- The paper introduces Temporal Search (TS), a training-free framework that iteratively focuses on relevant video segments using confidence-guided interval proposals.
- It employs a novel TS-BFS algorithm that navigates a tree of temporal intervals using model confidence scores and self-evaluation to refine predictions.
- Experimental results show TS significantly improves MLLM accuracy on benchmarks by using minimal frame samples while efficiently zooming into critical content.
Iterative Zoom-In for Enhanced Long Video Understanding
This paper introduces Temporal Search (TS), a novel, training-free framework designed to enhance the ability of Multimodal LLMs (MLLMs) to understand long-form videos by iteratively exploring temporal intervals. The core idea behind TS is inspired by human visual attention, which dynamically focuses on salient temporal regions rather than processing all frames uniformly. TS leverages the model's confidence in its generation across different temporal intervals as a key signal to guide the search process, focusing on regions most likely to contain task-relevant information.
Methodological Overview
The TS framework operates through iterative stages, effectively enabling MLLMs to "zoom in" on pertinent temporal segments (Figure 1). The process begins with the MLLM proposing a temporal interval likely to contain relevant information. Subsequently, a fixed number of frames are sampled from this interval, irrespective of its length, and fed into the model to generate a refined response and a confidence score. This iterative refinement allows the model to progressively narrow its focus, capturing finer-grained temporal details crucial for accurate understanding. To further enhance efficiency, the paper introduces TS-BFS, a best-first search strategy conducted over a tree structure representing temporal intervals (Figure 2). Each node in the tree corresponds to a candidate interval, expanded through model-driven proposals and uniform partitioning. Nodes are scored based on a combination of prediction confidence and self-evaluation of answer correctness. The key algorithmic components of TS and TS-BFS are detailed in Algorithm 1 and Algorithm 2, respectively.
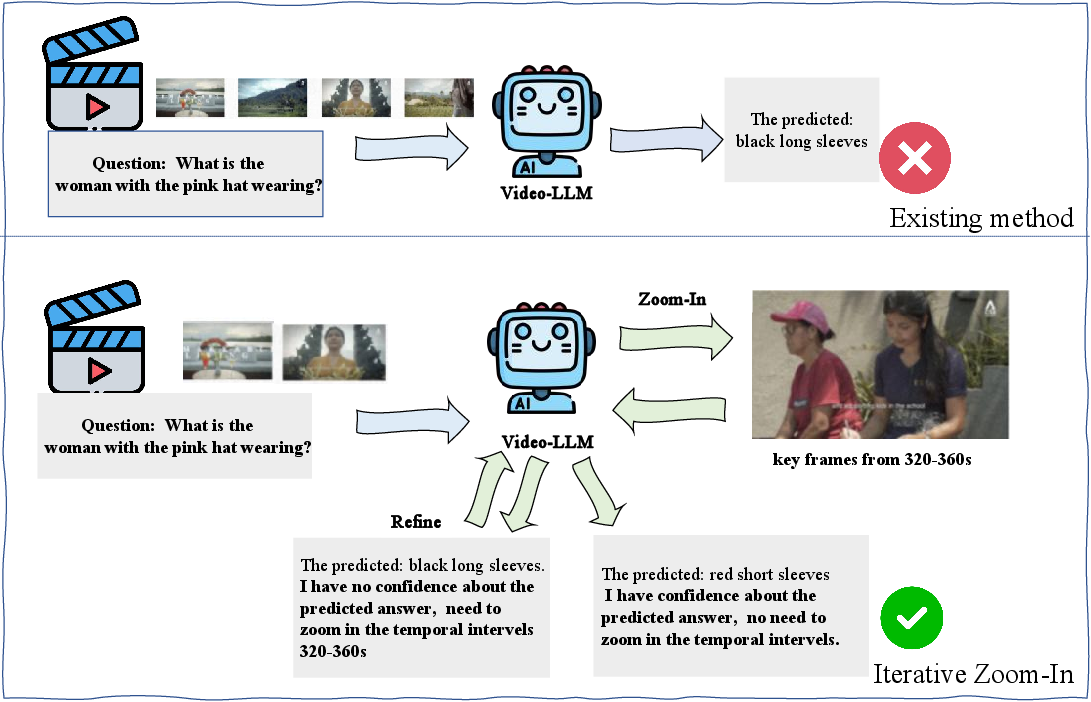
Figure 1: Iterative Zoom-In vs. Single-Pass Inference. Our method iteratively proposes new temporal intervals and samples a fixed number of frames from each. Shorter intervals lead to finer temporal perception, effectively zooming in on relevant intervals for more accurate understanding.
