- The paper presents IRIS, a benchmark that rigorously tests multimodal LLMs' abilities in tool-enabled image perception, transformation, and reasoning across 1,204 diverse tasks.
- IRIS tasks include both single-turn and multi-turn challenges, revealing stark performance gaps with the best model achieving only an 18.68% average pass rate and dominant visual perception errors.
- The analysis highlights that proactive, diverse tool usage correlates with better performance, underscoring the need for improved tool integration and training on tool-augmented workflows.
The paper "Beyond Seeing: Evaluating Multimodal LLMs on Tool-Enabled Image Perception, Transformation, and Reasoning" (2510.12712) introduces IRIS, a benchmark designed to rigorously evaluate the capabilities of Multimodal LLMs (MLLMs) in scenarios that require not only passive visual perception but also active image manipulation and tool-augmented reasoning. This work addresses a critical gap in current multimodal evaluation: the lack of systematic assessment for models' ability to "think with images"—that is, to dynamically transform and interact with visual content as part of a compositional reasoning process.
Motivation and Benchmark Design
Traditional multimodal benchmarks predominantly focus on static image understanding, where models are evaluated on their ability to answer questions or perform reasoning over fixed visual inputs. However, real-world applications often present images that are suboptimal—rotated, cluttered, or poorly exposed—necessitating active manipulation (e.g., cropping, enhancement) to extract salient information. The IRIS benchmark is constructed to reflect this reality, shifting the evaluation paradigm from "thinking about images" to "thinking with images."
IRIS comprises 1,204 open-ended tasks (603 single-turn, 601 multi-turn) spanning five domains: STEM, Medical, Finance, Sports, and Generalist. Each task is paired with detailed, weighted rubrics for systematic, multi-dimensional evaluation, enabling both binary pass/fail and fine-grained diagnostic scoring. The benchmark supports a suite of tools, including a vision-specific Python image processing API and general-purpose tools (web search, Python interpreter, calculator, historical weather lookup), accessible via a standardized function-calling interface.
