CLM: Removing the GPU Memory Barrier for 3D Gaussian Splatting
Abstract: 3D Gaussian Splatting (3DGS) is an increasingly popular novel view synthesis approach due to its fast rendering time, and high-quality output. However, scaling 3DGS to large (or intricate) scenes is challenging due to its large memory requirement, which exceed most GPU's memory capacity. In this paper, we describe CLM, a system that allows 3DGS to render large scenes using a single consumer-grade GPU, e.g., RTX4090. It does so by offloading Gaussians to CPU memory, and loading them into GPU memory only when necessary. To reduce performance and communication overheads, CLM uses a novel offloading strategy that exploits observations about 3DGS's memory access pattern for pipelining, and thus overlap GPU-to-CPU communication, GPU computation and CPU computation. Furthermore, we also exploit observation about the access pattern to reduce communication volume. Our evaluation shows that the resulting implementation can render a large scene that requires 100 million Gaussians on a single RTX4090 and achieve state-of-the-art reconstruction quality.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a system called CLM that helps computers create and train very detailed 3D scenes using a technique called 3D Gaussian Splatting (3DGS)—even when the scene is too big to fit in a graphics card’s memory. CLM lets a single consumer-grade GPU (like an RTX 4090) handle very large or complex scenes by smartly using regular computer memory (CPU memory) and only loading what’s needed into the GPU at the right time.
Key Questions the Paper Answers
Here are the simple goals the paper sets out to achieve:
- How can we train and render very large, detailed 3D scenes using 3DGS on just one GPU?
- Can we avoid buying multiple expensive GPUs or reducing image quality?
- Is there a smart way to move data between the GPU and CPU to keep things fast?
How It Works (Methods and Ideas)
First, a few quick explanations:
- 3D Gaussian Splatting (3DGS): Imagine building a 3D scene out of millions of tiny “colorful blobs” (Gaussians). Each blob has properties like position (where it is), shape and rotation (what it looks like), color, and opacity (how see-through it is). By carefully adjusting these blobs, the computer can render realistic views of the scene from any camera angle.
- GPU vs. CPU memory: Think of the GPU’s memory like a small backpack—fast but limited in space. The CPU’s memory is a big closet—slower but much bigger. The problem is: huge scenes don’t fit in the backpack.
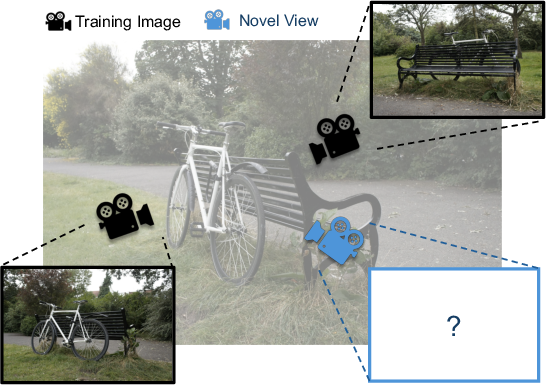
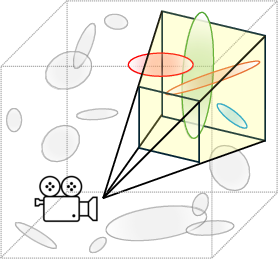
The paper’s key insight: when you render one camera view, you only need a tiny fraction of all the blobs (often less than 1%). Picture shining a flashlight into a dark room—the light cone (called a “camera frustum”) only illuminates part of the room. You don’t need every blob at once.
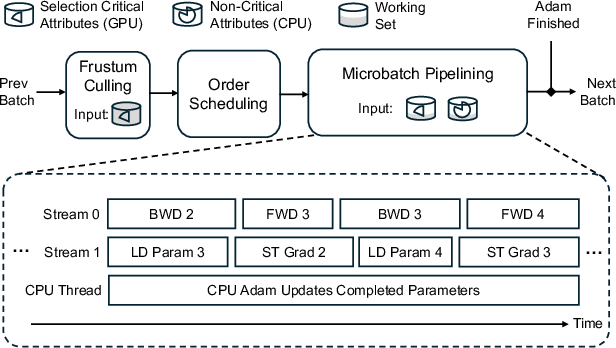
CLM uses that insight in four smart ways:
- Keep only essential info on the GPU: To figure out which blobs are inside the flashlight cone, the GPU only needs position, shape, and rotation. Those take much less memory. CLM keeps these “selection-critical” attributes on the GPU all the time so it can quickly decide which blobs matter for the current view.
