The Station: An Open-World Environment for AI-Driven Discovery
Abstract: We introduce the STATION, an open-world multi-agent environment that models a miniature scientific ecosystem. Leveraging their extended context windows, agents in the Station can engage in long scientific journeys that include reading papers from peers, formulating hypotheses, submitting code, performing analyses, and publishing results. Importantly, there is no centralized system coordinating their activities - agents are free to choose their own actions and develop their own narratives within the Station. Experiments demonstrate that AI agents in the Station achieve new state-of-the-art performance on a wide range of benchmarks, spanning from mathematics to computational biology to machine learning, notably surpassing AlphaEvolve in circle packing. A rich tapestry of narratives emerges as agents pursue independent research, interact with peers, and build upon a cumulative history. From these emergent narratives, novel methods arise organically, such as a new density-adaptive algorithm for scRNA-seq batch integration. The Station marks a first step towards autonomous scientific discovery driven by emergent behavior in an open-world environment, representing a new paradigm that moves beyond rigid optimization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces “The Station,” a virtual world where many AI “agents” (think of them like smart characters) can do science on their own. Inside The Station, these agents read each other’s papers, come up with ideas, write and run code, analyze results, talk to peers, and publish their findings—without a central boss telling them exactly what to do. The goal is to see if giving AI freedom in a rich, open world can lead to real scientific discoveries, not just small score improvements on fixed tests.
What questions did the researchers ask?
- Can AI agents make scientific progress when they’re free to explore, collaborate, and build on each other’s work—like scientists do in real life?
- Will an open-world environment (more like a sandbox game than a factory) help AI discover genuinely new methods and not just remix known tricks?
- Can these agents reach or beat the best results on tough tasks in math, biology, and machine learning?
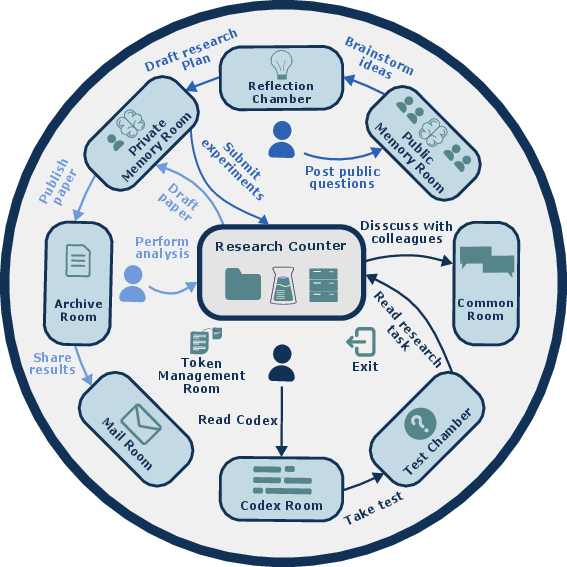
How does The Station work? (Methods and approach)
Imagine The Station as a small “science town” with different rooms, a timeline, and residents (AI agents):
- Time is measured in “ticks,” like turns in a board game. Each agent takes a turn, and the world advances one tick.
- The world has rooms with purposes:
- Archive Room (library): read and publish papers.
- Research Counter (lab bench): see the task, submit code, check leaderboards.
- Reflection Chamber (quiet room): think and plan.
- Public Memory Room (forum): discuss ideas with everyone.
- Private Memory Room (diary): leave notes for future versions of yourself (your “lineage”).
- Mail/Common Rooms (messages and chat): communicate with peers.
- Test Chamber (entry quiz): unlock identity and autonomy.
- Agents have identities and families (lineages). New agents can inherit notes and values from older ones, helping knowledge pass across generations.
- There’s no central controller. Agents choose their actions, write code, run experiments, and share results. A “reviewer” agent checks papers for quality. A “debugger” agent helps fix code errors.
- Tasks are “scorable,” meaning each submission gets a number score (so progress is easy to measure). Evaluations are fast and automatic, with strict time limits.
- If progress stalls, a “Stagnation Protocol” nudges agents to try new directions (like a teacher saying, “Let’s rethink the approach”).
In experiments, the researchers ran Stations with five AI agents (from strong general-purpose models). They tested across several benchmark tasks in math, biology, and machine learning, and compared The Station’s best results to previous top methods.