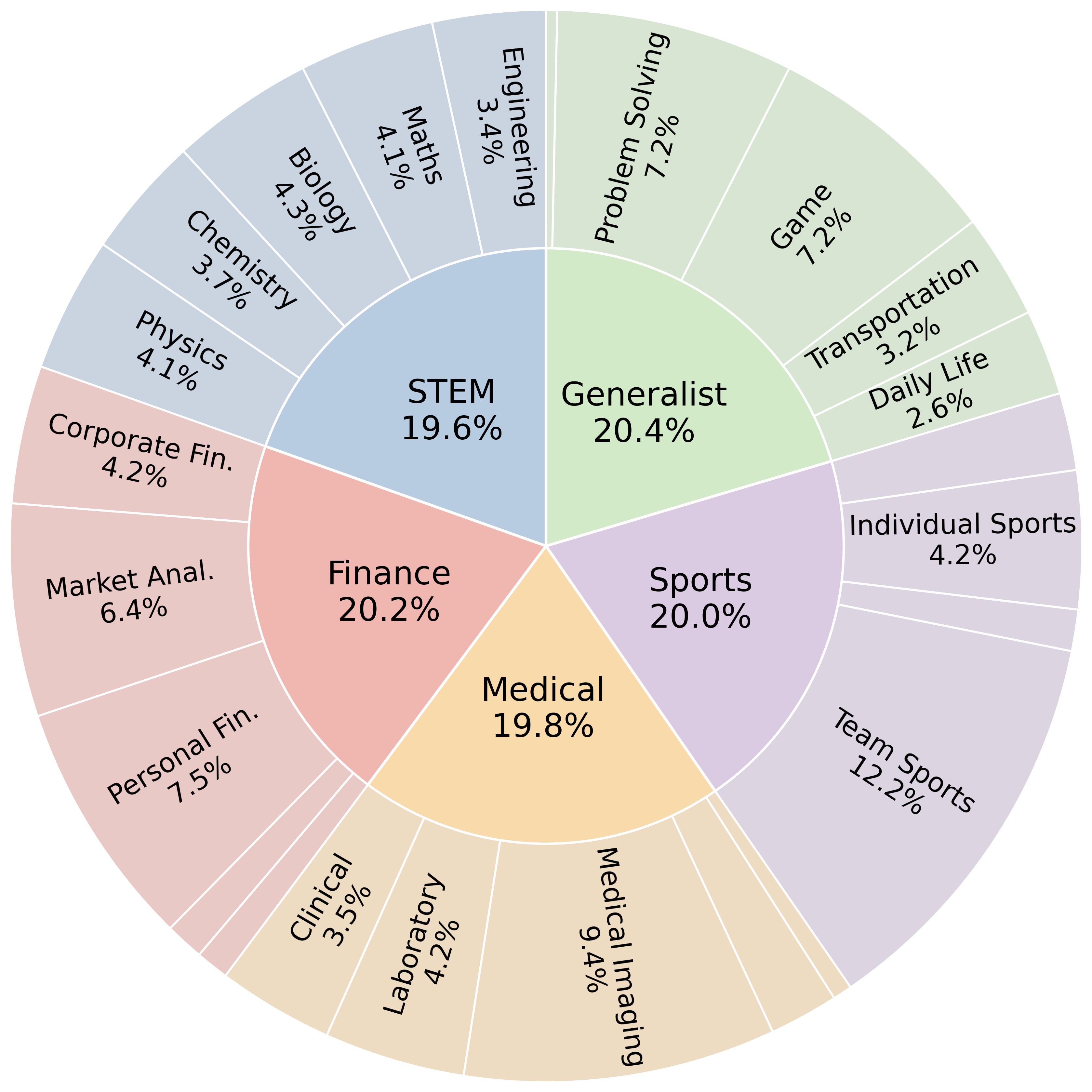
Figure 1: Topic distribution of IRIS tasks across five domains, ensuring broad coverage of real-world scenarios.
Task Categories and Data Collection
IRIS tasks are organized into five categories, each probing distinct aspects of multimodal reasoning:
- Region-Switch Q&A (Single-Turn): Requires models to extract and integrate information from multiple, spatially distinct regions of an image, often necessitating cropping and selective focus.
- Hybrid Tool Reasoning (Single-Turn): Involves orchestrating both vision-specific and general-purpose tools to solve multi-step problems.
- Follow-up Test (Multi-Turn): Evaluates conversational proactivity and clarification in underspecified scenarios.
- Temporal Visual Reasoning (Multi-Turn): Assesses reasoning over sequences of images, tracking changes and inferring causality.
- Progressive Visual Reasoning (Multi-Turn): Tests long-horizon reasoning and contextual memory across interdependent queries.
Tasks are authored and reviewed through a multi-stage pipeline to ensure realism, diversity, and challenge, with only those tasks that defeat at least two of three strong baseline models being retained.

Figure 2: Example IRIS task requiring region-based cropping and multi-step reasoning, with rubrics for both partial and critical evaluation.
Rubric-Based Evaluation Protocol
A key methodological contribution is the rubric-based evaluation framework. Each task is annotated with multiple rubric items, weighted by importance (1–5), spanning visual understanding, truthfulness, instruction following, reasoning, and presentation. Critical rubrics (weight ≥4) determine binary task success, while the weighted sum provides a nuanced rubric score. This approach enables granular analysis of model strengths and failure modes, moving beyond simple accuracy metrics.
Sixteen MLLMs with function-calling capabilities were evaluated on IRIS, including both open- and closed-source models. The primary metrics are Average Pass Rate (APR) and Average Rubric Score (ARS). The results are stark: no model surpasses a 20% pass rate, with the best-performing model (GPT-5-think) achieving 18.68% APR. Eleven out of sixteen models score below 10% APR, underscoring the substantial difficulty of the benchmark.
