- The paper introduces a novel Dense Motion Captioning task and the DEMO model that generates segment-level captions with accurate temporal boundaries.
- It employs a two-stage training process utilizing a large language model and a motion adapter on the newly developed CompMo dataset for precise motion-language alignment.
- Experimental evaluations show improved temporal localization and caption accuracy over existing methods, setting a new benchmark in 3D human motion analysis.
Dense Motion Captioning: An Academic Summary
This essay explores the task of Dense Motion Captioning (DMC) as presented in the paper titled "Dense Motion Captioning" (2511.05369). The discussion encapsulates the task formulation, dataset development, and the architectural design of the proposed Dense Motion Captioning Model (DEMO) alongside extensive experimental evaluations and implications in further advancing the understanding of complex human motion sequences.
Introduction to Dense Motion Captioning
Dense Motion Captioning is envisioned as a task that combines temporal localization and natural language processing to interpret and describe 3D human motion sequences with high precision. The primary objective is to generate detailed segment-level captions with accurate temporal boundaries, a capability largely absent in current annotation frameworks and datasets. This task is particularly aimed at enhancing motion understanding within long and complex sequences where nuanced temporal details are crucial.
Existing datasets like HumanML3D offer initial insights but fall short on complexity and comprehensive annotations required for the DMC task. In response, the authors introduce the Complex Motion Dataset (CompMo), which offers richly annotated sequences with precise segment-level captions, thereby setting a robust groundwork for model training and evaluation.
Dataset Development: The Complex Motion Dataset (CompMo)
The CompMo dataset was meticulously crafted to address the deficiencies in existing datasets regarding scale, annotation accuracy, and temporal complexity. It encompasses 60,000 motion sequences with duration averaging about 39.88 seconds and divided into multiple atomic actions. The collected motion data, sourced from HumanML3D, underwent a multi-stage generation pipeline incorporating advanced techniques like diffusion-based models and temporal stitching to ensure high-quality motion and textual descriptions.
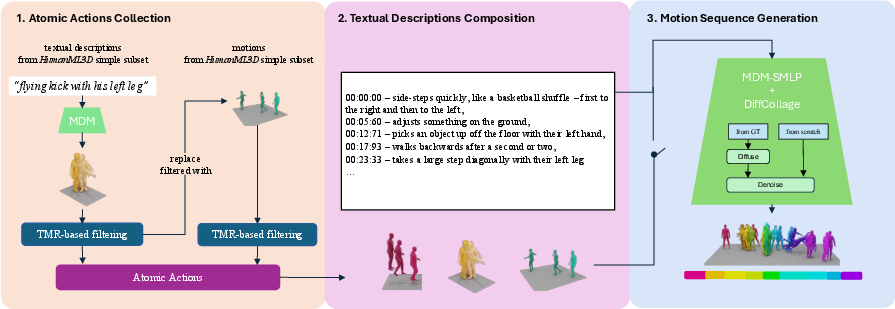
Figure 1: Overview of CompMo generation pipeline, illustrating the process from atomic actions collection to motion sequences generation.
These efforts culminate in a dataset that not only supports DMC but broadens potential applications, including enhanced motion-language alignment and advanced temporal motion analysis.
Dense Motion Captioning Model (DEMO)
The DEMO architecture exploits a LLM, finetuned to process 3D motion sequences and generate coherent, temporally aligned captions. This model integrates a motion adapter capable of transforming motion data into language-compatible embeddings, circumventing the traditional discretization losses associated with VQ-VAE-based approaches.
