RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services
Abstract: As a key medium for human interaction and information exchange, social networking services (SNS) pose unique challenges for LLMs: heterogeneous workloads, fast-shifting norms and slang, and multilingual, culturally diverse corpora that induce sharp distribution shift. Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness, especially for smaller models. To address these challenges, we introduce RedOne 2.0, an SNS-oriented LLM trained with a progressive, RL-prioritized post-training paradigm designed for rapid and stable adaptation. The pipeline consist in three stages: (1) Exploratory Learning on curated SNS corpora to establish initial alignment and identify systematic weaknesses; (2) Targeted Fine-Tuning that selectively applies SFT to the diagnosed gaps while mixing a small fraction of general data to mitigate forgetting; and (3) Refinement Learning that re-applies RL with SNS-centric signals to consolidate improvements and harmonize trade-offs across tasks. Across various tasks spanning three categories, our 4B scale model delivers an average improvements about 2.41 over the 7B sub-optimal baseline. Additionally, RedOne 2.0 achieves average performance lift about 8.74 from the base model with less than half the data required by SFT-centric method RedOne, evidencing superior data efficiency and stability at compact scales. Overall, RedOne 2.0 establishes a competitive, cost-effective baseline for domain-specific LLMs in SNS scenario, advancing capability without sacrificing robustness.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a LLM to work well on social media tasks. Social networks change fast: new slang appears, trends come and go, and people post in many languages and styles. A normal, general-purpose LLM can struggle with this. The authors introduce RedOne 2.0, a smarter way to train an LLM so it adapts quickly to social media, stays stable over time, keeps its general knowledge, and needs less training data.
What questions did the researchers ask?
- How can we adapt an LLM to fast-changing social media without making it forget its general skills (like math, coding, and common knowledge)?
- Is there a better training order than the usual “fine-tune first, then reinforce”? In other words, if we start with reinforcement learning (RL), then do targeted fine-tuning, and finish with RL again, will the model be more stable and efficient?
- Can a smaller model (with fewer parameters) trained in this new way match or beat bigger models, using less data?
How did they do it? (Methods explained simply)
Think of training a model like coaching a student athlete for a new sport (social media):
- LLM: A computer program that reads and writes text.
- Post-training: Extra training after the model already knows basic language skills, to make it good at specific jobs.
- Domain: A specific area of use; here, social networking services (SNS).
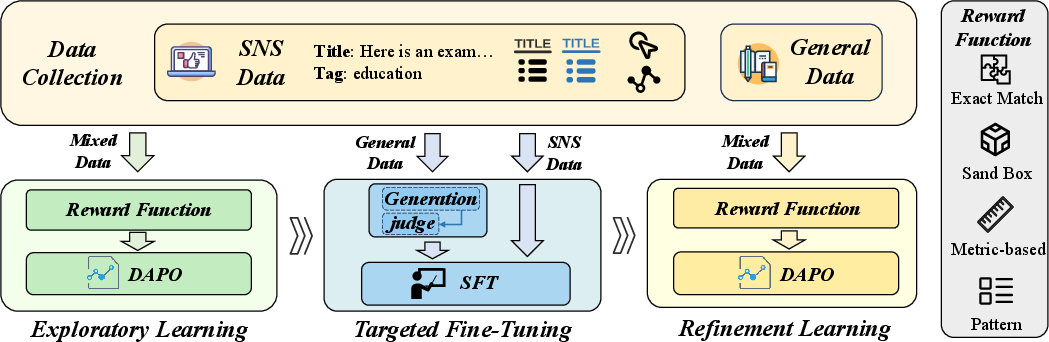
They use a three-stage plan:
- Exploratory Learning (RL-first)
- Analogy: Let the athlete “play lots of games” across many situations to learn the field.
- The model practices on many social media tasks (like picking hashtags, understanding posts, answering questions, and translating slang).
- Reinforcement learning (RL) gives feedback like a coach’s score, not just “right/wrong.” The feedback changes by task:
- Exact answer for multiple-choice (like a quiz).
- Metric-based for open tasks (like translation, where there can be many good answers).
- Run-and-check for code (does the program actually work?).
- Format checks for instruction following (did the model follow the requested structure?).
- A small amount of general data is mixed in so the model doesn’t forget its broader skills.
