- The paper introduces a unified autoregressive diffusion transformer model that integrates text, speech, music, and reference motion for enhanced motion generation.
- It employs a progressive weak-to-strong training strategy to resolve multimodal conflicts while preserving semantic alignment.
- The OmniMoCap-X dataset, featuring 64.3 million frames across 28 datasets, underpins state-of-the-art performance on diverse motion synthesis tasks.
OmniMotion-X: A Unified Multimodal Framework for Whole-Body Human Motion Generation
Introduction
OmniMotion-X presents a unified autoregressive transformer-based diffusion model for whole-body human motion generation, supporting a broad spectrum of multimodal tasks including text-to-motion, music-to-dance, speech-to-gesture, and global spatial-temporal control scenarios. The framework is designed to overcome the limitations of prior works, which are constrained by task-specific architectures, fragmented datasets, and insufficient multimodal integration. OmniMotion-X introduces reference motion as a novel conditioning signal and employs a progressive weak-to-strong mixed-condition training strategy to resolve multimodal conflicts and enhance controllability. The accompanying OmniMoCap-X dataset is the largest unified multimodal motion capture resource to date, standardized to SMPL-X format and enriched with hierarchical captions generated via GPT-4o.
Model Architecture and Multimodal Conditioning
OmniMotion-X leverages a Diffusion Transformer (DiT) backbone, integrating multiple condition modalities—text, global motion, speech, music, and reference motion—via modality-specific encoders and learnable linear projections. All condition tokens are concatenated as prefix context to the noisy motion tokens, enabling efficient fusion and interaction across modalities.
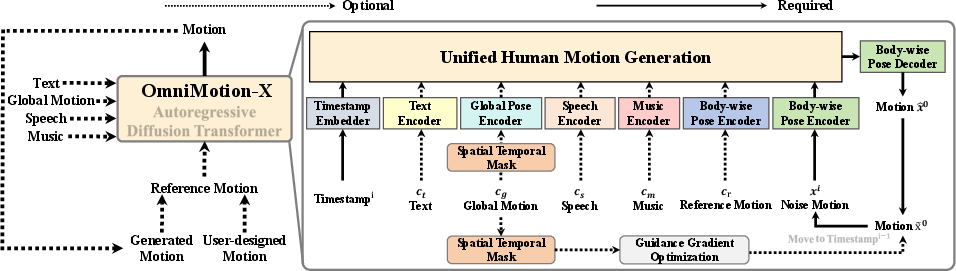
Figure 1: OmniMotion-X architecture fuses multimodal conditions through condition-specific encoders mapped into a unified space, with spatial-temporal guidance for consistent global motion.
The reference motion condition, absent in previous frameworks, provides fine-grained temporal and stylistic priors, substantially improving the consistency and realism of generated motions. The model supports mixed-condition training, allowing simultaneous conditioning on multiple modalities and enabling complex, interactive generation scenarios.
Progressive Weak-to-Strong Training Strategy
To address optimization conflicts arising from disparate condition granularities, OmniMotion-X employs a progressive weak-to-strong training paradigm. Initial training focuses on establishing semantic alignment with text, followed by incremental integration of stronger multimodal signals—reference motion, global motion, speech, and music. This staged approach prevents overfitting to low-level controls and preserves high-level semantic guidance.
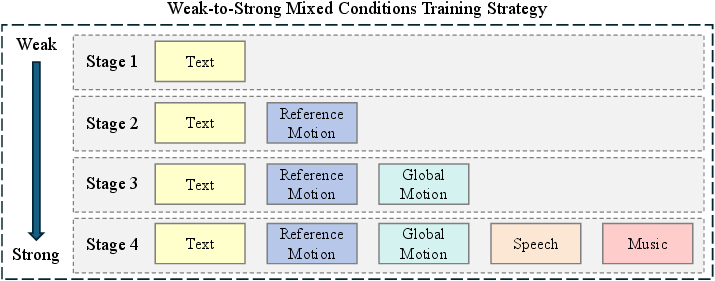
Figure 2: Weak-to-strong progressive training: text-based alignment precedes integration of stronger multimodal signals for enhanced controllability.
Empirical ablation demonstrates that this strategy is essential for maintaining controllability and avoiding suppression of weaker modalities by dominant low-level signals.
OmniMoCap-X Dataset: Scale, Quality, and Annotation
OmniMoCap-X aggregates 28 high-quality motion capture datasets across 10 tasks, unified under the SMPL-X format at 30 fps. The dataset comprises 64.3 million frames (286.2 hours), supporting diverse tasks such as T2M, M2D, S2G, HOI, HSI, and HHI. All motion formats are standardized, and temporal/spatial normalization ensures consistent coordinate systems and frame rates.
Captions are generated by rendering motion sequences into videos and annotating them with GPT-4o, combining visual and textual information for structured, hierarchical descriptions. This approach yields high lexical diversity and semantic richness, facilitating generalizable motion understanding and generation.

