- The paper introduces a dual-agent constitutional AI framework that statistically outperforms human interviews in transcript entropy, vocabulary richness, and semantic coherence.
- It employs a modular design combining a minimalist React.js interface with ethical supervision and natural language generation for controlled, sensitive data elicitation.
- The platform demonstrates practical applications across public opinion polling, journalism, and educational assessments, validated by robust causal analyses and empirical metrics.
Dual-Agent Constitutional AI: MimiTalk as a Paradigm Shift in Qualitative Research
MimiTalk is an AI-powered dual-agent interview platform designed for scalable, ethical, and quality-controlled conversational data collection in qualitative social science research. The modular architecture integrates a frontend React.js interview interface, a backend API service implemented in FastAPI, and an AI inference module orchestrating both supervisor and conversational agents. The interview interface adheres to minimalist design principles to reduce cognitive burden—only core interaction buttons and transcript display are present, thereby isolating content from extraneous anthropomorphic cues.
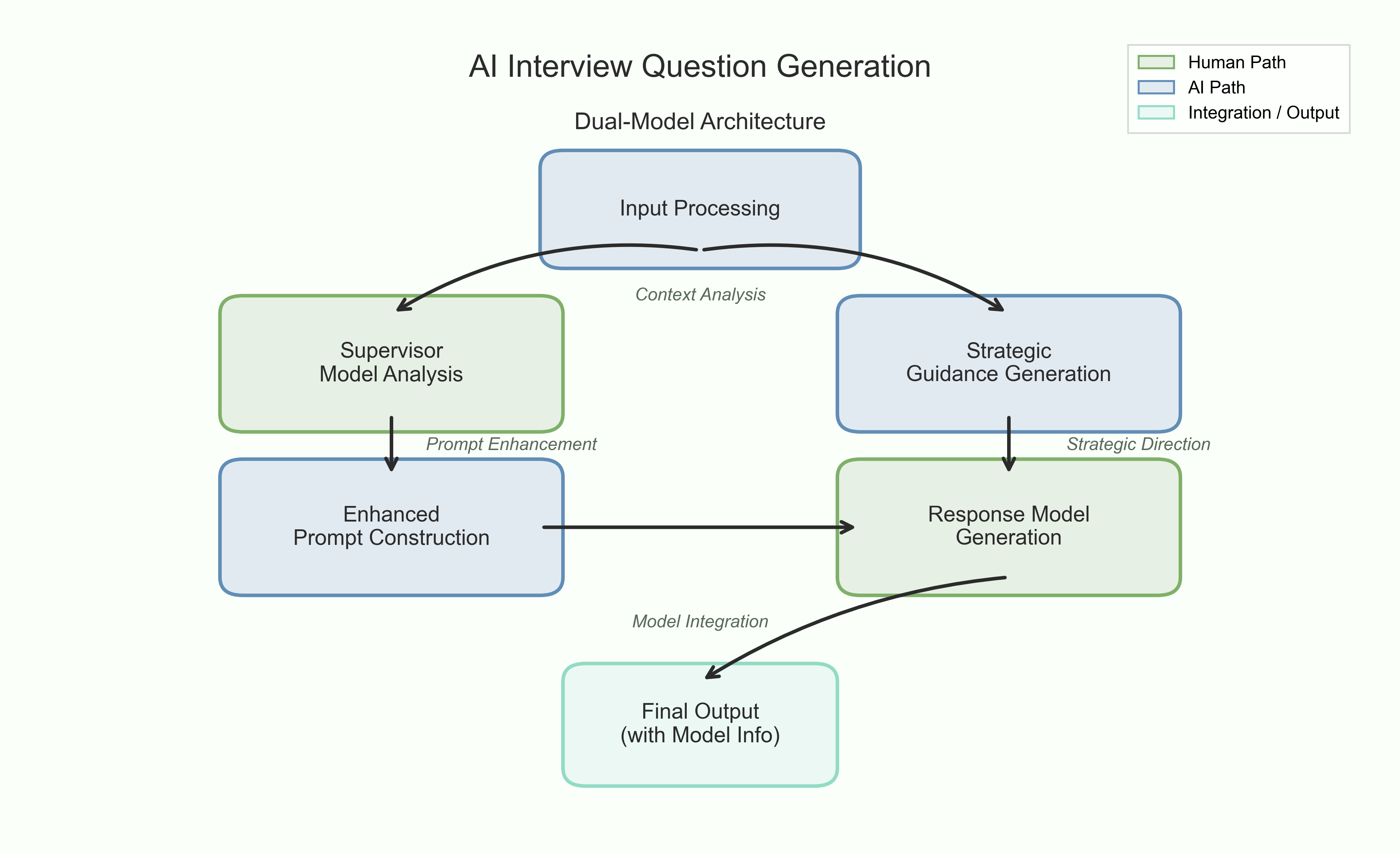
Figure 1: MimiTalk.app’s minimalist interview interface, emphasizing transcript-centric interaction free from anthropomorphic distraction.
The dual-agent architecture operationalizes constitutional AI principles [anthropic2022constitutional]. The supervisor agent (Claude Sonnet 4.0) enforces strategic oversight and ethical compliance, while the responder agent (GPT-5/Claude Haiku) executes natural conversation generation. This architectural decoupling yields contextually adaptive, compliance-guaranteed interviews without sacrificing conversational naturalness.
Usability Insights
A foundational usability study with 20 participants established the MimiTalk platform’s effectiveness in reducing interview anxiety and maintaining conversational coherence. The interface’s minimalist design garnered positive assessments for intuitiveness and navigation, while the absence of social and visual cues significantly lowered psychological pressure associated with traditional interviews.
Across 121 AI interviews and 1,271 human interviews (MediaSum dataset), MimiTalk consistently outperformed human interviewers in transcript entropy, question diversity, and response richness. AI interviews achieved higher overall transcript entropy (mean 7.703 vs. 7.273), an 8.3% increase in interviewer text entropy, and a 5.9% increase in vocabulary richness.