- Targeted Fine-Tuning (focused practice)
- Analogy: After watching the games, the coach picks the athlete’s weak spots and drills them.
- The team picks the tasks the model struggled with and fine-tunes (standard supervised training) on those.
- To prevent “forgetting,” they also mix a small set of general examples, some with “soft labels.” Soft labels means using the model’s own best answer (reviewed by a judge model) as the target, which is gentler and helps keep the model’s overall style and knowledge.
- Refinement Learning (RL again to polish)
- Analogy: Finish with scrimmages to smooth everything out.
- They do another round of RL on the harder SNS tasks, with more examples that include explanations, to stabilize and balance the model’s behavior across different jobs.
Why this order? Starting with RL helps the model explore and align with social media goals without over-specializing too soon. Targeted fine-tuning then repairs weaknesses. Finishing with RL smooths trade-offs so the model is strong and balanced.
Key ideas explained simply:
- “Seesaw effect”: If you push too hard on niche social tasks with normal fine-tuning, the model can get worse at general tasks (like a seesaw going up on one side and down on the other).
- “Catastrophic forgetting”: The model forgets things it knew before when trained too much on new stuff.
- This three-stage plan reduces both problems.
What did they find, and why is it important?
Main results:
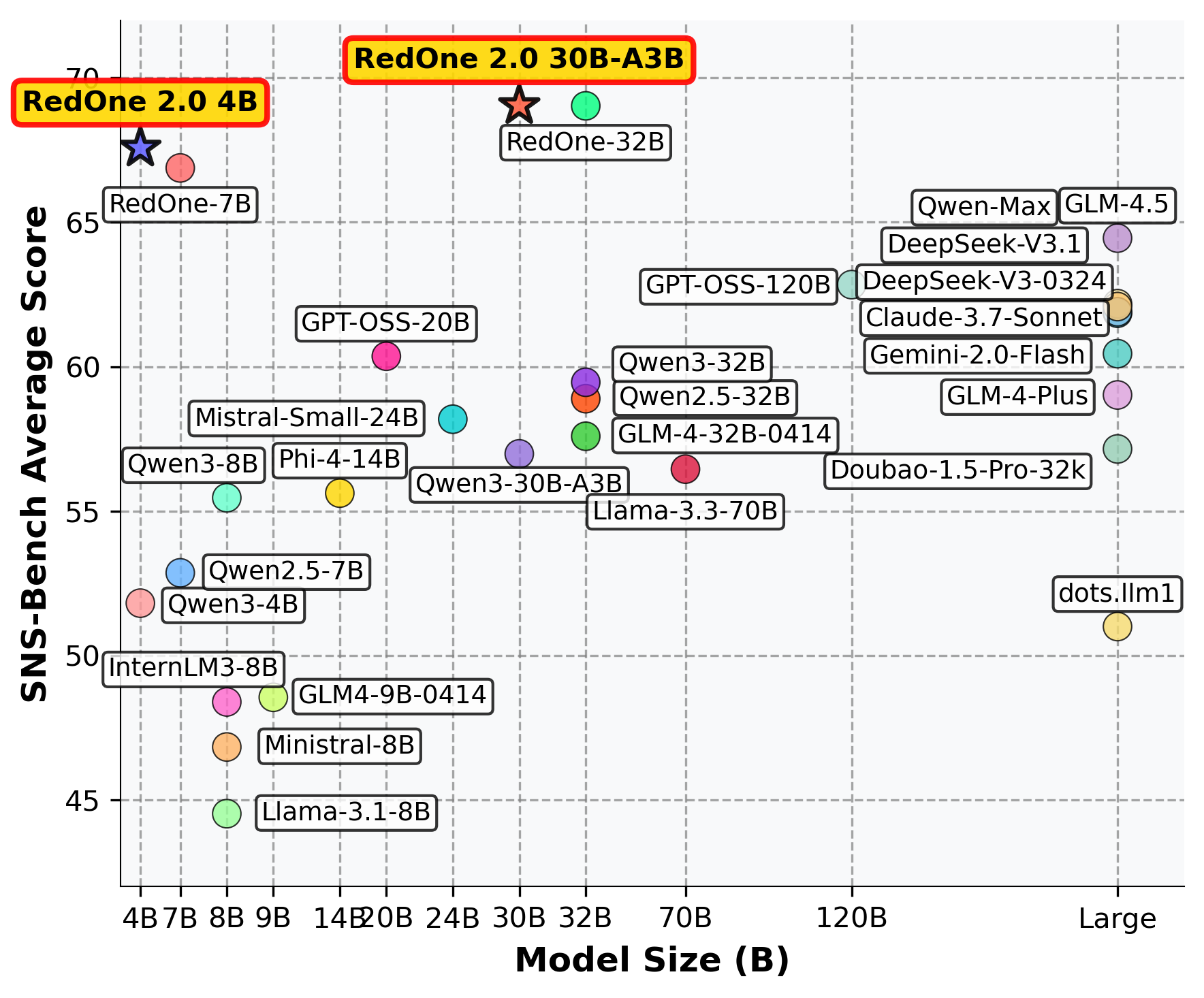
- A small 4B-parameter RedOne 2.0 model beat a larger 7B baseline by about 2.4 points on average across tasks.
