AI-Generated Image Detection: An Empirical Study and Future Research Directions
Abstract: The threats posed by AI-generated media, particularly deepfakes, are now raising significant challenges for multimedia forensics, misinformation detection, and biometric system resulting in erosion of public trust in the legal system, significant increase in frauds, and social engineering attacks. Although several forensic methods have been proposed, they suffer from three critical gaps: (i) use of non-standardized benchmarks with GAN- or diffusion-generated images, (ii) inconsistent training protocols (e.g., scratch, frozen, fine-tuning), and (iii) limited evaluation metrics that fail to capture generalization and explainability. These limitations hinder fair comparison, obscure true robustness, and restrict deployment in security-critical applications. This paper introduces a unified benchmarking framework for systematic evaluation of forensic methods under controlled and reproducible conditions. We benchmark ten SoTA forensic methods (scratch, frozen, and fine-tuned) and seven publicly available datasets (GAN and diffusion) to perform extensive and systematic evaluations. We evaluate performance using multiple metrics, including accuracy, average precision, ROC-AUC, error rate, and class-wise sensitivity. We also further analyze model interpretability using confidence curves and Grad-CAM heatmaps. Our evaluations demonstrate substantial variability in generalization, with certain methods exhibiting strong in-distribution performance but degraded cross-model transferability. This study aims to guide the research community toward a deeper understanding of the strengths and limitations of current forensic approaches, and to inspire the development of more robust, generalizable, and explainable solutions.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “AI‑Generated Image Detection: An Empirical Study and Future Research Directions”
