- The paper introduces a novel host offloading strategy for 3D Gaussian Splatting that reduces GPU memory usage by 3.3×–5.6×.
- Selective offloading and deferred optimizer updates overcome CPU bottlenecks in frustum culling and optimizer operations.
- System-level optimizations enable training with tens of millions of Gaussians, directly enhancing PSNR, SSIM, and LPIPS metrics.
GS-Scale: Host Offloading for Scalable 3D Gaussian Splatting Training
Introduction and Motivation
The paper introduces GS-Scale, a system-level solution for scalable 3D Gaussian Splatting (3DGS) training that leverages host (CPU) offloading to overcome GPU memory bottlenecks. 3DGS has become a state-of-the-art method for novel view synthesis, representing scenes with millions of trainable 3D Gaussian primitives. However, the explicit nature of this representation leads to substantial memory requirements, especially as scene complexity and the number of Gaussians increase. The memory footprint is dominated by Gaussian parameters, gradients, and optimizer states, which can quickly exceed the capacity of consumer-grade GPUs, limiting both scalability and rendering quality.
GS-Scale addresses this by storing all Gaussians and optimizer states in host memory, transferring only the necessary subset to the GPU for each forward and backward pass. This approach exploits the sparsity of the training workload, where only a small fraction of Gaussians are active per iteration. The system is further optimized to mitigate the performance penalties of host offloading, specifically targeting frustum culling and optimizer update bottlenecks.

Figure 1: Comparison of the maximum rendering quality achievable in 3DGS training using a GPU-only system and GS-Scale. Training is conducted on RTX 4070 Mobile GPU with Rubble scene. Higher is better for PSNR and SSIM, lower is better for LPIPS.
3D Gaussian Splatting Training Pipeline
3DGS training begins with initialization from a 3D point cloud, followed by iterative projection, frustum culling, sorting, blending, loss computation, backpropagation, and optimizer updates. Densification is periodically performed to adaptively control Gaussian density, splitting or pruning Gaussians based on accumulated gradients and opacity.

Figure 2: Overview of 3D Gaussian Splatting Training Pipeline.
The explicit representation in 3DGS leads to a direct relationship between the number of Gaussians and rendering quality. Increasing the number of Gaussians improves PSNR and SSIM, and reduces LPIPS, but also exacerbates memory pressure.
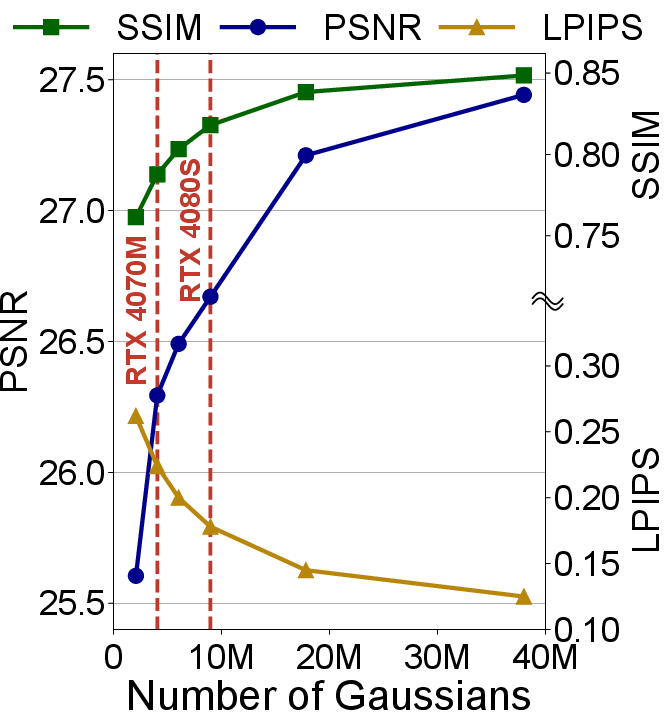
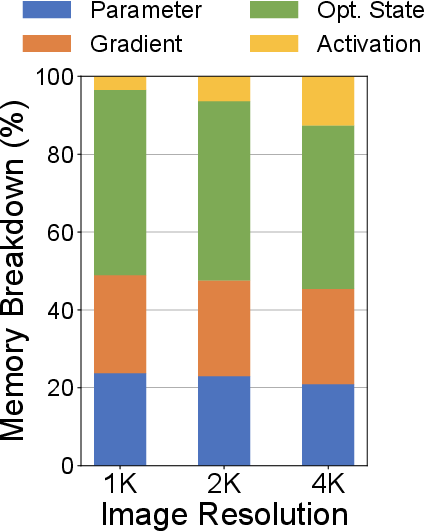
Figure 3: Effect of the Number of Gaussians on Rendering Quality
Host Offloading: Opportunities and Challenges
Profiling reveals that only a small subset (∼8.3%) of Gaussians are active per training iteration, suggesting significant memory savings by offloading inactive parameters to host memory. However, this introduces three main challenges:
- Frustum culling on CPU is compute-bound and slow.