- Compared to its original base model, the 4B RedOne 2.0 improved by about 8.7 points while using less than half the data of the earlier SFT-heavy method (RedOne). This shows better data efficiency.
- It performed strongly on both general tests (reasoning, math, coding, translation) and SNS-specific tasks (like categorizing posts, choosing hashtags, reading long posts, extracting entities, and generating search queries).
- It stayed competitive in Chinese–English translation tailored to social media (where emoji, humor, and memes matter).
- The approach scaled well: bigger versions (like ~30B) got even better, and the training recipe worked across different base models.
Real-world test:
- They deployed RedOne 2.0 to help creators rewrite post titles on a large platform.
- Results over millions of posts: advertiser value up ~0.43%; vague titles down ~11.9%; practical titles up ~7.1%; authentic titles up ~12.9%; interactive titles up ~25.8%.
- This suggests better titles that people want to read and interact with.
Why it matters:
- Strong performance with smaller models and less data saves money and energy.
- The model adapts to fast-changing trends without losing general skills.
- It reduces the “seesaw effect” where domain gains hurt general ability.
A known limitation:
- Sometimes the model makes a title more catchy but loses a key fact. So future work should tighten faithfulness while keeping style.
What does this mean for the future?
- For social platforms: Better tools for content understanding, recommendation, moderation, translation, and creator assistance that keep up with new slang and trends, while staying safe and reliable. Smaller, cheaper models can do the job well.
- For AI training: The “RL → targeted SFT → RL” recipe is a promising pattern for any domain that changes quickly, not just social media. It balances learning new skills with remembering old ones, uses data more efficiently, and stabilizes performance across many tasks.
In short, RedOne 2.0 shows a practical, cost-effective way to build domain-ready LLMs that learn fast, stay steady, and perform well both in their specialty and in general.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dataset transparency and reproducibility: The SNS and general-domain datasets, task taxonomies (75+ tasks), sampling strategies, and data preprocessing pipelines are not released or fully specified, hindering independent replication and fair comparison.
- Reward design specifics: The task-to-reward mapping, metric choices (e.g., exact functions for “Eval”, “Match”), weighting across reward types, and handling of noisy/ambiguous labels are not detailed, preventing others from reusing or auditing the reward system.
- Preference/judge model provenance: The “composite quality signal” and judge model used to score candidates for soft labels are not described (architecture, training data, calibration), raising risks of circularity and bias amplification.
- RL constraint feasibility: The DAPO constraint requiring at least one correct and one incorrect sample per batch (“0 < |equivalent| < G”) is under-specified; procedures for when all samples are correct/incorrect (especially as the model improves) are not provided.
- Reward hacking and misspecification: The observed bad case (more engaging but less faithful title) suggests reward misspecification; there is no systematic analysis or mitigation (e.g., faithfulness constraints, multi-objective RL, lexically anchored constraints).
- Safety, policy, and trustworthiness: No evaluation of toxicity, harassment, misinformation, bias/fairness, or policy compliance is provided, despite SNS safety being a primary motivation.
- Continual and rapid adaptation: The pipeline is offline and staged; mechanisms for continual learning, rapid adaptation to emerging slang/norms, and minimizing drift in production are not evaluated (e.g., update cadence, online RL/bandit feedback).
- Multilingual breadth: Evaluation focuses primarily on Chinese–English; coverage of other high-volume SNS languages, code-switching, dialects, transliteration, and emoji/meme semantics in other languages is untested.