Figure 3: Example of GPT-4o-generated hierarchical captions, demonstrating semantic and kinematic detail.
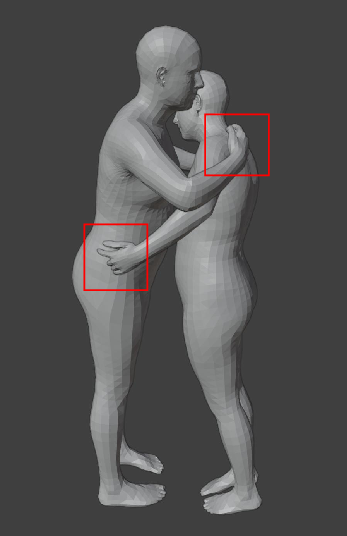
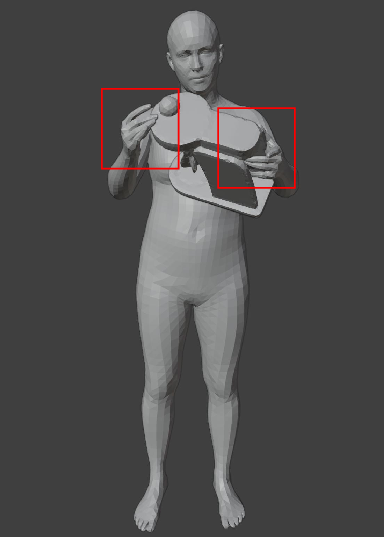

Figure 4: Dataset supports Human-Human, Human-Object, and Human-Scene interactions with detailed spatio-temporal annotations.
Task Coverage and Synthesis Capabilities
OmniMotion-X supports a wide array of motion synthesis tasks:
- Text-to-motion (T2M)
- Speech-to-gesture (S2G)
- Music-to-dance (M2D)
- Trajectory-guided motion
- Motion in-betweening
- Motion prediction

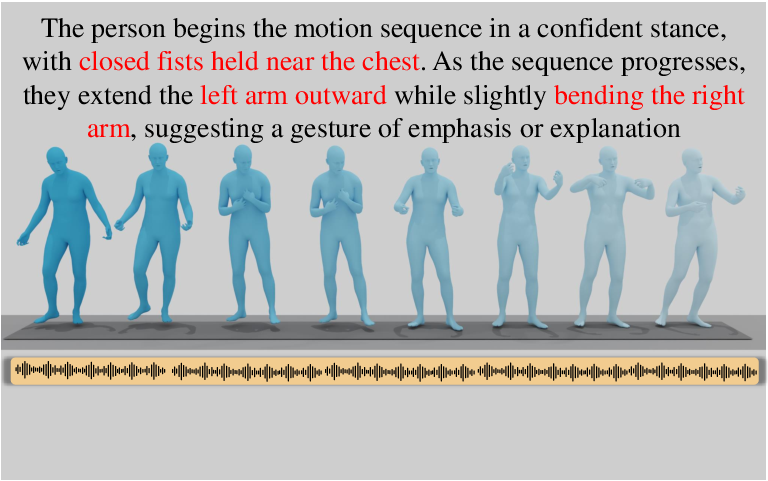

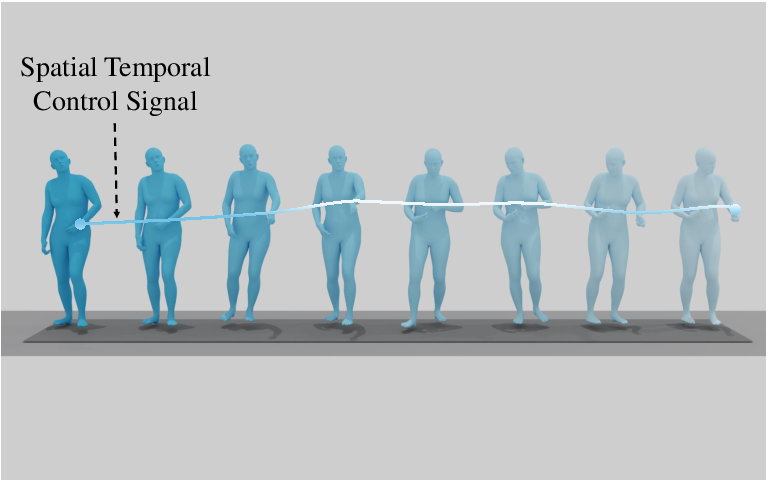
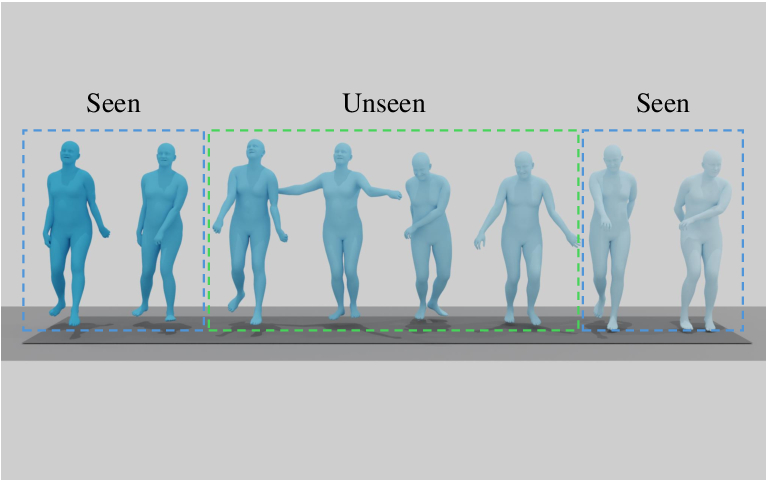
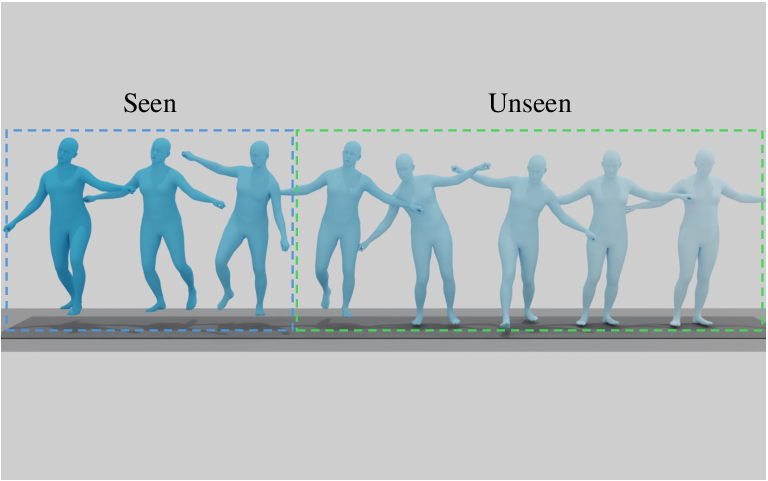
Figure 5: OmniMotion-X enables diverse motion synthesis tasks, including T2M, S2G, M2D, trajectory guidance, in-betweening, and prediction.
The model’s unified architecture and dataset enable seamless transfer and generalization across these tasks, with robust support for multimodal and interactive scenarios.
Quantitative and Qualitative Evaluation
Extensive experiments on the OmniMoCap-X test set demonstrate that OmniMotion-X achieves state-of-the-art performance across T2M, GSTC, M2D, and S2G tasks. Notably, the model outperforms baselines trained on smaller or lower-quality datasets, with significant improvements in R-Precision, FID, multimodal distance, and diversity metrics. The integration of reference motion further boosts alignment and generation quality.
Ablation studies confirm the necessity of the progressive training strategy for maintaining semantic alignment and effective spatiotemporal control. Qualitative results illustrate the model’s ability to generate coherent, realistic, and controllable long-duration motions under complex multimodal conditions.
Implementation Details and Deployment Considerations