Implementation Details
The implementation of TS involves several key steps, including temporal interval proposal, frame sampling, response generation, and confidence scoring. The model's confidence score, computed as the average log-probability of generated tokens, guides the search towards more accurate predictions. The authors also employ prompt engineering, utilizing Expand_Prompt, Evaluate_Prompt, and Key_Frame_Prompt, to direct node expansion, evaluation, and keyframe description generation (Figure 3). These keyframe descriptions are integrated into the input prompt, facilitating global video understanding by the VideoLLM.
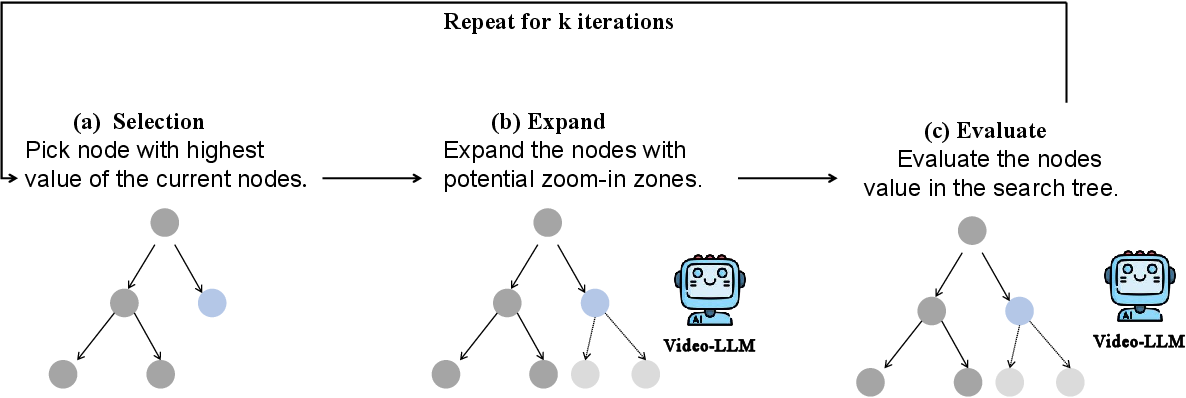
Figure 2: Nodes are selected based on a combined score of the modelâs prediction confidence and its self-evaluation of answer correctness. Each node is expanded using two strategies: model-guided proposal and uniform splitting of the current interval. In each iteration, the VideoLLM proposes new temporal intervals, generates responses with confidence scores, evaluates its answers, and produces keyframe-level descriptions incorporated into the input to support global video understanding.
Experimental Results
The efficacy of TS is demonstrated through extensive experiments on long-form video question answering benchmarks, including LongVideoBench and VideoMME. The results show that TS consistently improves the performance of MLLMs on long videos. For instance, TS-BFS enhances Qwen-VL-2.5's accuracy from 51.5% to 57.9% on LongVideoBench and from 48.5% to 55.1% on VideoMME. The authors also present a detailed analysis of the correlation between model confidence and prediction accuracy, confirming that higher confidence scores are indicative of greater answer accuracy (Figure 4). Ablation studies further validate the design choices and robustness of the TS framework across different video durations and frame sampling rates. Notably, the experiments reveal that TS achieves competitive performance with only 8 frames per inference, outperforming larger models that require significantly more frames. The authors find that increasing the frame count to 16 provides noticeable accuracy gains, while further increases (32 or 64 frames) yield diminishing returns but significantly raise memory usage

Figure 3: Prompts for Tree Search.
