Rethinking LLM Human Simulation: When a Graph is What You Need
Abstract: LLMs are increasingly used to simulate humans, with applications ranging from survey prediction to decision-making. However, are LLMs strictly necessary, or can smaller, domain-grounded models suffice? We identify a large class of simulation problems in which individuals make choices among discrete options, where a graph neural network (GNN) can match or surpass strong LLM baselines despite being three orders of magnitude smaller. We introduce Graph-basEd Models for human Simulation (GEMS), which casts discrete choice simulation tasks as a link prediction problem on graphs, leveraging relational knowledge while incorporating language representations only when needed. Evaluations across three key settings on three simulation datasets show that GEMS achieves comparable or better accuracy than LLMs, with far greater efficiency, interpretability, and transparency, highlighting the promise of graph-based modeling as a lightweight alternative to LLMs for human simulation. Our code is available at https://github.com/schang-lab/gems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: Do we really need giant chatbots (LLMs) to predict how people will choose among multiple options, or can a much smaller, simpler model do just as well?
The authors show that for many “multiple‑choice” style tasks (like surveys, votes, quizzes, or simple decisions), a small graph-based model can match or beat strong LLM baselines while being far cheaper, faster, and easier to understand. Their approach is called GEMS (Graph-basEd Models for human Simulation).
What questions did the researchers ask?
They focused on human behaviors that are multiple-choice decisions and asked:
- Can a graph model predict which option a person will pick as well as (or better than) big LLMs?
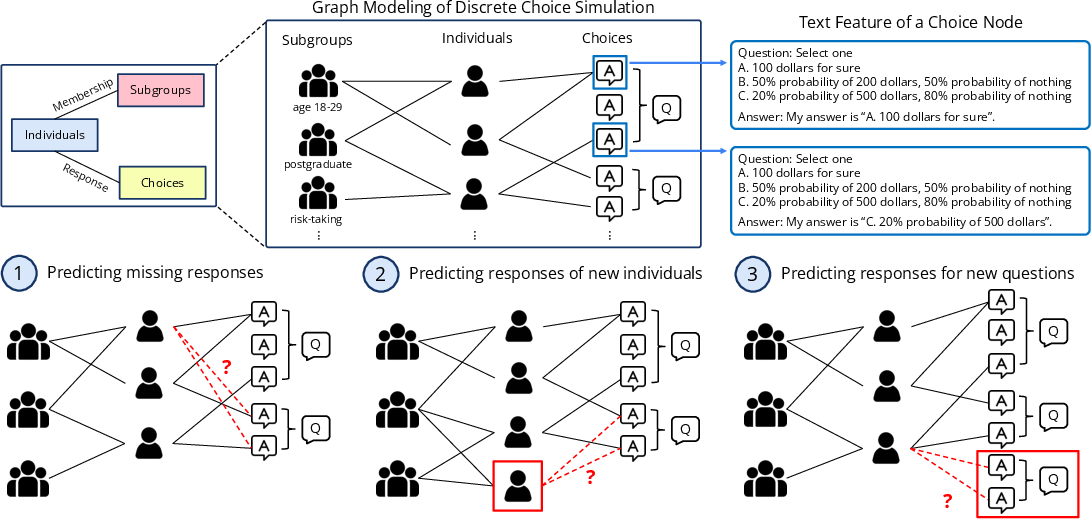
- Can this work in three common situations: 1) filling in a person’s missing answers, 2) predicting answers for completely new people, 3) predicting answers to brand-new questions?
- Is the graph approach more efficient, interpretable, and trustworthy than LLMs?
How did they do it?
Think of a graph like a map of dots and lines:
- Dots (nodes) represent people, groups (like “teenagers” or “college graduates”), and choices (each question’s options).
- Lines (edges) show relationships:
- A person belongs to some groups (membership edges).
- A person picked a particular option for a question (response edges).
Turning choices into a graph
- Each question with its options becomes several “choice” nodes (one per option).
- Each person is connected to the option they chose.
