seen before). The method is called VolSplat. It improves on earlier techniques by thinking and predicting directly in 3D space, making the results cleaner, sharper, and more consistent.
The main questions the paper asks
- How can we turn a handful of 2D photos into a good-looking 3D scene, fast?
- Why do previous “pixel-based” methods (which predict 3D from each image pixel) make mistakes like fuzzy edges, floating dots (“floaters”), and inconsistent shapes?
- Can switching from pixel-based predictions to voxel-based predictions (tiny 3D cubes) solve those issues and make the result more reliable?
How the method works (with everyday analogies)
To understand VolSplat, it helps to know a few ideas:
- Pixels vs. voxels:
- A pixel is a tiny square in a 2D image.
- A voxel is like a tiny cube in 3D space, similar to a building block in Minecraft.
- 3D Gaussian splats:
- Imagine representing a scene using lots of soft, colored blobs in 3D. Each blob (a “Gaussian”) has a position, size/shape, color, and transparency. When you render them together, you get a realistic image from any viewpoint.
Earlier methods took features from each pixel and tried to “unproject” them into 3D. That sounds simple, but it causes trouble when:
- Some parts are hidden behind others (occlusion).
- Surfaces have little texture (like plain white walls).
- The camera viewpoints are few or far apart.
VolSplat flips the process:
- Instead of predicting per pixel, it builds a 3D grid of voxels first and puts the image information into the correct 3D places. Then it predicts the 3D blobs (Gaussians) from that 3D grid.
Here’s the step-by-step flow:
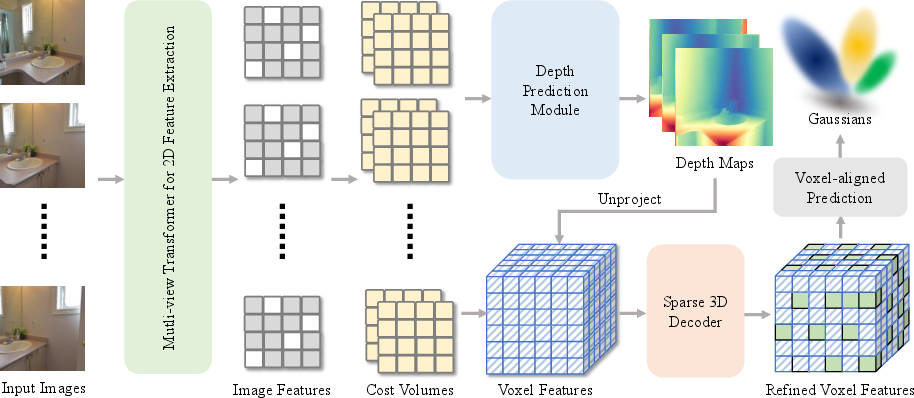
Step 1: Collect clues from the input images
The system takes several photos and finds patterns and depth hints in them (depth is how far things are). It uses a common trick called “plane sweeping” to compare images at different depth layers and estimate how far each point might be.
Step 2: Build a 3D voxel grid
Using the estimated depth and camera positions, it “lifts” the 2D information into 3D, placing features into tiny cubes (voxels) in a shared 3D coordinate space. Think of it as pouring 2D paint into the correct spots in a 3D mold.
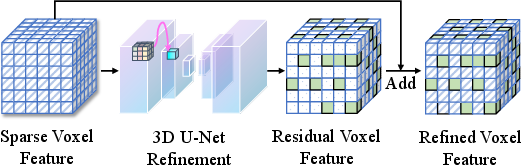
Step 3: Refine the 3D features
A 3D neural network (a 3D U-Net) smooths and enhances the features inside the voxel grid. This helps connect nearby information and fix mistakes, much like tidying up a blocky sculpture to make details clearer.
Step 4: Predict 3D Gaussians per voxel
From the refined 3D features, the system predicts where to place each soft 3D blob (its center), how large and stretched it should be (its shape), how transparent it is, and what color it should show from different directions.
Step 5: Render new views
Finally, it renders images from new camera angles by blending the effects of all these 3D blobs, producing realistic pictures of the scene from places the camera never actually went.
