- The paper introduces a taxonomy that categorizes watermarking techniques by pre-, in-, and post-processing stages to meet the AI Act's regulatory criteria.
- The methodology operationalizes the four criteria—reliability, robustness, effectiveness, and interoperability—using distinct evaluation metrics and testing procedures.
- The analysis reveals trade-offs between watermark strength and output quality, emphasizing that interoperability remains a significant challenge.
Watermarking LLMs in Europe: Technical and Regulatory Synthesis
Introduction
The paper "Watermarking LLMs in Europe: Interpreting the AI Act in Light of Technology" (2511.03641) provides a comprehensive analysis of watermarking techniques for LLMs in the context of the European Union's AI Act. The work addresses the gap between the Act's normative requirements—reliability, interoperability, effectiveness, and robustness—and the technical realities of watermarking methods. The authors propose a taxonomy of watermarking approaches, operationalize the Act's criteria, and critically evaluate the strengths and limitations of current techniques, with a particular focus on the underexplored area of interoperability.
Taxonomy of LLM Watermarking Techniques
The paper introduces a temporally grounded taxonomy, distinguishing watermarking methods by the stage of the LLM lifecycle at which they are applied: pre-processing, in-processing, and post-processing. This taxonomy is further refined by differentiating between modifications to the next-token distribution and the sampling process during inference.
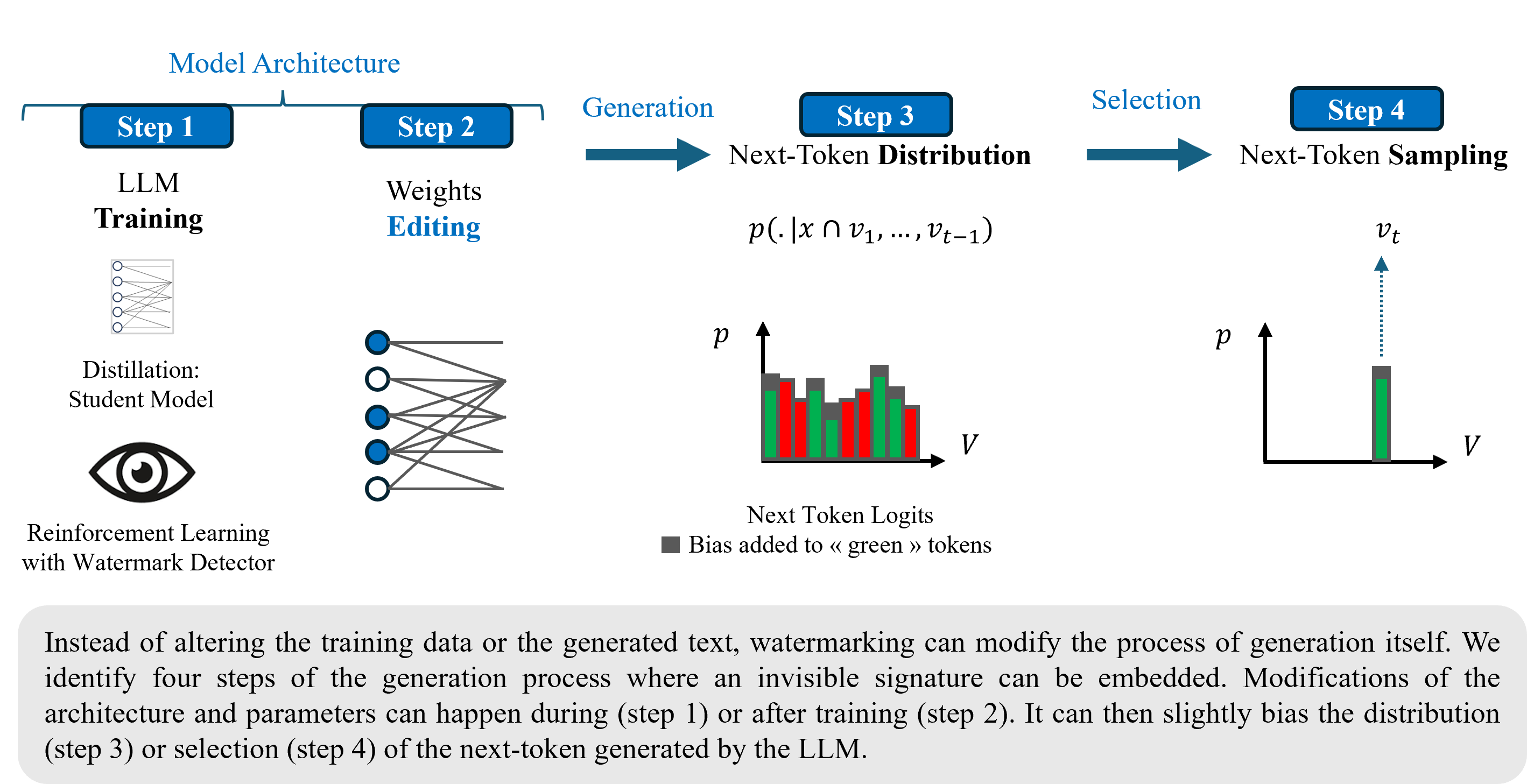
Figure 1: Watermarking a LLM by altering the Generation Process: Four Steps.