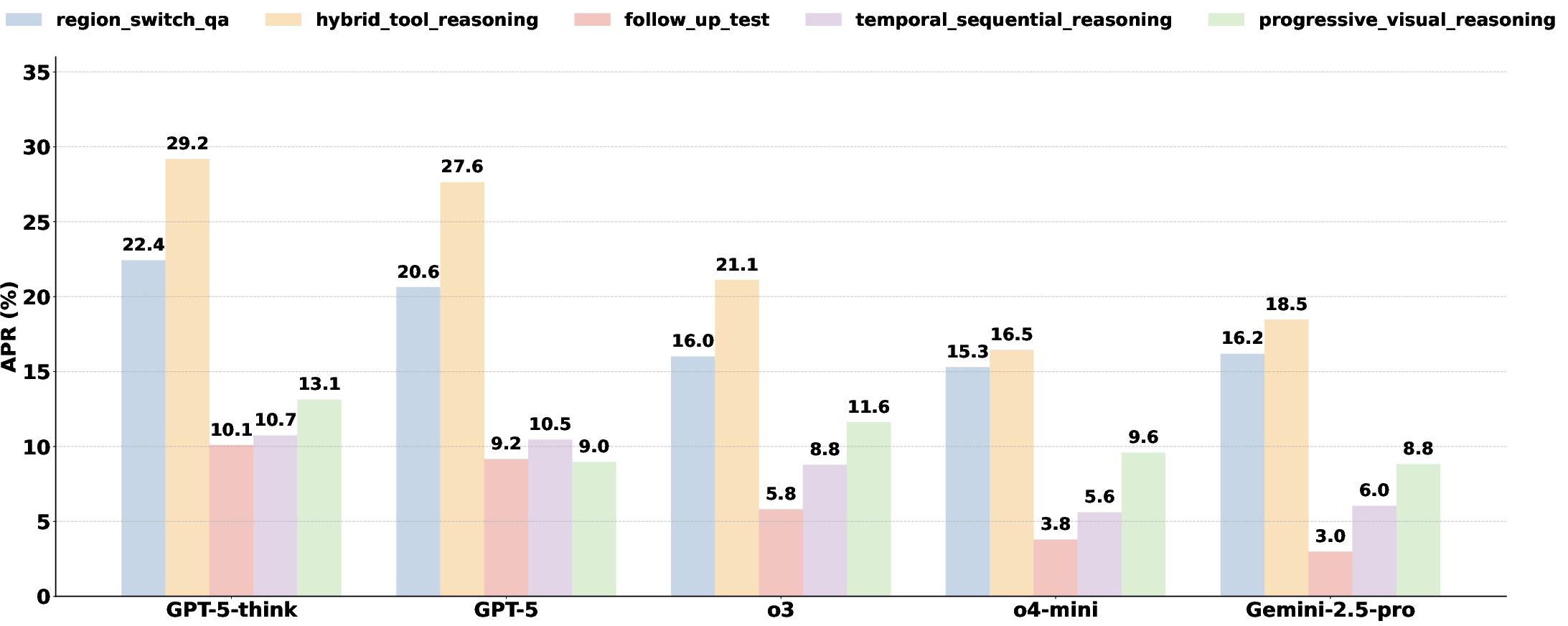
Figure 3: APR across task categories for the top five models, highlighting the pronounced difficulty of multi-turn and compositional tasks.
OpenAI models (GPT-5, GPT-5-think, o3) consistently outperform others, likely due to targeted training on tool-augmented workflows. Gemini-2.5-pro demonstrates strong visual perception but does not benefit from tool access, suggesting architectural or training differences in tool integration. Multi-turn tasks are significantly more challenging than single-turn tasks, reflecting the compounded complexity of maintaining context and reasoning over multiple steps.
A detailed analysis of tool-use behaviors reveals that proactive and diverse tool usage correlates with higher performance. OpenAI models exhibit both high tool-call proactivity and volume, with the vision tool (python_image_processing) accounting for the majority of tool invocations—over 90% in GPT-5. However, more tool calls do not guarantee better results; efficiency and diversity of manipulations are critical.
