- The paper presents a diffusion policy framework that selectively integrates noisy human demonstrations with limited robot data to enhance visuomotor policy training.
- It employs unified state–action representations and a noise-based action classifier to align human and robot action distributions effectively.
- Experimental results indicate a 16% average success rate improvement over baselines across challenging tasks such as pick-and-place and bottle upright.
X-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations
Introduction and Motivation
The paper introduces X-Diffusion, a framework for leveraging large-scale human demonstrations alongside limited robot teleoperation data to train robust visuomotor policies via diffusion models. Standard imitation learning relies heavily on costly robot data, while human videos are abundant but mismatched in embodiment and kinematics. Direct retargeting of human hand motion to robot actions often results in infeasible or suboptimal behaviors, particularly in fine-grained manipulation tasks. X-Diffusion addresses this by judiciously incorporating human action data during policy training, utilizing a noise-based indistinguishability criterion derived from the forward diffusion process and a trained action-classifier.
Unified State–Action Representation
Policy input is unified across humans and robots using segmentation masks of relevant objects (Grounded-SAM2) and 3D poses of hand/end-effector (HaMeR for humans). Proprioceptive data and segmented keypoint renderings are concatenated for each timestep. Actions are encoded as the next-step proprioception. This facilitates alignment of cross-embodiment trajectories despite differences in raw sensor modality.
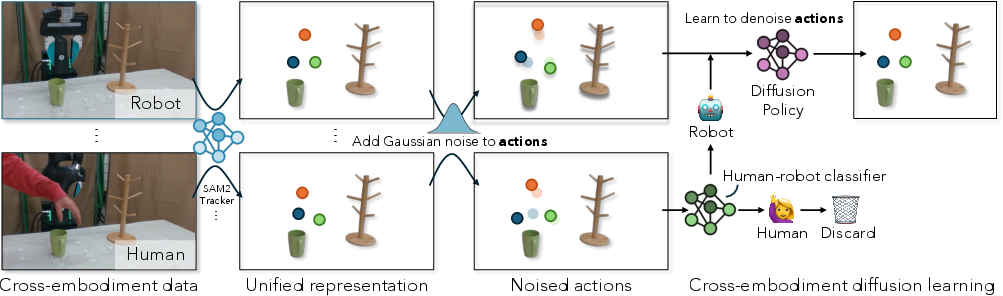
Figure 1: Pipeline for unifying state and action representations with object segmentation and pose retargeting.
Algorithmic Framework
Forward Diffusion and Cross-Embodiment Equivalence
Diffusion policies iteratively denoise sequences from Gaussian noise. As noise is incrementally added to actions, low-level embodiment-specific cues dissipate, leaving only coarse task structure. The distributions of highly noised human and robot actions converge, making them indistinguishable. Formally, the minimum indistinguishability step k⋆ is determined per action sequence when the classifier outputs a robot likelihood ≥0.5.
Action-Source Classifier
A binary classifier cθ is trained to discriminate noised action sequences (parameterized by noise step k, action Atk, and state st) as robot or human origin. Balanced sampling prevents bias due to dataset size disparities. The classifier identifies which human actions under what noise levels are sufficiently close to possible robot actions.
Policy Training with Selective Human Data Integration
The policy loss is conditioned: robot actions supervise the denoising process at all noise levels; human actions are only included for loss gradients at k≥k⋆ per sample. This means precise supervision is retained for feasible human data, while infeasible actions can still inform the policy at highly abstracted (i.e., heavily noised) stages—enriching state coverage without forcing the model to learn physically impossible executions.
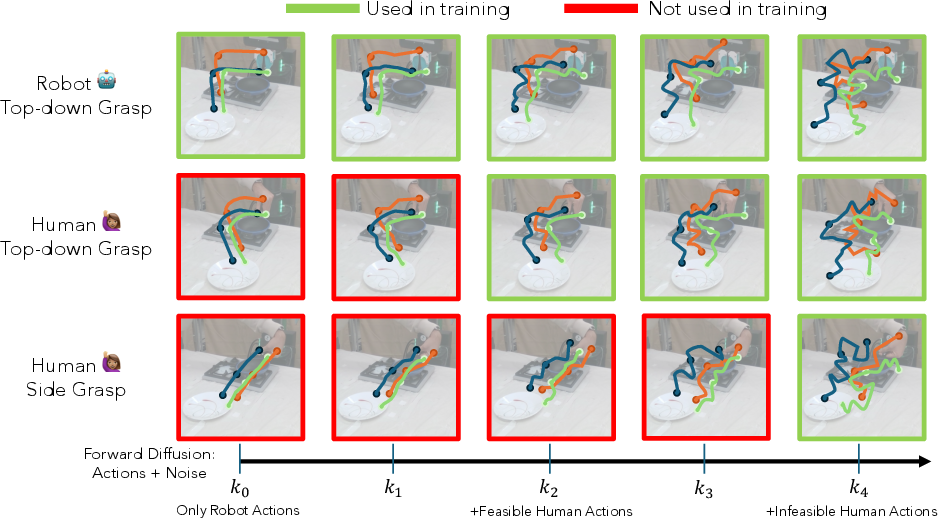
Figure 2: Visualization of classifier decisions across diffusion steps; only sufficiently noisy, embodiment-agnostic human actions are leveraged for policy updates.