- Cultural robustness: Cross-cultural generalization (beyond EN–ZH) and sensitivity (e.g., localized humor, taboos, regional slang) are not examined, though critical for SNS settings.
- OOD generalization rigor: Claims of mitigated “seesaw” are based on mixed-domain evaluation, not explicit OOD stress tests (e.g., temporal shifts, platform shifts, unseen task variants).
- Ablations on reward types: No ablation quantifies the contribution of each reward category (Exact Match, Metrics-based, Pattern, Sandbox) or their mixtures to stability/performance.
- RL algorithm choice: The paper adopts DAPO but does not compare against alternative RL/preference optimization methods (e.g., PPO-variants, IPO/DPO variants, RRHF, GRPO), leaving algorithmic optimality unclear.
- Stage-wise budget allocation: There is no principled analysis of how to allocate data/compute across the three stages (RL–SFT–RL) or how sensitive results are to schedule/ordering.
- Rationales’ role: The rationale proportion (57.18% in the final RL) is changed without a controlled study on when/why rationales help, their source (human vs synthetic), quality, and their inference-time cost.
- Soft-label strategy: Soft-labeled general data are used as a “data-level regularizer,” but there is no analysis of label noise tolerance, calibration, or trade-offs against using a small amount of gold-labeled data.
- Long-context costs: Training/inference with up to ~18k tokens is reported, yet there is no latency, memory, or cost analysis, nor techniques (e.g., retrieval, compression) to keep SNS production costs predictable.
- Compute and energy footprint: Training compute (FLOPs), wall-clock time, hardware profile, and energy/carbon footprint are not provided, limiting assessments of cost-efficiency claims.
- Privacy and compliance: The paper does not discuss privacy-preserving training (e.g., DP, anonymization), user consent, or regulatory compliance for SNS-derived data.
- Fairness across user groups: There is no stratified evaluation (e.g., by demographic attributes, creator cohorts) to check performance disparities or intervention side effects in SNS workflows.
- Online A/B test scope: The production deployment is limited to title re-creation; key details (assignment, confidence intervals, duration per cohort, guardrails) and long-term effects (retention, trust, creator satisfaction) are not reported.
- Feedback loops: Potential feedback-loop risks (e.g., model-generated titles shaping creator behavior and future training data) are not analyzed; countermeasures (debiasing, de-correlation) are absent.
- Cross-platform transfer: Generality beyond a single SNS platform is untested (e.g., transfer to other platforms with different community norms, content formats, or moderation policies).
- Failure taxonomies: While “systematic weaknesses” are diagnosed after stage 1, there is no public taxonomy of failure modes or a methodology to generate actionable diagnostics reusable by others.
- Theoretical underpinnings: The rationale for the RL→SFT→RL ordering is empirical; formal analysis of stability/generalization trade-offs (e.g., via bias–variance or optimization landscapes) is lacking.
- Robustness to contamination: Potential training–evaluation contamination on public benchmarks is not assessed (except for code via LiveCodeBench), weakening the evidence for true generalization gains.
- Safety–engagement trade-offs: The model aims for engagement (e.g., interactive titles) but may drift on factuality or safety; there is no multi-objective framework or Pareto analysis to manage such trade-offs.
- Personalization calibration: Methods to calibrate confidence/uncertainty for personalized outputs (and abstain when unsure) are not explored, despite high stakes in user-facing SNS content.
- Distillation/quantization: No exploration of distilling RL-aligned models to even smaller/cheaper deployment targets (e.g., mobile or edge) while preserving domain gains.
- Governance of reward functions: How to govern updates to reward functions as policies change (auditability, versioning, rollback) is not described, though essential in dynamic SNS environments.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world use cases that can be deployed now, grounded in the paper’s findings and methods. Each item includes sector linkage, potential tools/products/workflows, and feasibility assumptions.
- Creator title optimization and caption rewrites (software, media/advertising)
- Use case: Real-time, personalized re-creation of post titles/captions to improve engagement while preserving intent.
- Tools/products/workflows: “TitleRewrite API” powered by RedOne 2.0; A/B testing buckets; human-in-the-loop review for high-risk content; faithfulness constraints.
- Assumptions/dependencies: Access to creator content streams; guardrail prompts/policies; monitoring to avoid over-optimization that distorts key facts; multilingual support where needed.
