- The paper introduces a novel open-source audio editing model that leverages large-margin synthetic data for iterative emotion, style, and paralinguistic editing.
- It employs a dual-codebook tokenizer, a streamlined 3B parameter audio LLM, and a flow-based decoder with BigVGANv2 to ensure high fidelity in TTS conversion.
- Its supervised fine-tuning and PPO-based reinforcement learning strategies yield superior performance in zero-shot cloning and expressive audio editing compared to conventional models.
Step-Audio-EditX Technical Report
Introduction
The emergence of Step-Audio-EditX marks a significant advancement in the field of audio editing models, particularly those based on LLMs. This open-source model is adept at handling expressive and iterative audio editing tasks, such as modifying emotion, speaking style, and paralinguistics, alongside delivering robust zero-shot text-to-speech (TTS) capabilities. The model's ability to leverage large-margin synthetic data allows it to perform these tasks without the necessity of embedding-based priors or auxiliary modules, representing a notable deviation from conventional representation-level disentanglement approaches.
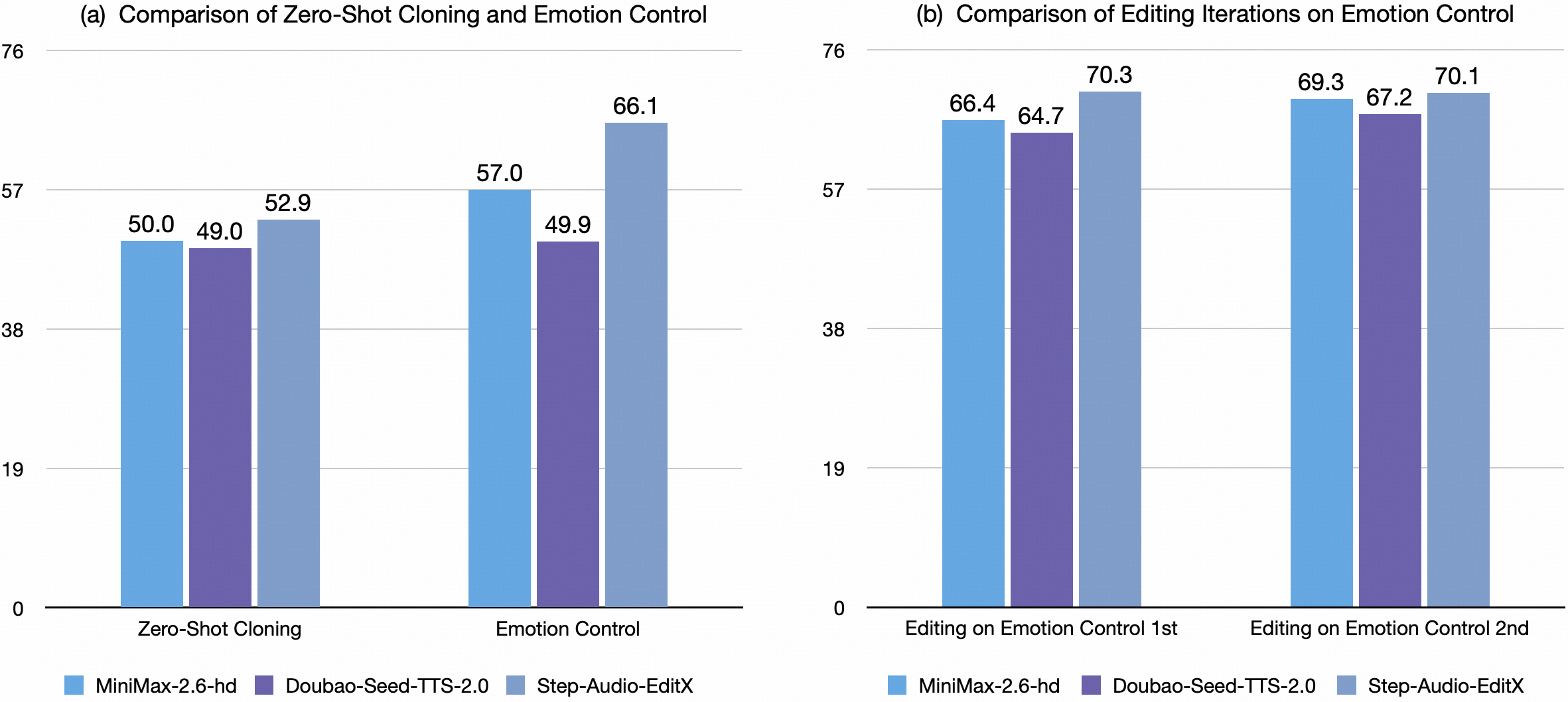
Figure 1: Comparison between Step-Audio-EditX and Closed-Source models illustrating superior performance in both zero-shot cloning and emotion control.