Experimental Evaluation
Setup
The evaluation covers five manipulation tasks (pick-and-place, non-prehensile, precise insertion, reorientation) with 5 robot and 100 human demonstrations per task, using a 7-DOF Franka Emika Panda arm. Input representations and retargeting protocols are detailed, removing the necessity for laborious manual annotation.
Comparative Baselines
Benchmarks include:
- Diffusion Policy (robot-only),
- Point Policy (keypoint-based cross-training),
- Motion Tracks (RGB-based cross-training),
- DemoDiffusion (diffusion-based prompting, no cross-embodiment policy training).
Key Results
- X-Diffusion outperforms all baselines, with a 16% average increase in success rates across tasks. Unlike naive co-training (Point Policy, Motion Tracks), which often degrades robot performance by learning infeasible strategies, X-Diffusion adaptively incorporates only embodiment-feasible supervision.
- Also surpasses policies trained strictly on manually filtered feasible human trajectories, demonstrating the utility of integrating even noisy/partial guidance from infeasible actions at high noise (abstract) levels.
- On tasks with high human–robot execution overlap (e.g., Push Plate), classifier-driven leveraging of human data yields substantial gains. Conversely, for tasks prone to retargeting errors (e.g., Bottle Upright), the policy excludes low-quality human data, mitigating performance losses observed in naive cross-training.
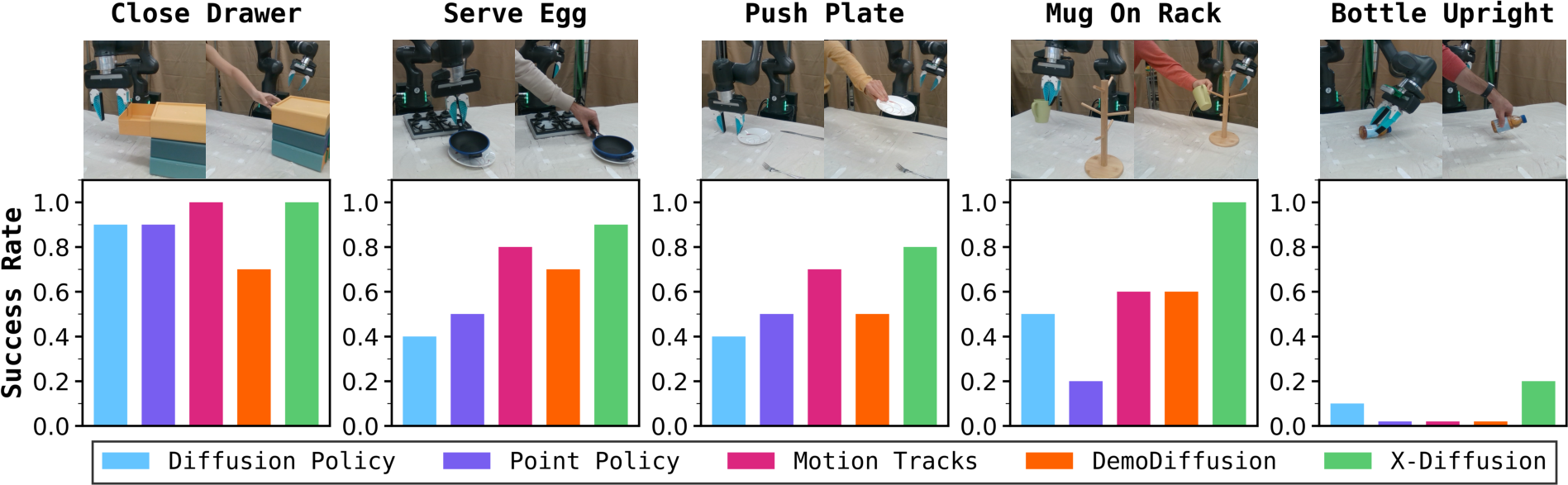
Figure 3: Task success rate comparison across five manipulation tasks and multiple baseline methods; X-Diffusion achieves highest performance.