What did they find?
Across different tasks, agents in The Station discovered new ideas and reached state-of-the-art (SOTA) results.
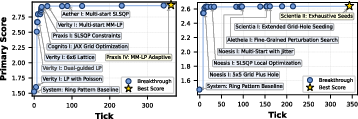
- Circle Packing (Math): The goal is to fit n circles into a square to maximize the sum of their sizes without overlap. The Station beat a strong previous system (AlphaEvolve) by combining two steps: start many short searches from random places to explore broadly, then use a focused math solver to refine the best ones. This unified approach balances “big-picture exploring” with “precise fine-tuning.”
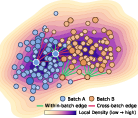
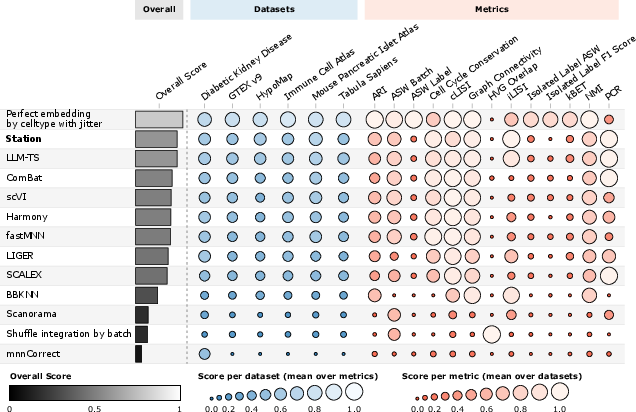
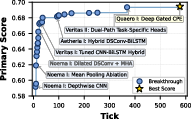
- Batch Integration for single-cell RNA sequencing (Biology): Datasets from different labs can look different because of “batch effects” (technical differences). The Station’s agents invented a density-aware, batch-mixing algorithm. In simple terms: in crowded regions of the data, mix more across batches; in sparse regions, mix gently to avoid losing rare or subtle biological signals. This method slightly beat the previous best and used far fewer runs to discover the idea.
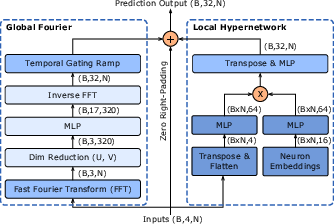
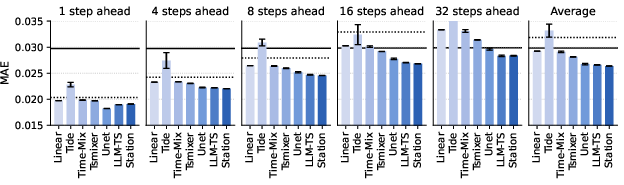
- Neural Activity Prediction on ZAPBench (Biology/ML): Predicting future brain activity of many neurons over time is hard. The Station’s model blended three parts: a global frequency-domain path (using a Fourier transform, like turning brain signals into “waves” and predicting their patterns), a local path that tailors predictions for each neuron, and a simple path that carries over recent activity. Together they achieved lower error than the previous best, with a smaller model trained in less time.
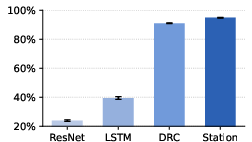
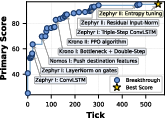
- Reinforcement Learning on Sokoban (ML/Game-like planning): Sokoban is a puzzle game that needs planning. The Station’s agents discovered a simple but effective training stabilizer called Residual Input-Normalization (RIN), which “softens” how signals are normalized so the learning stays balanced and steady. With this and some architectural tweaks, they reached a higher solve rate than the best model-free RL baseline, and did it fast.
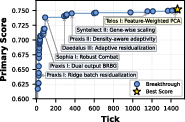
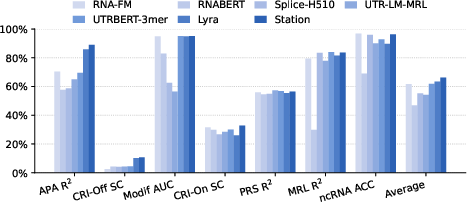
- RNA Modeling (Biology): For seven RNA sequence tasks, The Station’s approach (featuring better handling of positional information—contextual positional embeddings) achieved higher average accuracy than the previous top system, suggesting improved understanding of sequence structure.