- Load only what’s needed: The rest of each blob’s info (like color and opacity) stays in the CPU’s big closet. CLM loads those details for just the blobs inside the current camera frustum.
- Cache and schedule cleverly: Many nearby camera views use overlapping sets of blobs. CLM:
- Caches the overlapping blobs so it doesn’t reload them from the CPU.
- Reorders (schedules) the views to process neighboring areas back-to-back, maximizing overlap and minimizing data transfer. This is like visiting nearby houses in a logical route instead of zig-zagging across town.
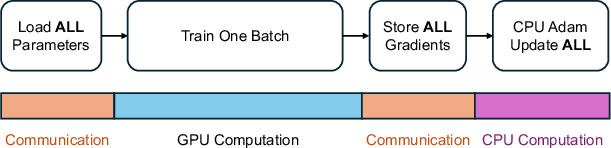
- Pipeline the work like an assembly line: CLM overlaps three things at once:
- Loading blob data (CPU→GPU)
- Rendering and computing gradients on the GPU
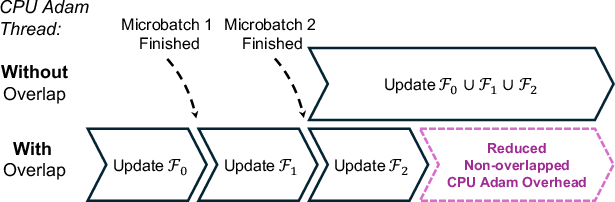
- Updating blob parameters (the “Adam” optimizer) on the CPU
That way, while the GPU is busy rendering one view, the system is already loading the next set of blobs and updating previously used blobs—keeping everything moving smoothly.
In short: CLM turns 3DGS training into a well-coordinated assembly line that only carries the right tools in the backpack, keeps shared tools on the desk (cache), and uses the big closet for storage (CPU memory).
Main Findings and Why They Matter
- Trains much larger models on one GPU:
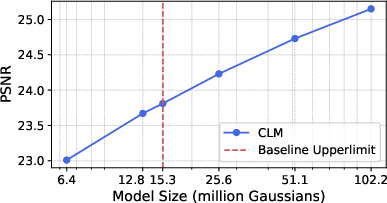
- CLM can train models up to about 6.1 times larger than a strong GPU-only baseline.
- On an RTX 4090, CLM trained a massive scene with 102 million blobs (Gaussians).
- Better image quality from larger scenes:
- On a city-scale dataset (BigCity), CLM achieved a higher PSNR (25.15) than a GPU-only setup (23.93), because it could use more blobs to capture details.
- Performance is still fast:
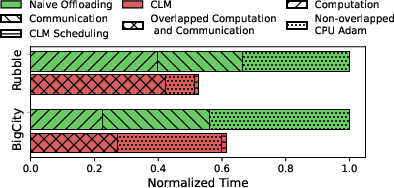
- Even with CPU↔GPU data transfers, CLM reaches 55%–90% of the speed of an enhanced GPU-only baseline on RTX 4090, and 86%–97% on RTX 2080 Ti.
- Compared to a “naive offloading” approach (which just moves everything back and forth), CLM is 1.38–1.92× faster, thanks to caching, smart scheduling, and pipelining.
These results show that you don’t need multiple expensive GPUs or simplified (lower-quality) models to handle big, detailed scenes.
Why This Matters (Implications)
- Affordable large-scale 3D: Artists, researchers, and developers can train and render huge, detailed 3D scenes on a single high-end consumer GPU instead of using multi-GPU setups.
- Better visuals in games, films, and VR: Higher-quality reconstructions mean more realistic environments and smoother camera movement without artifacts.
- Smarter systems beyond 3DGS: The idea of using sparsity (only what you need), caching overlaps, scheduling for locality, and pipelined CPU/GPU cooperation can inspire better designs in other memory-hungry AI and graphics tasks.
In simple terms: CLM shows how to pack smart, not heavy—by carrying just what you need, reusing what you can, and keeping the whole team (GPU and CPU) working together efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper—articulated as concrete, actionable items for future researchers.