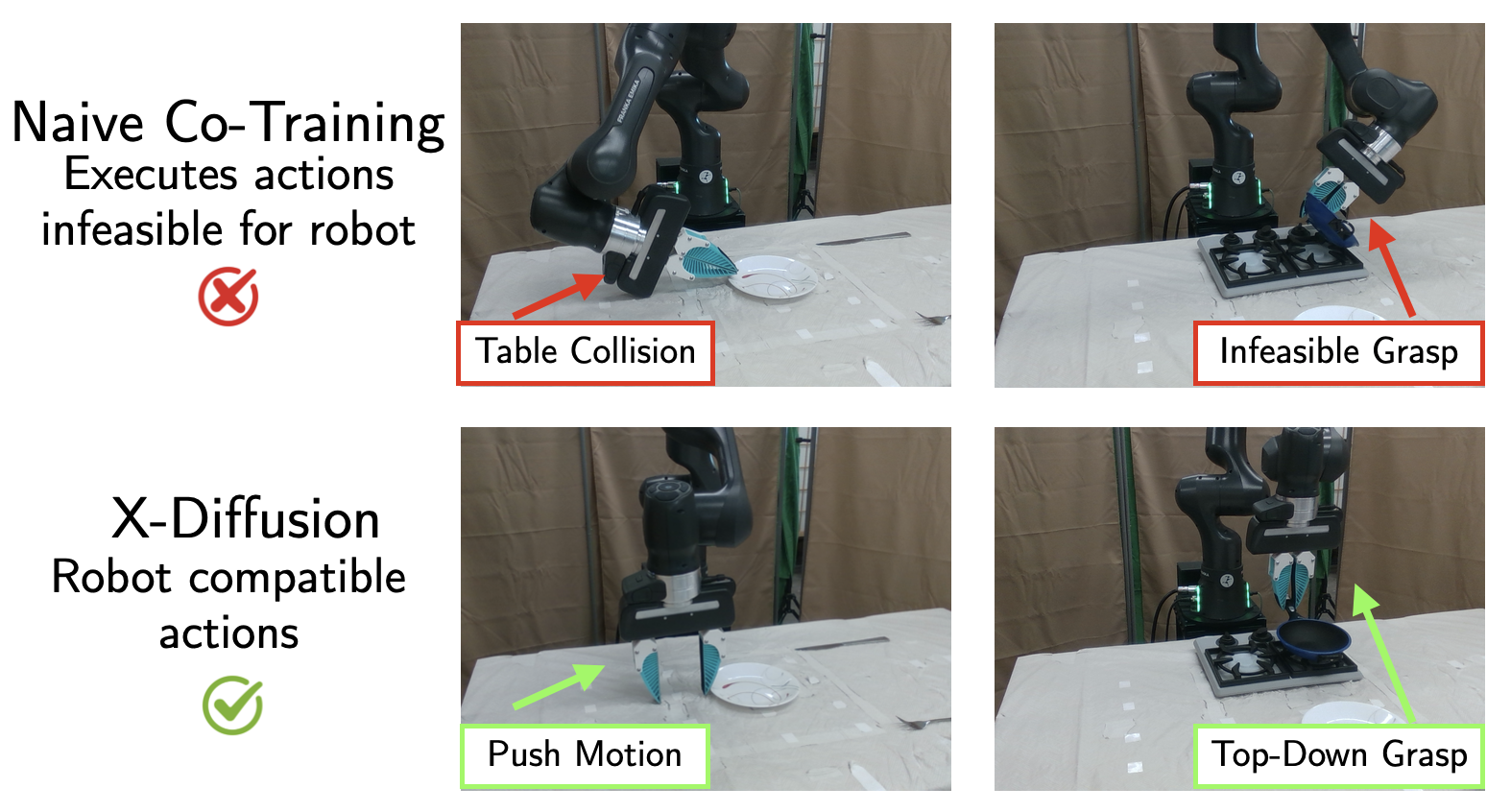
Figure 4: Naive co-training leads to learned actions that are infeasible for robots due to mismatched physical constraints.
Data Quality and Task Variance Analysis
Classifier predictions vary by task-specific overlap of human and robot action distributions throughout noise addition. Tasks with greater distributional intersection benefit more from human data. The classifier's selectivity functionally adapts the training procedure on a per-task basis, clarifying when cross-embodiment demonstration integration is beneficial.