The model utilizes an 8-layer, 8-head Transformer Encoder with a hidden dimension of 1536, trained progressively on a single H800 GPU. Training involves staged integration of conditions, with batch sizes and learning rates adjusted per stage. The dataset’s scale and diversity necessitate efficient data loading and preprocessing pipelines, including motion format conversion, normalization, and hierarchical captioning.
For deployment, inference speed is limited by the sample-space denoising process inherent to diffusion models. Future work should explore more efficient representations and sampling strategies to enable real-time applications.
Implications and Future Directions
OmniMotion-X establishes a new standard for multimodal whole-body motion generation, enabling flexible, interactive, and high-fidelity synthesis across a wide range of tasks and conditions. The unified dataset and hierarchical annotation framework facilitate transfer learning and generalization, supporting research in animation, gaming, virtual reality, and embodied intelligence.
However, the current framework lacks explicit modeling of scene, object, and human interaction constraints, limiting applicability in complex real-world environments. Future research should focus on integrating these constraints and optimizing inference efficiency, potentially via latent consistency models or hybrid autoregressive-diffusion architectures.
Conclusion
OmniMotion-X advances the state of multimodal human motion generation by unifying diverse tasks and modalities within a scalable autoregressive diffusion transformer framework. The introduction of reference motion conditioning and progressive training resolves multimodal conflicts and enhances controllability. The OmniMoCap-X dataset provides a high-quality, richly annotated foundation for generalizable motion synthesis. While limitations remain in interaction modeling and inference speed, the framework lays a robust foundation for future developments in large-scale, multimodal motion generation and interactive character control.