Analysis and Discussion
The results highlight the advantage of adaptive, iterative inference over static multi-pass aggregation, particularly when operating within fixed per-pass frame budgets. The tree-based search in TS-BFS can be efficiently parallelized by evaluating multiple candidate intervals in batches. Ablation studies show that moderately high values of the key-frame acceptance threshold c1 help avoid premature convergence, while stricter early termination thresholds c2 (1.0) promote more confident final decisions. A case study illustrates TS's ability to efficiently zoom in on relevant content, enabling accurate reasoning in long videos (Figure 5).
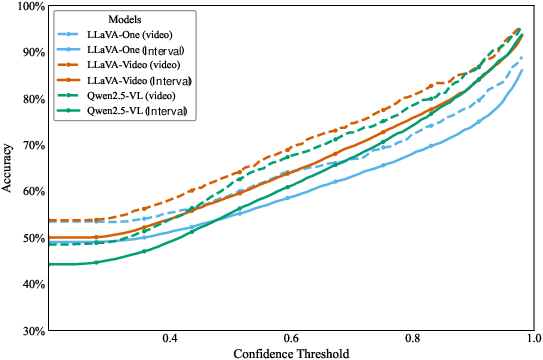
Figure 4: Relationship between model confidence and prediction accuracy at the video and interval levels. Higher confidence thresholds consistently correspond to higher accuracy, indicating that model confidence serves as a reliable signal for guiding temporal interval selection. Each point represents the accuracy of predictions whose confidence exceeds the corresponding threshold.
Implications and Future Directions
This work has significant implications for the field of video understanding, offering a practical approach to address the challenges posed by long-form videos. The training-free nature of TS makes it readily applicable to existing MLLMs, while its efficient temporal exploration strategy reduces computational costs. The finding that model confidence correlates with prediction accuracy is particularly noteworthy, as it provides a valuable signal for guiding the search process. Future research directions could explore more sophisticated search strategies, adaptive frame sampling techniques, and the integration of external knowledge sources to further enhance the performance of TS. The framework's ability to improve performance across different video durations suggests its potential for broader applications in video analysis.
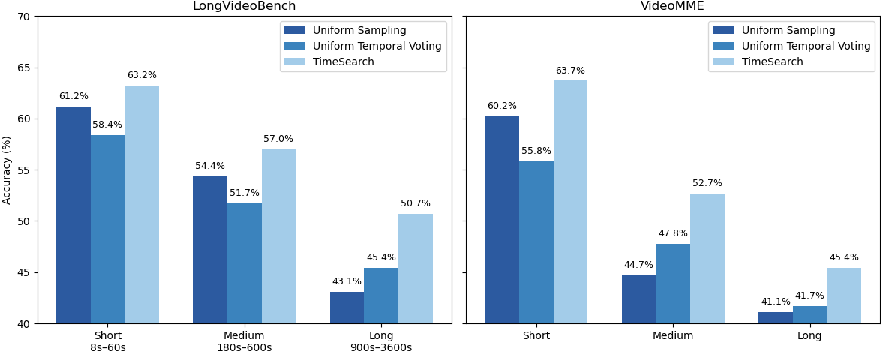
Figure 6: Accuracy on LongVideoBench and VideoMME by duration based on the Qwen2.5-Vl. TS improves accuracy across all durations, showing better generalization and robustness.
Figure 7: Model performance under different numbers of inference passes. Results are based on the Qwen2.5-VL on LongVideoBench.
Conclusion
The paper makes a compelling case for the use of iterative temporal exploration in long video understanding. By leveraging model confidence and employing efficient search strategies, TS offers a practical and effective solution to improve the accuracy and efficiency of MLLMs on long-form video tasks. The experimental results and ablation studies provide strong evidence of the framework's effectiveness and robustness, highlighting its potential for real-world applications.