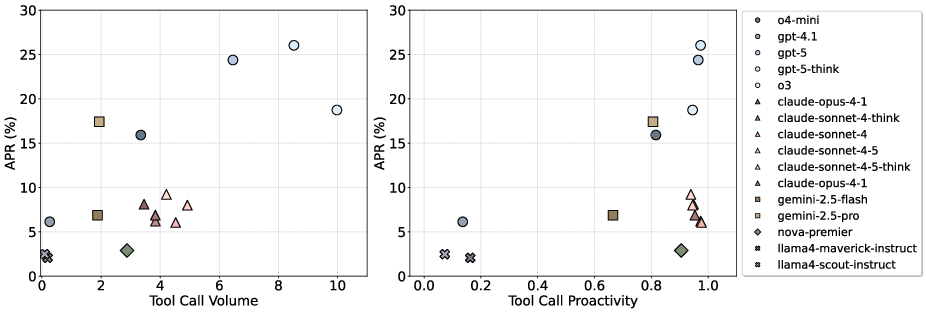
Figure 4: Relationship between APR and tool-use behaviors. Left: APR vs. tool-use proactivity. Right: APR vs. average tool call volume per task.
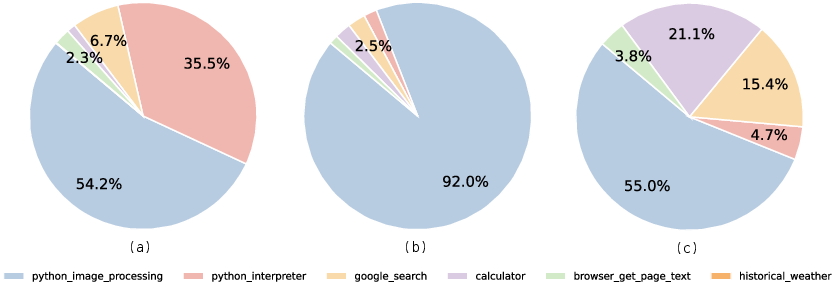
Figure 5: Tool-use distribution for top APR models, showing dominance of vision tool calls.
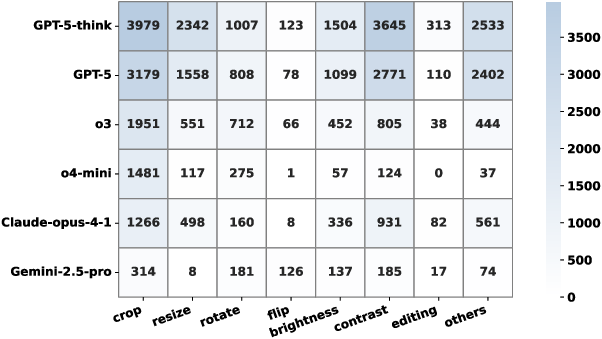
Figure 6: Image manipulation operation counts, with GPT-5 and GPT-5-think demonstrating both higher volume and diversity of operations.
GPT-5 and GPT-5-think often perform multiple manipulations within a single tool call, indicating greater tool-use efficiency compared to models like o3, which issues more but less effective calls. In contrast, models such as Gemini-2.5-pro and Claude variants show limited manipulation diversity and lower tool-use efficiency.
Error Analysis
Failure analysis across top models indicates that visual perception errors are the dominant failure mode (71–82% of errors), far exceeding reasoning or calculation mistakes. This highlights a fundamental limitation: current MLLMs, even with tool access, struggle to extract and interpret critical visual content when it is not directly accessible.
Ablation Studies
Ablation experiments demonstrate that tool access and strong prompting significantly impact performance for some models (e.g., GPT-5), with APR drops of 11–14% when tools are removed or prompts are weakened. Notably, Gemini-2.5-pro performs better without tool access, suggesting that tool integration can be detrimental if not properly aligned with model training.