1. What is this paper about?
This paper studies how well different computer programs can spot pictures made by AI (like deepfakes) versus real photos. The authors build a fair, unified way to test many detection methods on many kinds of AI images, so we can see which methods are truly reliable and which ones only work in limited situations.
2. What questions were they trying to answer?
- Are current fake‑image detectors tested fairly and in the same way?
- Do these detectors work not just on the images they were trained on, but also on new, unseen AI image styles?
- Which testing scores best show real‑world reliability?
- Can we understand why a detector made a decision (for trust and safety)?
3. How did they study it?
The authors created a unified “fair test” setup and ran many detectors across many datasets, all under the same rules.
- Datasets: They used seven public collections of images, including both:
- GAN images: Think of a GAN as a “computer artist” that learns to draw whole images at once.
- Diffusion images: Think of diffusion as a “digital painter” that starts with noise and gradually paints a clear image step by step.
- Detectors: They tested 10 state‑of‑the‑art methods. These methods were run in three ways:
- From scratch: Training the detector from the beginning, like cooking fully from raw ingredients.
- Frozen: Using a powerful pre‑trained model (like CLIP) without changing its inner parts; you only add a light layer on top—like using a ready sauce without tweaking its recipe.
- Fine‑tuned: Starting from a pre‑trained model but adjusting it to the new task—like seasoning and simmering a store‑bought sauce to fit your taste.