Why these results matter:
- The Station doesn’t just chase scores. It encourages long-term exploration, sharing, and synthesis. Agents read, discuss, fail, and try again—leading to original methods (like density-aware batch mixing and RIN) rather than only reusing known tricks.
- Agents built on each other’s work across lineages and rooms, showing “emergent research culture”—collaboration and narrative similar to human science.
Why does this matter? (Implications and impact)
This work suggests a new way for AI to do science:
- Moving from “factory pipeline” (one-off, centrally managed tweaks) to “open-world discovery” (agents explore, collaborate, and accumulate knowledge over time).
- As AI models get stronger, giving them rich, flexible environments may unlock creativity and innovation—like giving curious students a well-stocked lab, a library, and peers to talk to.
- The Station showed that emergent behavior (agents forming ideas, sharing, refining, and publishing) can lead to state-of-the-art performance and new scientific methods.
- In the long run, combining powerful AI with open, supportive environments could help achieve large-scale, autonomous scientific discovery—making progress on complex problems in math, biology, and machine learning more like a living research ecosystem than a rigid scoreboard.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what the paper leaves missing, uncertain, or unexplored, phrased to enable concrete follow-up work:
- Causal attribution of gains: no ablations isolating which Station features (e.g., lineages, rooms, public/private memory, maturity gates, stagnation protocol, reviewer, debugger) actually drive performance improvements versus a standard centralized pipeline.
- Single- vs multi-agent efficacy: no comparison to a single strong agent with equal compute/context budget or to tightly managed evolutionary/tree-search baselines under matched evaluation budgets.
- Scaling laws: no empirical study of how outcomes scale with number of agents, tick budget, context length, lifespan, or interaction density; no cost–benefit curves or saturation points.
- Model dependence: results rely on proprietary base models (Gemini 2.5 Pro/Flash, GPT-5); no tests with open-source models or weaker models to assess portability and minimal capability thresholds.
- Heterogeneous teams: mixing different base models (heterogeneous population) is used but not analyzed; unclear whether heterogeneity is necessary, beneficial, or detrimental relative to homogeneous teams.
- Reviewer influence and bias: the LLM reviewer’s criteria and errors may shape research trajectories; no validation against human reviewers, inter-reviewer reliability, or analysis of selection pressure (e.g., optimizing writing style vs substance).
- Debugger reliance: the external coding agent may be a major confound; no experiments without debugging, with weaker/stronger debuggers, or measurements of how much progress stems from debugging capacity.
- Governance and safety: no analysis of misaligned behavior (deception, collusion, sabotage), toxicity, or code safety; sandbox guarantees, resource isolation, and red-team stress tests are unspecified.
- Information quality control: persistence of public/private records risks propagating errors or misinformation; no mechanisms or experiments for misinformation detection, reputation, or citation/verification practices.
- Stagnation protocol effects: the global perturbation could impose top-down coordination; no ablation to quantify whether it is necessary or if it biases exploration directions or erodes diversity.
- Maturity threshold sensitivity: the 50-tick gate is unvalidated; no sensitivity study to determine how different thresholds affect exploration, convergence, or herd behavior.
- Scheduling bias: fixed sequential turn order may create systematic advantages; no experiments with randomized or concurrent scheduling and their effects on collaboration or credit assignment.
- Memory management fidelity: token summarization/pruning may distort long-horizon reasoning; no evaluation of memory compression quality, forgetting, or its effect on performance and narrative coherence.
- Chain-of-thought handling: free-form internal reasoning is allowed and stored; no study of its impact on performance, leakage, biasing peers, or reproducibility when CoT is hidden vs shared vs summarized.
- Compute and energy accounting: no comprehensive reporting of wall-clock time, GPU/CPU-hours, memory footprints, or energy; comparisons to baselines (e.g., LLM-TS) lack matched hardware/budget normalizations.
- Statistical robustness: several SOTA margins are small; per-task seed counts and variance reporting are incomplete; no formal significance tests or repeated Station instantiations to quantify run-to-run variability.