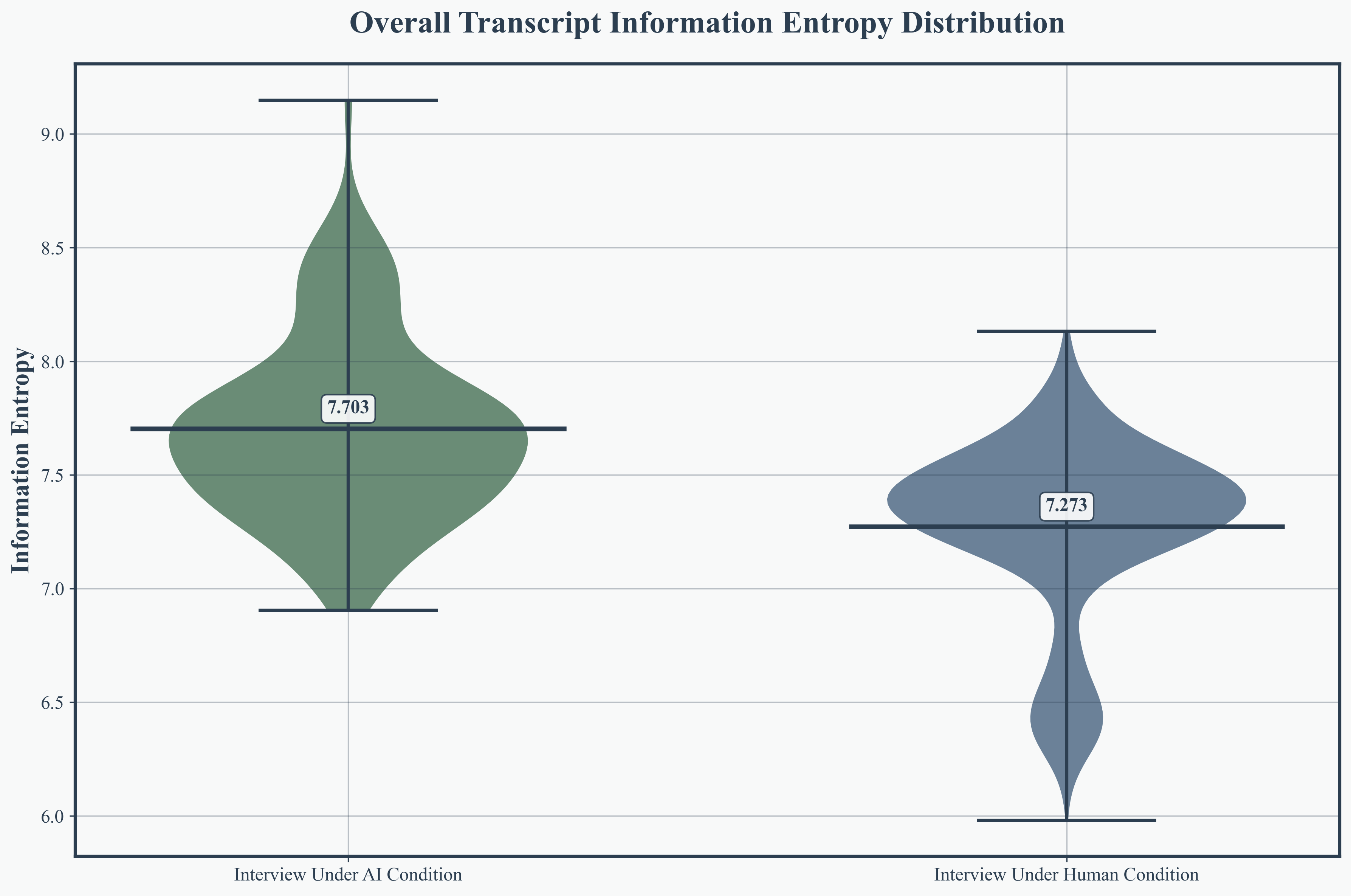
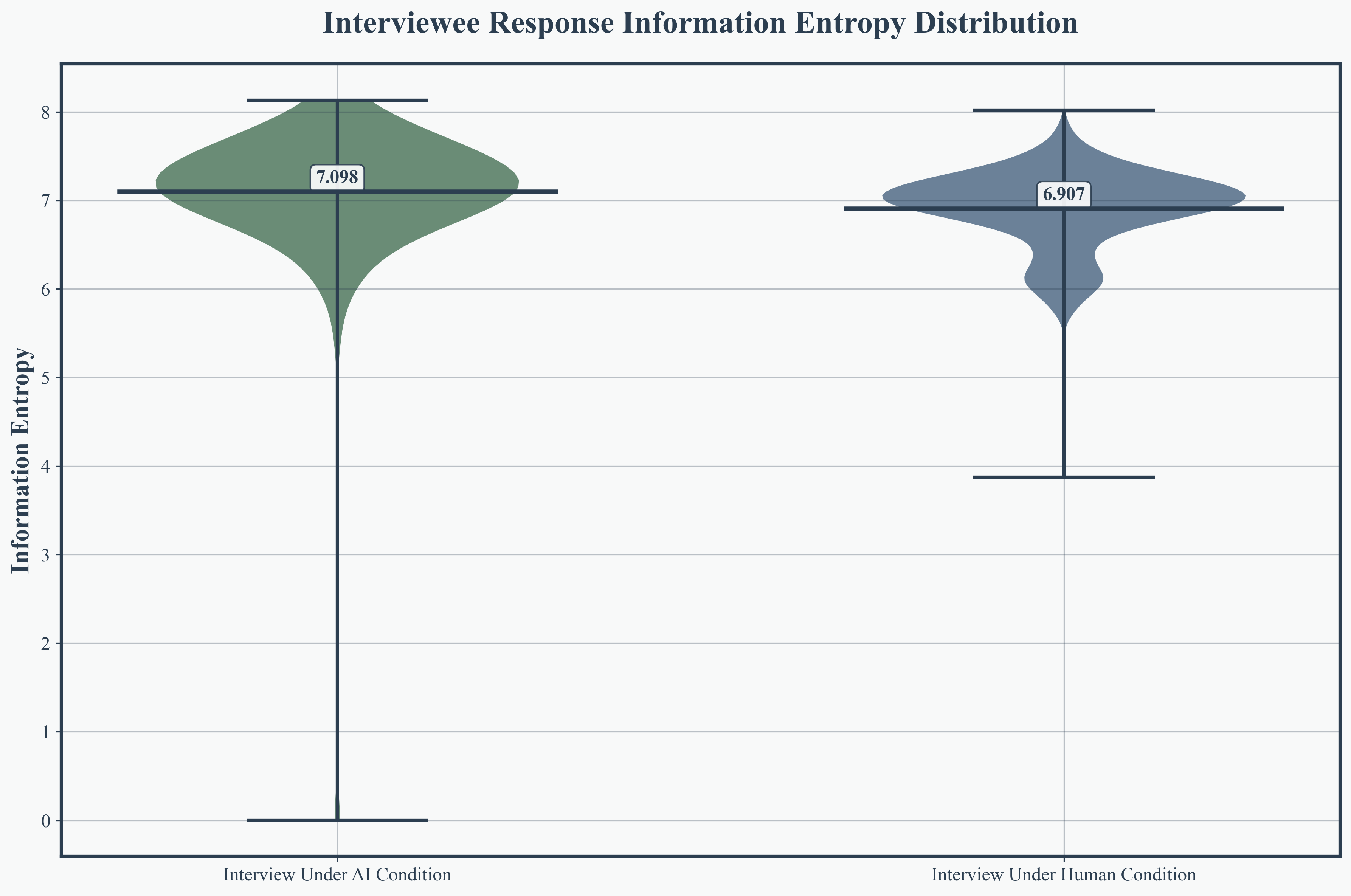
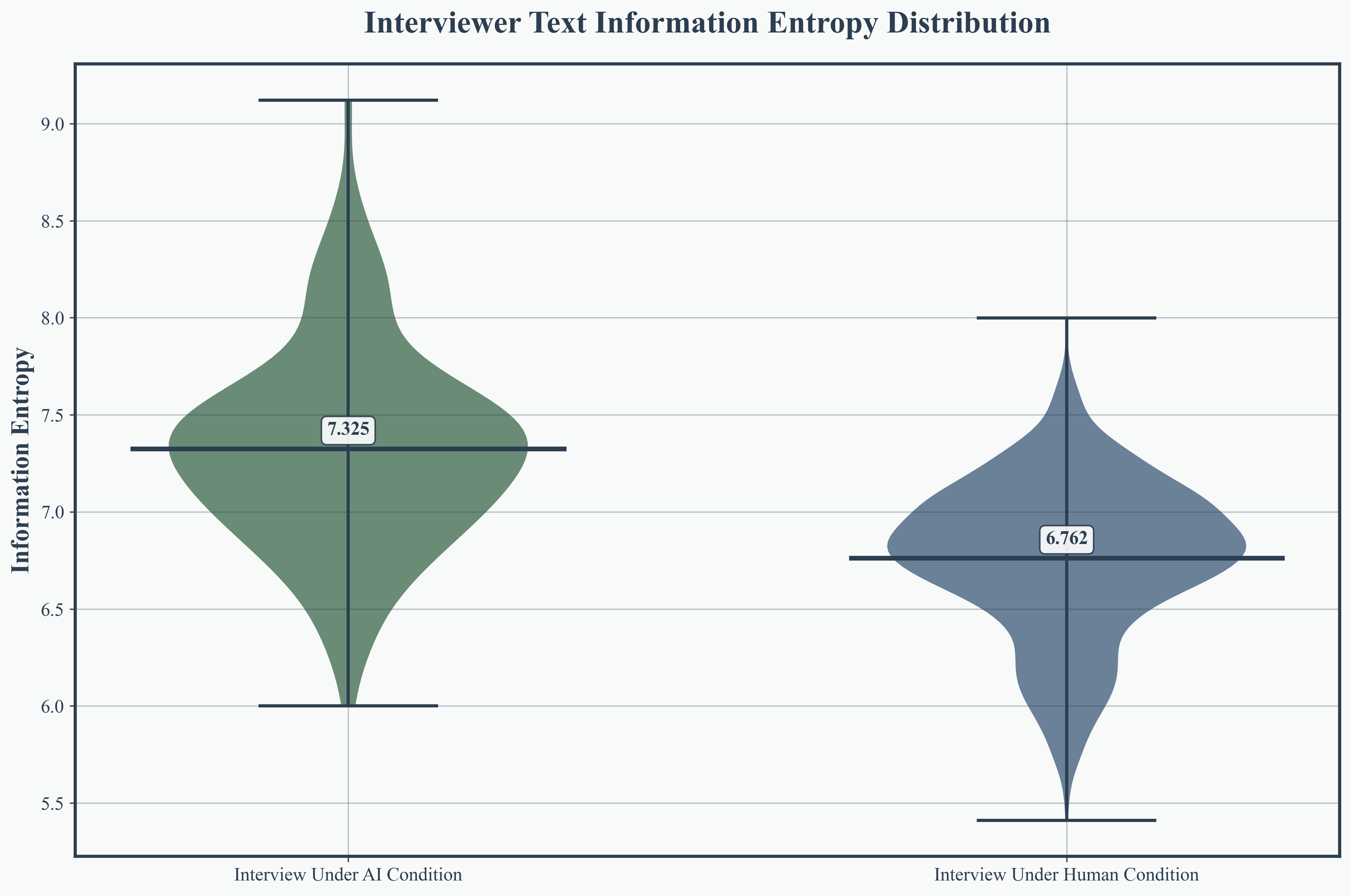
Figure 2: Overall transcript entropy revealing increased lexical diversity in AI interviews.