- Scores they reported:
- Accuracy: How often the detector is right.
- Average Precision (AP) and ROC‑AUC: How well it separates real vs. fake across different decision thresholds, not just at one cutoff.
- Error rates and class‑wise sensitivity: How often it misses real or fake images specifically.
- Making decisions explainable:
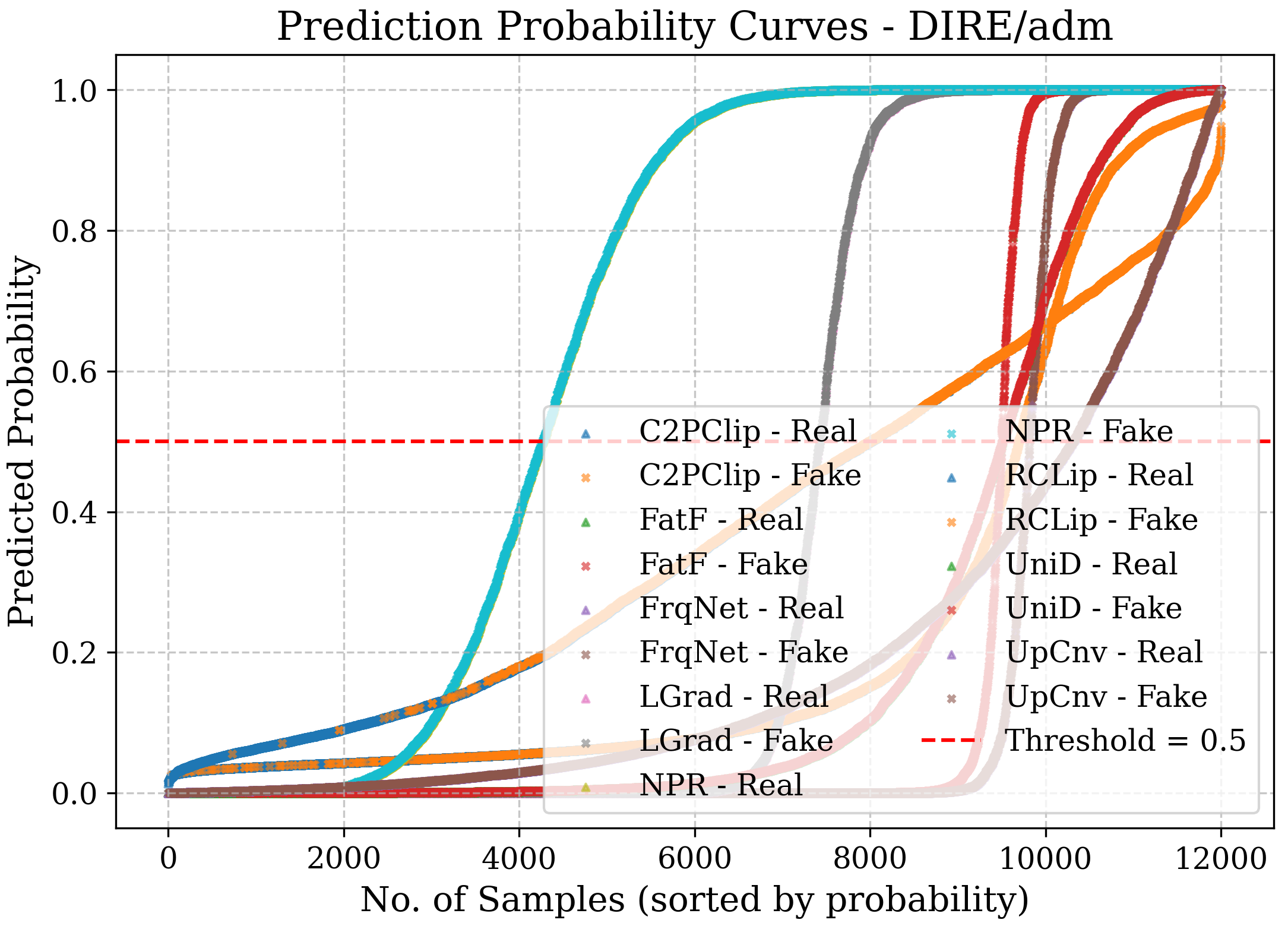
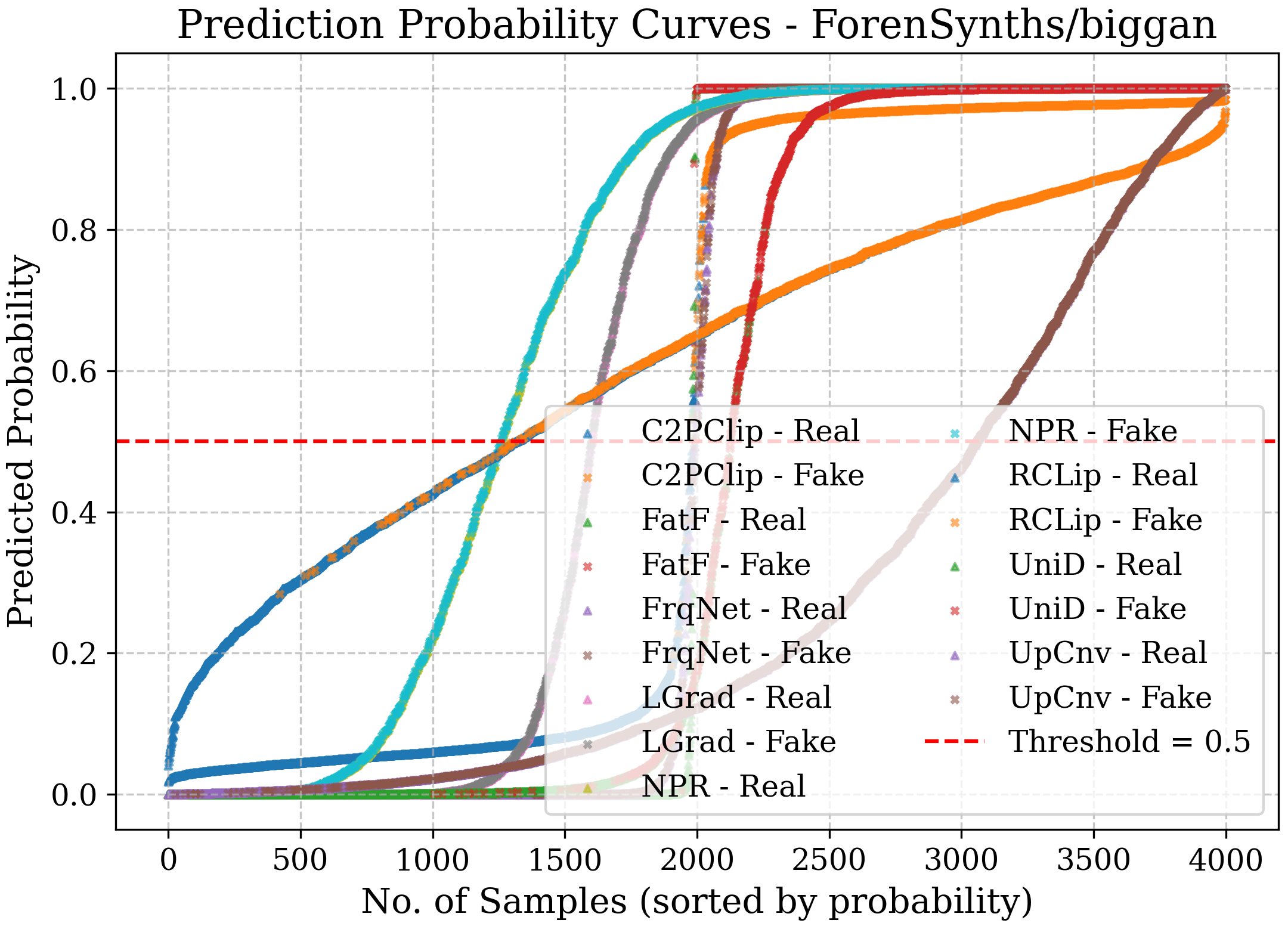
- Confidence curves: Show how confident a model is when it says “real” or “fake.”
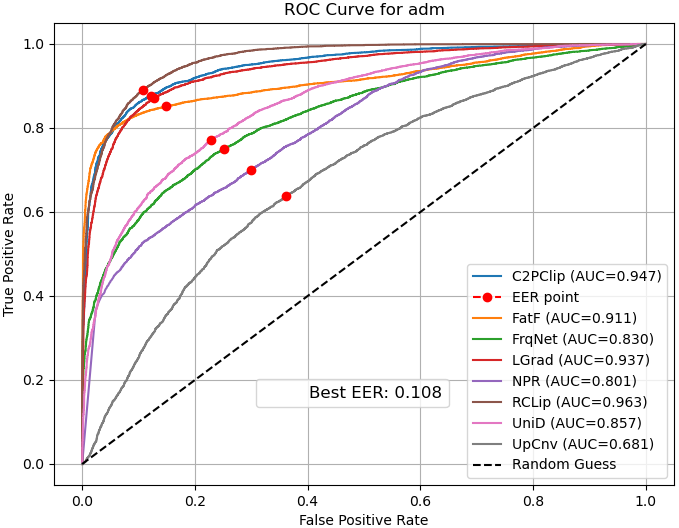
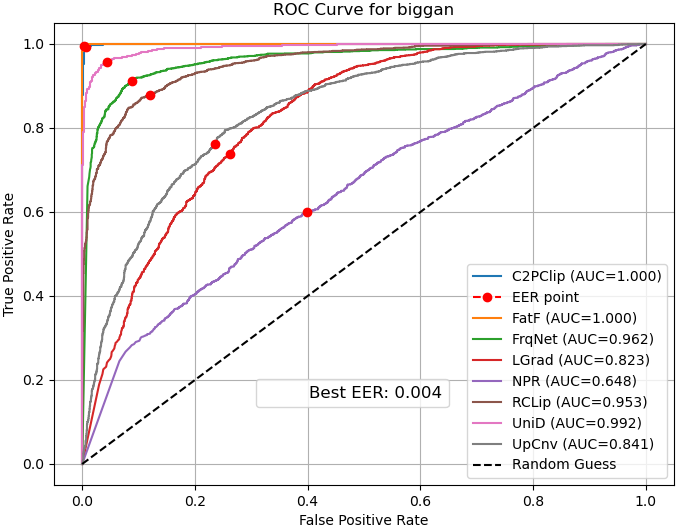
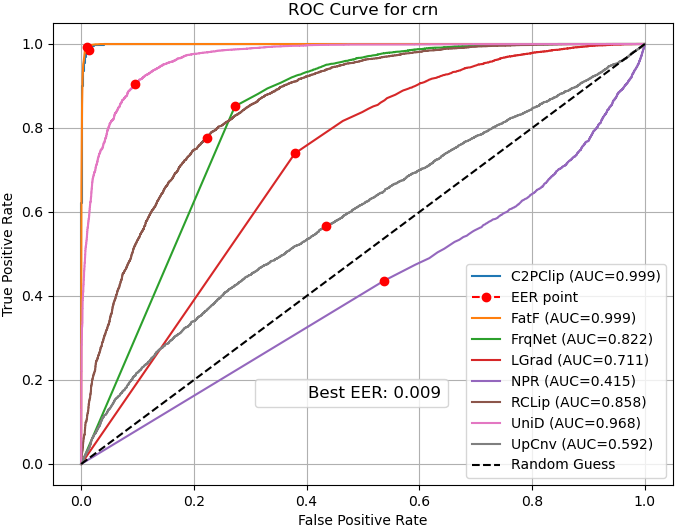
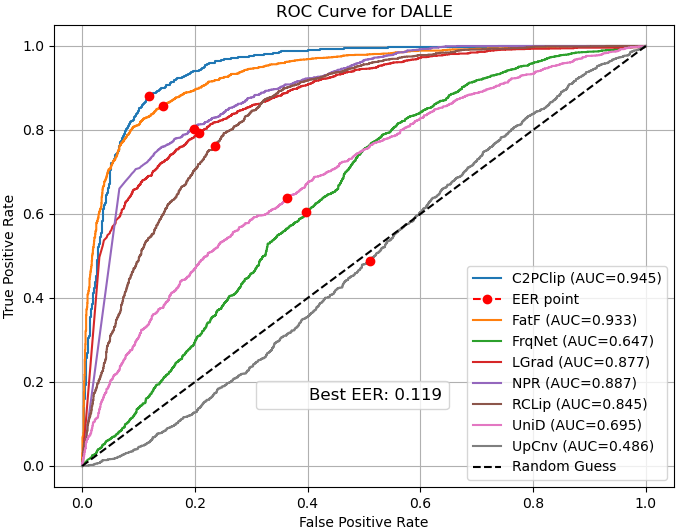
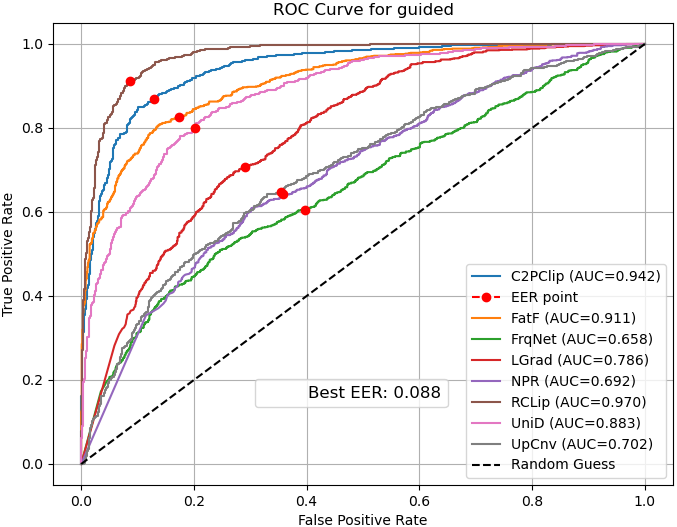
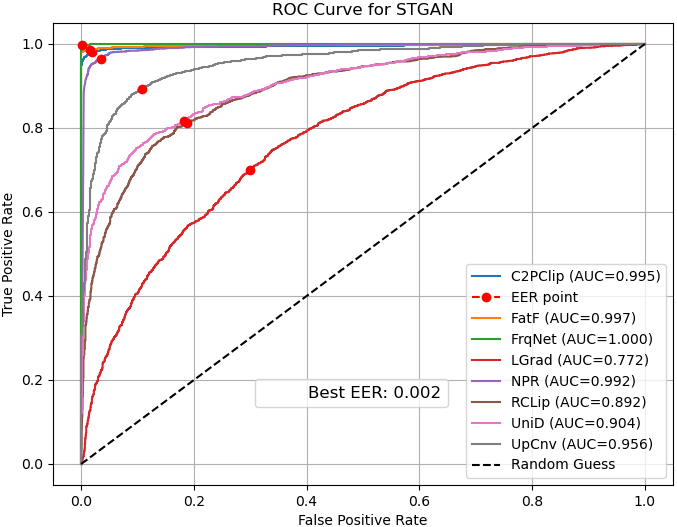
- ROC curves: Show the balance between catching fakes and avoiding false alarms.
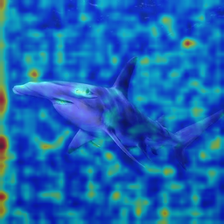
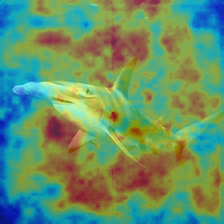
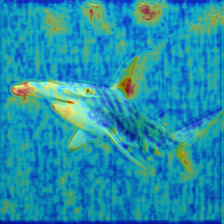
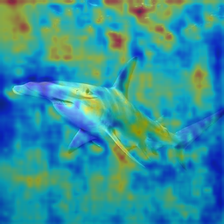
- Grad‑CAM heatmaps: Color maps that highlight which parts of the image influenced the decision—like showing where the model “looked.”
In short, they tested many detectors on many datasets, using the same rules, scored them in several ways, and then showed how and why the detectors made their decisions.
4. What did they find, and why is it important?
Key findings:
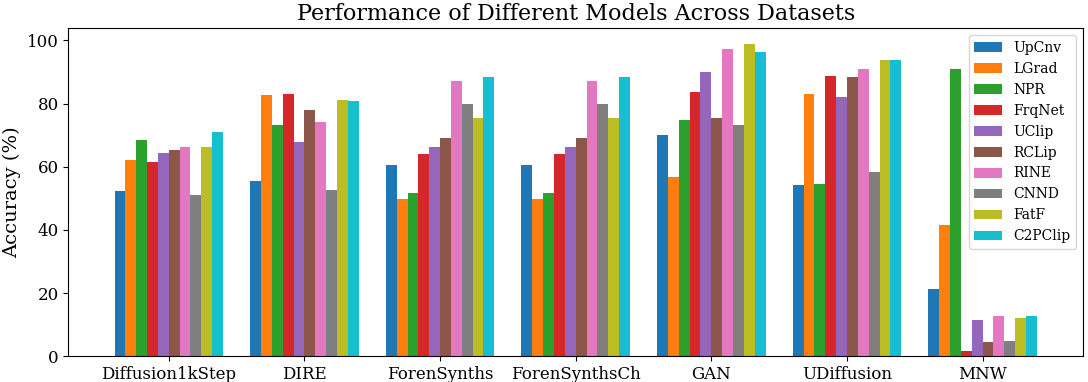
- Performance varies a lot across datasets:
- Some detectors look great on familiar data (the kind they were trained on) but drop sharply on new, unseen types of AI images. This means many methods don’t generalize well.
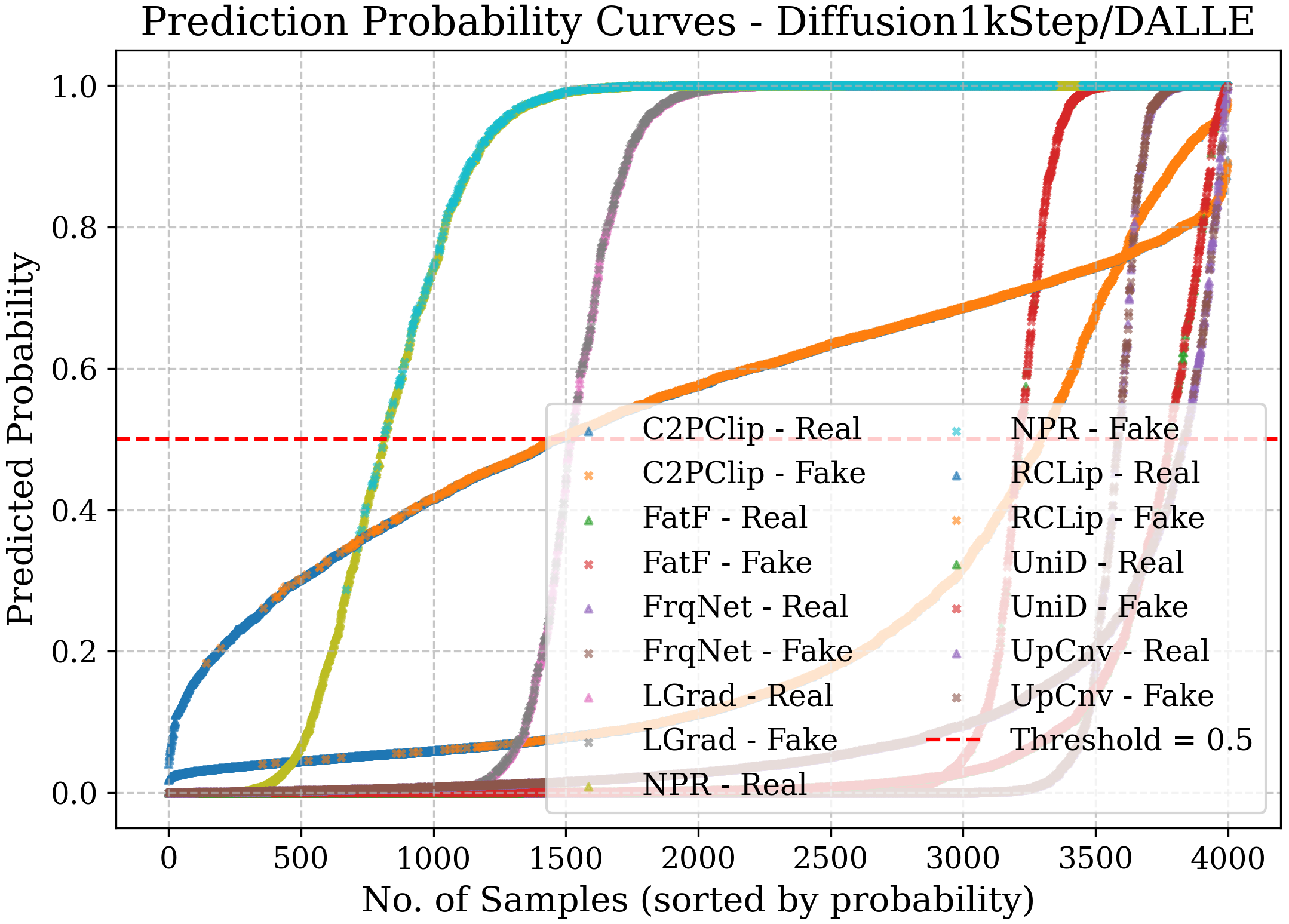
- Diffusion images can be harder:
- One tough dataset (Diffusion1kStep) reduced the accuracy of many detectors. Only a few methods handled it decently.