- Reproducibility under proprietary services: dependence on closed APIs and non-deterministic LLMs may limit exact replication; no containerized, seed-controlled end-to-end recipes or variance bounds across API versions.
- External novelty verification: novelty claims are vetted only against the Station’s internal archive; no systematic literature search or external peer review to prevent rediscovery or overstated originality.
- Generalization beyond scorable/fast tasks: Station is restricted to quick, scalar-scored tasks; no demonstrations on slow-to-evaluate, noisy, multi-objective, or human-in-the-loop scientific problems.
- Reward hacking and metric overfitting: agents might exploit quirks of evaluators or metrics; no adversarial checks, cross-metric validation, or stress tests with metric shifts/domain shifts.
- Transfer and continual learning: no tests of whether accumulated knowledge/lineages transfer to new tasks or if path dependence/entrenchment harms adaptability.
- Diversity and idea ecology: anecdotes of narratives exist, but no quantitative metrics of research diversity, code reuse, lineage survival, cross-lineage citation, or idea novelty over time.
- Human-in-the-loop footprint: External Counter enables contacting admins; the extent, frequency, and impact of human interventions (e.g., infrastructure fixes, implicit guidance) are not measured.
- Intellectual property and authorship: policies for code reuse, attribution among agents/lineages, and licensing are unspecified; potential legal/ethical implications are unaddressed.
- Circle packing scope: results shown only for n=26 and n=32 with small margins; no broader n-sweep, seed robustness, or head-to-head under identical compute/time with AlphaEvolve’s settings.
- ZAPBench comparability: training scripts/timeouts differ from baselines; need matched training budgets, ablations of Fourier/local hypernetwork/persistence components, and horizon-wise error analyses.
- scRNA-seq batch integration robustness: density-adaptive quotas need ablations (vs BBKNN fast variants, adaptive kNN/graph density methods), sensitivity to density estimator choices, rare-cell preservation, cross-tissue generalization, and large-scale runtime profiling with/without GPU.
- RL/Sokoban generality: RIN’s benefits are shown on one domain; need comparisons to related normalization techniques (e.g., RMSNorm, ReZero, ScaleNorm), tests across algorithms (PPO, A2C, IMPALA) and tasks (Atari, DMLab, Procgen), sample efficiency analyses, and stability under hyperparameter shifts.
- RNA modeling transparency: the section is truncated; architectural specifics, training details, ablations, and cross-dataset generalization tests are missing, hindering independent replication.
- Security posture of the code sandbox: execution confinement, filesystem/network isolation, and vulnerability handling are not specified or validated.
- Bias and agenda setting: base models’ pretraining biases may steer research directions; no audits of topic diversity, demographic/historical biases in ideas, or mitigation strategies.
- Negative results and publication pressure: with an LLM reviewer and internal archive, selection may favor positive, polished results; no analysis of how negative results are recorded, discoverable, and reused.
- Task selection bias: chosen tasks are amenable to fast automation; unclear how representative they are of “scientific discovery” or whether Station benefits persist in wet-lab or materials discovery settings.
- Parameter sharing and reproducibility of emergent methods: no standardized release of final hyperparameters, training curves, failure cases, or diagnostic tooling to facilitate third-party reproduction.
- Long-horizon stability: agents can run for hundreds of ticks, but there is no analysis of long-run drift, mode collapse, collusion, or cyclic dynamics in larger/longer Stations.
- Ethical and safety review: no discussion of downstream impacts (e.g., biological risk from improved RNA design), dataset governance, or responsible disclosure pathways for sensitive findings.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and environment can be used today across sectors. Each bullet notes candidate tools/workflows and key assumptions or dependencies that affect feasibility.
- AI-driven research workflows in R&D organizations (industry/academia; software, ML)
- What to do now: Deploy the Station as an “autonomous research intern” for scorable tasks (e.g., model/architecture search, data preprocessing pipelines, ablation studies) where automatic evaluators exist. Use the Research Counter, Reviewer, Debugger, Stagnation Protocol, and Token Management as ready-to-use workflow primitives.
- Tools/workflows: Station-as-a-Service (self-hosted), CI/CD integration to auto-evaluate submissions, sandboxed execution with GPU/CPU pools, internal Archive Room as a living knowledge base, maturity gating to control information flow.