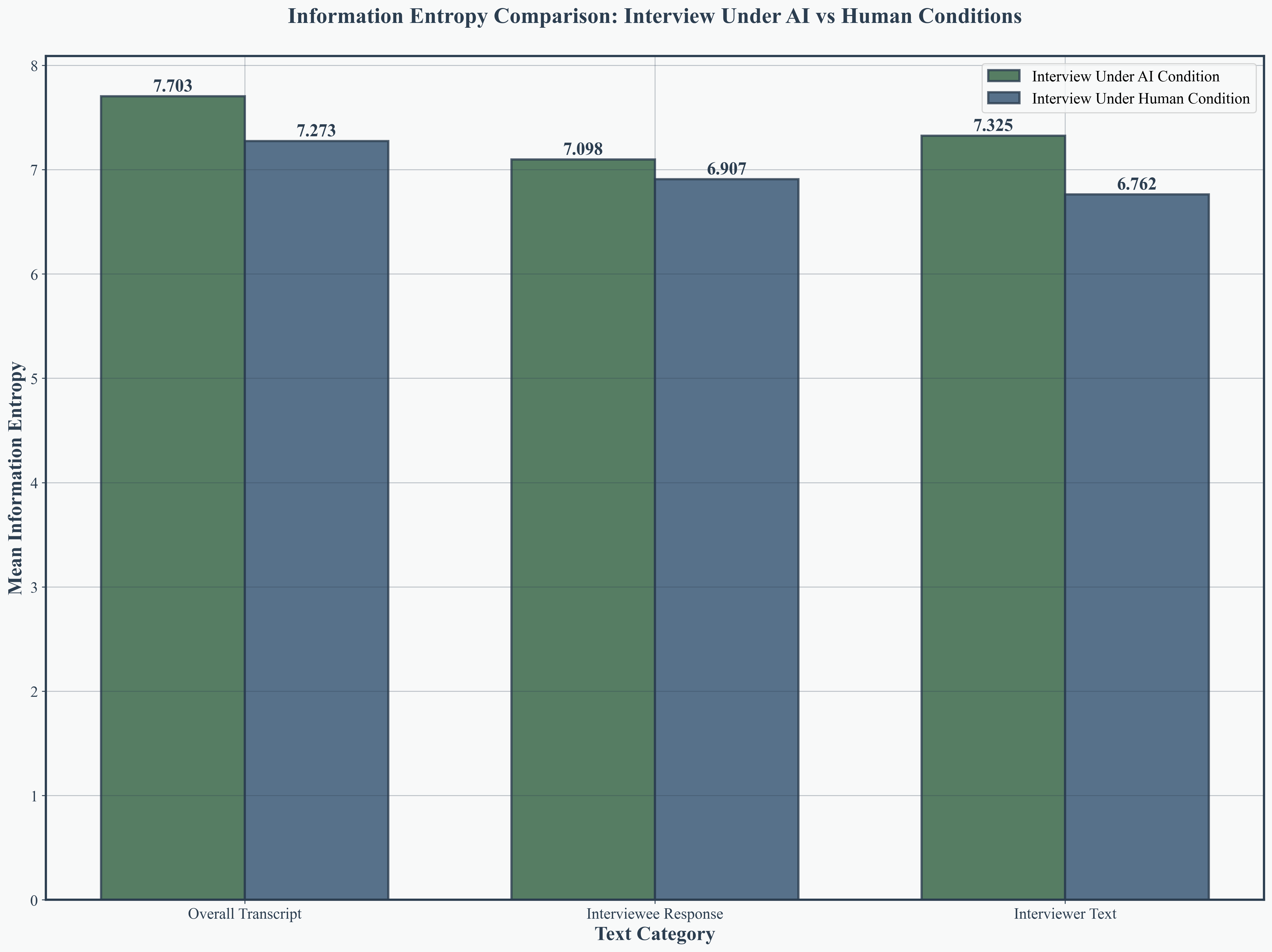
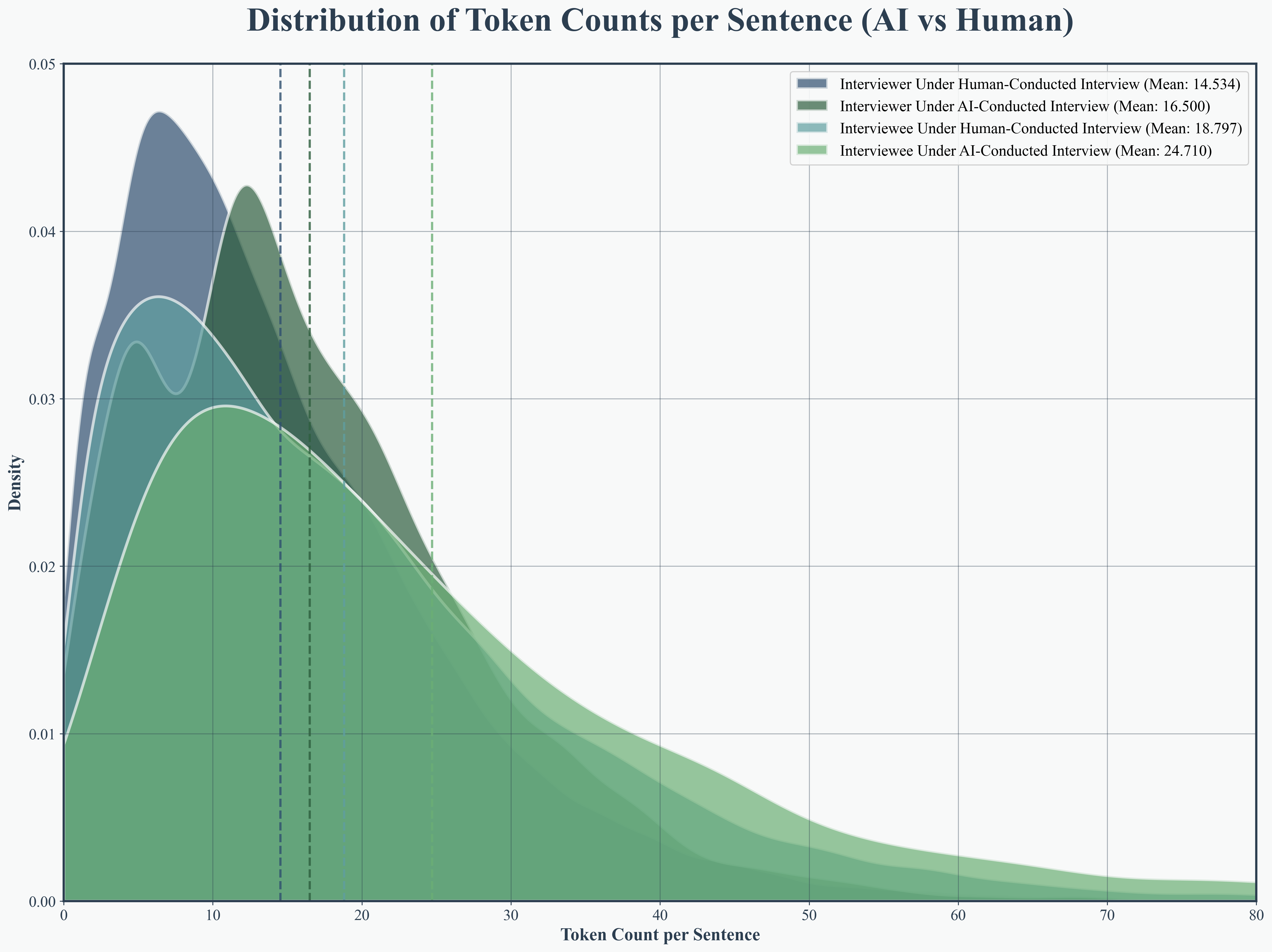
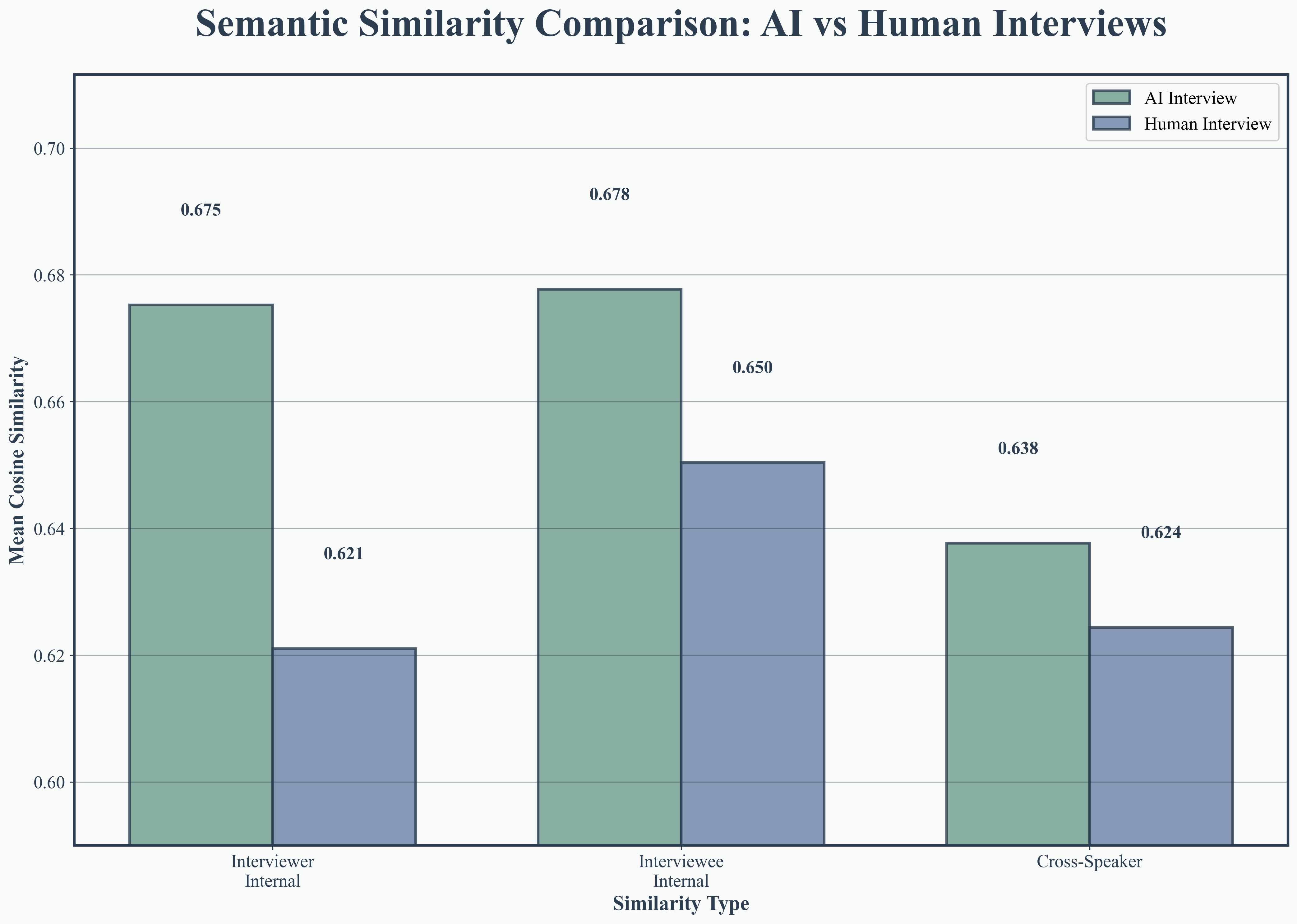
Figure 3: Comprehensive entropy comparison, further consolidating AI’s advantage in linguistic richness and diversity.
Token Usage and Response Elaboration
AI interviewees produced longer, more variable responses (mean 24.7 tokens per sentence, SD 22.2), surpassing humans