- A very diverse new dataset (MNW) is especially challenging:
- Most methods struggled badly here, showing how hard real‑world variety can be. One method that tends to “suspect fakes” did best on MNW—but that “bias toward fake” is risky in other scenarios.
- Simple take on methods:
- Some classic frequency/spectrum‑based methods underperformed on average.
- Methods that smartly use or adapt pre‑trained vision‑LLMs (like CLIP) often did better across a range of data.
- Bias and explainability matter:
- Confidence and ROC curves showed that some detectors lean toward calling images “real,” while others lean toward “fake.” This bias affects which datasets they handle well.
- Grad‑CAM maps showed different detectors look at different parts of images (sometimes backgrounds, sometimes random regions), which helps explain their choices and limits.
Why this matters:
- If a detector only works on a narrow set of fakes, it won’t protect people from new scams.
- Standard, fair testing helps researchers build detectors that truly work in the wild.
- Explainability builds trust and helps engineers fix weaknesses.
5. What does this mean for the future?
- Create standard testing rules: Shared training settings, preprocessing steps, and evaluation metrics so results are fair and repeatable.
- Aim for stronger generalization: Design detectors that look for clues that appear across many AI models (domain‑agnostic features), possibly via multi‑domain training or meta‑learning.
- Reduce bias: Balance training so detectors don’t default to “everything is fake” or “everything is real.”
- Be robust to preprocessing and attacks: Detectors should still work when images are cropped, compressed, or deliberately tweaked to fool them.
- Improve explainability: Use better visualizations and simple reports so people can understand why a detector flagged something, which supports trust in courts, newsrooms, banks, and social platforms.
Takeaway
This paper builds a fair playground to test fake‑image detectors and shows that many current tools don’t hold up well on new kinds of AI images. It points the way toward detectors that are more reliable, fair, and understandable—exactly what we need to fight deepfakes and protect the public.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Unified preprocessing remains uncontrolled: evaluations reuse method-specific pipelines (e.g., differing crops, normalizations, resize policies), making it impossible to isolate algorithmic merit from preprocessing effects. A harmonized, ablation-driven preprocessing protocol is needed to quantify its impact on each detector.
- Cross-generator generalization is not rigorously isolated: the study does not implement standardized leave-one-generator-out or leave-one-family-out training-to-testing protocols (e.g., train on GANs, test on unseen diffusion families), limiting causal conclusions about transferability across model families.
- Statistical robustness is unreported: no confidence intervals, multiple-seed runs, or statistical significance tests are provided. Results could reflect variance due to random initialization or sampling; a multi-seed, cross-fold design is needed.
- Metrics are incomplete/inconsistently presented: although the paper mentions ACC, AP, ROC-AUC, EER, and class-wise sensitivity, tables only report ACC/AP (and MNW lacks AP/AUC entirely). Quantitative calibration (ECE, Brier), FPR at fixed TPR, class-wise sensitivity, and threshold-independent measures should be systematically reported.
- Thresholding policy is unclear: it is not stated whether thresholds are fixed across datasets or tuned per dataset/method. A standardized thresholding protocol (e.g., fixed operating point, calibration across datasets) is required to ensure fair comparison.
- Dataset coverage is limited: only 7 out of 10 identified datasets are used; video deepfakes, localized edits (e.g., face swaps or object insertions), camera-pipeline manipulations (demosaicing, color space transforms), and provenance/watermark testbeds are absent. A broader benchmark spanning these cases is needed.
- MNW evaluation leaves critical gaps: AP/AUC are omitted and only accuracy is reported, obstructing a nuanced understanding of performance under severe distribution shift. Clarify why AP/AUC are missing and add full metrics (including calibration and class-wise breakdowns).
- Content-category effects are not analyzed: detectors may behave differently on faces, scenes, text, or compositional images. Provide per-category performance and bias diagnostics to identify failure modes tied to semantics.
- Class imbalance and dataset balance are not controlled: ForenSynth has uneven real/fake counts, yet accuracy (sensitive to imbalance) is used. Include macro-averaged metrics, balanced accuracy, and cost-sensitive analyses to mitigate misleading aggregate scores.
- Explainability analysis is qualitative: Grad-CAM and confidence curves are shown without quantitative validation (e.g., insertion/deletion tests, sanity checks for saliency, agreement with ground-truth artifact regions). Add quantitative interpretability benchmarks and artifact-localization validation.
- Bias diagnosis is incomplete: while NPR’s fake-class bias is observed, no causal analysis (e.g., label priors, loss functions, thresholding, feature distributions) is conducted. A formal bias audit with debiasing interventions (reweighting, balanced losses, calibration) should be performed.
- Anti-forensics (AF) robustness is underexplored: only conventional noise/compression are mentioned; no optimization-based AF attacks or generative AF (GAN/diffusion-based perturbations) are evaluated. Develop AF suites and measure detector resilience under adaptive, white-box attacks.
- Post-processing robustness is unquantified: systematic evaluations under realistic pipelines (JPEG/WebP compression levels, resizing, sharpening, denoising, retouching, social-media transcoders) are lacking. Include controlled stress tests and report performance degradation curves.
- Sample-efficiency analysis is limited: RCLIP explores small sample regimes; other methods lack data-curve analyses. Characterize performance as a function of training size and diversity (per generator, per content type) to inform practical deployment.
- Hyperparameter and augmentation ablations are missing: models are largely used with default settings from original papers. Systematically test augmentations (frequency-space, color jitter, camera pipeline simulation), regularization, and optimizer choices to identify what drives cross-model generalization.
- Detector fusion and ensembling are not explored: complementary strengths (e.g., frequency-domain vs spatial detectors, CLIP-based vs CNN-based) could be combined. Evaluate fusion strategies (late fusion, stacking, mixture-of-experts) and their robustness under shift and AF.
- Open-set/OOD detection is absent: real-world systems need to abstain on unfamiliar distributions. Add open-set metrics (AUROC for OOD, FPR@TPR for unknown classes) and evaluate selective prediction strategies.
- Efficiency, scalability, and deployment constraints are unreported: inference latency, memory footprint, and energy are not measured. Provide resource profiles, throughput on commodity hardware, and cost-accuracy trade-offs for large-scale moderation pipelines.