- People are also connected to group nodes that describe them (such as age group or education level).
- The prediction problem becomes: Given a person and a question, which option node will they connect to? This is called link prediction (guessing which new line should be drawn).
Teaching the graph to predict links
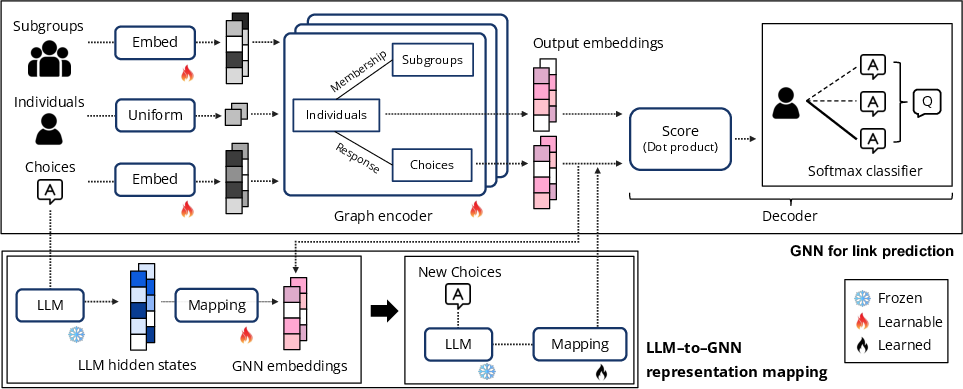
They use a Graph Neural Network (GNN), which is a model built to learn from the structure of graphs. In everyday terms, it learns from “who’s connected to what” and “who is similar to whom.”
- The GNN reads the graph and creates an “embedding” (a compact set of numbers, like coordinates) for each person and each choice.
- To predict which option a person will pick, it compares the person’s embedding with the embeddings of that question’s options and picks the best match (like seeing which dot is closest in an invisible coordinate space).
Important: In most cases, the GNN does not need to read the text of the questions or options. It learns patterns purely from who picked what.
New questions need some language help
For brand-new questions, there are no edges yet, so the GNN can’t learn an embedding for the new options from the graph alone. Here, the authors use a tiny bit of LLM help:
- They take a frozen LLM (like a dictionary that turns text into a vector) to encode the new question’s option text into a vector.
- They train a simple linear mapping (a basic math transformation) to convert that vector into the GNN’s embedding space.
- This lets the GNN score the new options, even without seeing anyone’s answers to them.
What did they find?
Across three datasets:
- OpinionQA: 76,000 people answering 500 public-opinion questions.
- Twin‑2K: 2,000 people answering 150 items on preferences and personality.
- Dunning–Kruger replication: ~3,000 people answering 20 grammar/logical reasoning questions with confidence ratings.
The main results:
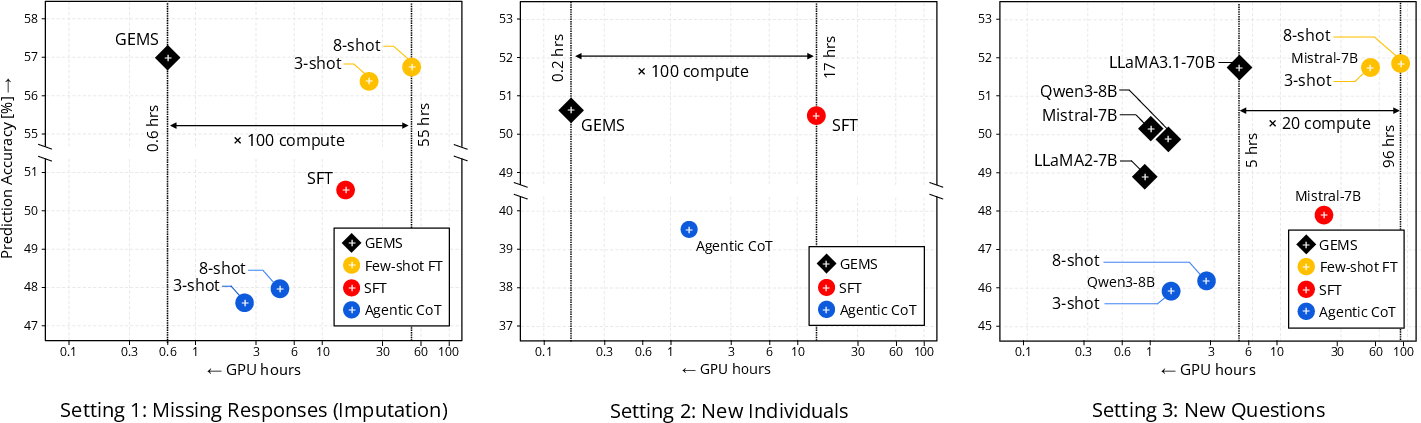
- For filling in missing answers and predicting for new people, the GNN matched or beat strong LLM baselines without reading any text.