- Automated taxonomy and hashtag assignment (software, community operations)
- Use case: Classify posts into platform-specific taxonomies and select context-appropriate hashtags to boost discoverability.
- Tools/products/workflows: “Taxonomy Tagger” and “Hashtag Selector” microservices; pattern-based reward functions to enforce output format; scheduled retraining on fresh SNS corpora.
- Assumptions/dependencies: Up-to-date taxonomies/ontology; periodic refresh with slang/meme drift; language coverage for target markets.
- Query–content correlation for search/recommendations (software, search/recs)
- Use case: Improve note-query alignment to power semantic search, federated recommendations, and better CTR/retention.
- Tools/products/workflows: “QueryCorr Scorer” integrated into retrieval pipelines; metrics-based rewards (e.g., NDCG-like proxies) in RL refinement; offline evaluation harness.
- Assumptions/dependencies: Access to logs for offline labels; privacy-safe aggregation; latency budgets met by compact 4B models.
- Comment highlighting and summarization (software, community operations)
- Use case: Extract salient comment highlights (CHLW) to surface high-quality threads, enable moderation triage, and improve UX.
- Tools/products/workflows: “CommentHighlighter” service; pattern rewards for extraction format; dashboards for ops teams.
- Assumptions/dependencies: Streaming comment access; multilingual entity/phrase extraction; safe handling of sensitive content.
- Multilingual, SNS-style translation (software, localization)
- Use case: Translate posts/comments with SNS-specific pragmatics (emoji/meme semantics, humor localization) for global communities.
- Tools/products/workflows: “SocialTranslate” with task-specific BLEU/chrF++ metrics; curated style/meme lexicons; QA sampling.
- Assumptions/dependencies: Culture-aware reference sets; continuous tuning as trends evolve; policy filters for inappropriate content.
- Moderation and safety compliance assistants (trust & safety, policy)
- Use case: Align content actions with platform policies (harassment/hate, spam, self-harm) while minimizing false positives.
- Tools/products/workflows: RL rewards encoding policy constraints; format-compliant action templates (pattern rewards); uncertainty-based escalation to human reviewers.
- Assumptions/dependencies: Clear, codified policy rules; bias/fairness audits; multilingual safety taxonomies; robust appeal workflows.
- Real-time abuse response and support templating (customer support)
- Use case: Rapid, policy-aligned responses to abuse reports, harassment, and customer support tickets with consistent tone.
- Tools/products/workflows: “ResponseGenerator” with pattern rewards for structure; small 4B model deployment for low latency; template libraries.
- Assumptions/dependencies: Well-defined escalation paths; tone/style guides; ongoing RL refinement with preference signals.
- Data-efficient domain adaptation for smaller platforms (software, startups)
- Use case: Adopt RedOne 2.0’s RL-prioritized three-stage pipeline to adapt compact models (e.g., 4B) with limited domain data.
- Tools/products/workflows: DAPO-based training scripts; reward design library (Exact Match, Metrics-based, Sandbox, Pattern); soft-label regularization with judge models.
- Assumptions/dependencies: Modest compute budgets; curated SNS dataset slices; basic ML ops (evaluation harness, capability maps).
- Academic replication and benchmarking (academia)
- Use case: Study “seesaw” mitigation between in-distribution gains and out-of-distribution robustness in domain-specific post-training.
- Tools/products/workflows: Open base models (e.g., Qwen3 family); staged training configs; SNS-Bench and SNS-TransBench evaluation.
- Assumptions/dependencies: Accessible datasets or suitable proxies; reproducible RL preference pipelines; ethical data use approvals.
- Capability mapping and training prioritization (software, ML ops)
- Use case: Use Exploratory Learning diagnostics to map failure buckets and prioritize targeted fine-tuning cycles.
- Tools/products/workflows: “Capability Map Dashboard”; auto-stratified sampling; rationale-heavy data curation to preserve reasoning.
- Assumptions/dependencies: Comprehensive evaluation suite; telemetry for drift detection; incremental training infrastructure.
Long-Term Applications
The following applications are feasible with further research, scaling, or development, building on the paper’s innovations in RL-prioritized post-training, reward design, and data efficiency.
- Continual RL alignment from online signals (software, ops)
- Vision: Update models using implicit feedback (engagement, satisfaction) while avoiding clickbait and feedback loops.