- Generalization to inference: Evaluate CLM for real-time or interactive inference (single-view rendering), where microbatch overlap opportunities are limited; quantify latency, stutter, and prefetch strategies along camera trajectories.
- Interaction with adaptive densification and pruning: Measure how frequent Gaussian creation/removal affects offload scheduling, GPU allocator fragmentation, and correctness; quantify reallocation overheads and their impact on throughput and memory fragmentation over long training runs.
- Optimizer correctness under overlap: Provide empirical and numerical evidence that overlapped CPU Adam (early finalization by L_g) produces identical or within-bounds updates vs strictly synchronized GPU-only training; document conditions where ordering-induced numeric differences appear.
- Optimizer diversity and precision: Assess support for optimizers beyond Adam (e.g., SGD, RMSProp, AdaGrad) and mixed-precision (FP16/BF16) optimizer states; quantify memory savings vs convergence behavior and image quality.
- Scheduling cost and scalability: Quantify the computational overhead of TSP-based microbatch ordering (including 2-opt search) per batch, its scalability to large batches (e.g., 64 images), and whether scheduling time ever dominates training at scale.
- Scheduling under evolving sparsity: Investigate how often microbatch schedules must be recomputed as Gaussians move and densification/pruning change S_i; evaluate online and incremental scheduling strategies and their benefits vs static per-epoch schedules.
- Beyond pairwise caching: Explore caching strategies that extend reuse beyond consecutive microbatches (e.g., k-step windows, region-level caches); design eviction policies and measure the trade-off between GPU cache footprint and reduced CPU-GPU bandwidth.
- Selective loading kernel performance characterization: Report achieved PCIe bandwidth (GB/s), GPU occupancy, and cache-line efficiency; compare to cudaMemcpyAsync/UVM across PCIe 3.0/4.0, NVLink, and NUMA configurations; assess portability to non-CUDA backends (e.g., Vulkan) and different OS/IOMMU settings.
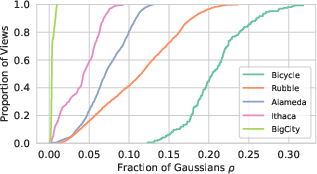
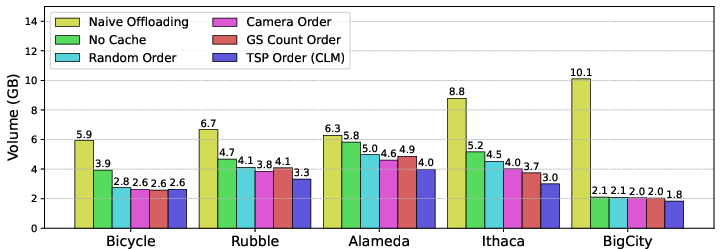
- Communication volume breakdown: Provide detailed attribution of communication volume per attribute type (SH coefficients, opacity, etc.) and per microbatch; model how volume scales with sparsity ρ, batch size, and resolution; identify thresholds where offloading ceases to be beneficial.
- Activation memory vs model state: Develop an analytic memory model that predicts GPU usage (activation, model states, double buffers) as a function of resolution, batch/microbatch size, and sparsity; validate across datasets and use it to guide auto-configuration.
- Hardware robustness and portability: Evaluate CLM on diverse hardware (NVLink-equipped GPUs, AMD GPUs, Apple Metal, integrated memory systems) and multi-socket NUMA CPUs; measure sensitivity to pinned-memory behavior, IOMMU, and ECC.
- Energy and CPU utilization: Measure end-to-end energy consumption and CPU load of overlapped CPU Adam and communication vs GPU-only and multi-GPU baselines; analyze cost-performance (total cost of ownership) implications.
- Quality comparisons to alternative scaling strategies: Benchmark PSNR/SSIM vs multi-GPU systems and pruning/compression approaches across multiple datasets; include time-to-quality curves to contextualize slower throughput vs larger models.
- Limits in low-sparsity regimes: Identify the sparsity (ρ) and resolution regimes where CLM underperforms or becomes counterproductive; develop an automatic switch/tuner between GPU-only and offloaded modes based on measured ρ and activation footprint.
- Selection-critical attributes management: Clarify whether optimizer states and gradients for position/scale/rotation reside on CPU or GPU; detail synchronization and update propagation to ensure GPU-resident copies remain consistent; measure the overhead of keeping selection-critical parameters on GPU while updating them on CPU.