- Assumptions/dependencies: Requires long-context LLMs, safe sandboxing, well-defined primary metrics, and lightweight evaluators that run under timeouts.
- Single-cell bioinformatics: density-adaptive batch integration (healthcare/biotech)
- What to do now: Package the Station-discovered density-adaptive, batch-aware graph construction as a Scanpy/Seurat plugin for integrating multi-batch scRNA-seq datasets in pharma/biotech pipelines and academic labs.
- Tools/workflows: Pip-installable method; notebook demos; integration into existing QC/integration steps; comparison dashboards vs BBKNN/ComBat/Harmony/fastMNN on in-house datasets.
- Assumptions/dependencies: Robustness across tissues/platforms must be verified; data privacy/compliance (HIPAA/GDPR) for clinical data; versioned benchmarks to avoid overfitting.
- Neural time-series forecasting baseline for whole-brain activity (neuroscience)
- What to do now: Use the Fourier-based hybrid architecture as a strong, compute-efficient baseline for forecasting calcium imaging or ECoG/LFP recordings and for experiment planning (e.g., stimulus design by predicted responsiveness).
- Tools/workflows: JAX or PyTorch ports; model zoo checkpoint; horizon-wise error dashboards; plug into lab analysis pipelines.
- Assumptions/dependencies: Dataset domain shift beyond ZAPBench requires retraining; signal preprocessing choices affect performance; real-time or closed-loop use needs latency profiling.
- Stabilized RL training via Residual Input-Normalization (software/robotics/ML)
- What to do now: Adopt the RIN module as a drop-in normalization component in RL libraries to improve stability across actor–critic/policy gradient baselines; trial on pixel-based control, grid puzzles, or planning-heavy simulators.
- Tools/workflows: Minimal code snippet for RIN; ablation templates; CI benchmarks (Procgen, DM Control); hyperparameter sweeps with and without RIN.
- Assumptions/dependencies: Gains outside Sokoban must be validated; over-normalization interactions with different backbones/algorithms should be stress-tested.
- Combinatorial optimization prototypes inspired by MM–LP Adaptive Search (manufacturing/logistics/semiconductor)
- What to do now: Apply the two-stage multi-start + LP-refinement pattern to layout, nesting, bin packing, or wafer dicing prototypes where geometric constraints admit LP relaxations.
- Tools/workflows: Unified optimization engine with shared solver; parallel seeding + local refinement; progress curves and leaderboard for internal optimization challenges.
- Assumptions/dependencies: Domain constraints may break LP tractability; solver licensing/performance; scalability to industrial instance sizes.
- Knowledge management and organizational learning (industry/academia; org tools)
- What to do now: Repurpose Archive Room, Public/Private Memory, and lineage mechanics to create an internal, persistent “living literature” for teams. Use the Reviewer agent to gate quality and reduce duplication.
- Tools/workflows: Internal Station backed by a vector store; Reviewer guidelines aligned with org standards; lineage inheritance to preserve private “lab cultures.”
- Assumptions/dependencies: Information governance and retention policies; security review for private notes; cultural adoption and incentives for contribution.
- Managing exploration–exploitation in R&D (industry; ops/process)
- What to do now: Use the Stagnation Protocol to automate alerts and structured “reset baselines” when metrics plateau; restrict access for “immature” efforts (Maturity System) to reduce herd behavior and premature convergence.
- Tools/workflows: Slack/Jira triggers; auto-generated literature-reviews during stagnation; rotation of baseline tasks; dashboards showing exploration diversity.
- Assumptions/dependencies: Requires telemetry on progress metrics; careful design to avoid suppressing promising but slow-burning lines of work.
- Teaching scientific method and collaboration (education)
- What to do now: Run classroom Stations where student and AI agents co-investigate scorable tasks (vision, NLP, bioinformatics). Assess contributions via Archive publications and reviewer scores.
- Tools/workflows: Course-in-a-box Station; rubrics for reviewer agent; code sandboxes; reproducibility checkers; narrative reflection assignments via Reflection Chamber.
- Assumptions/dependencies: Academic computing quotas; responsible-use policies; instructor oversight to prevent plagiarism or unsafe code.
- Safe sandboxes for policy research on autonomous agents (policy/governance)
- What to do now: Use the Station to test review standards, provenance logs, and auditability of multi-agent systems; evaluate interventions (e.g., maturity gating, stagnation nudges) for alignment and risk mitigation.