What’s new and why it helps
- From pixels to voxels:
- Pixel-based predictions depend heavily on matching 2D image features across views, which easily breaks when things are hidden or low-texture.
- Voxel-based predictions fuse information directly in 3D, so all views contribute to the same 3D location. This makes alignment across views simpler and more reliable.
- Adaptive detail:
- Pixel-based methods often predict a fixed number of blobs (one per pixel), wasting detail on empty or simple areas and not giving enough to complex parts (like plant leaves or sharp edges).
- VolSplat adapts the number and placement of blobs to scene complexity—more where detail is needed, fewer where it’s simple.
- Cleaner geometry and fewer artifacts:
- By reasoning in 3D first, VolSplat reduces “floaters” (random dots hanging in space) and jagged edges, especially at object boundaries.
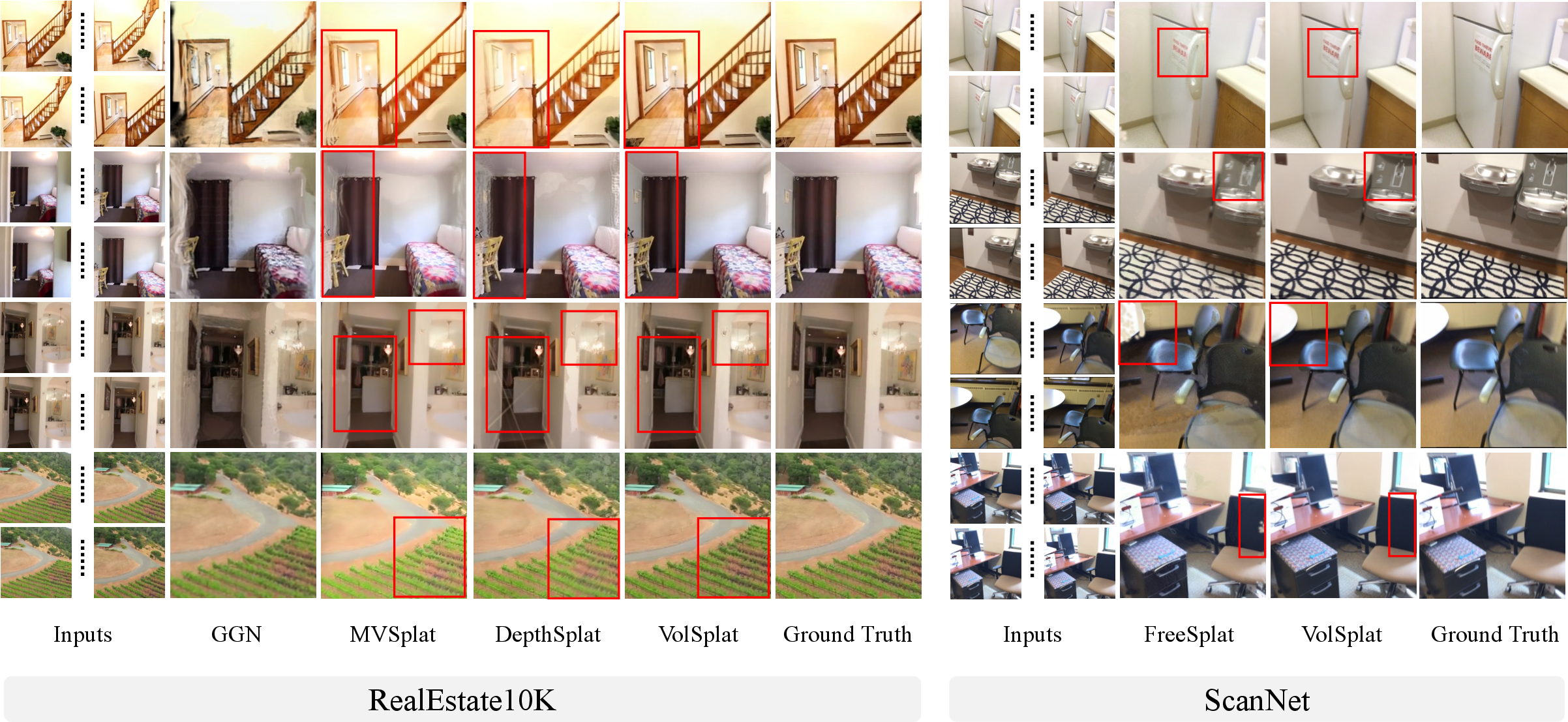
What the experiments show
The authors tested VolSplat on well-known datasets:
- RealEstate10K: indoor/outdoor scenes from real-estate videos.