- Memory growth under densification: Quantify the cost (time and fragmentation) of allocating GPU-resident selection-critical attributes for newly densified Gaussians at scale; propose allocator strategies (pooling, compaction) to mitigate fragmentation.
- Frustum culling sensitivity: Study the effect of the 3σ culling threshold on both sparsity and reconstruction quality; explore adaptive thresholds that balance communication savings vs rendering accuracy during different training phases.
- Batch composition strategy: Investigate dataset-level image selection and ordering to maximize spatial locality (e.g., region-first curriculum), not just within-batch TSP; quantify gains vs random sampling and potential impacts on generalization.
- Attribute compression/quantization: Evaluate FP16/BF16 or quantized representations for offloaded attributes (especially SH coefficients) during transfer/storage; measure bandwidth savings and any quality degradation.
- Backpressure and fault handling: Define how CLM behaves under communication stalls or CPU contention (e.g., dropped DMA, delayed CPU Adam); design backpressure mechanisms, recovery strategies, and correctness guarantees.
- Multi-GPU extensions: Explore CLM with multiple GPUs, partitioning Gaussian sets across devices with coordinated CPU memory; study inter-GPU caching, microbatch routing, and communication overlap.
- Applicability beyond 3DGS: Assess generality to other differentiable renderers (mesh-based, NeRF variants) or Gaussian formulations (2D/4D); identify which components (frustum culling, caching, scheduling) transfer and which require redesign.
- Real-time interactive applications: Measure latency and jitter when users navigate a scene; design predictive prefetch and caching along motion paths; study trade-offs between responsiveness and memory/bandwidth usage.
- Missing quantitative details in evaluation: Complete and report the truncated memory breakdown for BigCity and Rubble; add detailed communication metrics, CPU time for Adam, and kernel-level profiling to substantiate claimed overhead reductions.
- Selective loading kernel safety: Document error handling (page faults, DMA errors), data integrity checks, and behavior with ECC/non-ECC memory; provide debugging and verification tooling for correctness.
- Concurrency proof or test suite: Formalize the synchronization between the GPU communication stream and CPU Adam using the signal buffer; provide proofs or deterministic test suites ensuring absence of races and consistent gradient accumulation.
- Scaling laws for quality: Derive and validate how PSNR/SSIM scale with Gaussian count across datasets; provide guidance for choosing model sizes under memory constraints.
- Tiered memory beyond DRAM: Explore hierarchical offloading, e.g., CPU DRAM → CXL-attached memory → SSD, with predictive prefetch; model expected performance bounds and acceptable latency for training and inference.
Practical Applications
Immediate Applications
Below are specific use cases that can be deployed now, directly leveraging the paper’s methods (attribute-wise offloading, pre-rendering frustum culling, microbatch pipelining with Gaussian caching and order optimization, selective loading kernels, and overlapped CPU Adam).
- Single-GPU training of large photorealistic scenes for film/VFX, gaming, and AR/VR content creation
- Sectors: media/entertainment, software
- What emerges: plugins or “CLM mode” for gsplat/Grendel; Blender/Unreal integrations enabling city-scale or highly detailed sets to be trained on one RTX 4090-class workstation
- Workflow: COLMAP → CLM-enabled 3DGS training (microbatch pipeline and caching) → export to engine
- Assumptions/Dependencies: posed images available; scene sparsity and spatial locality; CUDA-capable GPU; pinned CPU memory; enough CPU RAM; PCIe bandwidth suffices
- Cost reduction for cloud-based 3D reconstruction services and startups
- Sectors: cloud/software, fintech (cost optimization)
- What emerges: SaaS “3DGS Trainer” tiers that promise large-scene training with single-GPU instances; billing/pricing tied to CPU RAM instead of multi-GPU
- Workflow: user upload → frustum-aware training → deliver splat-based scene representation
- Assumptions/Dependencies: CPU RAM is abundant; PCIe 4.0/5.0 preferable; predictable sparsity yields high cache reuse
- Urban planning and AEC (architecture, engineering, construction): workstation-scale training of drone-captured city blocks and infrastructure
- Sectors: geospatial, construction, public sector
- What emerges: desktop pipeline for photorealistic digital twins; GIS integration with splat-based renderers
- Workflow: aerial capture → COLMAP → CLM 3DGS → GIS/digital-twin systems