- For brand-new questions (where text matters), adding the tiny LLM-to-GNN mapping made the GNN competitive with fine-tuned LLMs and clearly better than prompting alone.
- The GNN used about 100 times less compute and about 1,000 times fewer parameters than the LLMs.
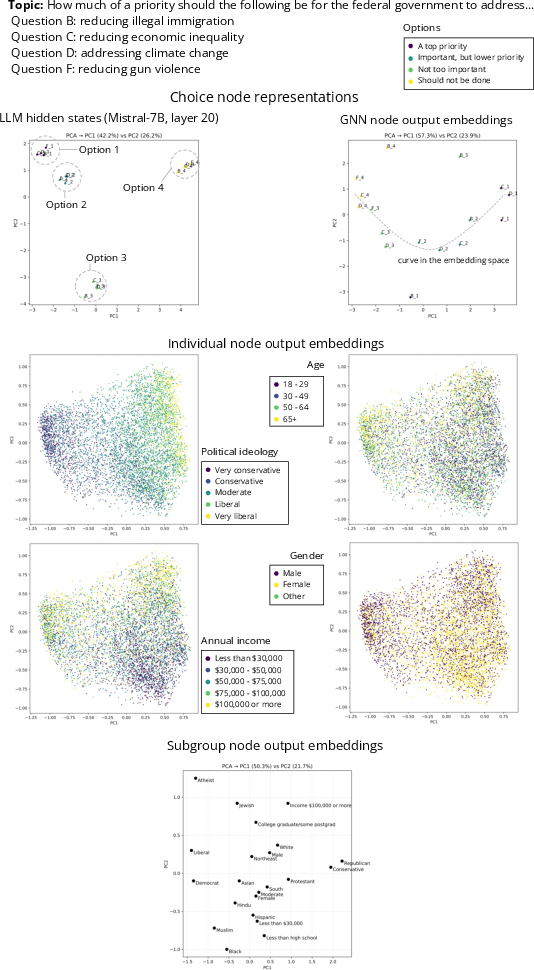
- The GNN was more interpretable: its embeddings of people, groups, and choices showed meaningful structure (for example, political leanings or income/education differences emerged naturally).
- It was more transparent and had fewer risks of hidden training data or social biases that can affect LLMs.
Why this matters:
- It shows that for lots of practical “which option will a person pick?” problems, you don’t need a huge, expensive LLM. A small, specialized graph model can do the job as well or better.
What’s the impact?
- Lower cost and greener: Because the GNN is so much smaller, it’s far cheaper and faster to train and run. More researchers and organizations can use it without giant computers.
- Scales better: The approach can handle very large datasets without exploding costs.
- Easier to trust and explain: You can inspect the embeddings and see why the model made a prediction. It’s trained on clearly defined data, not mysterious internet text.
- Use the right tool for the job: If you need open‑ended writing or creative language, use an LLM. But for many multiple-choice prediction tasks, a graph model may be “what you need,” using language only when a brand-new question requires it.
Key terms, simply explained
- LLM: A huge AI that predicts text; great at understanding and generating language.