- Optimizer updates on CPU are memory-bound and inefficient, especially for Adam, which updates all states regardless of gradient activity.
- Peak memory usage is dictated by the most demanding training image, limiting the effectiveness of offloading.
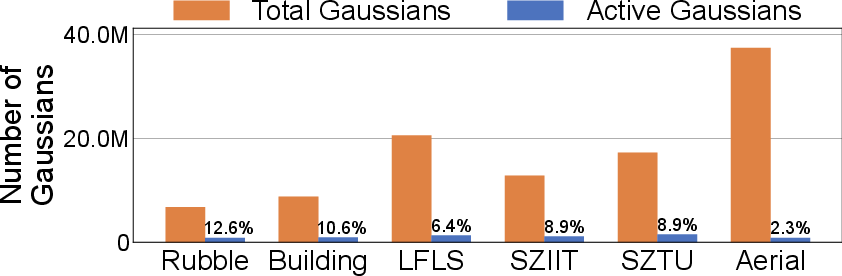
Figure 4: Average Number of Gaussians Used while Training Compared to Total Gaussians.
GS-Scale System Design
Baseline Host Offloading
The baseline GS-Scale system offloads all Gaussian parameters and optimizer states to host memory, transferring only the required subset to the GPU for each iteration. While this reduces GPU memory usage, it incurs a 4× slowdown due to CPU bottlenecks in frustum culling and optimizer updates.
Figure 5: Baseline GS-Scale with Host Offloading.
Figure 6: Training Iteration in Baseline GS-Scale.
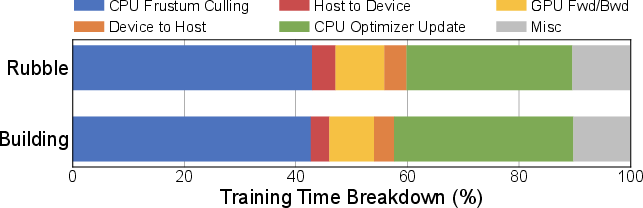
Figure 7: Training Time Breakdown of Baseline GS-Scale Measured on RTX 4070 Mobile GPU.
System-Level Optimizations
GS-Scale introduces three key optimizations:
- Selective Offloading: Only geometric attributes (mean, scale, quaternion) are kept on the GPU for fast frustum culling, incurring a modest 17% memory overhead but dramatically accelerating culling.
- Parameter Forwarding: Early updates of only the parameters needed for the next iteration enable pipelined execution of CPU optimizer updates and GPU computation, breaking the data dependency and minimizing GPU idle time.
- Deferred Optimizer Update: Updates for parameters with zero gradients are deferred, with restoration performed only when gradients become nonzero or a counter saturates. This reduces memory accesses proportional to the ratio of active to total Gaussians.
Figure 8: Nth Training Iteration in GS-Scale with Selective Offloading and Parameter Forwarding.
Figure 9: Execution Timeline of GPU-Only, Baseline GS-Scale, and GS-Scale with optimizations. H2D/D2H denote Host to Device transfers, M.S.Q. is mean/scale/quaternion.
The deferred optimizer update is implemented via a 4-bit counter per Gaussian, with restoration using precomputed scaling factors for momentum and variance. The pseudocode demonstrates efficient memory access patterns and minimal computational overhead.
GS-Scale achieves 3.3×–5.6× reduction in peak GPU memory usage across diverse datasets and platforms. This enables training with substantially more Gaussians under the same memory budget, directly improving rendering quality metrics (PSNR, SSIM, LPIPS).
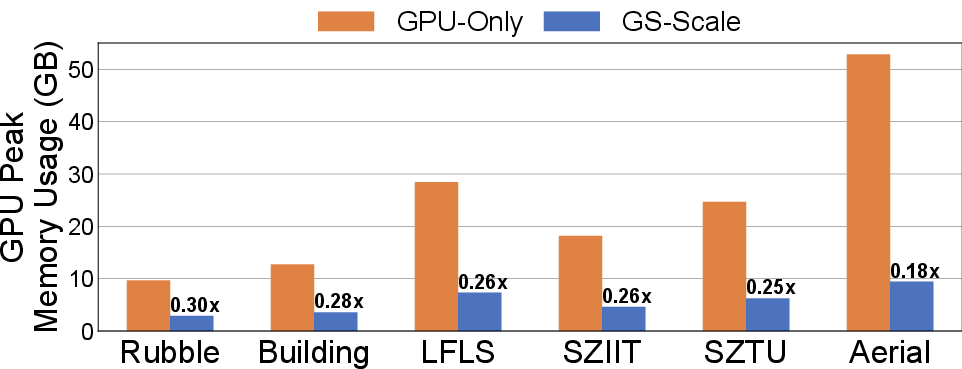
Figure 10: Peak GPU Memory Usage Savings with GS-Scale.