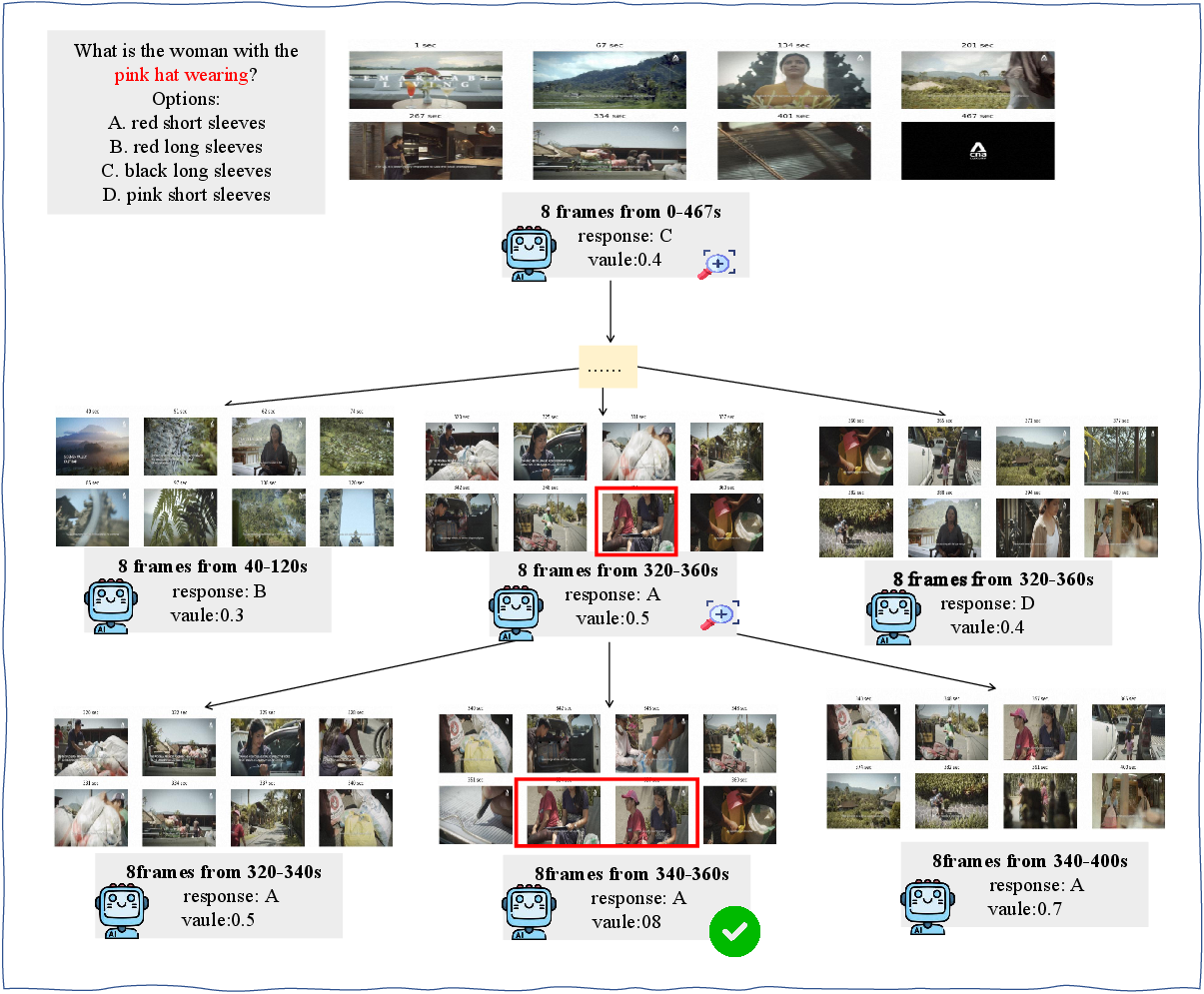
Figure 5: Illustration of the Temporal Search framework with iterative zoom-in on valuable temporal segments.