- Graph Neural Network (GNN): An AI that learns from networks of connections (graphs).
- Embedding: A set of numbers that represent an item (like a person or choice) so similar things end up with similar numbers.
- Link prediction: Guessing which new connections (edges) should exist between nodes in a graph.
- Prompting vs. fine-tuning:
- Prompting: Asking an LLM a question with some examples.
- Fine-tuning: Training the LLM on lots of task-specific examples so it learns the task better.
- LLM-to-GNN mapping: A simple transformation that converts an LLM’s text-based vector into the GNN’s embedding space, used for new questions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper—framed as concrete, actionable items for future research.
- Generalization beyond discrete, single-choice tasks: How would the approach extend to multi-select responses, ordinal scales, or continuous outcomes (e.g., ratings, time-to-event)?
- Joint cold-start: The paper does not evaluate the challenging case where both the individual and the question are unseen at test time; methods for simultaneous new-individual/new-question prediction are needed.
- Dynamic behavior: No modeling of temporal evolution (e.g., attitude drift, learning, or repeated measures); evaluate time-aware graphs and sequence-aware GNNs.
- Graph design choices: Effects of alternative node/edge types are unexplored—e.g., adding explicit question nodes, edges linking semantically similar choices, or knowledge-graph relations between options.
- Subgroup construction sensitivity: The paper defines subgroups from nine demographics or pre-question confidence ratings; robustness to different subgroup definitions, granularities, and overlapping/multi-label subgroup membership is not assessed.
- Unseen/novel subgroups: How to handle out-of-vocabulary subgroup values at inference (new demographic categories, non-binary/continuous attributes)?
- Text-free assumptions in Settings 1–2: The method achieves parity without text; test whether integrating textual features in the graph (e.g., via textual embeddings for choices or subgroup descriptors) improves performance or robustness.
- Linear LLM-to-GNN projection: The mapping is linear; evaluate non-linear, regularized, or contrastive mappings, multimodal adapters, and alignment objectives to better capture semantic structure.
- Choice of LLM for mapping: The mapping performance tracks the underlying LLM; quantify how mapping benefits from stronger LLMs (e.g., 70B, GPT-class) and whether model distillation or ensemble hidden states yield gains.
- Cross-lingual/generalization: All datasets are English; assess performance when question/option text is multilingual and when subgroup features span cross-cultural contexts.
- Scalability and sparsity: While compute is lower than LLMs, scaling to much larger graphs (millions of users/questions) with highly sparse interactions, long-tail options, or large option sets per question is not benchmarked.
- Rare-choice performance: Accuracy may be dominated by frequent choices; evaluate performance, calibration, and recall on rare options and long-tail distributions.
- Evaluation breadth: The paper reports accuracy only; add metrics for calibration (e.g., Brier score, ECE), reliability (test-retest gaps vs. human retest), subgroup fairness (per-group accuracy disparities), and distributional similarity to human response distributions.
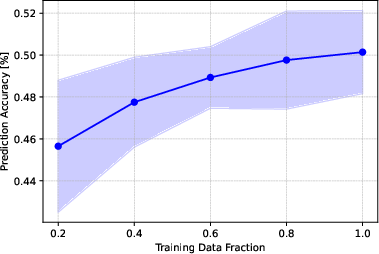
- Statistical significance and robustness: Results are averaged over 3 seeds; conduct significance testing, confidence intervals, and sensitivity analyses to splits, masking rates, and hyperparameters.
- Fairness and bias: The method claims reduced contamination, but learned embeddings may still encode data-driven biases; measure disparate impact, subgroup-specific error, and fairness trade-offs vs. LLMs.
- Causal validity and counterfactuals: The model is predictive; capabilities for causal inference (e.g., simulating interventions, counterfactual responses) are not explored.
- Interpretability quantification: Embedding inspections are qualitative (PCA); develop quantitative probes (e.g., supervised concept alignment, probing classifiers, influence functions) to assess whether embeddings reflect ground-truth latent constructs.