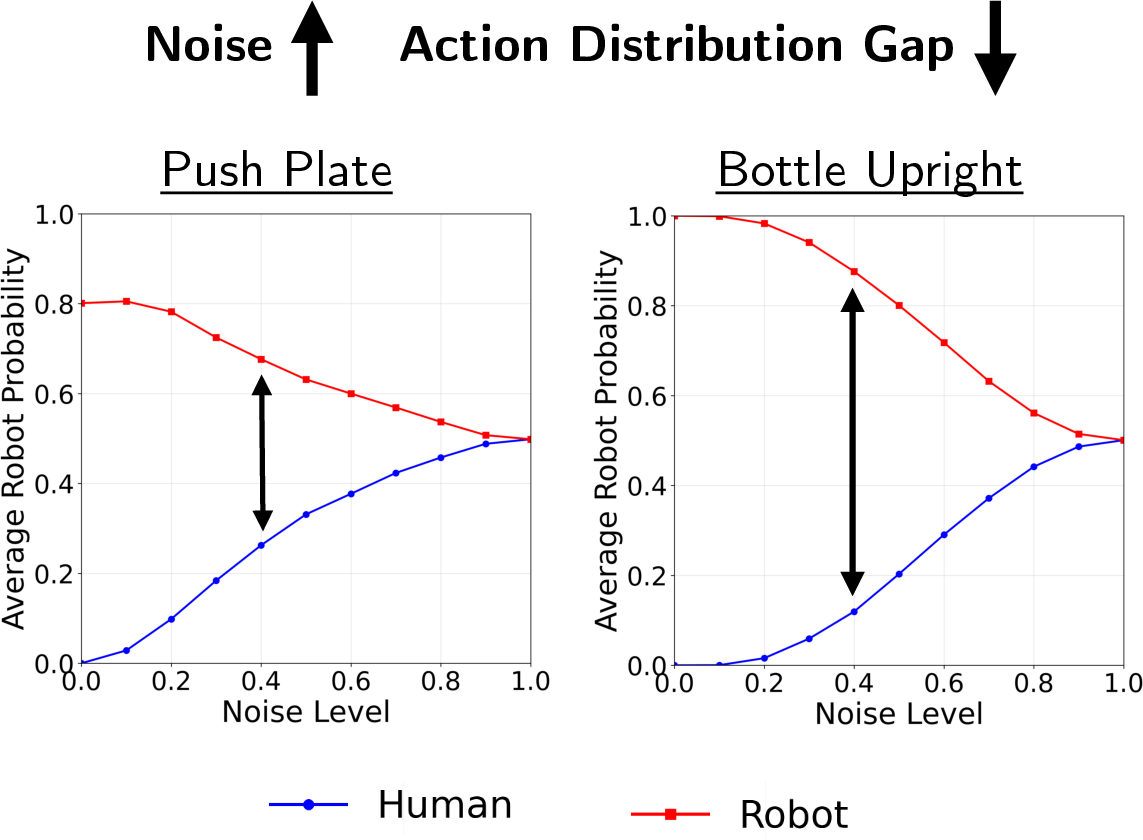
Figure 5: Evolution of classifier robot probability over diffusion steps, illustrating task-dependent alignment of human and robot action distributions.
Implementation Considerations
- Classifier Architecture: Requires balanced batch construction, supports state/context-aware discrimination.
- Diffusion Policy: Employs UNet model backbone with ResNet50 CNN visual encoder, prediction/action horizons set to 8, trained with 100 diffusion timesteps.
- Data Retargeting: Retargeting efficacy is critical; inaccurate 3D keypoint estimation can pollute the feasible human action pool, further justifying selective integration.
Theoretical and Practical Implications
X-Diffusion decouples low-level motion feasibility from high-level task structure, enabling scalable robot learning from uncurated human video datasets. By embracing noisy abstraction, it avoids overfitting to suboptimal or physically infeasible action sequences. The approach theoretically justifies gradient propagation only when action distributions are sufficiently aligned, which may generalize to other generative-model-based policy paradigms.
Practically, this framework provides a robust recipe for leveraging internet-scale human data in robotics without extensive manual curation or simulator-based reward engineering. It is expected to facilitate the development of generalist robot agents capable of adapting to new manipulations with minimal robot-specific demonstrations, contingent on accurate classifier calibration and retargeting pipeline reliability.
Conclusion
X-Diffusion presents a principled framework for robot policy co-training with cross-embodiment human data, maximally extracting informative signals while mitigating physical execution mismatches. The classifier-driven selective integration achieves significant gains over both robot-only and naive cross-training approaches, robustly translating high-level manipulation strategies to physically grounded robot actions. Future work should investigate scaling to unstructured video, classifier generalization, and extension to multi-modal demonstration sources.