by 31.4%. AI interviewers formulated more detailed questions (mean 16.5 tokens) than their human counterparts, indicating enhanced informational depth and scaffolding.
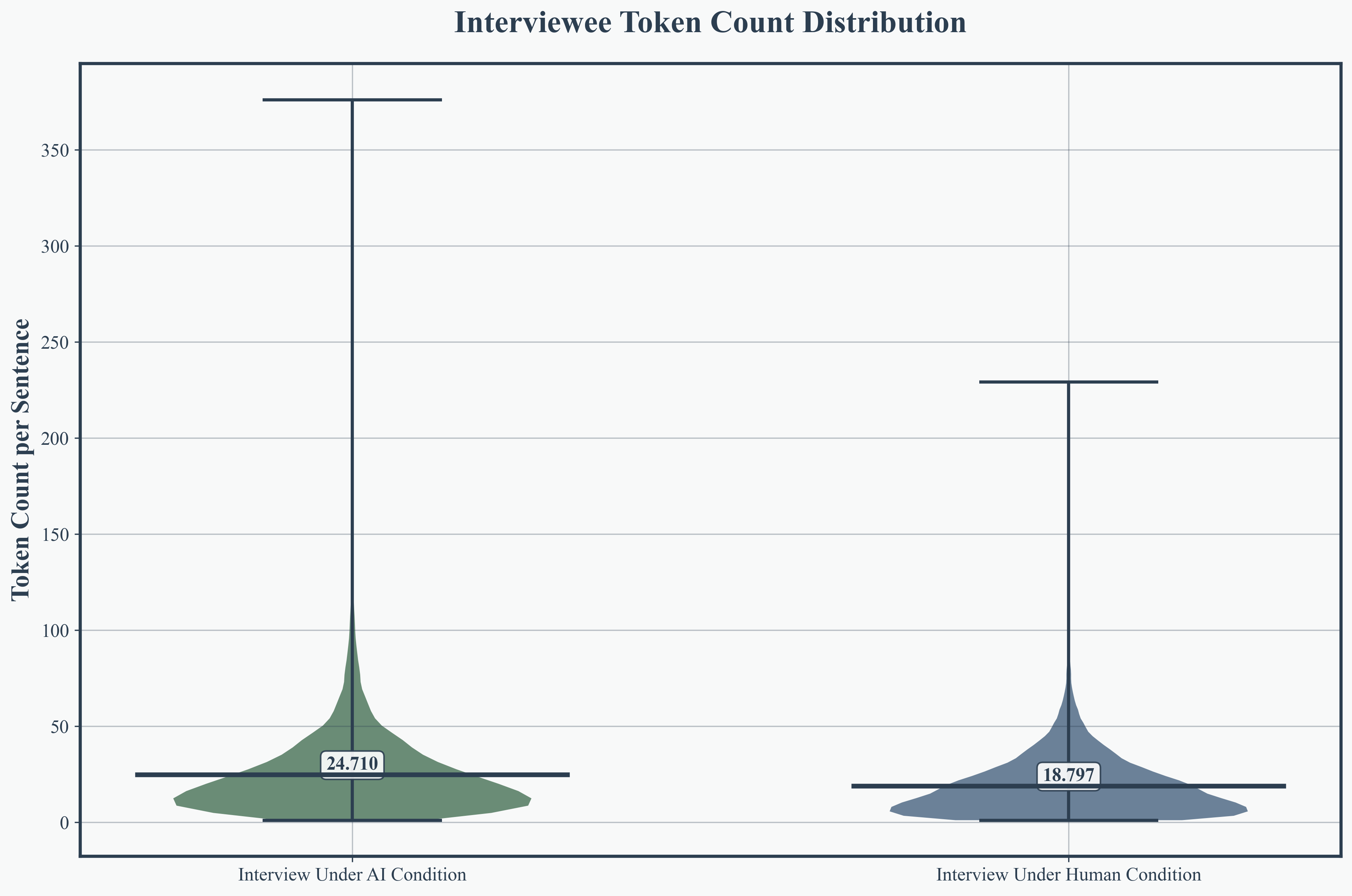
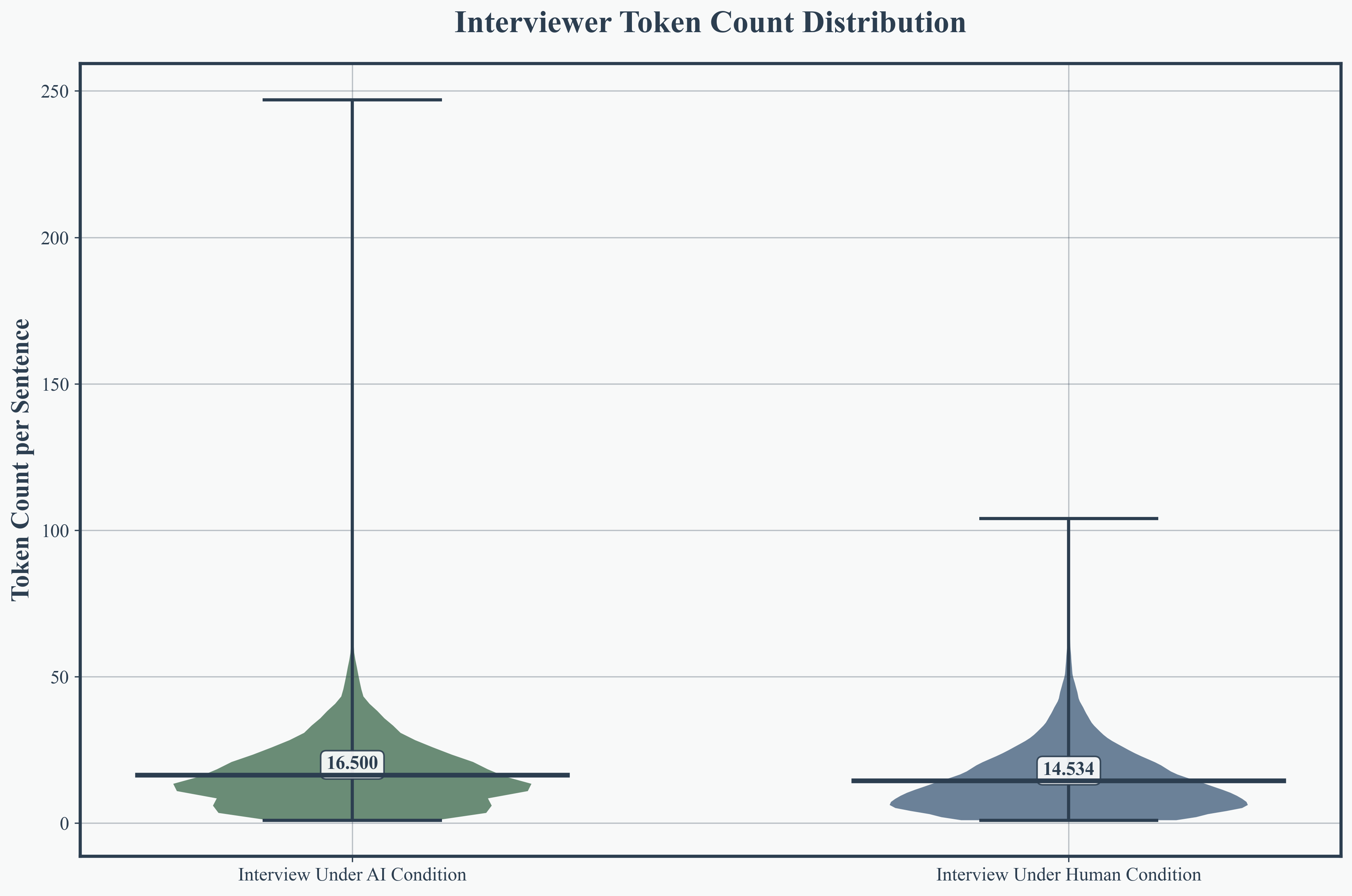
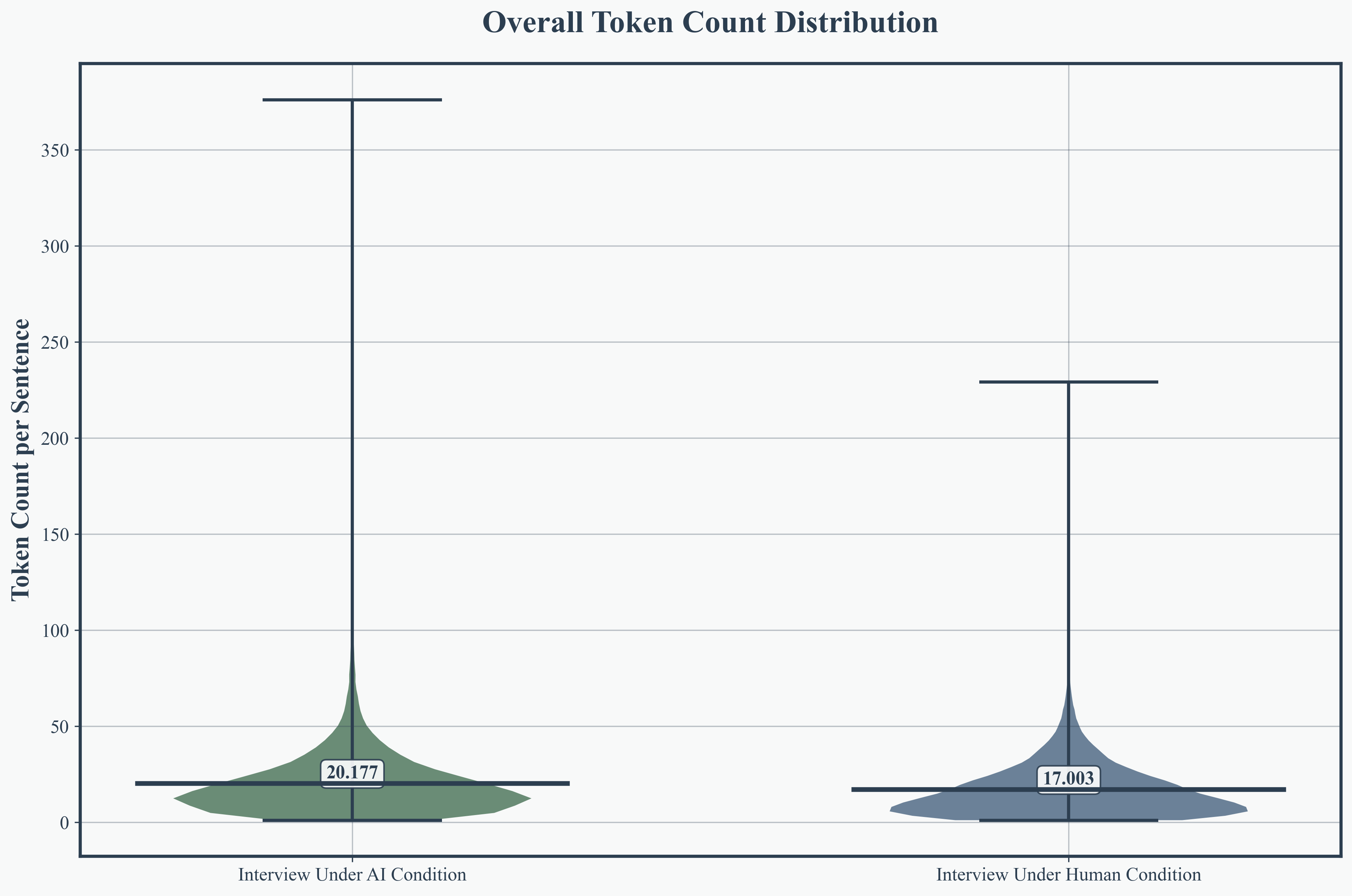
Figure 4: Interviewee response token count distribution, highlighting AI-induced elongation and variability in answers.
Semantic Coherence
Transformer-based embedding analysis (using DeBERTa-v3 and BERT) established that AI interviews are more semantically coherent, with higher internal similarity in both interviewer questions (0.886 vs. 0.814) and interviewee responses (0.892 vs. 0.847). Cross-speaker similarity also improved (0.872 vs. 0.824), evidencing superior thematic continuity and alignment.