- Tools/products/workflows: Off-policy learning with causal corrections; counterfactual evaluation; guardrails for trust & safety.
- Assumptions/dependencies: Robust causal inference pipelines; bias/fairness controls; governance for optimization objectives.
- Multimodal SNS LLMs (media, software)
- Vision: Extend to images/video/audio for creator assistance, moderation (e.g., OCR + meme detection), and cross-modal search.
- Tools/products/workflows: Multimodal rewards (sandbox for code-like tool use; metrics for caption accuracy/style); unified training with diverse data.
- Assumptions/dependencies: Large-scale multimodal corpora; higher compute budgets; reliable annotation of visual/aural phenomena.
- Cross-platform domain LLM hub (platform engineering)
- Vision: A unified model with plug-in reward modules for different SNS tasks (moderation, ranking, creator tools), reusing capability maps.
- Tools/products/workflows: Modular reward SDK; dynamic task sampling; per-task performance SLAs; shared infrastructure for A/B testing.
- Assumptions/dependencies: Standardized interfaces across product teams; monitoring for interference between tasks.
- Privacy-preserving on-device personalization (mobile, privacy)
- Vision: Deploy compressed 4B variants on devices to personalize content creation, translation, and moderation hints locally.
- Tools/products/workflows: Distillation/quantization; federated RL/SFT; on-device evaluation; privacy-preserving telemetry.
- Assumptions/dependencies: Efficient inference on commodity hardware; secure FL infrastructure; energy/latency constraints.
- Policy encoding and auditability (policy, compliance)
- Vision: A policy DSL for reward functions, with audit logs that trace content actions to explicit policy clauses.
- Tools/products/workflows: Compliance-aware reward compilers; audit dashboards; automatic policy diff-based retraining.
- Assumptions/dependencies: Cross-industry policy standards; regulator buy-in; reliable audit trails.
- Misinformation and factuality resilience (policy, media)
- Vision: RL signals from external fact-checkers, knowledge bases, and sandboxed verification tasks to reduce hallucinations and misinformation spread.
- Tools/products/workflows: Fact-check reward pipelines; retrieval-augmented generation; escalation for contested claims.
- Assumptions/dependencies: High-quality fact sources; scalable verification; clear policies on contentious topics.
- Creator co-pilot suites (media, e-commerce)
- Vision: Integrated assistants for titles, thumbnails, tags, scripts, pacing, and localization with guardrails for authenticity and trust.
- Tools/products/workflows: Multi-tool agent workflows; iterative A/B testing automation; explainability for suggestions.
- Assumptions/dependencies: Tool-use capabilities; connectors to creative suites; user preference modeling and consent.
- Sector adaptations beyond SNS (healthcare, education, finance)
- Vision: Apply the pipeline to domain-specific social interactions (patient forums, classroom discussions, investor communities).
- Tools/products/workflows: Domain reward libraries (e.g., safety/ethics in healthcare, accuracy in finance); targeted datasets; human oversight.
- Assumptions/dependencies: Domain-specific corpora; strict safety/regulatory compliance; subject-matter expert involvement.
- Fairness-aware engagement optimization (policy, trust & safety)
- Vision: Incorporate fairness constraints into RL to ensure title optimization and recommendation don’t disproportionately harm groups.
- Tools/products/workflows: Constraint-aware RL; fairness metrics/monitoring; counterfactual audits.
- Assumptions/dependencies: Agreed fairness definitions; demographic/context signals handled ethically; regular external audits.
- Collaborative academic testbeds for distribution shift (academia, industry)
- Vision: Shared benchmarks and anonymized datasets to study rapid slang/trend drift and robust domain adaptation.
- Tools/products/workflows: Open evaluation harnesses; drift simulators; staged RL/SFT recipe repositories.
- Assumptions/dependencies: Data-sharing agreements; privacy-preserving transformations; funding and governance for sustained collaboration.
Glossary
- AdamW: A variant of the Adam optimizer with decoupled weight decay that improves generalization in deep learning. "Optimization employed AdamW with a constant learning rate of "
- AIME 2025: A contemporary set of high-difficulty math competition problems used for evaluating mathematical reasoning in LLMs. "and the high-stakes AIME 2025~\cite{aime25} set"
- BBH: Big-Bench Hard, a challenging suite of reasoning tasks to probe LLM robustness. "BBH~\cite{bbh}"
- BLEU: A machine translation metric that measures n-gram overlap between candidate and reference translations. "maintains competitive results across BLEU and chrF++ metrics."