- ScanNet: indoor 3D scenes.
- They also checked how well it generalizes to a different dataset (ACID) without retraining.
In plain terms, VolSplat:
- Produced sharper images, with fewer visual glitches and more consistent shapes than previous methods.
- Scored better on standard quality measures:
- PSNR (how close the rendered image is to the real one),
- SSIM (how similar the structure looks),
- LPIPS (how similar images feel to a neural network’s perception).
- Held up better when there were fewer input views (a tough situation).
- Generalized better to new data it wasn’t trained on.
Why this matters
- Faster 3D: It’s feed-forward, meaning it can make a 3D scene in one shot without slow, per-scene optimization—useful for real-time apps like robotics, AR/VR, and quick 3D mapping.
- More reliable 3D: Thinking in voxels makes multi-view consistency easier, leading to cleaner 3D reconstructions you can trust.
- Scalable and flexible: Working in a 3D grid makes it easier to add extra 3D hints (like depth maps or point clouds) and to use efficient data structures for speed and memory savings.
Simple glossary of key terms
- Novel view synthesis: Making a picture from a camera angle you didn’t actually capture.
- Occlusion: When one object blocks the view of another.
- Voxel: A small cube in 3D space (like a 3D pixel).
- Gaussian splat: A soft 3D blob used to represent part of a scene; many of these together create a full 3D model.
- Feed-forward: The model produces its output in one pass, instead of slowly improving by iterating many times.
- Cost volume / plane sweeping: Techniques to figure out depth by comparing how parts of images match up at different distances.
Takeaway
VolSplat shows that predicting 3D directly in a voxel grid—rather than from 2D pixels—leads to cleaner, more consistent, and more flexible 3D reconstructions. It adapts detail where needed, works better with few views, and opens the door to faster and more robust 3D scene building in the real world.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of unresolved issues and opportunities for future work identified in the paper.
- Assumption of known, accurate camera poses: VolSplat requires calibrated intrinsics/extrinsics; robustness to pose noise, miscalibration, or fully pose-free inputs (as in recent works) is not evaluated.
- Reliance on predicted depth for lifting features: The voxel construction depends on a depth module (Depth Anything V2 + plane-sweep cost volume); the impact of depth errors on voxel occupancy, Gaussian placement, and rendering quality is not quantified.
- Occlusion and visibility modeling: The voxel feature aggregation uses simple average pooling without explicit visibility weighting, per-view confidence, or occlusion-aware fusion, leaving occlusion handling choices underexplored.
- Voxelization discretization and quantization: Points are assigned to voxels via nearest-integer rounding; the effects of quantization (aliasing, boundary artifacts) and potential alternatives (trilinear splatting, learned aggregation kernels) are not studied.
- Fixed, global voxel size: Only uniform voxel sizes are examined; adaptive/hierarchical voxelization (e.g., octree or scene-dependent LOD) to balance memory, speed, and detail is not implemented or evaluated.
- Gaussian density control is implicit: Density emerges from voxel occupancy, but there is no explicit budget-aware strategy (e.g., target count, error-driven pruning/merging) or quality–complexity trade-off policy.
- Parameterization details unablated: The choice of 18D per-voxel parameters (e.g., SH color order, covariance parameterization) and the offset range hyperparameter r are not justified or ablated for quality vs. stability.
- Multi-view attention scope: Cross-view attention is limited to the two nearest views; the effect of using more (or all) views, different selection criteria, and attention architectures on consistency and performance is not explored.