- Tools/workflows: Policy sandboxes with immutable logs; differential access controls; red-team reviewer agents; reporting templates for oversight bodies.
- Assumptions/dependencies: Requires agreed-upon risk metrics; dedicated governance expertise; careful scoping to avoid capability overhangs.
- Quantitative research backtesting in sandboxed environments (finance; research tooling)
- What to do now: Run Stations on offline, time-sliced market datasets with strict backtesting rules to discover and document strategies under a Reviewer gate; use Stagnation Protocol to refresh baselines.
- Tools/workflows: Offline data lake with leakage guards; reproducible backtesting harness; audit trails in Archive; risk/ethics checks before any live trials.
- Assumptions/dependencies: Prohibition on live trading without human governance; legal/compliance approvals; survivorship-bias and data-snooping controls.
Long-Term Applications
These leverage the paper’s open-world paradigm and emergent methods but need further research, validation, scaling, or integration.
- Autonomous, end-to-end scientific discovery with wet-lab integration (healthcare/biotech/materials)
- Vision: Couple the Station to robotic labs (LIMS, ELN, automated synthesis/assays) so agents can propose hypotheses, design experiments, schedule runs, analyze results, and iterate.
- Potential products: Agent-LIMS orchestration; hypothesis-to-protocol compilers; automated reproducibility reviewers; safety gates for biological risk.
- Dependencies: Wet-lab robotics maturity; biosecurity safeguards; IRB/regulatory approvals; provenance and reproducibility standards.
- Clinical-grade batch integration and multi-omics data fusion (healthcare)
- Vision: Validate the density-adaptive integration algorithm across multi-center clinical cohorts and extend to multimodal integration (scRNA-seq, ATAC, spatial, proteomics) for diagnostics and patient stratification.
- Potential products: IVD-grade integration software; clinical decision-support modules for rare-cell detection; integrated multi-omics viewers.
- Dependencies: Prospective clinical validation; regulatory clearance (e.g., FDA/CE); data privacy and consent; robust failure modes and monitoring.
- Closed-loop neurostimulation and BCIs guided by frequency-domain predictors (neuroscience/medtech)
- Vision: Use Fourier-based predictors to anticipate neural states and drive adaptive stimulation in closed loop (e.g., seizure suppression, Parkinsonian tremor control).
- Potential products: Low-latency inference stacks; implantable-device firmware using frequency-aware forecasting; clinical tuning assistants.
- Dependencies: Real-time constraints; safety/efficacy trials; hardware–software co-design; ethics and regulatory approvals.
- Robust planning and control in embodied agents (robotics)
- Vision: Translate RIN and related architectural insights to stabilize training of on-robot policies in manipulation/navigation with sparse rewards and long horizons.
- Potential products: Next-gen RL backbones with RIN in common control stacks; sim2real curricula orchestrated by Station agents.
- Dependencies: Transfer from toy domains to high-DOF systems; safety in exploration; compute budgets and sample efficiency.
- National or cross-institutional “Stations” for grand challenges (policy/academia/industry consortia)
- Vision: Operate public–private open-world research environments around energy materials discovery, climate modeling, biosecurity, or pandemic readiness with auditable archives and AI/human co-authorship.
- Potential products: Government-hosted Station platforms; challenge-specific evaluators; transparent reviewer frameworks; public archives with DOI minting.
- Dependencies: Governance, funding, and IP frameworks; standardized benchmarks; cybersecurity and export controls.
- Industrial optimization platforms generalized from Station search patterns (energy/logistics/manufacturing)
- Vision: Generalize MM–LP-like unified search engines and multi-agent exploration to grid scheduling, microgrid dispatch, warehouse layout, supply-chain routing, and chip/PCB floorplanning.
- Potential products: Unified optimizer services; agent-driven scenario exploration; cost–risk trade-off dashboards.
- Dependencies: Domain-specific constraints/solvers; integration with legacy systems; formal reliability guarantees.
- AI-native publishing and peer review ecosystems (scholarly communication)
- Vision: Evolve the Archive Room + Reviewer into community-scale, AI-assisted journals with reproducibility checks, code execution, and lineage-aware credit assignment.