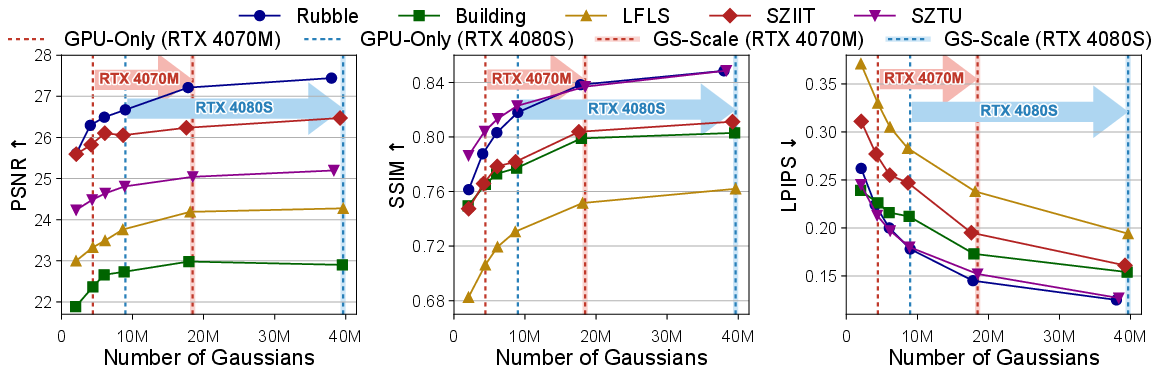
Figure 11: Evaluation of GS-Scale's Rendering Quality and Scalability Across Gaussian Scales.
GS-Scale maintains training throughput comparable to GPU-only systems, with geomean throughput ratios of 1.22× (laptop) and 0.84× (desktop) relative to GPU-only, excluding OOM cases. The optimizations yield a 4.5× speedup over the baseline host-offloading system.
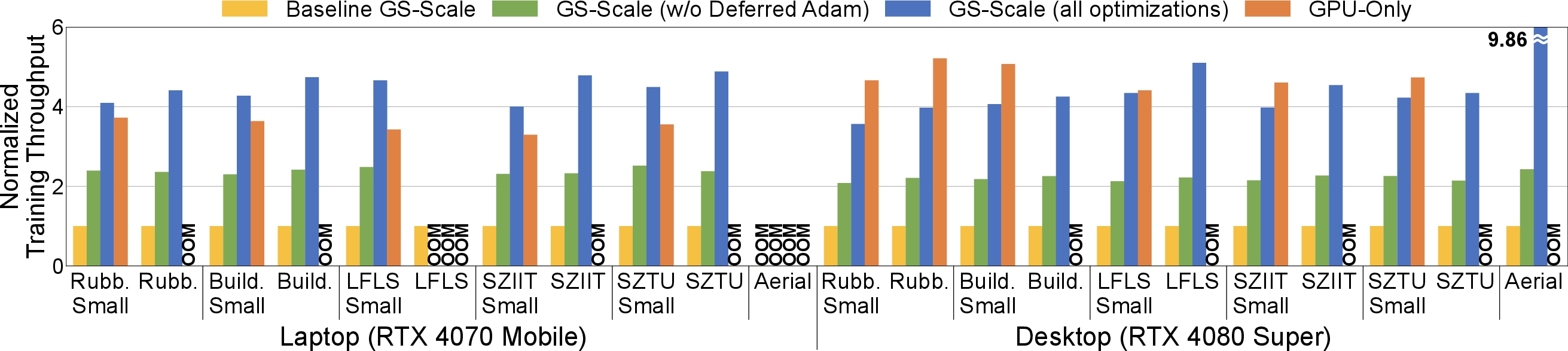
Figure 12: Training Throughput Normalized to Baseline GS-Scale.
GS-Scale enables scaling from 4M to 18M Gaussians on RTX 4070 Mobile and from 9M to 40M on RTX 4080 Super, yielding up to 35% LPIPS improvement.
Sensitivity and Deployment Considerations
GS-Scale's memory savings and throughput are sensitive to the mem_limit threshold, GPU memory bandwidth, and image resolution. Lower mem_limit increases memory savings at the cost of throughput due to additional frustum culling and gradient accumulation. Higher image resolutions reduce relative memory savings but increase throughput due to longer GPU computation, allowing more effective pipelining.
