- The paper introduces BoxingGym, a benchmark that evaluates AI agents’ abilities in automated experimental design and model discovery across diverse simulated scientific environments.
- Methodologically, BoxingGym employs generative probabilistic models, expected information gain metrics, and communication-based evaluation to assess hypothesis formulation and data interpretation.
- Experimental results show that current agents, including GPT-4o and Box's Apprentice, struggle with integrating observations and optimizing experimental designs, highlighting key areas for future improvement.
BoxingGym: Benchmarking Automated Experimental Design and Model Discovery
The paper introduces BoxingGym, a new benchmark designed to evaluate the capabilities of AI agents in experimental design and model discovery. It addresses the gap in systematic evaluation of LLMs in proposing scientific models, collecting experimental data, and iteratively refining these models based on empirical evidence. BoxingGym provides a suite of diverse, simulated environments rooted in real-world scientific domains, enabling quantitative assessment of agents' abilities to design informative experiments and construct explanatory models.
Key Components and Design Principles
BoxingGym is designed around several key principles to ensure a comprehensive and realistic evaluation of scientific AI agents.
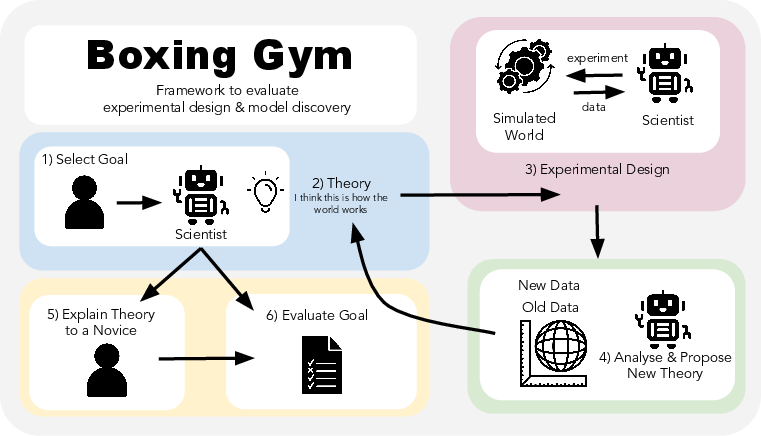
Figure 1: Overview of BoxingGym, illustrating the iterative process of theory formulation, experimental design, data analysis, and model refinement, culminating in explanation and evaluation.
A central aspect is the implementation of each environment as a generative probabilistic model. This design choice enables agents to actively experiment by sampling from the underlying model, conditioned on specific interventions. The benchmark accommodates different representations of scientific theories through a flexible language-based interface. This allows agents to interact with the environment using natural language, facilitating the expression of hypotheses and experimental designs. The framework also supports goal-directed discovery, allowing users to specify high-level objectives that guide the agent's experimentation process. This mirrors real-world scientific inquiry, where experiments are often driven by specific questions or hypotheses.
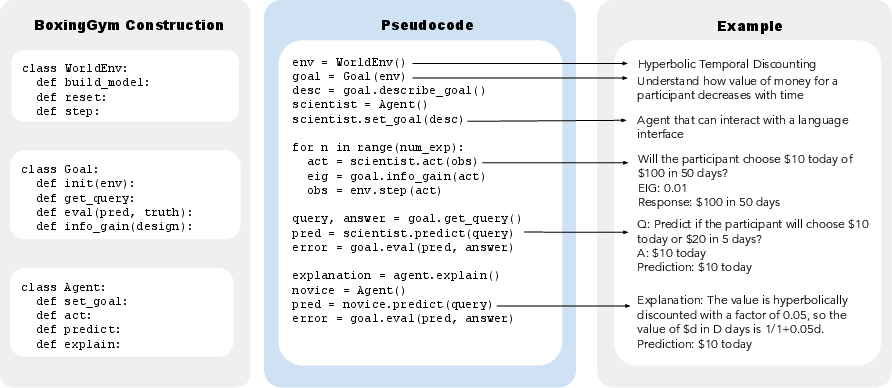
Figure 2: Python pseudocode examples showcasing the modularity of BoxingGym and the workflow of setting goals, performing experiments, and providing explanations.
Evaluation Metrics
The benchmark employs principled evaluation metrics to assess both experimental design and model discovery. Experimental design is evaluated using the Expected Information Gain (EIG), which measures how much an experiment reduces uncertainty about the parameters of the generative model.
The EIG is defined as:
EIG(d)=Ep(y∣d)[H[p(θ)]−H[p(θ∣y,d)]]
where d is the experimental design, y is the experimental outcome, θ represents the model parameters, and H denotes entropy.
Model discovery is evaluated through a communication-based strategy. A "scientist" agent is tasked with distilling its experimental findings into a natural language explanation. The quality of this explanation is then assessed by measuring how well it enables a "novice" agent to make accurate predictions about the environment. This approach aligns with the communicative nature of science, where theories are evaluated based on their ability to explain and predict phenomena. Prediction errors, such as Mean Squared Error (MSE), are also used as standard model evaluation metrics.
Experimental Results and Analysis
The paper presents initial experimental results using two baseline agents: a purely language-based agent (GPT-4o) and a language agent augmented with statistical modeling capabilities (Box's Apprentice). The experiments reveal that both agents face significant challenges in experimental design and model discovery across the benchmark's diverse environments.