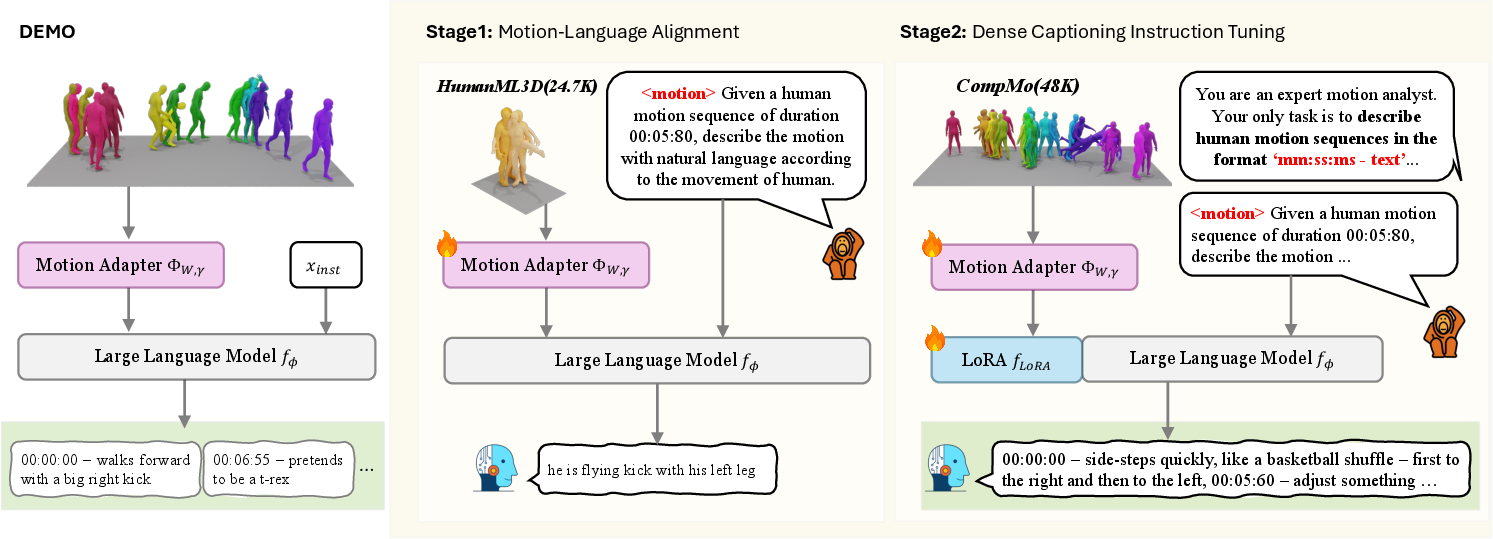

Figure 2: DEMO overview, showing the encoding process of motion sequences and the generation of temporally grounded captions.
Training is conducted in two stages: motion-language alignment on simpler sequences followed by instruction tuning using CompMo. This strategy optimizes the model’s capacity to handle complex motions and generate high-fidelity captions, establishing a benchmark for both motion understanding and caption generation.
Experimental Evaluation
Extensive evaluations showcase DEMO’s superiority over adapted existing models in dense captioning accuracy and temporal localization. On challenging datasets like CompMo, DEMO significantly improves performance metrics in SODA, temporal IoU, and motion-caption alignment, evidencing its robustness and adaptability.