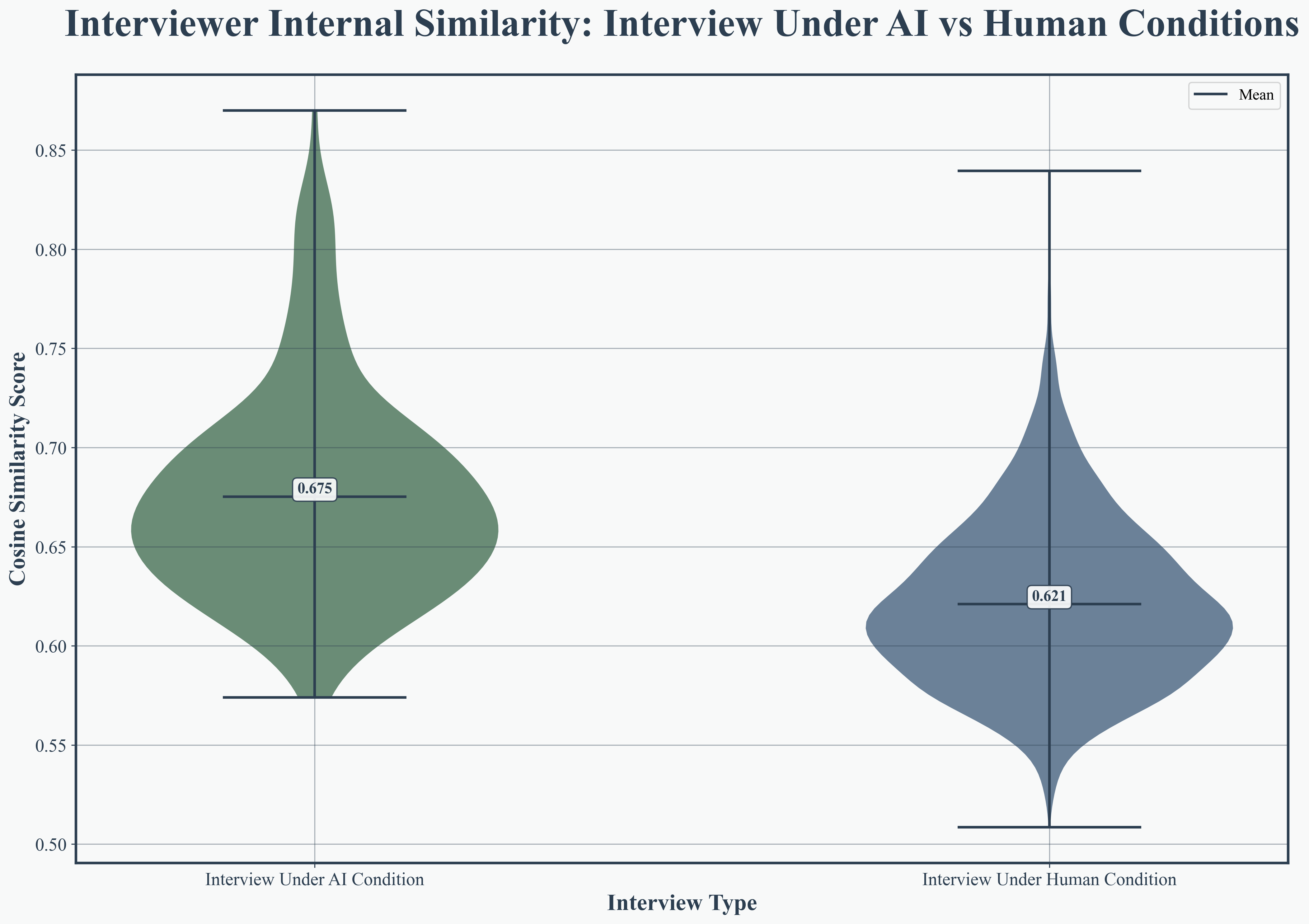
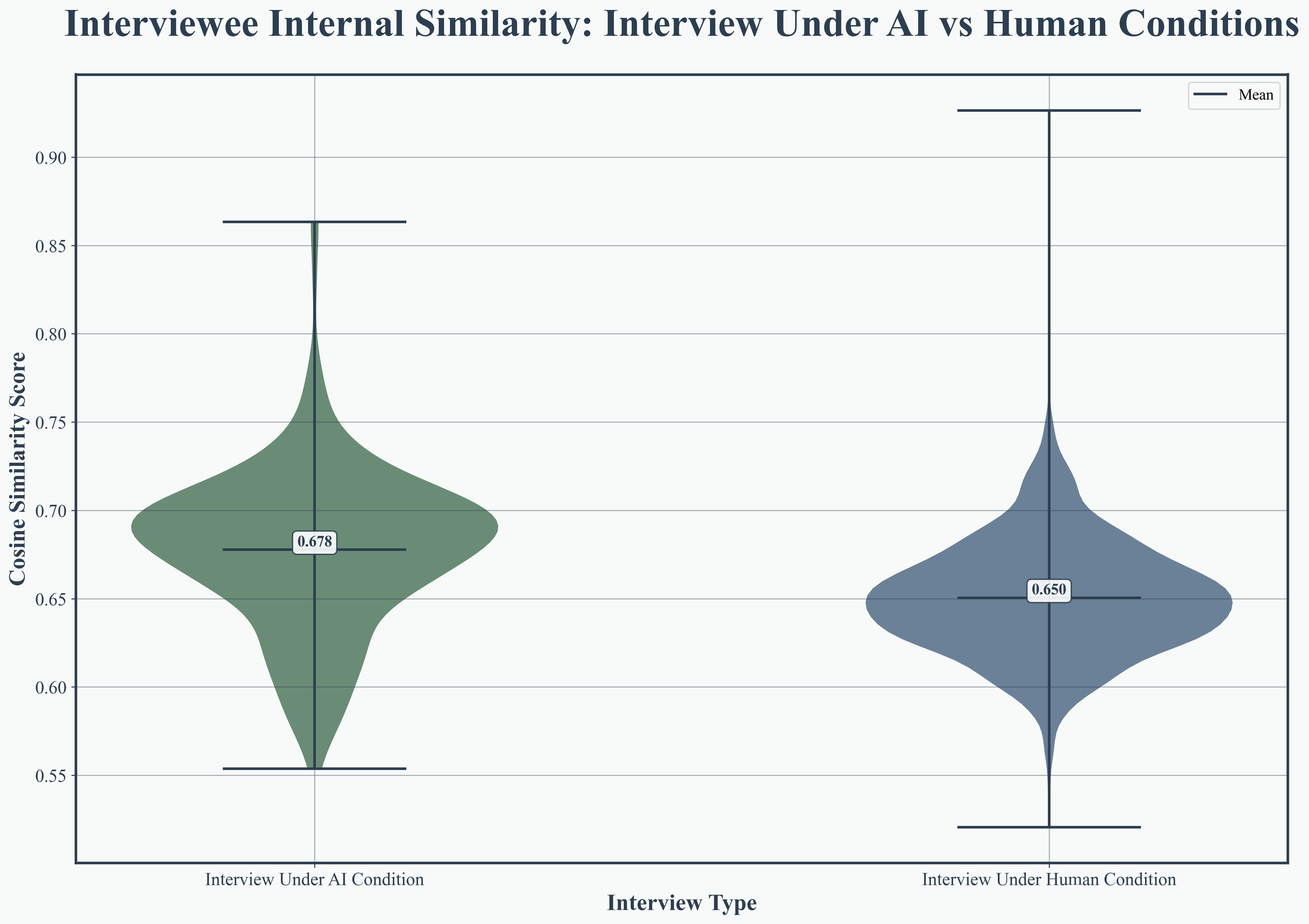
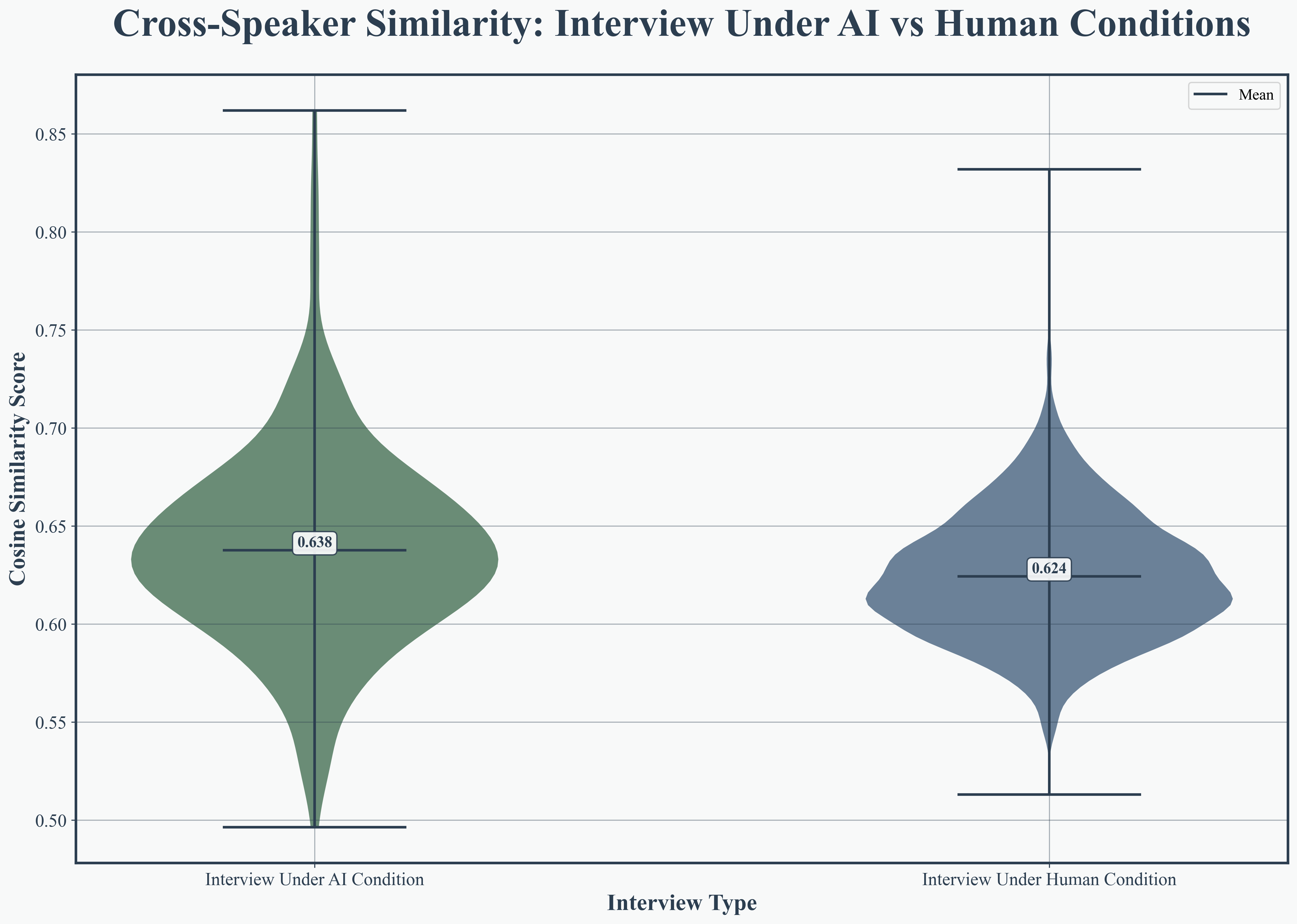
Figure 5: Interviewer internal similarity, demonstrating AI’s consistency in question formulation.
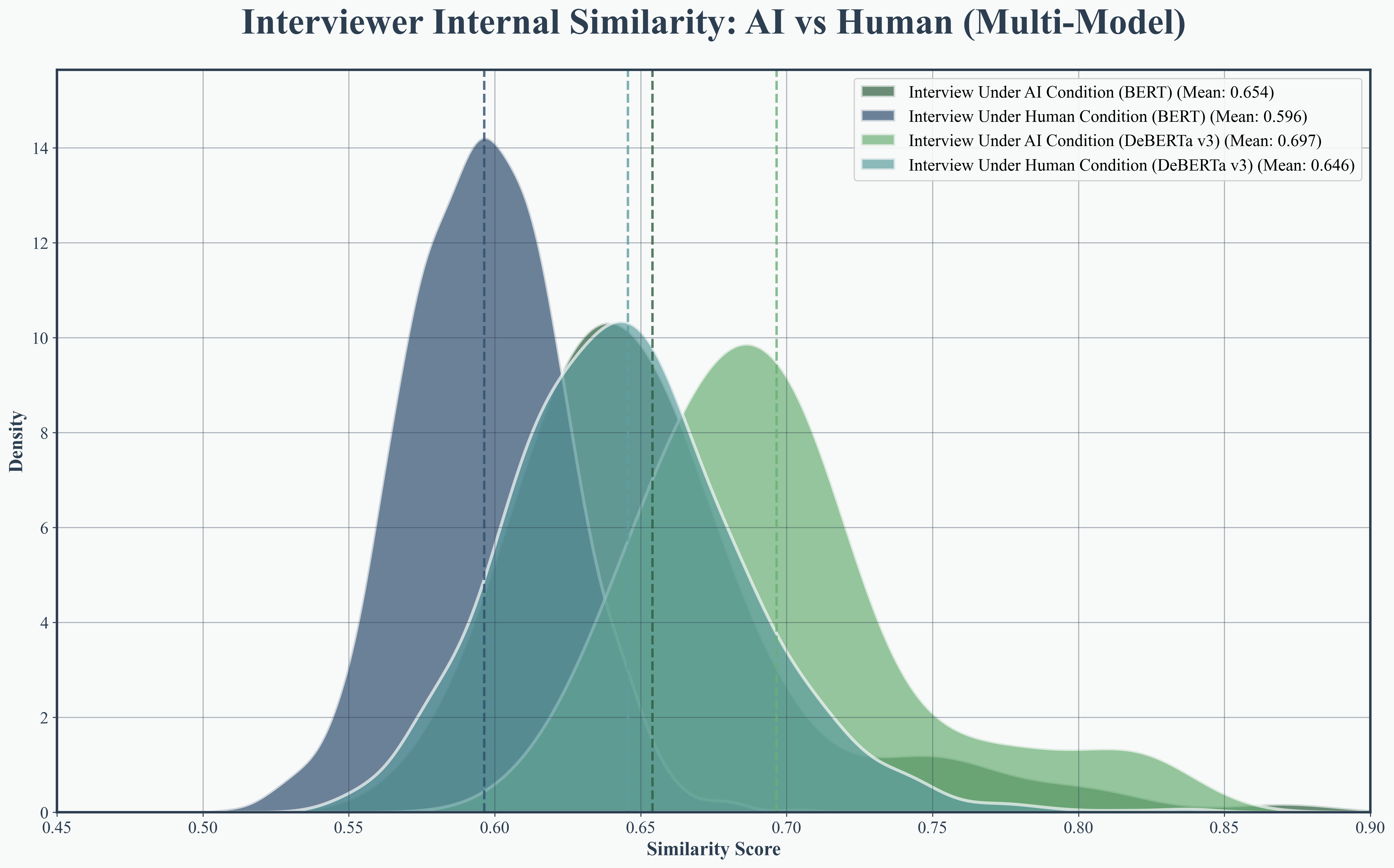
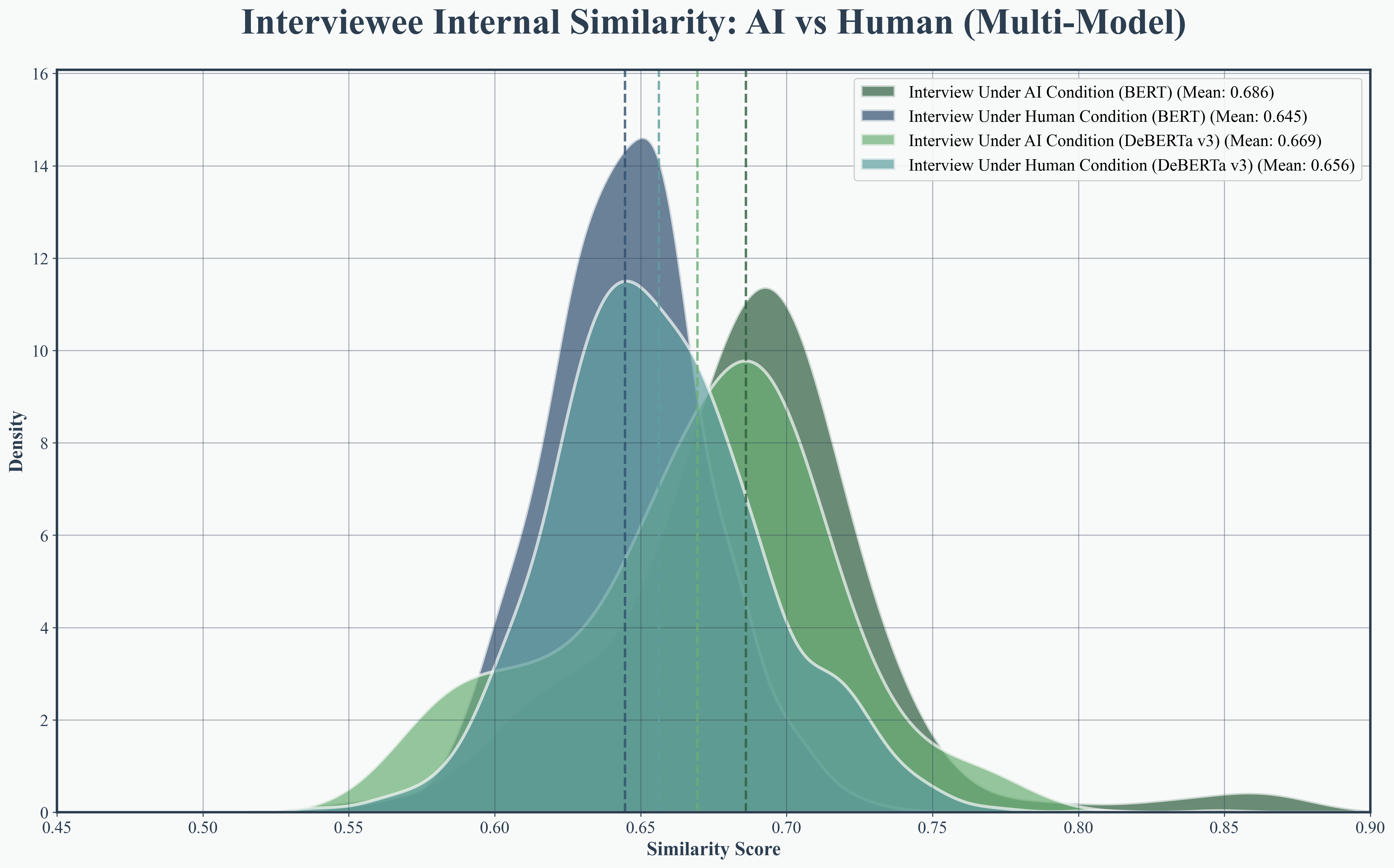
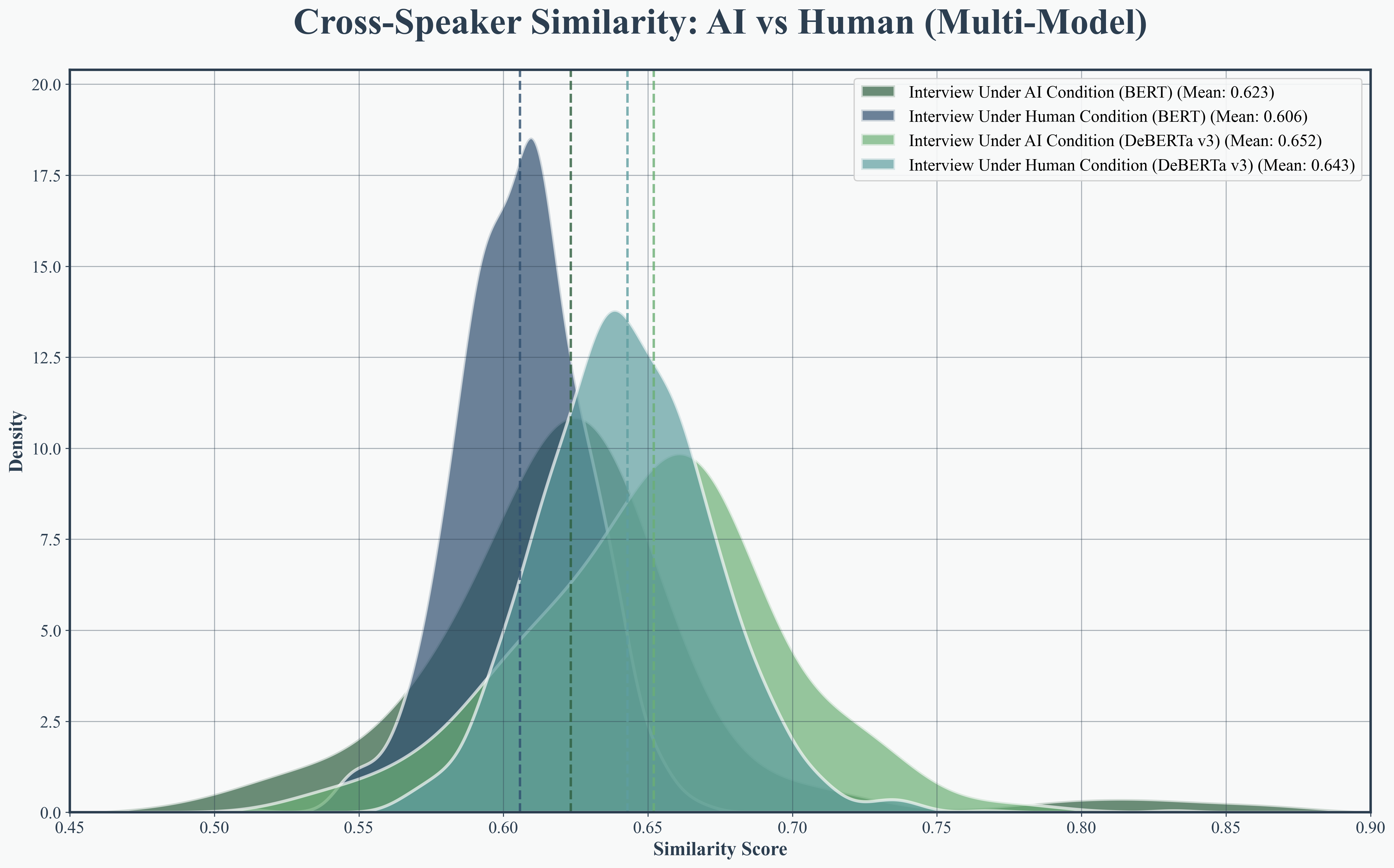
Figure 6: Interviewer internal similarity KDE, showing concentrated higher semantic similarity in AI interviewer questions.
Statistical evaluation (parametric and non-parametric methods) confirmed significance with very large effect sizes for most metrics (Cohen’s d > 1.0). Propensity Score Matching (kernel matching) established causal impact, with robust placebo and alternative model validation.
Theoretical and Practical Implications
The MimiTalk framework validates constitutional AI as an “evocative object” in qualitative contexts, facilitating psychological projection and meaning construction along Lacanian-symbolic and Dennettian-intentional stance lines. This architecture mechanizes the tension between "scalability and emotional subtlety": while AI systems excel in eliciting technical and sensitive disclosures (reducing social desirability bias), human interviewers remain superior in extracting cultural and affective nuance.