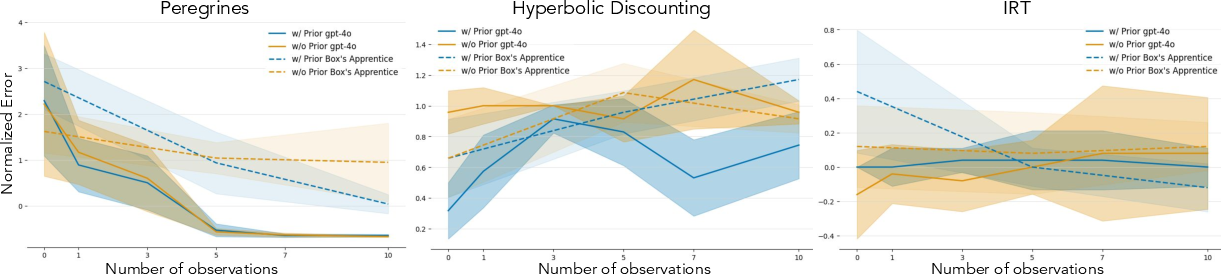
Figure 3: Standardized errors for GPT-4o and Box's Apprentice across Peregrines, Hyperbolic Discounting, and IRT domains, illustrating the relative performance of the two agents.
Specifically, GPT-4o sometimes struggles to integrate new observations and can exhibit decreased performance after experimentation due to "over-correction" based on limited data. Box's Apprentice, while capable of proposing and fitting statistical models, often fails to systematically improve its predictions after additional observations. This is attributed to a bias towards simpler functional forms and difficulty in strategically collecting informative data in low-data regimes.
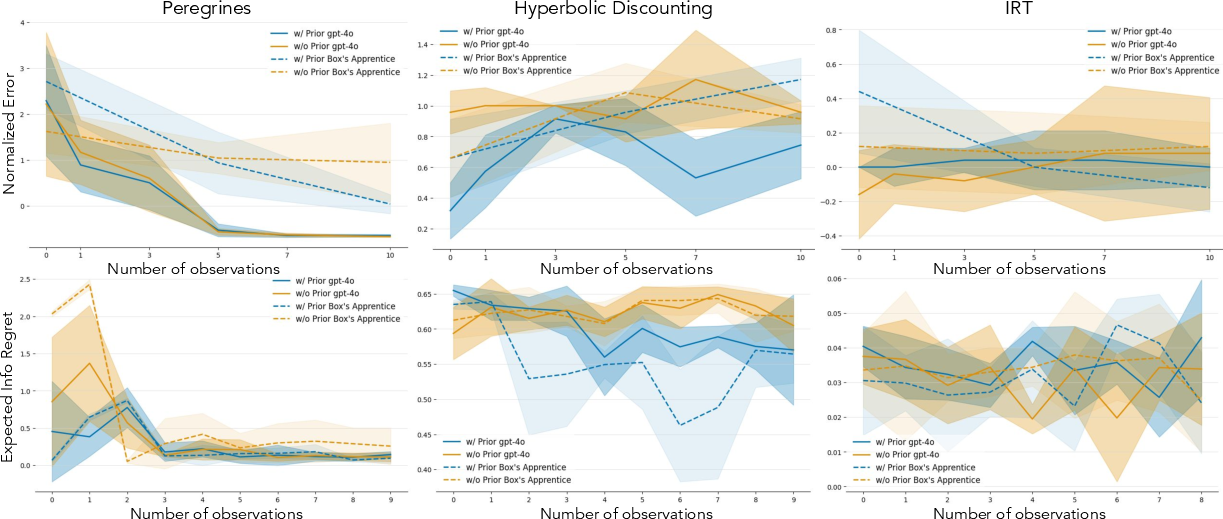
Figure 4: Standardized errors and EIG regrets for GPT-4o and Box's Apprentice, highlighting the trade-offs between prediction accuracy and information gain in experimental design.
The communication-based evaluation reveals that explanations generated by both agents generally improve the novice's predictions, but a gap remains between the novice's performance and the performance of agents that directly interact with the environment. This suggests that learning from agent-generated explanations is not as effective as hands-on experimentation.
Implications and Future Directions
The research has several important implications for the development of scientific AI agents. The benchmark highlights the need for improved methods for hypothesis generation, experimental design, and the integration of prior knowledge with new observations. The results suggest that augmenting LLMs with statistical modeling capabilities does not automatically lead to improved performance, indicating that more sophisticated approaches are needed to effectively combine language and symbolic reasoning.
Future research directions include expanding the benchmark to include more diverse scientific domains, incorporating the costs of experiments, and developing more sophisticated simulations of human participants. The authors also suggest exploring new interfaces that leverage data visualization techniques, strategic simulations, and web-based research strategies to enhance the ability of AI agents to guide experimentation and discovery.
Conclusion
BoxingGym offers a valuable framework for evaluating and advancing the capabilities of AI agents in scientific discovery. By providing a set of diverse, simulated environments and principled evaluation metrics, this benchmark can drive progress in automated experimental design and model discovery. The initial results presented in the paper underscore the challenges that remain in building AI agents that can effectively propose hypotheses, design experiments, and iteratively refine their models based on empirical evidence.