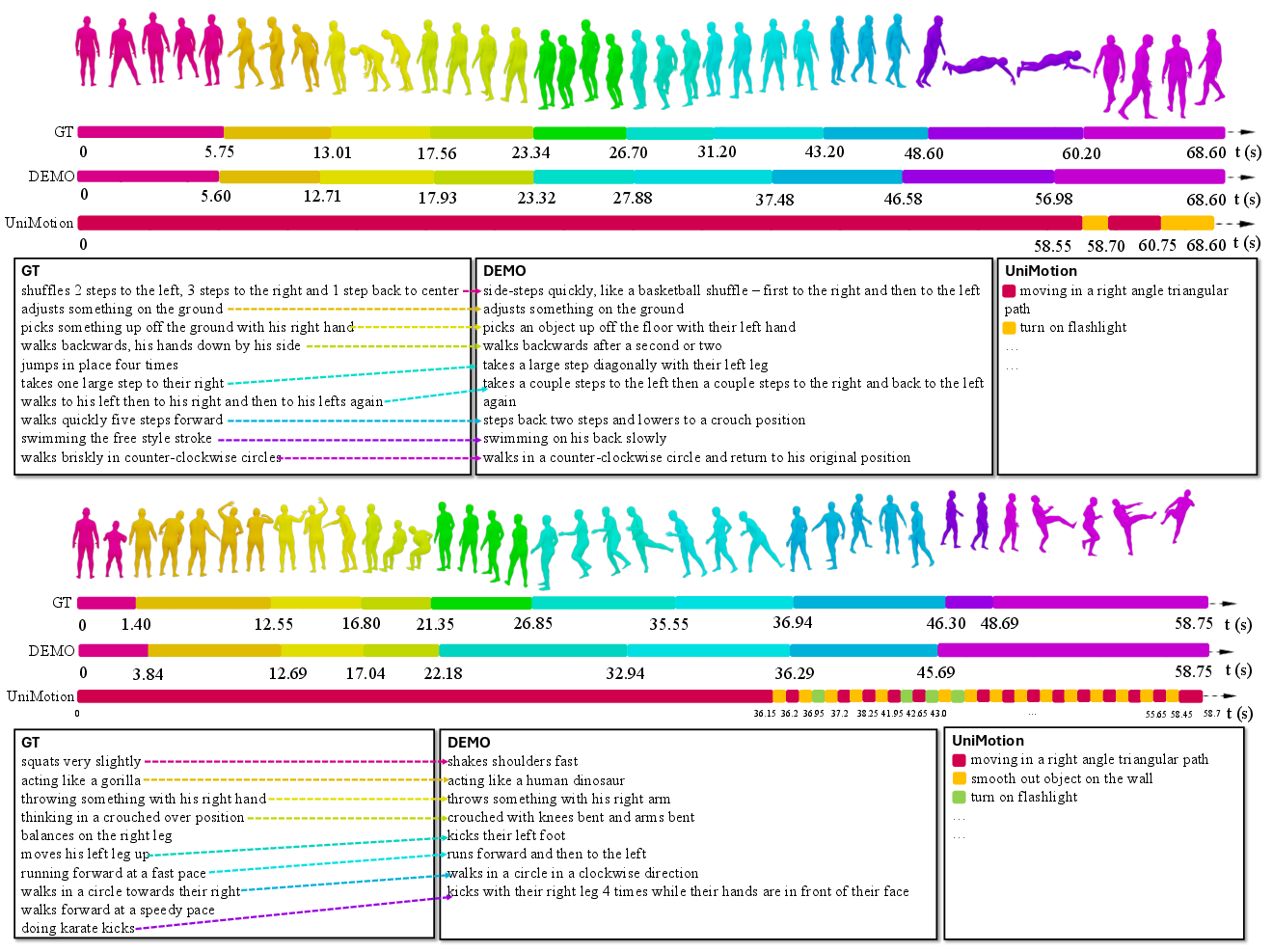
Figure 3: Qualitative results comparing captions generated by DEMO with ground truth and existing models.
The qualitative analysis further reinforces DEMO’s capability in creating contextually and temporally accurate descriptions, enhancing interpretability and alignment with intended annotations.
Implications and Future Scope
Dense Motion Captioning introduces a paradigm shift in 3D human motion understanding by embedding language generation within temporally complex motion sequences. This task extends beyond traditional video analysis, facilitating more precise body-centric motion interpretations. Future work could focus on integrating causal action modeling, spatio-temporal compositions, and enhancing dataset realism, ensuring natural transitions and coherent action narratives.
Conclusion
This academic exploration highlights Dense Motion Captioning as a forward-thinking task that merges motion analysis with natural language processing to unlock deeper insights into human activity recognition. With CompMo and DEMO, the foundation is laid for further research and application in fields demanding detailed temporal motion awareness. The task's development is pivotal in advancing AI systems capable of interacting with and understanding human dynamics comprehensively.