- Label noise and dataset integrity are not verified: “real” pools (e.g., LSUN/ImageNet) may contain mislabeled or edited images. Conduct label-audit procedures (human validation, cross-dataset duplicate detection, provenance checks) and report sensitivity to label noise.
- Temporal robustness and continual learning are unexplored: detectors may degrade as new generators emerge. Evaluate time-split (train on older models, test on newer), propose continual/adaptive learning protocols, and measure catastrophic forgetting.
- Provenance and watermark baselines are omitted: compare content-based detectors with watermark/provenance approaches (e.g., signature recovery, camera model identification) to understand complementary coverage and joint use cases.
- Partial forgery/localized edit detection is not considered: detectors may differ on localized manipulations (e.g., face-only edits). Introduce localized-forgery benchmarks and measure spatial detection/localization capabilities.
- Cross-modal effects are ignored: text-conditioned diffusion artifacts (e.g., typography, layout) and prompt-level signals may influence CLIP-based detectors. Systematically control for text/attribute prompts and measure sensitivity to prompt variability.
- Reproducibility is deferred: code, weights, and datasets are promised “upon acceptance” rather than provided now. Without immediate release, independent verification is blocked; publish artifacts with versioned configs, seeds, and scripts to enable replication.
- Security model and threat assumptions are under-specified: clarify attacker capabilities (black-box vs white-box, allowed post-processing), detector access controls, and operational thresholds for false positives/negatives in high-stakes settings.
- Failure analysis of extreme cases (e.g., MNW) is shallow: many methods collapse on MNW, but the paper does not investigate failure causes (generator-specific artifacts, content distribution, preprocessing mismatch). Perform root-cause analyses with feature attribution and controlled re-generation.
Glossary
- ACC: Classification accuracy; the proportion of correct predictions over all predictions. "We reported ACC, AP, AUC, and EER"