- Pre- and Post-Processing: These methods operate on training data (pre-processing) or generated text (post-processing), typically via syntactic (e.g., Unicode substitution) or semantic (e.g., synonym replacement) manipulations. While easy to implement and minimally invasive to model quality, they are generally vulnerable to simple removal or spoofing attacks.
- In-Processing: Watermarks are embedded within the model architecture or during inference. This includes:
- Training-Time Watermarking: Modifying the model during training, e.g., via distillation or RLHF, to encode a watermark in the weights.
- Weights Editing: Post-training insertion of bias or noise into model parameters, often targeting salient weights for robustness.
- Next-Token Distribution: Altering the logits before sampling, e.g., partitioning the vocabulary and biasing token probabilities.
- Next-Token Sampling: Modifying the sampling algorithm itself, such as tournament or Gumbel-softmax sampling, to encode a watermark in the output sequence.
This taxonomy clarifies the procedural and temporal dimensions of watermarking, addressing ambiguities in prior literature and providing a foundation for systematic evaluation.
Evaluation Criteria and Mapping to the AI Act
The authors decouple the AI Act's four criteria and map them to measurable technical properties:
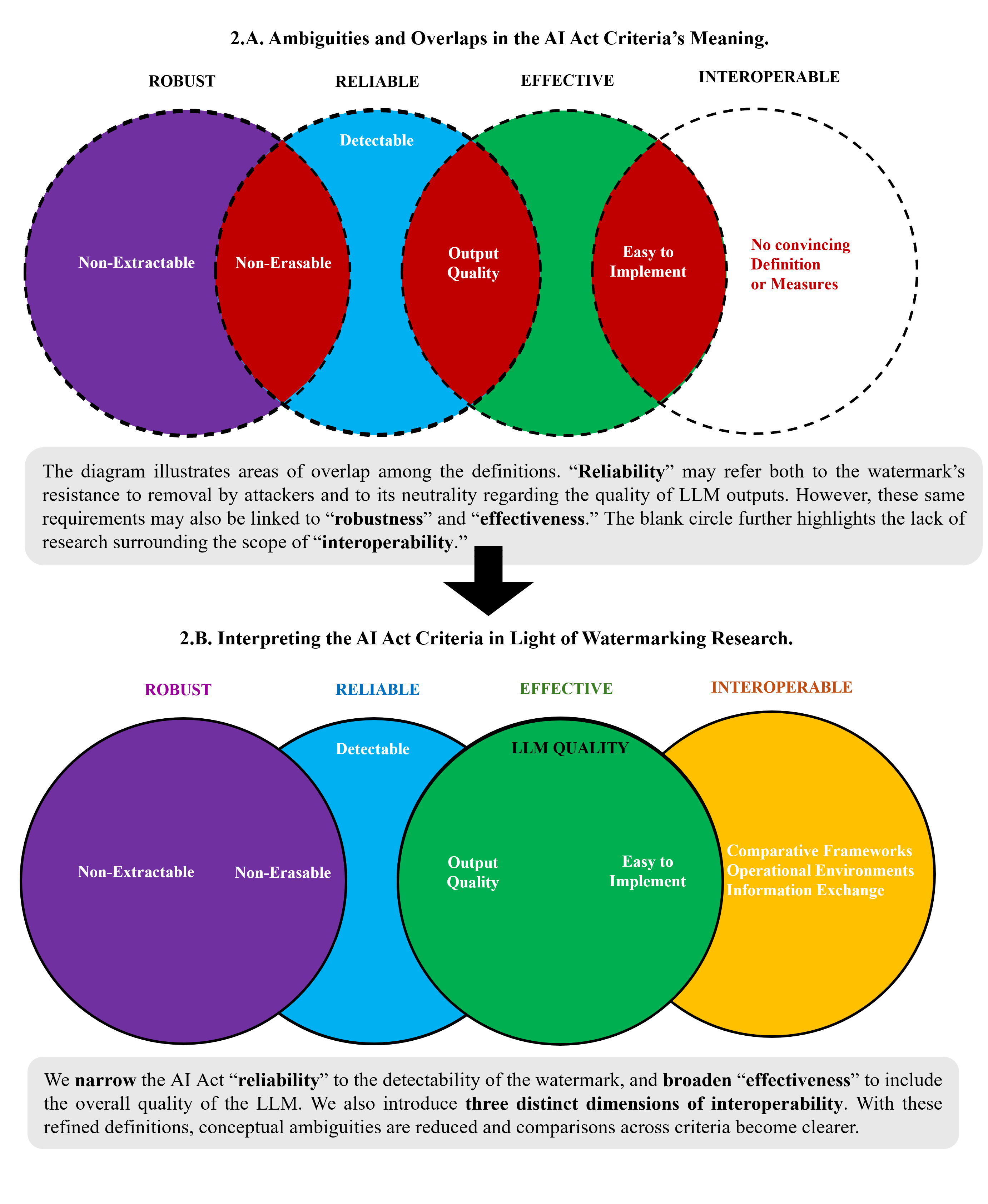
Figure 2: Interpreting the AI Act Criteria for LLM Watermarking: From Overlaps to Measurable Standards.