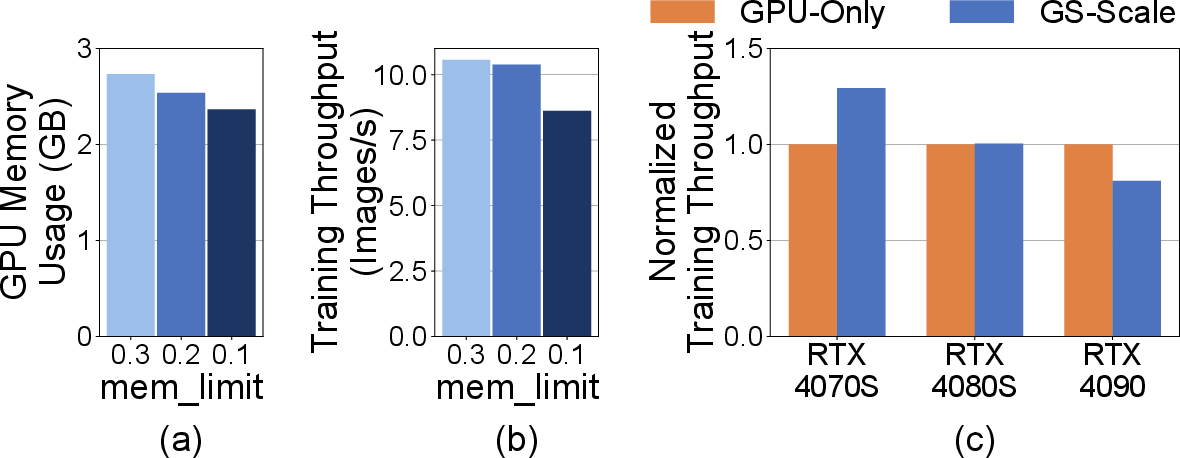
Figure 13: (a), (b) Sensitivity to mem_limit on Rubble scene. (c) Sensitivity to GPU on LFLS scene. Desktop is used.
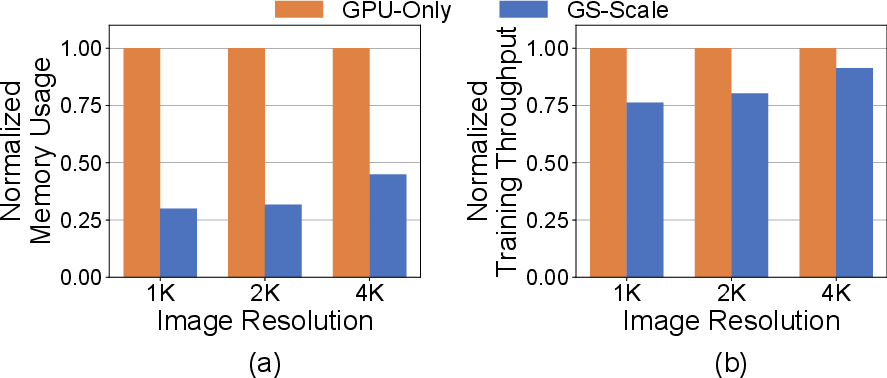
Figure 14: Impact of Image Resolution on Memory Usage and Throughput on Desktop for Rubble Scene.
GS-Scale is implemented on top of gsplat v1.5.0, with pipelined CPU-GPU execution via Python threading and deferred optimizer update as a custom C++ PyTorch extension with OpenMP. The system is compatible with commodity hardware and can be deployed on laptops, desktops, and servers.
Theoretical and Practical Implications
GS-Scale demonstrates that system-level host offloading, combined with targeted optimizations, can unlock large-scale 3DGS training without algorithmic modifications. This preserves the original training pipeline, avoiding the compromises of divide-and-conquer approaches. The deferred optimizer update is theoretically sound for momentum-based optimizers, with negligible impact on training quality as confirmed by empirical results.
The approach is generalizable to other explicit scene representations and can be extended to distributed or multi-node settings. The system-level perspective complements algorithmic advances, highlighting the importance of memory management and workload sparsity in scaling differentiable rendering methods.
Future Directions
Potential future developments include:
- Extending GS-Scale to multi-GPU and distributed environments, leveraging host offloading for inter-node memory management.
- Adapting the deferred optimizer update to other optimizers and scene representations.
- Integrating hardware accelerators for further speedup in frustum culling and optimizer updates.
- Exploring dynamic mem_limit adjustment and adaptive image splitting for optimal memory-throughput trade-offs.
Conclusion
GS-Scale provides a robust, memory-efficient, and scalable solution for 3D Gaussian Splatting training on commodity GPUs. By offloading inactive parameters to host memory and optimizing bottlenecks in frustum culling and optimizer updates, GS-Scale enables training with significantly more Gaussians, directly improving rendering quality. The system maintains high throughput and is compatible with existing frameworks, offering a practical path toward large-scale, high-fidelity 3D scene reconstruction.