- The paper introduces a novel penalty for wrong-direction updates in PPO, keeping the importance ratio close to 1 for improved learning stability.
- The paper details a directional-clamp strategy using tunable hyperparameters (alpha and beta) to enhance gradient updates and accelerate convergence.
- The paper presents theoretical justifications and empirical evaluations on MuJoCo environments, demonstrating superior performance over standard PPO variants.
"Directional-Clamp PPO" Implementation and Application
This essay discusses the key aspects of the paper titled "Directional-Clamp PPO", focusing on the methodology, implementation details, theoretical justifications, and empirical performance of the proposed Directional-Clamp PPO (DClamp-PPO) algorithm. The primary goal of DClamp-PPO is to refine the Proximal Policy Optimization (PPO) by addressing its tendency to make updates in the "wrong" direction during policy optimization, thus enhancing learning stability and performance.
Methodology Overview
The core insight of the paper is that during the PPO optimization process, the importance sampling ratios often drift in an undesirable manner—it lowers the probability of advantageous actions or raises that of disadvantageous ones, which hinders performance. The paper introduces a novel mechanism to counteract this drift by penalizing updates that move in the wrong direction more strictly.
PPO and Its Limitations
PPO is a popular policy gradient method known for its simplicity and effectiveness across various domains. It uses a clipped objective function to maintain updates within a conservative region and prevent excessive optimization. However, the algorithm's stochastic nature allows a significant portion of action probabilities to drift counterproductively.
Directional-Clamp Strategy
DClamp-PPO modifies the original PPO clipping surrogate with an additional penalty that activates in the strictly wrong-direction regions. This is quantified using a tunable parameter β. The penalty increases the gradient's steepness, thus enforcing a stronger pull toward the center (ratio of 1), effectively mitigating undesirable updates.
The function fDClamp(wθ(s,a),ϵ,α,β) defines the clamping strategy where the importance ratio wθ(s,a) is either increased or decreased based on the advantage estimate’s sign and a directional-clamp parameter α>1.
Theoretical Considerations
The authors provide theoretical evidence that DClamp-PPO maintains the PPO ratios closer to 1 more effectively than standard PPO, especially when initiated from a position in a strict wrong-direction region. This theory is backed by Lemma 1, which offers insight into why DClamp-PPO can better confine policy updates to stay closer to the trusted region, supporting both stable and efficient learning dynamics.
Implementation Details
The implementation of DClamp-PPO is straightforward yet impactful, requiring negligible computational overhead compared to PPO. The strategy involves the following steps:
- Initialization: Define hyperparameters α>1, β∈(0,1), and ϵ for the surrogate loss.
- Policy Update: Compute advantage estimators and apply the DClamp-PPO surrogate function to optimize the policy iteratively.
- Penalization: Actively apply additional penalties in the strict wrong-directional regions to steer policies more effectively toward advantageous actions.
Algorithm 1 provides the pseudo-code for DClamp-PPO, clearly outlining the integration of the directional-clamp strategy into the standard PPO update cycle.
Empirical Evaluation
DClamp-PPO is empirically evaluated on various complex control tasks such as MuJoCo environments, comparing its performance with baseline PPO and its variants: PPO-RB and Leaky-PPO. The results consistently demonstrate that DClamp-PPO outperforms these algorithms in terms of convergence speed and final performance scores across different environments, as exemplified by its notable improvements in environments such as Hopper-v4 and Humanoid-v4.