- Reliability: Interpreted as the statistical detectability of the watermark. This is operationalized via hypothesis testing (e.g., z-scores, p-values) and standard binary classification metrics (FPR, FNR, ROC, PR curves). The paper emphasizes the need for sufficient token length and robustness to minor text modifications.
- Robustness: Defined as resistance to both extraction (spoofing) and erasure (removal) attacks. The analysis distinguishes between attacks targeting the watermark (to falsely attribute content) and those targeting the LLM output (to evade detection).
- Effectiveness: Mapped to the preservation of LLM output quality, measured by BLEU, Meteor, BERTScore, semantic similarity, and diversity metrics. The trade-off between watermark strength and output distortion is highlighted, especially for in-processing methods.
- Interoperability: Identified as the least developed criterion, encompassing the ability to authenticate outputs across heterogeneous models and watermarking schemes. The authors propose three research directions: comparative frameworks, operational environments, and information exchange standards (e.g., C2PA).
Comparative Analysis of Watermarking Methods
The paper systematically compares watermarking families along the operationalized criteria:
- Pre- and Post-Processing: High output quality and easy implementation, but low robustness to removal and spoofing. Contextual or adversarial synonym substitution increases robustness at the cost of computational complexity.
- Next-Token Distribution: Detectable and robust to some attacks, but sensitive to window size. Larger windows increase robustness to extraction but reduce resistance to paraphrasing; smaller windows have the opposite trade-off. Output diversity can be compromised if not carefully managed.
- Next-Token Sampling: Cryptographically inspired methods offer strong undetectability and high output diversity but are computationally intensive and may be less robust to targeted attacks.
- In-Model Watermarking (Architecture/Weights): Embedding watermarks in model weights or via RLHF offers high robustness and minimal impact on output quality. However, detectability post-fine-tuning or model merging is not guaranteed, and empirical evaluation remains limited.
No single method currently satisfies all four EU criteria. In particular, interoperability remains an open challenge, with little empirical evidence supporting cross-model or cross-method detection in real-world settings.
Implications and Future Directions
The operationalization of the AI Act's criteria provides a framework for both technical development and regulatory compliance. The analysis reveals that:
- Structural watermarking (in weights/architecture) is a promising direction, offering robustness and low quality impact, but requires further research on detectability after model modifications.
- Token-level and text-level methods are mature but face inherent trade-offs between robustness and output quality.
- Interoperability is critical for regulatory enforcement and large-scale deployment but is currently underexplored. The development of open-source toolkits and standardized benchmarks is necessary to advance this area.
The paper also situates the European approach within a global context, noting divergent regulatory strategies in the US and China and the emergence of international standards (e.g., C2PA). The need for robust governance, auditability, and certification mechanisms is emphasized.
Conclusion
This work provides a rigorous synthesis of watermarking techniques for LLMs, grounded in the requirements of the EU AI Act. By clarifying the mapping between legal criteria and technical properties, the paper enables systematic evaluation and comparison of watermarking methods. The identification of interoperability as a critical but underdeveloped area sets a clear agenda for future research. As LLMs become increasingly integrated into digital infrastructure, the development of robust, effective, and interoperable watermarking solutions will be essential for trustworthy AI governance and compliance.