- C-Eval: A Chinese comprehensive evaluation benchmark covering diverse academic subjects. "C-Eval~\cite{ceval}"
- Catastrophic forgetting: The loss of previously learned capabilities when a model is fine-tuned on new data. "more susceptible to catastrophic forgetting as new domain patterns overwrite previously learned skills."
- chrF++: A character n-gram F-score metric for machine translation, sensitive to morphology and spelling. "maintains competitive results across BLEU and chrF++ metrics."
- CMMLU: Chinese Massive Multi-task Language Understanding benchmark for broad knowledge and reasoning. "CMMLU~\cite{li2023cmmlu}"
- CompassBench: A comprehensive benchmark providing integrated, multi-dimensional evaluation of LLMs. "as well as CompassBench~\cite{2023opencompass}, a comprehensive bench to provide an integrated, multi-dimensional view of model performance."
- Cosine scheduling: A learning rate schedule that decays following a cosine curve to stabilize training. "applying a warmup ratio of 0.1 followed by cosine scheduling."
- DAPO: Direct Advantage Preference Optimization, a reinforcement learning framework that optimizes policies using advantage-normalized preference signals with clipping. "DAPO-based~\cite{yu2025dapo} RL training for this stage."
- DPO: Direct Preference Optimization, a method that simplifies preference learning by directly optimizing preference scores. "DPO~\cite{rafailov2023direct}"
- Distribution shift: A change between training and deployment data distributions that degrades model performance. "strong robustness under distribution shift"
- Exact Match: A binary scoring criterion that awards points only if the model’s answer exactly matches the reference. "1) Exact Match. For close-ended problems with determinate answers"
- Exploratory Learning: The initial stage that broadly exposes the model to domain data to align and diagnose weaknesses. "1) Exploratory Learning. The model is exposed to curated SNS corpora to establish initial domain alignment and to diagnose the lack of ability for realistic distributions."
- FLORES: A multilingual dataset designed to evaluate machine translation across many languages. "FLORES~\cite{flores}"
- GPQA-Diamond: A high-difficulty subset of GPQA for probing advanced factual and reasoning skills. "GPQA-Diamond~\cite{rein2024gpqa}"
- GRPO: A reinforcement learning method (e.g., Group Relative Preference Optimization) designed for efficient reward-driven optimization. "GRPO~\cite{shao2024deepseekmath} and DAPO~\cite{yu2025dapo} introduce more efficient, reward-driven reinforcement learning frameworks"
- GSM8K: A benchmark of grade-school math word problems testing multi-step reasoning. "GSM8K~\cite{gsm8k}"
- HaluEval: A benchmark assessing hallucination tendencies in LLM-generated content. "HaluEval~\cite{halueval}"
- HumanEval: A code generation benchmark where solutions are executed to validate correctness. "HumanEval~\cite{HumanEval}"
- IFEval: An instruction-following benchmark with automatically verifiable constraints. "We employ IFEval~\cite{ifeval}, which provides automatically verifiable constraints to quantify compliance under explicit instructions."
- In-distribution (ID): Tasks drawn from the same distribution as the training data where models typically perform best. "in-distribution (ID) tasks"
- Instruction-tuned backbones: Base models further fine-tuned on instruction-response pairs to improve following and alignment. "they are both based on instruction-tuned backbones"
- LiveCodeBench: A contamination-aware, temporally refreshed code benchmark emphasizing execution-based scoring. "LiveCodeBench~\cite{jain2024livecodebench}, reporting pass@k and execution-based metrics."