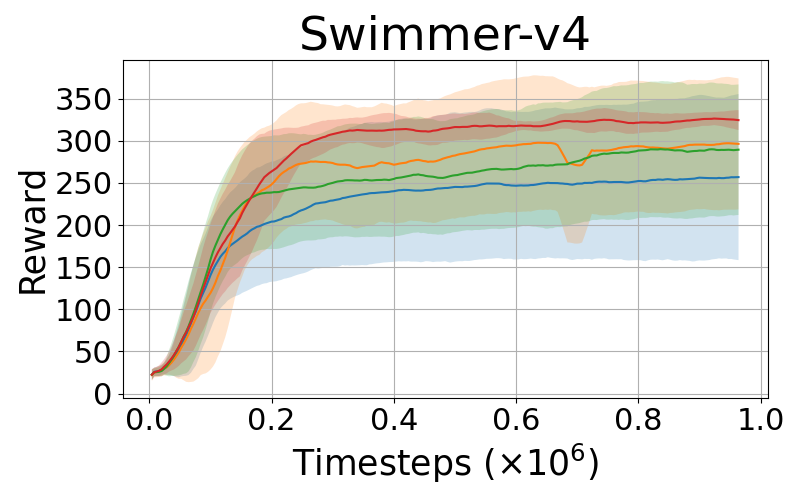
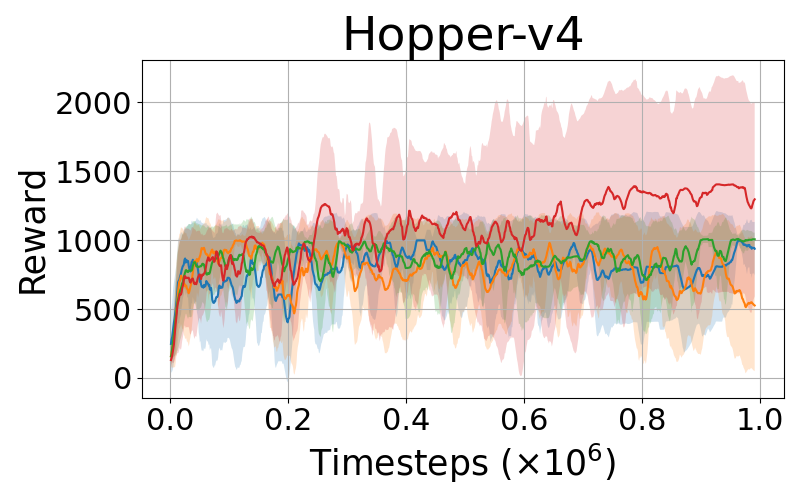
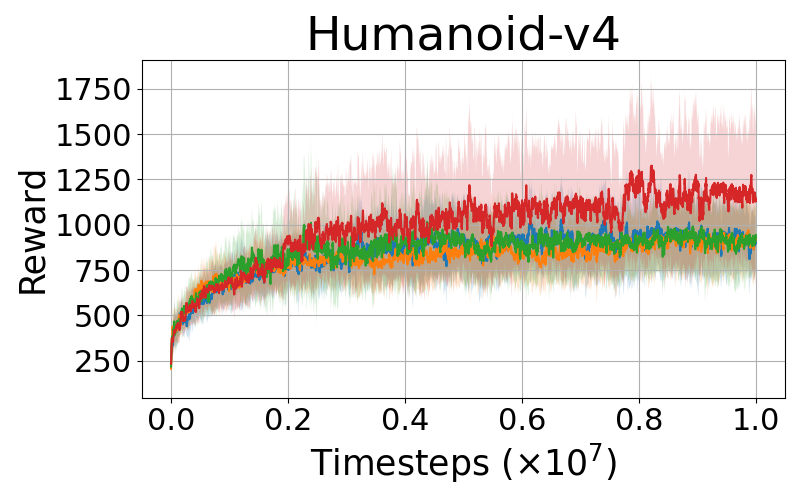
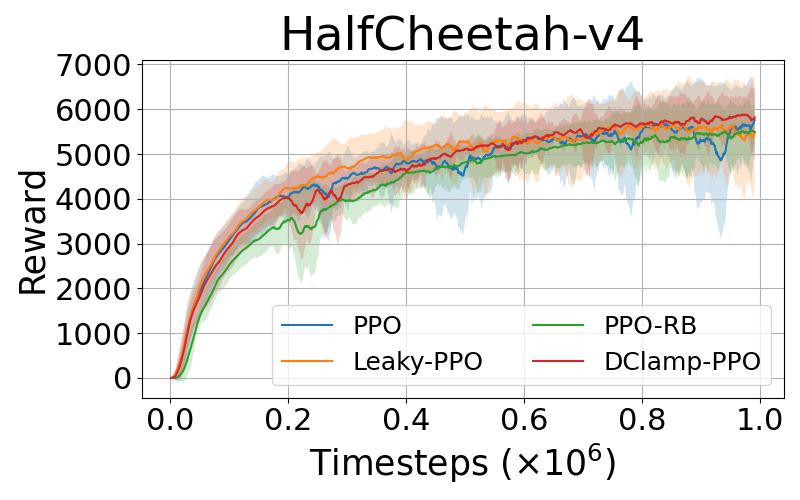
Figure 1: Performance comparisons of PPO, PPO-Leaky, PPO-RB, and DClamp-PPO across MuJoCo environments.
Impact of Hyperparameters
The study also provides insights into the role of hyperparameters α and β, emphasizing their influence on performance. Appropriate tuning of these parameters allows DClamp-PPO to effectively balance exploration-exploitation dynamics and maintain policy stability.
Conclusion
The paper "Directional-Clamp PPO" identifies and addresses a limitation in the PPO algorithm by introducing a targeted penalization for wrong-direction updates. DClamp-PPO provides a robust framework for enhancing PPO’s performance, validated by both theoretical analysis and empirical data across standard RL benchmarks. The insights and methods presented could guide future research into developing more sophisticated and direction-aware policy optimization techniques.