- Adapter (forgery-aware adapter): A lightweight, trainable module inserted into a model to capture task-specific signals; here, cues of image forgery. "FatFormer integrates a forgery-aware adapter to capture frequency cues"
- AFs (anti-forensics): Techniques or conditions designed to evade or degrade forensic detectors. "Vulnerability to AFs: A few studies~\cite{wang2020cnn} have evaluated robustness against conventional AFs, such as noise and compression. However, none have considered AFs based on GANs~\cite{uddin2019anti}, diffusion models~\cite{wang2023dire}, or optimization-based anti-forensic (AF) attacks."
- AP (average precision): The area under the precision–recall curve summarizing performance across recall thresholds. "We reported ACC, AP, AUC, and EER"
- AUC (Area Under the Curve): The area under a ROC curve, measuring trade-offs between true and false positive rates. "We reported ACC, AP, AUC, and EER"
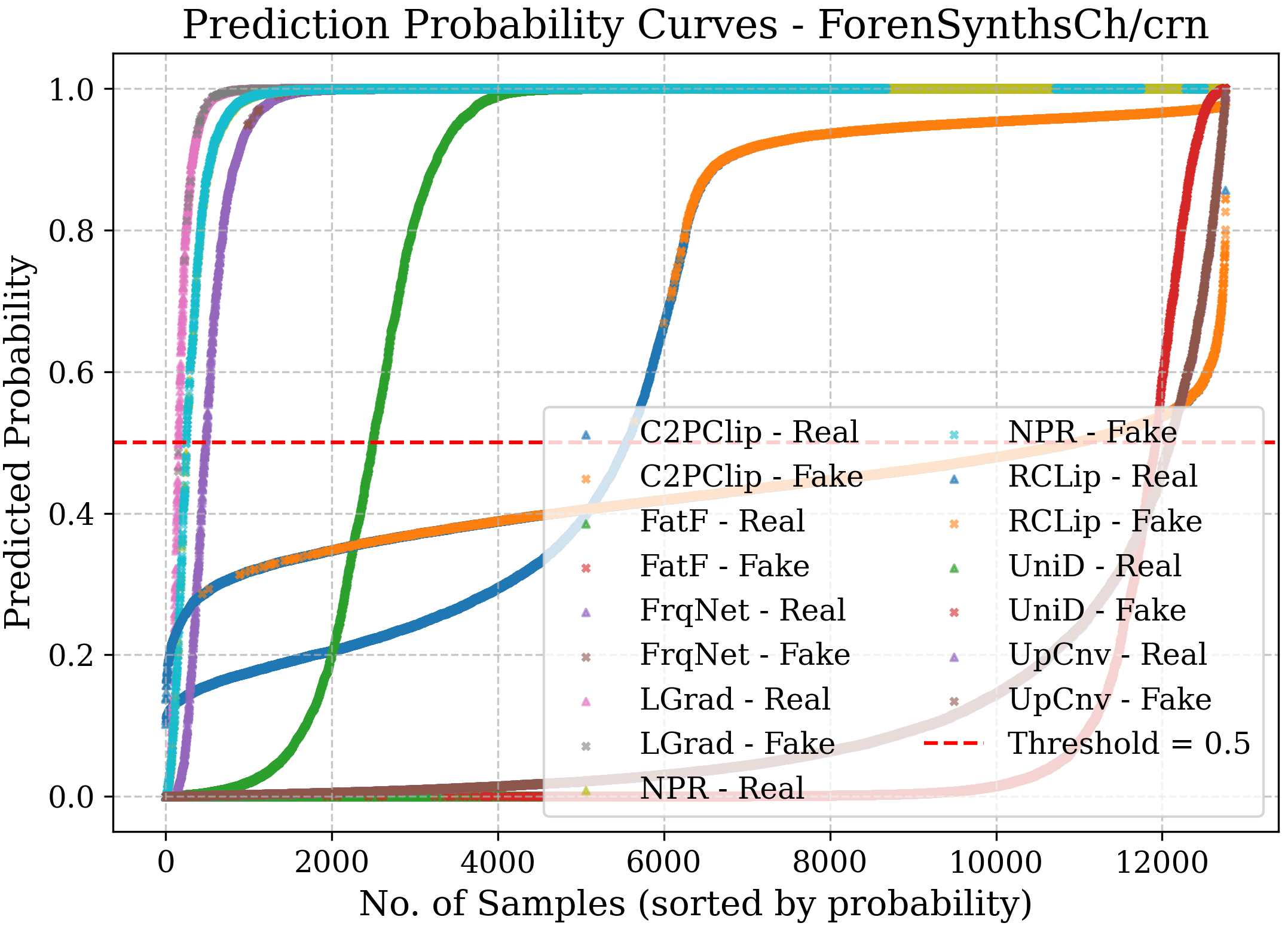
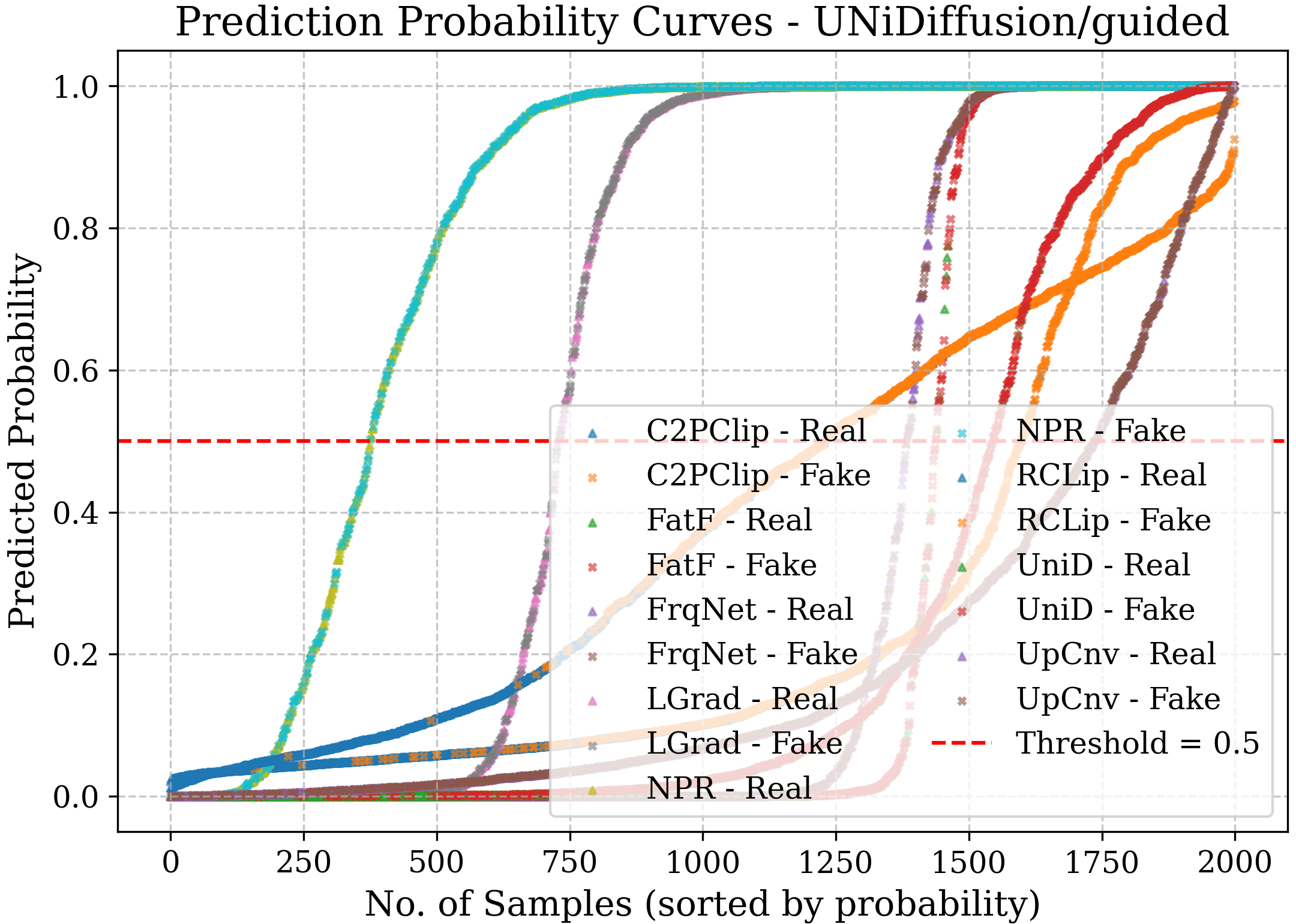
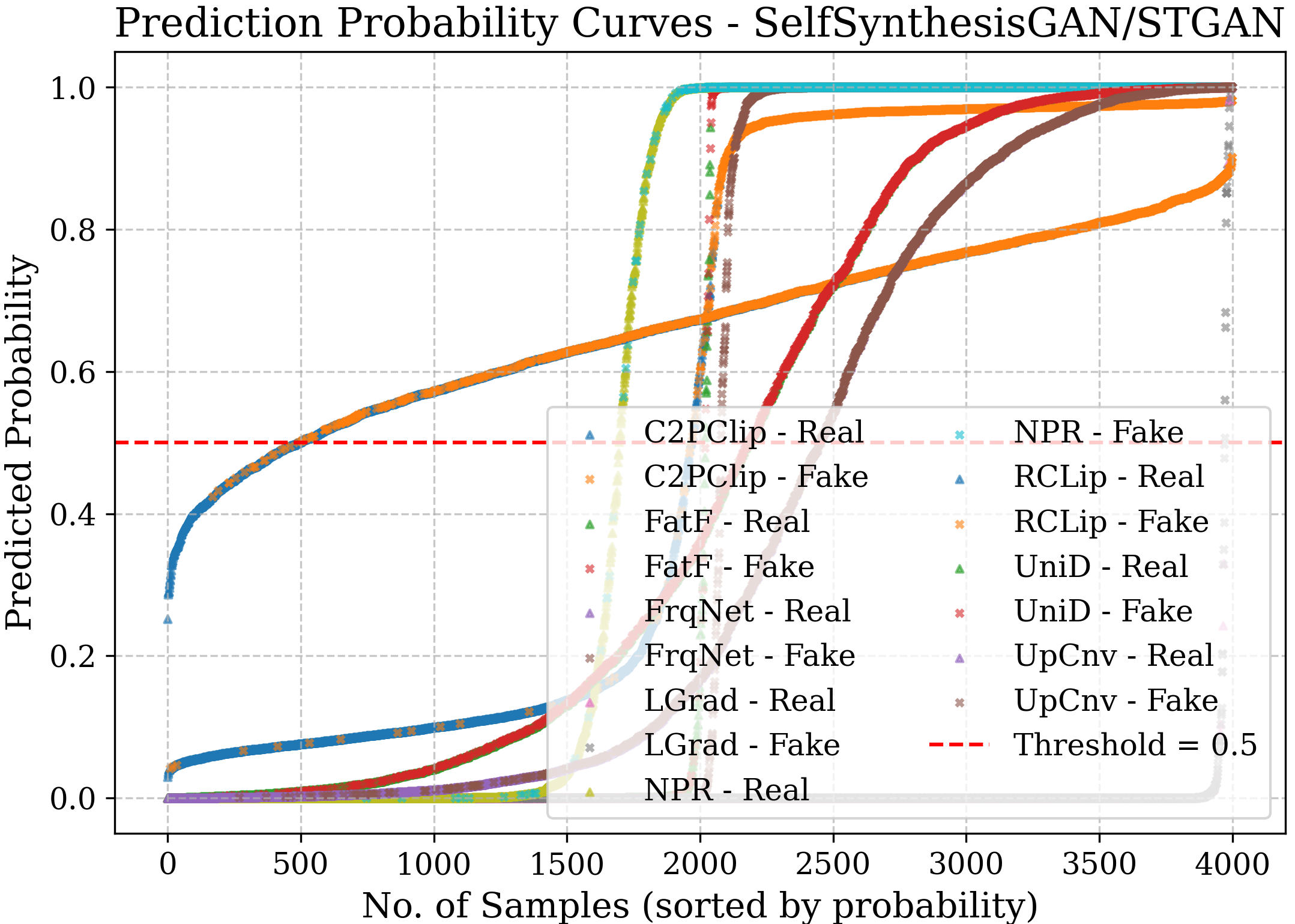
- Bias: Systematic tendency of a model toward one class or decision. "in most cases, NPR~\cite{tan2024rethinking} is biased towards the fake class, while UpConv~\cite{durall2020watch} tends to favor the real class."
- Category-common prompts: Shared textual prompts injected into a vision–LLM to improve generalization across categories. "C2PClip~\cite{c2pclip2025} injects category-common prompts to enhance generalization."
- Class-wise sensitivity: Per-class true positive rate, indicating how well each class is detected. "We evaluate performance using multiple metrics, including accuracy, average precision, ROC-AUC, error rate, and class-wise sensitivity."
- CLIP: A vision–language foundation model that aligns images and text in a joint embedding space. "Does not require retraining of CLIP"
- Confidence curve: A visualization of predicted probabilities for classes to inspect certainty and separability. "the confidence curve represents the prediction probabilities of each model for the real and fake classes"
- Cross-model transferability: The ability of a detector trained on one generative model to perform on other, unseen models. "with certain methods exhibiting strong in-distribution performance but degraded cross-model transferability."