- Assumptions/Dependencies: reliable pose estimation; spatial locality; adequate CPU RAM; non-real-time training acceptable
- Robotics and autonomous systems: offline mapping from large multi-session datasets on a single GPU
- Sectors: robotics, automotive
- What emerges: improved map quality with larger Gaussian budgets without cluster hardware; “CLM-based mapping” mode in SLAM/post-processing suites
- Workflow: SLAM for poses → CLM training → downstream navigation/simulation
- Assumptions/Dependencies: offline training; sufficient PCIe bandwidth; predictable frustum overlaps across views
- Real estate and e-commerce: high-fidelity virtual walkthroughs trained on consumer hardware
- Sectors: real estate, retail
- What emerges: desktop tools for listing creators; pipeline templates for large interiors with detailed geometry and materials
- Workflow: photo capture → CLM-enabled 3DGS → hosted viewer
- Assumptions/Dependencies: adequate capture coverage; GPU drivers (CUDA); CPU RAM availability
- Academic reproducibility and scaling of 3DGS research
- Sectors: academia
- What emerges: open-source CLM modules; benchmarks for large-scene training on single GPUs; classroom assignments using microbatch scheduling and caching
- Assumptions/Dependencies: integration with popular kernels (gsplat); reproducible datasets; manageable TSP-based scheduling compute
- Immediate performance uplift in GPU-only pipelines via pre-rendering frustum culling
- Sectors: software/graphics, HPC
- What emerges: kernel-level optimization that avoids unnecessary work and activation storage even without offloading
- Workflow: frustum culling → rasterization only on in-frustum Gaussians
- Assumptions/Dependencies: adoption in existing renderer backends; minimal refactoring required
- Indie studios and small labs: democratized access to city-scale training
- Sectors: media/entertainment, education
- What emerges: training playbooks for large models with limited hardware; community datasets grown in size and complexity
- Assumptions/Dependencies: stable CUDA drivers; single high-end consumer GPU; large CPU RAM
- Energy and cost efficiency for data centers
- Sectors: energy, cloud ops
- What emerges: policies/workflows that prioritize single-GPU, CPU-RAM-enabled training for splat-based NVS workloads
- Assumptions/Dependencies: ops readiness for pinned memory; monitoring for CPU-GPU bandwidth utilization
- Developer tooling: microbatch order optimizers and selective-loading kernel libraries
- Sectors: software tools
- What emerges: reusable libraries for TSP-based microbatch scheduling; CUDA kernels for sparse, contiguous, cache-line-aligned loading and gradient offloading
- Assumptions/Dependencies: dataset preprocessing to compute in-frustum sets; pinned memory available; typical sparsity (<1–2% per view for large scenes)
Long-Term Applications
These opportunities require further research, scaling, or development (e.g., latency optimization, hardware co-design, generalized frameworks).
- Real-time exploration of city-scale scenes on single GPUs for AR/VR and digital twin platforms
- Sectors: AR/VR, geospatial, smart cities
- What could emerge: interactive view synthesis with streaming microbatch-like caching; predictive frustum scheduling for user navigation
- Dependencies: low-latency kernels; faster CPU-GPU interconnects (NVLink, PCIe 5.0, CXL); inference-optimized splatting
- On-device training/incremental updates for robots and autonomous vehicles
- Sectors: robotics, automotive
- What could emerge: incremental CLM variants that update local splat maps online; memory-aware scheduling on embedded GPUs
- Dependencies: battery/thermal constraints; mobile interconnects; robust out-of-order gradient accumulation and consistent optimizers
- Generalized sparse offloading frameworks for other ML/graphics workloads
- Sectors: software/ML, graphics
- What could emerge: “Sparse Memory Offload SDK” applying attribute-wise offload and microbatch pipelining to point-based rendering, neural fields, or sparse transformers (e.g., KV cache management)
- Dependencies: identifiable selection-critical attributes; predictable sparsity patterns; backend support (CUDA/Vulkan)
- Hardware and OS co-design for selective memory offload
- Sectors: semiconductors, systems software
- What could emerge: GPU driver support for fine-grained DMA of structured tensors; memory pooling across CPU/GPU via CXL; cache-coherent offload-aware architectures
- Dependencies: vendor adoption; standardization; ISA and driver changes
- Managed cloud services for “single-GPU city-scale reconstruction”
- Sectors: cloud, geospatial
- What could emerge: turnkey pipelines that ingest aerial/ground imagery, auto-compute frustum overlaps, and schedule training to minimize communication
