- The paper introduces MAVE, an autoregressive architecture that combines structured state-space modeling with cross-attention for robust voice editing and TTS synthesis.
- It employs an innovative token rearrangement strategy with causal masking to achieve bidirectional context, enhancing accuracy and computational efficiency.
- Experimental evaluations demonstrate improved WER and MOS scores, with MAVE achieving human parity in naturalness and outperforming models like VoiceCraft and FluentSpeech.
Speak, Edit, Repeat: High-Fidelity Voice Editing and Zero-Shot TTS with Cross-Attentive Mamba
Introduction
The paper presents MAVE (Mamba with Cross-Attention for Voice Editing and Synthesis), a novel autoregressive architecture designed for high-fidelity voice editing and text-to-speech (TTS) synthesis. MAVE integrates structured state-space modeling through Mamba with cross-attention mechanisms, allowing for precise text-acoustic alignment that enhances the naturalness and speaker consistency of synthetic speech. The model operates efficiently even in zero-shot TTS scenarios, without explicit training on this task, outperforming existing autoregressive and diffusion models on diverse audio data.
MAVE Architecture
MAVE's architecture incorporates a hybrid design that marries the efficiency of Mamba-based state-space models with the flexibility of cross-attention mechanisms for text conditioning. The input consists of phonemized text and audio tokens, processed using a causal masking strategy that rearranges audio tokens to enable bidirectional context for editing (Figure 1). A Mamba block forms the core of the model, providing efficient sequence modeling capabilities, while cross-attention layers facilitate audio generation conditioned on the textual embeddings produced by a Transformer encoder.
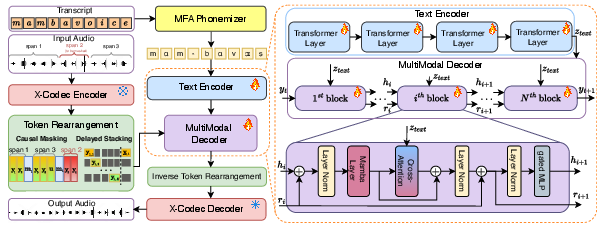
Figure 1: Overview of the proposed MAVE architecture. The model accepts phonemized text and audio tokens as input. A causal masking and rearrangement strategy is applied to the audio tokens to enable bidirectional context for editing. The core of the model is a Mamba block for efficient sequence modeling, augmented with cross-attention layers to condition the audio generation on the text embeddings produced by a Transformer encoder.
Experimental Evaluation
MAVE was evaluated on the RealEdit benchmark for speech editing and a zero-shot TTS task using LibriTTS. The architecture demonstrated superiority in word error rate (WER) and mean opinion score (MOS) for naturalness and intelligibility against competitors like VoiceCraft and FluentSpeech. Notably, MAVE achieved parity with human-edited audio, as evidenced by human evaluations where listeners rated MAVE-edited speech perceptually equal to the original 57.2% of the time.
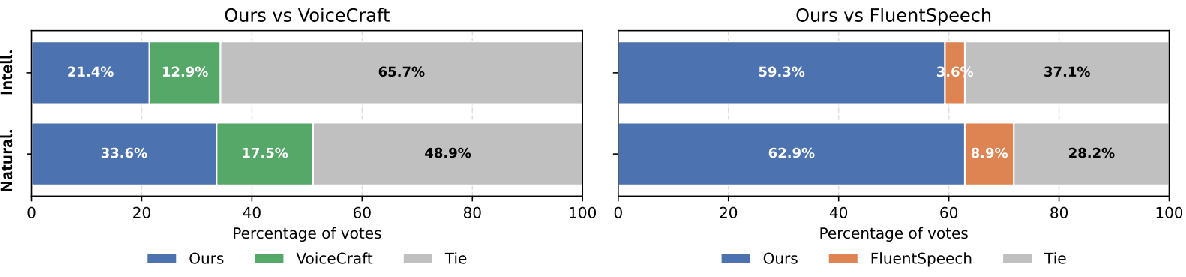
Figure 2: Side-by-side comparison between MAVE (ours), VoiceCraft, and FluentSpeech.
Analysis of Efficiency and Complexity
A comparative analysis of MAVE's complexity highlights its computational efficiency. MAVE's use of Mamba allows for linear complexity scaling with sequence length, significantly reducing memory usage and processing time compared to quadratic-complexity Transformer-based models. This efficiency makes MAVE more suitable for long-duration audio tasks while maintaining high fidelity and speaker consistency.
Methodological Advancements
MAVE introduces several methodological advancements:
- Cross-Attention for Text Conditioning: Cross-attention layers efficiently integrate text information, allowing seamless context-aware editing and synthesis.
- Token Rearrangement Strategy: The novel masking and rearrangement strategy enables bidirectional context access, improving model accuracy in handling masked token spans.
- Structured State-Space Modeling: By using Mamba blocks, the model efficiently maintains temporal coherence and prosodic consistency across long sequences.
Implications and Future Work
MAVE sets a new standard in speech editing and synthesis, demonstrating robust performance in human evaluations while maintaining scalability and efficiency. The integration of Mamba with cross-attention offers a promising approach for future developments in AI-driven audio processing. Potential advancements could involve training on longer audio sequences to fully leverage Mamba's proficiency in handling extensive temporal dependencies.
Conclusion
MAVE exemplifies a significant leap toward unified and efficient speech synthesis and editing frameworks. Its hybrid architecture balances fidelity and computational efficiency, proving its capacity to perform competitively in both synthesized speech and zero-shot TTS tasks. As the field of AI continues to evolve, MAVE’s architecture can serve as a foundational frame for future innovations in high-fidelity audio generation and editing.