- Robustness to feature noise/missingness: No experiments on noisy, incomplete, or adversarially perturbed individual features or responses; evaluate resilience and imputation strategies.
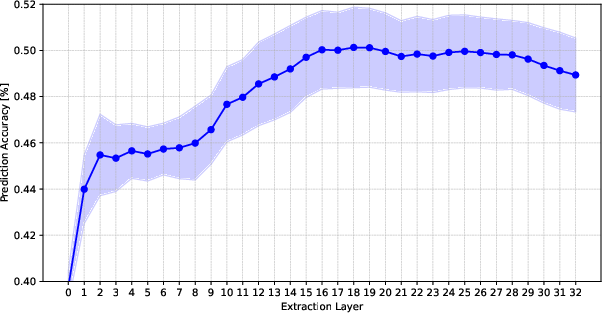
- Prompt sensitivity in projection: The paper notes lower variance for the projection but does not quantify sensitivity to different prompt templates, tokenization, or hidden-state extraction layers.
- Alternative GNN architectures: Only RGCN, GAT, GraphSAGE are tested; benchmark LightGCN, KGAT, HGT, message-passing with attention across relation types, and graph contrastive learning objectives.
- Negative sampling and class weighting: The decoder uses softmax over options per question without explicit class weighting; explore loss reweighting, focal losses, or hard negative mining to improve rare-option prediction.
- Privacy and transparency: While training data are “transparent,” implications for privacy (e.g., de-anonymization risk via embeddings) are not analyzed; evaluate privacy-preserving training (DP-GNNs, federated setups).
- Domain transfer: Performance across datasets is shown, but formal transfer learning (training on one dataset, testing on another) and out-of-domain generalization are not evaluated.
- Error analysis: The paper lacks a systematic breakdown of failure cases where GNNs underperform LLMs (e.g., semantically subtle questions, compositional reasoning); targeted analyses could guide hybrid designs.
- Hybrid graph–LLM integration: Beyond linear mapping in Setting 3, investigate end-to-end joint training (e.g., co-training text encoders and GNNs), retrieval-augmented graphs, or transformer–GNN fusion for richer relational-textual reasoning.
Practical Applications
Practical Applications of the Paper’s Findings
This paper introduces GEMS (Graph-basEd Models for Human Simulation), a graph neural network framework that casts discrete-choice human simulation as link prediction on a heterogeneous graph. GEMS matches or surpasses strong LLM baselines while using far less compute, offering interpretable embeddings and transparent training. Below are actionable applications grouped by deployment horizon.
Immediate Applications
- Survey research and public opinion (policy, academia)
- Use cases:
- Impute missing responses to reduce respondent burden and clean incomplete datasets.
- Predict responses of new respondents from demographics (cold-start), enabling targeted sampling and stratification.
- Evaluate and pilot newly designed survey questions via LLM-to-GNN projection without full-scale fielding.
- Subgroup analysis via interpretable embeddings (e.g., ideology vs. class axes), improving cross-tabs and segment discovery.
- Tools/products/workflows:
- SurveyGraph: a SaaS that ingests survey data, builds the heterogeneous graph (subgroups, individuals, choices), trains GEMS, and serves imputation/cold-start predictions.
- QuestionLab: a lightweight pipeline to project LLM hidden states into GNN space for new items, estimate likely distributional responses, and flag wording issues via embedding similarity.
- Assumptions/dependencies:
- Availability of prior response data, consistent subgroup definitions (e.g., demographics), and discrete-choice items.
- Stationarity of response distributions across time; domain drift requires monitoring.
- Political analytics and polling (policy, industry)
- Use cases:
- Microtargeting response prediction for voter segments (e.g., ballot measure support).
- Early warning of opinion shifts by tracking embedding drift of choices or subgroups.
- Scenario testing for alternative wording or framing of policy questions before deployment.
- Tools/workflows:
- PollingSim: an API that predicts subgroup choice distributions under different question framings and surfaces the most sensitive segments.
- Assumptions/dependencies:
- Careful governance to avoid misuse (e.g., manipulative targeting); robustness checks to ensure demographic fairness.