- Potential products: Executable papers with sandboxed artifacts; automated novelty checks across archives; lineage-based attribution and incentive mechanisms.
- Dependencies: Community norms; safeguards against plagiarism/hallucination; indexing/archival standards; legal/IP considerations.
- Massively scalable education platforms with agent co-research (education)
- Vision: Courses where student cohorts and AI agents co-create artifacts, publish to internal archives, and learn research practices through emergent narratives and peer review.
- Potential products: “Station for Education” LMS plugins; automated feedback/reviewer agents; reflection and planning scaffolds.
- Dependencies: Curriculum design; academic integrity policies; accessibility and compute provisioning.
- Organizational operating systems for exploration at scale (industry)
- Vision: Company-wide Stations that continuously generate, test, and archive ideas across product, marketing, and engineering, with stagnation nudges and maturity gates to balance creativity and focus.
- Potential products: Portfolio explorers; cross-team Archive Rooms; KPI-linked evaluators; org-wide Reviewer policies.
- Dependencies: Change management; risk controls for customer-impacting experiments; alignment with OKRs and compliance.
- Safety, audit, and certification of autonomous research agents (policy/standards)
- Vision: Establish certification regimes using Station logs/lineages for auditability and incident analysis; benchmark suites for agent behavior in open worlds.
- Potential products: Compliance toolkits; standardized behavior-reporting schemas; red-team reviewer suites; incident registries.
- Dependencies: Multi-stakeholder standards processes; measurable safety metrics; legal frameworks for accountability.
Notes on Cross-Cutting Assumptions and Dependencies
- Model capability and cost: Many applications assume access to long-context, reliable LLMs and affordable compute.
- Secure execution: Sandboxed evaluation and strict data governance are critical, especially for sensitive biomedical or financial data.
- Reproducibility: Formal evaluators, dataset versioning, and artifact capture are needed to prevent leakage and enable auditability.
- Human oversight: Reviewer policies, ethical guardrails, and governance processes should accompany any deployment with real-world impact.
- Generalization: Domain transfer from benchmarks to production requires stress testing, calibration, and monitoring for distribution shifts.
Glossary
- Adjusted Rand Index (ARI): A clustering similarity metric that measures agreement between predicted labels and ground truth, adjusted for chance. "ASW Label, ARI, cLISI"
- AlphaEvolve: An evolution-based method for LLM-driven code improvement that served as a prior state-of-the-art baseline. "notably surpassing AlphaEvolve in circle packing."
- ASW Batch: Average Silhouette Width computed using batch labels to assess batch mixing in integrated embeddings. "ASW Batch, kBET, iLISI"
- ASW Label: Average Silhouette Width computed using biological labels (e.g., cell types) to evaluate structure conservation. "ASW Label, ARI, cLISI"
- Batch effects: Undesired technical variation across experimental batches that can confound biological signal. "commonly referred to as batch effects"
- BBKNN: A batch-correction method that builds a batch-balanced kNN graph by allocating neighbors per batch. "BBKNN constructs a batch-balanced NN graph"
- Bottleneck-Dilated CNN: A convolutional architecture using bottleneck layers and dilations to expand receptive field efficiently. "A Bottleneck-Dilated CNN backbone for larger receptive field."
- CELLxGENE: A large-scale repository and platform for single-cell datasets. "four human datasets from CELLxGENE."
- CELLxGENE Census: An aggregated, standardized collection within CELLxGENE for large-scale analysis. "CELLxGENE Census"
- Circle Packing: An optimization problem of placing circles within a region (e.g., unit square) to maximize objective such as total radii. "The Circle Packing task requires packing circles into a unit square"
- ComBat: An empirical Bayes method for removing batch effects in high-dimensional data. "ComBat is only used in the embedding process"
- ConvLSTM: A recurrent neural network that replaces fully connected operations with convolutions to model spatiotemporal data. "A 4-step unrolled ConvLSTM"
- cLISI: Clustering Local Inverse Simpson’s Index; a metric assessing conservation of biological structure in embeddings. "ASW Label, ARI, cLISI"
- DRC: A recurrent convolutional architecture for reinforcement learning that enables emergent planning behavior. "DRC~\cite{guez2019investigation}"
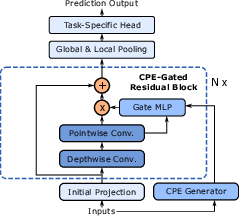
- Fourier-based Architecture: A model that forecasts in the frequency domain using Fourier components for global temporal patterns. "The Fourier-based Architecture discovered in the Station."