- Number of input views: Training and evaluation use N=6 views; there is no systematic paper of performance vs. view count (e.g., 1–2 views or many views), nor of failure modes at extreme sparsity or redundancy.
- Scene scale and bounding volume: The method assumes a canonical voxel frame but does not specify automatic scene scaling, bounding box estimation, or robustness to very large/unbounded environments.
- Dataset and resolution scope: Experiments are constrained to 256×256 images and a small set of indoor/outdoor datasets; scaling to high-resolution inputs, large-scale outdoor scenes, and diverse materials (specular/transparent) remains untested.
- Geometry metrics absent: Claims of improved geometric consistency are not supported with 3D metrics (e.g., depth/normal error, mesh quality, point-cloud fidelity) or floaters artifacts measurement.
- Runtime and memory profiling: Aside from a small memory comparison, end-to-end inference speed, throughput, and scalability (with respect to voxel density and scene size) are not reported.
- Streaming and online reconstruction: Applicability to incremental/streaming inputs (e.g., SLAM-like pipelines or FreeSplat-style online updates) and efficient voxel/Gaussian updates over time is not addressed.
- Dynamic scenes: The approach presumes static scenes; handling of non-rigid motion, moving objects, or time-varying appearance is not explored.
- Domain shift and broader generalization: Zero-shot tests are limited to ACID; more rigorous cross-domain evaluations (e.g., urban driving, synthetic benchmarks, varied lighting/photometrics) are needed.
- Integration with external 3D priors: While voxel alignment is amenable to LiDAR/point clouds, no experiments or designs demonstrate fusing external geometry (nor handling misalignment between modalities).
- Loss design: Training uses photometric MSE+LPIPS only; the benefits of auxiliary geometric losses (depth consistency, normal regularization), visibility-aware losses, or uncertainty-aware objectives are not studied.
- Robustness to calibration/exposure differences: Photometric consistency under varying exposure, white balance, or radiometric calibration is not analyzed; potential gains from radiometric normalization remain open.
- Alignment error analysis metrics: The paper asserts reduced alignment-induced errors but does not define or report a quantitative alignment error metric; methodology for measuring multi-view consistency improvements is missing.
- Cost-volume design choices: The number of depth hypotheses, fusion strategy, and sensitivity to wide-baseline geometry are not ablated; trade-offs between cost-volume resolution and compute are unclear.
- Sparse 3D decoder design: The choice of sparse 3D U-Net is motivated but alternatives (octree-based sparse operators, transformer-based 3D decoders, hybrid 2D–3D conditioning) and their efficiency/quality trade-offs are not evaluated.
- Pruning/merging after prediction: Post-prediction Gaussian simplification (e.g., clustering, merging, compression) is not discussed, despite practical importance for downstream rendering speed and storage.
- Uncertainty estimation: The pipeline does not produce uncertainty/confidence per voxel/Gaussian; leveraging uncertainty for adaptive sampling, pruning, or active view selection is unexplored.
- View-dependent appearance: SH-based color may struggle with strong specularities; the method does not investigate enhanced view-dependent models or appearance disentanglement in the feed-forward setting.
Practical Applications
Immediate Applications
These applications can be implemented with existing tooling using the paper’s released code and models, standard 3DGS renderers, and commodity multi-view RGB capture. They leverage VolSplat’s voxel-aligned, feed-forward reconstruction to improve multi-view consistency, reduce floaters, and adapt Gaussian density to scene complexity.