- Dependencies: dataset governance; compliance with urban imagery regulations; robust scheduling across diverse scenes
- Standards and benchmarks for memory-efficient NVS
- Sectors: academia, policy/standards
- What could emerge: community benchmarks that include sparsity profiles; guidelines for reporting throughput vs. quality (PSNR) under constrained GPU memory
- Dependencies: community consortium; shared datasets; reproducible pipelines
- Consumer-grade personal digital twins
- Sectors: consumer software, smart home
- What could emerge: apps that convert smartphone captures into detailed home/workplace twins trained locally; interactive design and planning tools
- Dependencies: easy UX; automated pose estimation; long training times tolerable or offloaded to background
- Urban planning workflows and procurement policies emphasizing low-carbon, low-GPU training
- Sectors: public sector, sustainability
- What could emerge: guidelines prioritizing single-GPU, CPU-assisted training for city-scale twins; grant programs enabling small labs to participate
- Dependencies: policy adoption; lifecycle emissions accounting; training reproducibility
- Rapid reconstruction for disaster response and defense
- Sectors: public safety, defense
- What could emerge: field-deployable kits for fast scene reconstruction without clusters; preplanned microbatch schedules for typical flight paths
- Dependencies: rugged hardware; secure data handling; robust performance under poor sparsity (e.g., cluttered indoor scenes)
- Game engine integration for live environment updates from scans
- Sectors: gaming/engines
- What could emerge: runtime import of splat-based recon; memory-aware streaming loaders; hybrid splat+mesh pipelines
- Dependencies: engine APIs for splats; conversion tools; latency constraints for dynamic updates
Notes on Feasibility Across Applications
- The approach assumes high sparsity and spatial locality per view; scenes with wide FOVs or crowded interiors may reduce benefits.
- PCIe/NVLink bandwidth and pinned memory quality are critical; older interconnects may cap throughput or increase latency.
- Selection-critical attributes must fit in GPU memory; exceedingly large scenes could still strain VRAM for positions/rotation/scale.
- Quality improvements rely on being able to train with more Gaussians; capture quality and accurate camera poses remain bottlenecks.
- The ordering benefits depend on computing in-frustum sets and effective TSP-like schedules; scheduling overhead must be controlled.
- Current implementation is CUDA-centric; Vulkan or other backends need compatible kernels and driver support.
Glossary
- 1F1B pipelining: A pipeline scheduling technique that overlaps one forward pass with one backward pass across stages to improve utilization. "analogously to the 1f1b pipelining method for training neural networks described in \cite{1f1b}"
- 3D Gaussian Splatting (3DGS): A differentiable rendering approach that represents scenes with many 3D Gaussians for fast, high-quality novel view synthesis. "3D Gaussian Splatting (3DGS) is an increasingly popular novel view synthesis approach"
- 3σ: A three-standard-deviation threshold commonly used to bound Gaussian contributions during culling. "within $3$ standard deviations ()"
- Adam optimizer: A stochastic optimization algorithm using adaptive estimates of first and second moments to update parameters. "the Adam optimizer~\cite{kingma2015adam} is run to update Gaussian parameters."
- Adaptive densification: A procedure that adds or removes Gaussians during training to focus capacity on high-error regions. "Periodically, adaptive densification~\cite{3dgs, hierarchicalgaussians, mcmc3dgs} is performed"
- Anisotropic 3D Gaussians: Gaussian primitives whose covariance produces direction-dependent spread, modeling geometry and appearance. "a large number of anisotropic 3D Gaussians"
- Backpropagation: The reverse-mode automatic differentiation process used to compute gradients for parameter updates. "backpropagation is run to update the Gaussian attributes."
- COLMAP: A structure-from-motion and multi-view stereo pipeline used to generate input point clouds for initialization. "using a user-provided point cloud generated by COLMAP~\cite{colmap}"
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "Our current implementation of CLM is built on CUDA"
- CUDA events: Synchronization primitives in CUDA used to order operations across streams. "We add CUDA events to correctly synchronize operations across streams"
- CUDA streams: Independent command queues in CUDA enabling concurrent kernel execution and data transfers. "we employ two CUDA streams: one for computation, and the other for communication."