- Data augmentation: Systematic transformations applied to training data to improve robustness and generalization. "Some approaches~\cite{wang2020cnn, tan2024rethinking} incorporate preprocessing and data augmentation techniques to enhance generalization"
- Debiasing techniques: Methods to mitigate systematic preferences toward particular classes or patterns. "Balanced objectives and debiasing techniques to avoid skew toward one class."
- Domain-agnostic features: Representations intended to be invariant across data domains or generative sources. "domain-agnostic features using meta-learning or multi-domain training."
- Encoder: The feature-extracting backbone of a model; often frozen and paired with trainable heads. "RINE~\cite{koutlis2024leveraging} employs a frozen CLIP encoder with a trainable importance estimator"
- EER (Equal Error Rate): The rate at which false acceptance equals false rejection; a threshold-agnostic error summary. "We reported ACC, AP, AUC, and EER"
- Explainable AI: Approaches that make model decisions understandable to humans via interpretable artifacts. "explainable AI techniques, such as attention visualization, causal reasoning, rule-based representations, and large language modelâdriven report generation"
- Explainability: The extent to which a model’s decisions can be understood and justified. "limited evaluation metrics that fail to capture generalization and explainability."
- Fine-tuned: A training paradigm where a pretrained model is further trained on a task-specific dataset. "ten SoTA forensic methods (scratch, frozen, and fine-tuned)"
- Foundation models: Large, pretrained models (e.g., CLIP) used for broad feature extraction and downstream tasks. "leverage SoTA foundation models for robust feature extraction to ensure better generalizability."
- Frequency domain artifacts: Forgery traces detectable in the Fourier domain rather than pixel space. "Captures frequency domain artifacts"
- Frequency-aware architecture: A model design that explicitly learns in or leverages frequency-space representations. "offering an end-to-end frequency-aware architecture"
- Frozen model: A model (or backbone) whose parameters are held fixed while downstream components are trained. "we selected two frozen-based models"
- Generalization: Performance of a detector on unseen data distributions or generative sources. "generalization capabilities of SoTA forensic methods"
- Grad-CAM: A technique that highlights image regions most influential to a CNN’s decision using gradients. "Grad-CAM heatmaps"
- Gradient-based features: Features derived from gradients of a pretrained generative model to capture subtle artifacts. "extract gradient-based features"
- In-distribution performance: Performance on data drawn from the same distribution as the training set. "strong in-distribution performance"
- Interpretability: Tools and analyses that reveal how a model arrives at its predictions. "We also further analyze model interpretability using confidence curves and Grad-CAM heatmaps."
- Nearest Pixel Relationship (NPR): A detector that exploits correlations among neighboring pixels to reveal upsampling artifacts. "The nearest pixel relationship (NPR)~\cite{tan2024rethinking} method takes a spatial perspective, focusing on the correlations among neighboring pixels to uncover artifacts introduced during the upsampling process."
- Preprocessing pipeline: A prescribed sequence of image loading, resizing, cropping, and normalization steps. "Most methods rely on predefined preprocessing pipelines tailored to specific datasets"
- ResNet: A residual network architecture commonly used as a pretrained backbone for fine-tuning. "using a pretrained ResNet (trained on ImageNet) fine-tuned on this dataset."
- ROC curve: A plot of true positive rate versus false positive rate across decision thresholds. "the ROC curve illustrates the trade-off between the true positive rate and false positive rate across different thresholds"
- ROC-AUC: Area under the ROC curve; a scalar measure of separability across thresholds. "We evaluate performance using multiple metrics, including accuracy, average precision, ROC-AUC, error rate, and class-wise sensitivity."
- Scratch-trained model: A model trained from randomly initialized weights rather than from a pretrained backbone. "We selected four scratch-trained models"
- Spectral analysis: Analysis in the frequency domain (e.g., via Fourier transforms) to detect distributional anomalies. "exploits spectral analysis to identify upsampling artifacts"
- Spectral features: Features computed in the frequency domain that characterize signal content. "Captured spectral features"
- Upsampling artifacts: Imperfections introduced by generative upsampling operations, often detectable in spatial or frequency cues. "identify upsampling artifacts"
Practical Applications
Below are actionable, sector-linked applications derived from the paper’s unified benchmarking framework, empirical findings on generalization and bias, and explainability analyses (confidence curves, ROC, Grad-CAM). Each item notes potential tools/workflows and key assumptions that influence feasibility.
Immediate Applications
- Industry — Social media/content platforms (software, media integrity)
- Application: Upload-time AI-image screening and human-in-the-loop moderation using an ensemble of top performers (e.g., C2P-CLIP, FatFormer, CLIP-based methods) to reduce cross-model failure modes observed in the study.
- Tools/workflows: “Screening Gateway” microservice; reviewer console with Grad-CAM overlays; per-generator threshold calibration via ROC curves; weekly dataset coverage checks aligned with Diffusion1kStep and MNW subsets.
- Assumptions/dependencies: Access to up-to-date diffusion/GAN samples; platform policies for false positives; human escalation paths; continuous re-calibration to counter domain shift.
- Newsrooms and fact-checkers (media, education)
- Application: Verification desk toolkit for image provenance triage that reports accuracy/AP/ROC metrics, confidence curves, and visual rationales.
- Tools/workflows: Risk-scoring panel; Grad-CAM heatmaps to justify flags; “two-detector agreement” rule to reduce bias highlighted in the paper; model cards including class-wise sensitivity.
- Assumptions/dependencies: Bandwidth to run multiple models; editorial thresholds tuned to minimize reputation/false-flag risk; access to new generative model exemplars.
- Finance/call centers/KYC (finance, cybersecurity)
- Application: Real-time screening of onboarding selfies, ID photos, and high-value video-call verifications to mitigate deepfake-enabled fraud.
- Tools/workflows: API that combines frequency- and CLIP-based detectors; threshold tuning to minimize false negatives on Diffusion1kStep-like cases; automatic escalation to manual review.
- Assumptions/dependencies: High-quality captures; PII and compliance controls; latency budgets; periodic vendor/benchmark re-tests to cover new generators.
- E-commerce, advertising, and marketplaces (retail, marketing)
- Application: Listing/ad pre-clearance to detect AI-generated product/model images and enforce disclosure policies.
- Tools/workflows: Batch scanner integrated into ad submission; ROC-based policy thresholds per category; reviewer aids with confidence curves to spot bias (e.g., NPR’s fake-class tilt).
- Assumptions/dependencies: Clear disclosure rules; appeal and override mechanisms; evolving generators require regular retraining/benchmark refresh.
- Biometrics and remote onboarding (security, healthcare access)
- Application: Liveness and synthetic-photo checks for face unlock and remote ID verification, leveraging frequency/spectral cues (e.g., FreqNet, UpConv) plus CLIP-based features.
- Tools/workflows: Edge pre-checks on device; backend ensemble verification; class-wise sensitivity calibration to reduce identity lockouts.
- Assumptions/dependencies: Camera access/quality; on-device compute or efficient distillations; privacy-by-design.
- Law enforcement, legal, and e-discovery (legal tech)
- Application: Evidence triage that attaches explainability artifacts to each detection decision (Grad-CAM regions, calibrated scores, error-rate profiles).
- Tools/workflows: Chain-of-custody logging; model cards with sensitivity/specificity per dataset family (GAN vs diffusion); expert review workflow.
- Assumptions/dependencies: Forensic validation standards; documented limitations on MNW-like unseen distributions; Daubert/Frye admissibility prep.
- Cybersecurity/SOC and enterprise collaboration (software, security)
- Application: Email/chat attachment scanner to flag possible synthetic images used in phishing and social engineering.
- Tools/workflows: “Detections-as-metadata” tags; SOC dashboard with model confidence distributions; alert suppression tuned by ROC/PR trade-offs.