- Fast interior capture and virtual tours
- Sectors: real estate, property management, hospitality
- Tools/products/workflows: smartphone capture (6–10 photos or short video), camera pose estimation (SfM or ARKit/ARCore), VolSplat inference (cloud or workstation GPU), 3DGS tour viewer (Unity/Unreal/Blender plugin)
- Assumptions/dependencies: known or reliably estimated camera intrinsics/extrinsics; sufficient coverage of the space; moderate GPU for inference; privacy/compliance for indoor scanning
- On-set environment reconstruction for film/VFX and game dev
- Sectors: media/entertainment, gaming
- Tools/products/workflows: multi-view set photography → VolSplat → splat assets for previsualization; integration with LightGaussian/FlexGS for compression; rapid iteration in Unreal/Blender
- Assumptions/dependencies: consistent lighting or robust color handling; pose accuracy; higher-resolution capture may require scaling the voxel grid and compute
- Robotics mapping and navigation in indoor environments
- Sectors: robotics (service robots, inspection), logistics
- Tools/products/workflows: ROS2 node wrapping VolSplat; feed-forward map generation from robot-mounted RGB cameras; plug into path planning and semantic perception pipelines
- Assumptions/dependencies: calibrated cameras; sufficient view overlap; static or quasi-static scenes; onboard or edge GPU; dynamic objects may need filtering
- AEC site documentation and facility digital twins
- Sectors: architecture, engineering, construction; facility management; energy
- Tools/products/workflows: periodic site scans (handheld or robot) → VolSplat → splat models aligned to BIM; change detection via difference in Gaussian distributions/density maps
- Assumptions/dependencies: alignment to site coordinate frame; adequate scene coverage; export/interop with BIM tools; safety, consent, and data governance
- E-commerce 3D product listings from sparse photos
- Sectors: retail/e-commerce
- Tools/products/workflows: controlled multi-view product photos → VolSplat → compact splat assets; AR try-on/placement via 3DGS viewers
- Assumptions/dependencies: clean backgrounds and stable poses; small-scale objects may require finer voxel size and more views
- Education and research baselines for 3D reconstruction
- Sectors: academia, education
- Tools/products/workflows: course labs comparing pixel- vs voxel-aligned reconstructions; benchmark experiments on RealEstate10K/ScanNet; integration tests with depth priors and sparse 3D ops
- Assumptions/dependencies: GPU access; familiarity with PyTorch and 3DGS tooling; reproducible camera poses
- Mobile AR measurements and interior planning
- Sectors: consumer apps, interior design
- Tools/products/workflows: quick room scans → VolSplat → metric measurements and layout planning in reconstructed model (distance/area tools)
- Assumptions/dependencies: pose quality; calibration; cloud inference for consumer devices; user consent for indoor data capture
- Insurance and remote inspection for claims/maintenance
- Sectors: finance/insurance, property services
- Tools/products/workflows: claimants submit multi-view photos; VolSplat produces 3D evidence; adjusters review novel views for damage assessment
- Assumptions/dependencies: data authenticity; standardized capture protocols; privacy and regulatory compliance; varying scene complexity handled via adaptive Gaussian density
Long-Term Applications
These applications require further research, scaling, and engineering—such as pose-free inputs, dynamic scenes, on-device acceleration, sensor fusion, and standardization—to unlock broader impact.
- Real-time, on-device feed-forward reconstruction
- Sectors: mobile software, AR/VR
- Tools/products/workflows: VolSplat-lite models optimized with TensorRT/CoreML; sparse voxel ops with mobile-friendly backends; streaming recon on smartphones/AR glasses
- Assumptions/dependencies: efficient model compression (e.g., Zpressor); hardware acceleration; reduced memory footprint; robust pose estimation integrated
- Dynamic scene reconstruction and streaming telepresence
- Sectors: communications, robotics, telemedicine
- Tools/products/workflows: temporal voxel alignment; online updates (FreeSplat-like streaming); dynamic object segmentation and motion modeling
- Assumptions/dependencies: temporal consistency losses; robust handling of occlusions and parallax; low-latency inference; bandwidth-aware asset streaming
- Pose-free or weakly posed capture
- Sectors: consumer apps, crowdsourced mapping
- Tools/products/workflows: integrate SelfSplat/no-pose methods; joint optimization of pose and splats within voxel framework; casual capture by non-experts