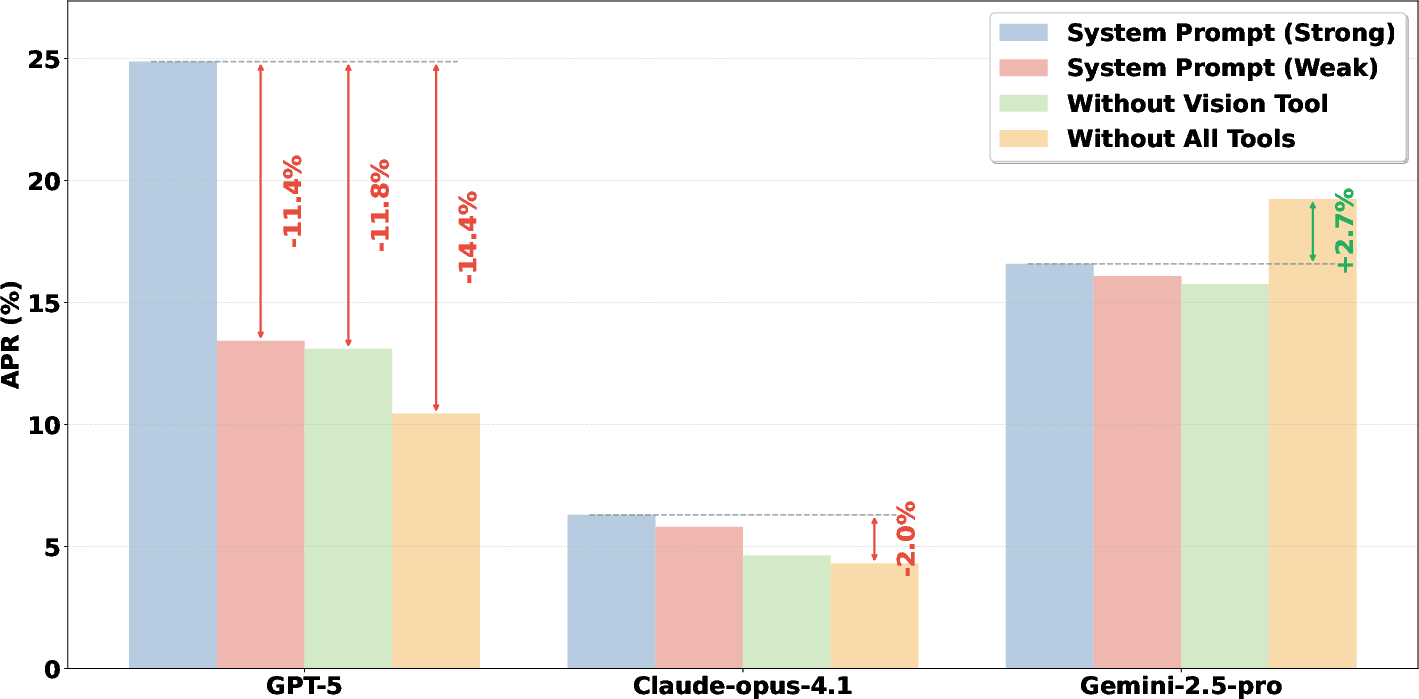
Figure 7: Impact of system prompts and tool availability on APR for representative models, illustrating divergent effects of tool access.
Implications and Future Directions
The IRIS benchmark exposes critical deficiencies in current MLLMs' ability to perform tool-augmented, compositional visual reasoning. The low pass rates, even for state-of-the-art models, indicate that advances in passive visual perception have not translated into robust, interactive visual intelligence. The findings suggest several directions for future research:
- Improved Tool Integration: Models require more effective mechanisms for deciding when and how to invoke tools, particularly for vision-specific manipulations.
- Training on Tool-Augmented Workflows: Supervised and reinforcement learning approaches that explicitly target tool use and compositional reasoning are likely necessary.
- Enhanced Visual Perception: Addressing the high rate of visual perception errors will require advances in both model architecture and training data.
- Evaluation Beyond Static Inputs: Benchmarks must continue to evolve toward dynamic, interactive scenarios that reflect real-world complexity.
Conclusion
IRIS represents a significant step toward rigorous, realistic evaluation of MLLMs under the "think with images" paradigm. The benchmark's design, rubric-based evaluation, and comprehensive analysis provide a robust foundation for diagnosing current limitations and guiding future development. The results make clear that substantial progress is needed before MLLMs can reliably perform tool-enabled, compositional visual reasoning in open-ended, real-world settings.