- MBPP: Mostly Basic Programming Problems, a code synthesis benchmark with short problems. "MBPP~\cite{mbpp}"
- MMLU: Massive Multi-task Language Understanding benchmark covering many academic disciplines. "MMLU~\cite{mmlu}"
- MMLU-Pro: A harder variant of MMLU focusing on more challenging and robust evaluation. "MMLU-Pro~\cite{mmlupro}"
- Note-CHLW (CHLW): An SNS-Bench task to highlight salient words in comment threads. "7) Note-CHLW (CHLW) to highlight salient words in comment threads;"
- Note-Gender (Gender): An SNS-Bench task evaluating gender-sensitive appeal in content. "6) Note-Gender (Gender) to assess gender-sensitive appeal;"
- Note-Hashtag (Hash.): An SNS-Bench task selecting suitable hashtags for social posts. "2) Note-Hashtag (Hash.) to select suitable tags;"
- Note-MRC (MRC): An SNS-Bench machine reading comprehension task over long social notes. "4) Note-MRC (MRC) for simple and complex reading comprehension over long notes;"
- Note-NER (NER): An SNS-Bench named entity recognition task tailored to social content. "5) Note-NER (NER) for entity extraction;"
- Note-QueryCorr (QCorr): An SNS-Bench task aligning user queries with note content and topics. "3) Note-QueryCorr (QCorr) to align user queries with note content and topic;"
- Note-QueryGen (QGen): An SNS-Bench task generating effective search queries for social content. "8) Note-QueryGen (QGen) to produce effective search queries."
- Note-Taxonomy (Taxon.): An SNS-Bench content categorization task for social posts. "1) Note-Taxonomy (Taxon.) for content categorization;"
- Out-of-distribution (OOD): Tasks drawn from distributions different from training data, typically challenging for generalization. "out-of-distribution (OOD) generalization."
- Overlong buffer: An extra token allowance with penalty used to handle overly long sequences in RL rollouts. "plus a 4,096-token overlong buffer with 1.0 penalty factor."
- Pass@k: A code metric indicating the probability that at least one of k attempts passes all tests. "reporting pass@k and execution-based metrics."
- Pattern-based matching mechanism: A formatting compliance check that rewards outputs matching specified structural patterns. "we design a pattern-based matching mechanism that emphasizes adherence to specified formats rather than the semantic content itself."
- Policy model: The parameterized decision function in RL that maps inputs to action distributions. "from the old policy model $\pi_{\theta_{\mathrm{old}}$"
- Preference alignment: Aligning model outputs with human or task preferences via feedback-driven optimization. "its practical value has been demonstrated across preference alignment, safety shaping, controllable generation and task-level policy tuning"
- Preference optimization: Training methods that optimize models directly against preference signals instead of explicit labels. "then apply preference optimization with human or automated feedback"
- Refinement Learning: The final stage that applies RL to consolidate improvements and balance trade-offs. "3) Refinement Learning. Building on the corrected model, we reuse RL with SNS-centric signals to consolidate improvements"
- Reinforcement learning (RL): An optimization paradigm using reward signals to align behavior with objectives. "reinforcement learning (RL) offers a more distinctive advantage for domain specific post-training"
- Reward function: The scalar scoring rule that evaluates model outputs and guides RL optimization. "In RL, the reward function is the most critical supervision signal during training."
- RRHF: Rank Responses with Human Feedback, a method for preference learning via ranking. "RRHF~\cite{yuan2023rrhf}"
- Sandbox simulation: Executing generated code/solutions in a controlled environment to evaluate correctness. "The most direct approach is sandbox simulation"
- Sequence packing: Combining multiple shorter sequences into one training sequence to improve efficiency. "maximum sequence length of 16,384 using sequence packing."
- SNS-Bench: A large-scale benchmark of real SNS tasks covering comprehension, retrieval, sentiment/intent, and recommendation. "We use SNS-Bench~\cite{sns-bench}, a large-scale bench with 6,658 questions spanning eight tasks from a social platform with over 300M users"
- SNS-TransBench: An SNS-focused translation benchmark emphasizing pragmatics, style, and culture-specific phenomena. "we adopt SNS-TransBench~\cite{redtrans-bench}, a curated set of 2,858 EnglishâChinese cases from posts, comments, and multimedia captions"
- Supervised fine-tuning (SFT): Gradient-based training on labeled instruction-response pairs to specialize model behavior. "Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness"
- Targeted Fine-Tuning: The second stage that applies SFT to specific weaknesses, blending some general data to mitigate forgetting. "2) Targeted Fine-Tuning. We apply SFT on tasks where previous stage diagnostics reveal systematic weaknesses"
- Warmup ratio: The fraction of training steps used to linearly ramp up the learning rate before the main schedule. "applying a warmup ratio of 0.1 followed by cosine scheduling."
Collections
Sign up for free to add this paper to one or more collections.