- Assumptions/dependencies: reliable pose recovery from sparse views; domain-robust training; failure detection and fallback strategies
- City-scale mapping and crowdsourced digital twins
- Sectors: geospatial, urban planning, smart cities
- Tools/products/workflows: distributed capture (mobile fleets, citizens) → federated voxel-aligned recon → merged splat maps; LOD-aware splat organization (Octree-GS)
- Assumptions/dependencies: multi-session alignment; storage and privacy policy frameworks; standard formats and APIs; sensor diversity and domain shift management
- Sensor fusion: RGB + depth/LiDAR for robust 3D
- Sectors: autonomous driving, drones, industrial inspection
- Tools/products/workflows: fuse depth maps/point clouds into voxel frame; joint refinement with 3D U-Net; confidence-weighted Gaussian prediction
- Assumptions/dependencies: time-synchronized, calibrated sensors; sparse voxel ops at scale; cross-sensor uncertainty modeling
- Semantic 3DGS for robot manipulation and task planning
- Sectors: robotics (manufacturing, home assistants)
- Tools/products/workflows: semantic labels attached to voxels/Gaussians; object-centric splats for grasp planning; integration with detection/tracking modules
- Assumptions/dependencies: labeled training data; multi-task learning; continual updates in changing environments
- Medical endoscopy and minimally invasive 3D reconstruction
- Sectors: healthcare
- Tools/products/workflows: adapt voxel-aligned feed-forward recon to endoscopic RGB streams; occlusion and specular highlight handling; surgical planning and education
- Assumptions/dependencies: domain adaptation to medical imagery; regulatory approval; hardware sterilization and integration; robust performance under challenging optics
- Standardization and policy frameworks for 3DGS assets
- Sectors: policy/regulation, enterprise IT
- Tools/products/workflows: interoperable formats (LOD, compression, metadata); consent and privacy protocols for indoor scans; audit trails for insurance/legal use
- Assumptions/dependencies: multi-stakeholder standards bodies; alignment with geospatial/BIM ecosystems; clear governance for data sharing and retention
- Energy and industrial plant inspection with periodic updates
- Sectors: energy, manufacturing
- Tools/products/workflows: scheduled multi-view scans → voxel-aligned recon → change detection and anomaly flagging; integration with maintenance workflows
- Assumptions/dependencies: safe capture procedures; domain-specific model tuning; harsh lighting/reflective surfaces; OT/IT integration
- Marketplace and content platforms for splat-based assets
- Sectors: software platforms, media
- Tools/products/workflows: creator tools for generating, compressing, and selling splat models; standardized viewers and licensing; search and recommendation based on geometry/appearance
- Assumptions/dependencies: ecosystem adoption of 3DGS; efficient distribution; IP management and rights enforcement
Glossary
- 3D Gaussian Splatting (3DGS): A point-based scene representation that renders images by projecting and blending many 3D Gaussian kernels in space. "Feed-forward 3D Gaussian Splatting (3DGS) has emerged as a highly effective solution for novel view synthesis."
- 3D U-Net: A 3D convolutional encoder–decoder with skip connections used for volumetric feature refinement at multiple scales. "Sparse 3D features are fed into a 3D U-Net for processing, which predicts residual features for each voxel."
- AdamW: An optimizer that decouples weight decay from gradient-based updates, often improving generalization in deep learning. "optimize the model with the AdamW~\cite{loshchilov2017decoupled} optimizer"
- Anisotropic 3D Gaussians: Gaussian kernels whose covariance varies by direction, enabling elongated or oriented shapes in 3D. "represent the 3D scene using a set of anisotropic 3D Gaussians."
- Canonical volumetric coordinate frame: A fixed 3D reference frame used to align volumetric features and geometry across views. "a 3D voxel grid that shares a canonical volumetric coordinate frame with the predicted geometry."
- Camera intrinsics: Parameters defining a camera’s internal geometry (e.g., focal length, principal point) used to map pixels to rays. "is unprojected to a 3D point in the camera coordinate frame using the camera intrinsics."
- Cost volumes: 3D tensors (height × width × depth) encoding per-pixel matching costs across hypothesized depths for multi-view stereo. "Next, we build per-view cost volumes using a plane-sweep strategy~\cite{xu2023unifying}."