Blind thematic analysis confirmed AI’s role as an efficiency enhancer rather than creativity substitute. Trust calibration follows task-specific contours: low for citation/retrieval, moderate for programming/analysis, high for writing/formatting. AI-generated interviews elicited frank discourse on sensitive issues (e.g., academic integrity), supporting the framework’s utility in contexts where anonymity and candor are paramount.
Methodological Contribution and Domain Applications
MimiTalk introduces a reusable, dual-agent constitutional paradigm embedding ethical compliance and quality control in scalable qualitative research while retaining conversational fluidity. The platform is applicable in public opinion polling, consumer research, investigative journalism, educational assessment, and organizational surveys—domains where anonymity, replicability, and standardization are critical.
Network-theoretic insights imply that AI interviews, by leveraging weak ties and diverse knowledge routing [aralWhatExactlyNovelty2023], may attain unique information mining capacity. Future extensions should optimize semantic depth and contextual adaptation, further exploiting entropy-based information quality metrics.
Future Directions
Limitations include linguistic and domain generalizability—current evidence is strongest for English academic contexts but preliminary studies in Chinese affirm broader applicability. Longitudinal investigation is warranted to assess impacts on research quality and participant experience. Additionally, hybrid human-AI modes may rectify AI’s deficiencies in cultural/emotional depth, as shown in thematic analysis studies [prescottComparingEfficacyEfficiency2024, sakaguchiEvaluatingChatGPTQualitative2025].
Conclusion
MimiTalk exemplifies how dual-agent constitutional AI architectures can advance qualitative research by enhancing information richness, coherence, and scalability, with empirically verified performance gains across entropy, response length, and semantic similarity (\textbf{statistically significant, causal, and robustly validated}). The trade-off between scalability and emotional subtlety necessitates careful deployment, but the platform represents a methodological leap for large-scale, controlled qualitative research in diverse, sensitive domains (2511.03731).