- Differentiable rendering: Rendering where the output image is differentiable with respect to scene parameters, enabling gradient-based learning. "3DGS' differentiable rendering allows it to use gradient-based optimization based on minibatch SGD."
- Double-buffering: A memory technique using two buffers to safely overlap computation and communication. "CLM uses double-buffering to ensure that communication and computation can be safely overlapped."
- Ellipsoid: The geometric shape induced by a Gaussian’s covariance (scale and rotation) used in frustum intersection tests. "the Gaussian's ellipsoid (which is derived from its scale and rotation)"
- Frustum culling: The process of excluding primitives outside the camera frustum to determine which Gaussians are used per view. "the frustum culling step is run on the GPU"
- Gaussian caching: Reusing Gaussians across consecutive microbatches to reduce redundant CPU–GPU transfers. "using Gaussian Caching (\S\ref{sec:design:gaussian-caching})"
- Gradient accumulation: Summing gradients over multiple microbatches before an optimizer step to reduce memory usage. "with gradient accumulation to reduce activation memory usage."
- Greedy heuristic: A locally optimal choice strategy used within a search to quickly approximate an effective schedule. "stochastic local search with a greedy heuristic"
- GSplat: A set of optimized CUDA kernels for Gaussian splatting used as the rendering backbone. "We use GSplat's CUDA kernels"
- Hamiltonian path: A path visiting each node exactly once; used here to describe an optimal microbatch ordering objective. "shortest Hamiltonian path through this graph"
- Microbatch pipelining: Executing smaller per-image units in a pipeline to overlap communication and computation across steps. "microbatch pipelining allows CLM to overlap communication for one microbatch with the computation for another"
- Minibatch SGD: Stochastic gradient descent that updates parameters using gradients computed on batches of samples. "based on minibatch SGD."
- Novel View Synthesis (NVS): Rendering an image of a scene from a previously unseen viewpoint using learned representations. "Novel View Synthesis (NVS) is the task of rendering an image of a 3D scene from a previously unseen viewpoint."
- Optimizer state: Auxiliary per-parameter values (e.g., moments in Adam) maintained by the optimizer during training. "optimizer state"
- PCIe: The peripheral component interconnect express bus used for high-speed CPU–GPU data transfer. "loads (over PCIe) the in-frustum Gaussian parameters"
- Peak Signal-to-Noise Ratio (PSNR): A metric measuring reconstruction quality of rendered images against ground truth; higher is better. "evaluate the reconstruction quality using peak signal-to-noise ratio (PSNR)"
- Pinned memory: Page-locked host memory enabling higher-throughput DMA transfers between CPU and GPU. "stores offloaded Gaussian attributes in pinned CPU memory"
- Rasterization kernels: GPU kernels that project and blend Gaussian primitives onto the image plane during rendering. "incorporated the rasterization kernels of gsplat~\cite{gsplat} into Grendel."
- Spherical harmonics: Basis functions used to represent view-dependent color components of Gaussians. "determined by the spherical harmonics"
- Spatial locality: The tendency for nearby views to access overlapping sets of Gaussians, exploitable for scheduling and caching. "The training process exhibits spatial locality"
- Stochastic local search: A randomized optimization method that explores neighbors to improve a solution. "stochastic local search with a greedy heuristic"
- Traveling Salesman Problem (TSP): A combinatorial optimization problem used to model microbatch ordering to maximize overlap. "formulating the scheduling problem as an instance of the Traveling Salesman Problem (TSP)~\cite{tsp}"
- Unified Virtual Memory: A memory management system that transparently migrates pages between CPU and GPU, often with overhead. "use a technology such as Unified Virtual Memory that uses CPU memory to augment GPU memory"
- Vulkan: A low-overhead cross-platform graphics and compute API; an alternative backend for implementation. "can be ported to the Vulkan platform~\cite{vulkan}"
- Zero-Offload: A technique that offloads gradients and optimizer state/computation to the CPU to scale model training. "Work on deep-learning, e.g. Zero-Offload~\cite{zerooffload}, has shown"
Collections
Sign up for free to add this paper to one or more collections.