- Assumptions/dependencies: False-positive cost controls; user education; secure handling of scanned media.
- MLOps and vendor selection (software/AI tooling)
- Application: Continuous benchmarking harness (“ForensicOps”) to evaluate internal and vendor detectors under unified protocols and report ACC/AP/AUC/EER with cross-model transfer tests.
- Tools/workflows: CI jobs seeded with the seven benchmark datasets; stress tests on Diffusion1kStep and MNW subsets; model cards and procurement scorecards.
- Assumptions/dependencies: Dataset licenses; reproducible pipelines; GPU budget; versioning and periodic refresh.
- Academia and education (academia, education)
- Application: Reproducible teaching labs and research baselines for deepfake detection and explainability; integrity checks for academic image submissions.
- Tools/workflows: Course modules that replicate the paper’s protocols; public leaderboards; classroom exercises on bias/thresholding.
- Assumptions/dependencies: Open access to code/datasets; institutional policies for image authenticity screening.
- Autonomous driving/robotics dataset governance (automotive, robotics)
- Application: Curation filters to detect and quarantine synthetic images in training/validation sets to prevent perception failures.
- Tools/workflows: Pre-ingest scanning; dataset “health” metrics by generator type; alerts when class-wise sensitivity degrades.
- Assumptions/dependencies: Not all synthetic images are harmful; domain experts decide where synthetic data is acceptable; performance tested on real-world distributions.
- IoT and surveillance (security, edge computing)
- Application: Monitoring for fake/injected frames in camera feeds using frequency and spatial artifact detection.
- Tools/workflows: Lightweight edge model + periodic cloud audits; anomaly dashboards; dual-channel verification.
- Assumptions/dependencies: Edge compute constraints; secure firmware; real-time requirements.
- Insurance claims (insurance, risk)
- Application: Claims photo triage with calibrated risk scores and explainability to prioritize manual investigation.
- Tools/workflows: Batch pre-screen; claim-level risk aggregation; auditor explanations.
- Assumptions/dependencies: Policy and customer communication around false positives; human review time.
- HR and trust/safety (enterprise)
- Application: Profile photo authenticity guard for recruiting platforms and internal directories to deter impersonation.
- Tools/workflows: Onboarding checks; user-visible explanations for contested decisions.
- Assumptions/dependencies: Consent and privacy; fair-use policies.
- Daily life/consumer safety (consumer software)
- Application: Browser/mobile extension that flags likely AI-generated images with a simple confidence band and a “second opinion” option.
- Tools/workflows: On-device light model plus cloud verification; user education nudges about uncertainty and false positives.
- Assumptions/dependencies: Transparent UX on limitations; opt-in privacy; regular model updates.
Long-Term Applications
- Standards and certification (policy, industry consortia)
- Application: Sector-wide standardized evaluation protocols, certification badges, and RFP templates based on the unified benchmarking setup (metrics, cross-model tests, explainability).
- Tools/workflows: Third-party certification labs; minimum performance thresholds (e.g., ROC-AUC on Diffusion1kStep-like sets); model cards with class-wise sensitivity.
- Assumptions/dependencies: Multi-stakeholder governance; consensus on test sets and disclosure; update cadence as generators evolve.
- Content provenance ecosystem (policy, software)
- Application: Combine cryptographic provenance (e.g., C2PA) with detector stress tests from the benchmark to audit unlabeled media and watermark failures.
- Tools/workflows: Provenance-verification pipeline + detector fallback; incident reports when detectors and provenance disagree.
- Assumptions/dependencies: Broad adoption of provenance standards; legal frameworks for disclosure; coordinated response to evasion.
- Real-time video conferencing and streaming protection (communications, security)
- Application: On-device or near-real-time detection of synthetic faces/backgrounds in calls, robust to anti-forensic (AF) attacks.
- Tools/workflows: Distilled/quantized variants of strong models; adaptive thresholds per device; AF-aware training and monitoring.
- Assumptions/dependencies: Edge compute; low-latency pipelines; privacy-preserving designs.
- Adversarial testing and AF-robust defenses (software security)
- Application: Red-team frameworks that generate GAN/diffusion-based AFs and optimization attacks, and train detectors to be robust against them.
- Tools/workflows: AF scenario library; robustness dashboards; automated regression on MNW-like hard distributions.
- Assumptions/dependencies: Access to evolving generator/AF toolchains; compute; clear robustness KPIs.
- Market integrity monitoring (finance, policy)
- Application: Synthetic-media early-warning systems that track spikes in AI-generated imagery tied to market-moving narratives.
- Tools/workflows: Media ingestion + detector ensemble + anomaly detection; analyst triage workflows; compliance reporting.
- Assumptions/dependencies: Data partnerships; careful false-positive governance; legal boundaries.
- Federated/private detection networks (privacy tech)
- Application: Privacy-preserving collaborative model updates (federated learning) to keep detectors current with new forgery styles without centralizing sensitive data.
- Tools/workflows: Federated training with unified metrics; secure aggregation; drift monitoring via confidence/ROC shifts.
- Assumptions/dependencies: Cross-org agreements; reliable telemetry; privacy regulations.
- Healthcare and scientific publishing forensics (healthcare, academia)
- Application: Authenticity checks for medical/scientific images to protect against manipulated or synthetic figures in research and clinical workflows.
- Tools/workflows: Journal submission screening; hospital PACS triage flags; explainable reports accompanying decisions.
- Assumptions/dependencies: Domain-specific calibration (minimize false positives); sensitive-data handling; governance for disputes.
- Explainable AI upgrades (software, governance)
- Application: LLM-assisted narrative explanations that translate confidence curves, ROC trade-offs, and Grad-CAM maps into auditor- and user-friendly reports.
- Tools/workflows: “Decision brief” generator; bias diagnostics that quantify fake/real skew and recommend thresholds.
- Assumptions/dependencies: Guardrails for hallucinations; audit trails; human oversight.
- Deepfake insurance and risk products (insurance, finance)
- Application: Underwriting models that incorporate standardized detector scores and generalization metrics as part of fraud risk assessment.
- Tools/workflows: Risk APIs; policy terms tied to detection coverage levels; incident analytics.
- Assumptions/dependencies: Actuarial validation; regulatory approval; evolving threat models.
- Living benchmarks and dataset refresh pipelines (research infrastructure)
- Application: Continually updated public benchmarks that add new generators (e.g., MNW-like expansion) and report longitudinal generalization/bias.
- Tools/workflows: Data contribution protocol; versioned leaderboards; governance on ethical sourcing.
- Assumptions/dependencies: Sustainable funding; community participation; licensing.
- Open ForensicOps platforms (developer ecosystems)
- Application: Open-source orchestration for training, evaluating, and deploying detectors under unified, reproducible protocols with CI/CD integration.
- Tools/workflows: Templates for scratch/frozen/fine-tuned models; plug-in metrics; dataset adapters.
- Assumptions/dependencies: Maintainer community; reproducible compute; security hardening.
Notes on cross-cutting assumptions and dependencies:
- Rapid generator evolution (GANs to advanced diffusion) necessitates frequent re-benchmarking and ensemble approaches to mitigate the generalization gaps revealed by Diffusion1kStep and MNW results.
- Thresholds must be calibrated per domain using ROC and class-wise sensitivity to manage costs of false positives/negatives and model bias (e.g., NPR’s fake-class bias).
- Human-in-the-loop review, clear appeals, and explainability artifacts (Grad-CAM, confidence curves) are essential for trust, legal defensibility, and continuous improvement.
- Compute, dataset licensing, privacy compliance, and governance around misuse prevention are practical constraints for deployment at scale.
Collections
Sign up for free to add this paper to one or more collections.