- Cross-view attention: An attention mechanism that exchanges information among different camera views to improve multi-view consistency. "These features are then refined with cross-view attention that exchanges information with the two nearest neighboring views."
- Depth ambiguities: Uncertainties in inferring depth from images due to limited viewpoints, low texture, or occlusions. "the resulting 3D predictions can suffer from depth ambiguities"
- Epipolar transformers: Attention modules constrained by epipolar geometry to match features across views efficiently. "pixelSplat~\cite{charatan2024pixelsplat} proposes a two-view feed-forward pipeline that combines epipolar transformers and depth prediction to generate Gaussians."
- Floaters: Spurious, floating artifacts in reconstructed 3D point sets or splats due to mismatches or noise. "Volumetric aggregation reduces floaters and view dependent inconsistency"
- Gaussian primitives: Basic 3D elements parameterized as Gaussians (position, covariance, opacity, color) used to represent scenes. "predicting Gaussian primitives within a 3D voxel grid."
- Learned Perceptual Image Patch Similarity (LPIPS): A learned metric measuring perceptual differences between images based on deep features. "Learned Perceptual Image Patch Similarity (LPIPS)"
- Motion parallax: Apparent motion of scene points relative to the camera due to viewpoint change, used as a depth cue. "struggles in regions affected by occlusion, motion parallax, or low texture."
- Neural Radiance Fields (NeRF): Neural networks that map 3D position and viewing direction to color and density for volumetric rendering. "including Neural Radiance Fields (NeRF)~\cite{mildenhall2021nerf} and 3D Gaussian Splatting (3DGS)~\cite{kerbl20233d}"
- Octrees: Hierarchical spatial data structures that recursively partition 3D space, enabling sparse storage and computation. "sparse structures like octrees were introduced for more efficient storage and computation~\cite{koneputugodage2023octree}."
- Opacity: The transmittance/alpha parameter controlling how much a Gaussian contributes to rendered color along a ray. "These include the offset of the Gaussian center , opacity , covariance , and spherical harmonic color representation ."
- Peak Signal-to-Noise Ratio (PSNR): A pixel-level fidelity metric measuring reconstruction quality relative to ground-truth images. "including pixel-level Peak Signal-to-Noise Ratio (PSNR), patch-level Structural Similarity Index Measure (SSIM),and feature-level Learned Perceptual Image Patch Similarity (LPIPS)."
- Photometric consistency: The principle of enforcing consistent pixel colors across views when projected from a common 3D model. "photometric or geometric consistency"
- Plane-sweep strategy: A multi-view stereo technique that evaluates feature similarity across a set of hypothetical depth planes. "using a plane-sweep strategy~\cite{xu2023unifying}"
- Sparse convolution: Convolutions applied only on occupied voxels in a sparse 3D grid to reduce computation and memory. "a sparse convolutional 3D U-Net~\cite{cciccek20163d} predicts a residual voxel field :"
- Spherical harmonics: Basis functions on the sphere used to represent view-dependent color efficiently in rendering. "spherical harmonic color representation ."
- Structural Similarity Index Measure (SSIM): A patch-level metric assessing perceptual image quality based on luminance, contrast, and structure. "Structural Similarity Index Measure (SSIM)"
- Unprojection: The process of mapping a pixel and its depth back into a 3D point in camera/world coordinates. "First each pixel in image space is unprojected to a 3D point in the camera coordinate frame"
- Voxel-aligned Gaussians: Gaussians predicted and organized with respect to a 3D voxel grid to improve multi-view consistency. "replaces pixel alignment with voxel-aligned Gaussians."
- Voxelization: Discretizing continuous 3D space into a grid of volumetric cells (voxels) for structured processing. "Voxelization, which discretizes 3D space into regular voxel grids, has been a foundational representation in 3D reconstruction and modeling~\cite{meagher1982geometric}."
- Volumetric aggregation: Fusing multi-view evidence in a shared 3D volume before prediction to stabilize geometry and appearance. "Volumetric aggregation reduces floaters and view dependent inconsistency"
Collections
Sign up for free to add this paper to one or more collections.