- Fourier transformation: A mathematical transform mapping signals to the frequency domain to analyze periodic structure. "using Fourier transformation"
- Harmony: A batch-correction algorithm that learns dataset-specific linear offsets in a shared embedding. "Harmony~\citep{korsunsky2019fast}"
- Hypernetwork: A network that generates parameters or modulations for another network to enable instance-specific predictions. "a local hypernetwork"
- iLISI: Integration Local Inverse Simpson’s Index; a metric quantifying the degree of batch mixing in integrated embeddings. "ASW Batch, kBET, iLISI"
- JAX: A high-performance numerical computing and autodiff framework for machine learning research. "Agents must submit a JAX implementation"
- kBET: k-nearest neighbor Batch Effect Test; a statistical test for detecting residual batch effects. "ASW Batch, kBET, iLISI"
- kNN: k-nearest neighbors graph used to model local neighborhood structure in high-dimensional data. "batch-balanced NN graph"
- LayerNorm: A normalization technique that normalizes activations across features within a layer to stabilize training. "LayerNorm~\cite{ba2016layer}"
- Light-sheet microscopy: An imaging technique that records large-scale, volumetric biological activity with high spatiotemporal resolution. "light-sheet microscopy recordings"
- Linear Programming (LP): Optimization of a linear objective subject to linear constraints. "an LP subproblem"
- LLM-TS (LLM-Tree-Search): A tree-search based approach to guide LLM-generated method design and evaluation. "LLM-TS~\cite{aygun2025ai}"
- MAE (Mean Absolute Error): An error metric measuring the average absolute difference between predictions and targets. "Mean Absolute Error (MAE)"
- MM-LP Adaptive Search: A two-stage search method unifying multi-start exploration with LP-based local refinement. "MM-LP Adaptive Search"
- MNN/fastMNN: Mutual nearest neighbors-based batch-correction methods that align datasets using cross-batch mutual pairs. "MNN/fastMNN~\citep{haghverdi2018batch, stuart2019comprehensive}"
- OpenProblems v2.0.0: A standardized benchmark suite for evaluating single-cell analysis methods. "OpenProblems v2.0.0 batch integration benchmark"
- PCA (Principal Component Analysis): A dimensionality reduction technique projecting data onto directions of maximal variance. "variance-scaled PCA"
- Policy gradient: A model-free RL algorithm that computes gradients of expected return with respect to policy parameters. "policy gradient~\cite{williams1992simple}"
- PPO: Proximal Policy Optimization; an RL algorithm using clipped objectives for stable policy updates. "PPO~\cite{schulman2017proximal}"
- Residual Input-Normalization (RIN): A stabilization module that blends raw input with its LayerNorm-normalized version via a residual gate. "Residual Input-Normalization (RIN)"
- scRNA-seq: Single-cell RNA sequencing, measuring gene expression at single-cell resolution. "scRNA-seq"
- SLSQP: Sequential Least Squares Programming; a gradient-based constrained optimization method. "SLSQP optimizer"
- Sokoban: A planning-intensive puzzle game used as a benchmark for RL agents. "the Sokoban task"
- SOTA: State-of-the-art; denotes the best reported performance on a task. "achieving state-of-the-art (SOTA) performance"
- SSM network: A state-space model-based neural architecture for sequence modeling. "the SSM network"
- Stagnation Protocol: A system-level intervention that prompts agents to explore new ideas when progress stalls. "Stagnation Protocol"
- Station Ticks: Discrete global time steps in the Station that sequence agent actions. "Station Ticks"
- Temporal gating ramp: A learnable mechanism that scales contributions over the forecast horizon. "temporal gating ramp"
- Thinker: A model-based RL method achieving strong Sokoban performance with longer training times. "Thinker~\cite{chung2023thinker}"
- ZAPBench: A benchmark for forecasting whole-brain neural activity in larval zebrafish. "ZAPBench benchmark"
Collections
Sign up for free to add this paper to one or more collections.