Architecture
Overview
The architecture of Step-Audio-EditX incorporates a streamlined model with significant capabilities consolidated into a 3B parameter model architecture, reducing complexity from its predecessor's 130B parameters. The system is composed of a dual-codebook audio tokenizer, an audio LLM, and a flow-based audio decoder. This design facilitates seamless integration and processing within a unified framework for both zero-shot TTS and diverse audio editing tasks.

Figure 2: An overview of the architecture of Step-Audio-EditX.
Audio Tokenizer
The dual-codebook tokenization approach from previous iterations remains intact, facilitating nuanced emotional and stylistic encoding while concurrently managing a considerable amount of linguistic information for detailed audio reconstruction.
Audio LLM
The audio LLM maintains a 3B parameter size for optimized performance and is trained using a hybrid dataset comprising text and audio tokens, enabling it to proficiently generate and process audio token sequences in a chat format.
Audio Decoder
The audio decoder, featuring a flow matching model and BigVGANv2 vocoder, converts the LLM's predictions into Mel spectrograms and further into audio waveforms, enhancing both pronunciation and timbre fidelity.
Data
The post-training dataset, key to Step-Audio-EditX's advancement, includes extensive SFT data for zero-shot TTS, emotion, and speaking style editing. Reinforcement learning data supports model fine-tuning to align outputs with human preferences, utilizing large-margin pairs selected through human annotation and automated scoring models.
Training
Supervised Fine-tuning
SFT trains the model to optimize its zero-shot TTS and editing abilities, adjusting to a range of system prompts and user inputs within a single epoch, modifying the learning rate dynamically.
Reinforcement Learning
PPO is employed to bolster the model's instruction-following capabilities and expressivity, refining its performance through continuous reward-model-informed adjustments.
Evaluation
The evaluation of Step-Audio-EditX involves employing a comprehensive benchmark devised with an LLM-as-a-Judge model to assess emotion, speaking styles, and paralinguistics accuracy, demonstrating its advantage over other TTS systems.
Emotion and Speaking Style
The model achieves enhanced accuracy through iterative editing, confirming the efficacy of large-margin learning in improving expressive content alignment beyond initial cloning abilities.
Paralinguistic Editing
The model effectively incorporates paralinguistic features through targeted editing strategies, validating its capacity to generalize these tasks across different closed-source models.
Extensions
This research extends the large-margin methodology to applications such as speed editing and denoising, wherein adjustments enabled by SFT and iterative editing demonstrate clear improvements in audio processing environments.
Conclusion
Step-Audio-EditX sets a new standard for LLM-based audio models with its integration of large-margin learning and reinforcement strategies, embodying a flexible framework that applies efficiently across a spectrum of audio manipulation tasks. Given its scalable design and adaptability, this approach offers promising pathways for future research and practical applications in audio editing and synthesis.
These innovations reflect a strategic pivot from the traditional emphasis on absolute speech representation disentanglement to an efficient model that achieves high adaptability through robust data pairing and iterative enhancement methodologies.