- Marketing and product analytics (software, finance, retail)
- Use cases:
- Predict discrete customer actions (opt-in/out, plan selection, feature enablement) in cold-start and sparse-data settings.
- Forecast A/B test outcomes with limited data by leveraging relational structure (co-selected options and subgroup memberships).
- Personalization for new users using subgroup-derived embeddings rather than heavy LLM inference.
- Tools/workflows:
- ChoiceGraph plug-in for product analytics stacks (Amplitude/Mixpanel) to build graphs and serve real-time propensity scores for discrete actions.
- Assumptions/dependencies:
- Clear mapping of “choice” nodes to product decisions; graph needs ongoing refresh to handle rapidly changing products.
- Education and assessment (education)
- Use cases:
- Knowledge tracing for multiple-choice exams, predicting missing or upcoming responses.
- Adaptive testing: choose next items for students to maximize information gain while reducing test length.
- Rapid vetting of new questions (LLM-to-GNN mapping) before adding to item banks.
- Tools/workflows:
- GEMS-Ed: adaptive testing service integrating student-subgroup membership (e.g., prior performance bands) with choice embeddings for item selection.
- Assumptions/dependencies:
- Item response theory alignment; careful calibration to avoid overfitting to subgroup signals and preserve item fairness.
- Healthcare questionnaires and patient-reported outcomes (healthcare)
- Use cases:
- Impute missing answers in clinical PROs to reduce respondent burden and improve data completeness.
- Predict adherence-related choices (e.g., attendance, self-management step selection) for new patients using subgroup features.
- Vet new survey items or digital triage questions with LLM-to-GNN projection before deployment.
- Tools/workflows:
- PRO-Graph: clinical survey module that builds graphs from EHR-linked demographics and PRO items; includes an auditing dashboard for subgroup bias.
- Assumptions/dependencies:
- Regulatory compliance (HIPAA/GDPR); de-identification of individuals; strict governance to avoid using predictions for punitive decisions.
- Social science experiments (academia)
- Use cases:
- Replicability checks: simulate expected response distributions across subgroups before fielding.
- Power analysis via simulated distributions derived from embeddings; prioritize stimuli with high discriminative potential.
- Tools/workflows:
- ExperimentSim: a workflow to pretest experimental stimuli and outcome labels via GEMS embeddings.
- Assumptions/dependencies:
- Simulations are predictive, not causal; careful interpretation and preregistration needed.
- Fairness, auditing, and interpretability (cross-sector)
- Use cases:
- Inspect subgroup and choice embeddings to identify systematic biases or undesired clustering (e.g., stereotyping).
- Evaluate stability under small prompt or data perturbations; GEMS’ order-invariant aggregation reduces format sensitivity.
- Tools/workflows:
- Embedding Audit Dashboard: visual analytics for variance, principal components, and subgroup spread; fairness metrics over predicted distributions.
- Assumptions/dependencies:
- Requires agreed-upon fairness criteria and domain-appropriate subgroup definitions.
- ML/AI operations: compute-efficient simulation (software)
- Use cases:
- Replace LLM-based discrete-choice simulators with GEMS to reduce compute by ~100× and parameters by ~1000× while maintaining accuracy.
- Scale simulations to larger datasets and more frequent retraining cycles.
- Tools/workflows:
- GEMS library (github.com/schang-lab/gems) integrated into existing MLOps pipelines; includes masking strategies and link prediction training.
- Assumptions/dependencies:
- Engineering for graph construction; monitoring for data drift and periodic retraining.
Long-Term Applications
- Large-scale societal digital twins (policy, academia)
- Use cases:
- City- or nation-level simulation of discrete civic choices (e.g., ballot initiatives, public service uptake) under alternative framings or timing.
- Scenario analysis for emergency communications and behavior-influencing campaigns.
- Tools/products:
- CivicTwin: platform that maintains evolving population graphs, supports real-time “what-if” simulations, and feeds insights to policy planners.
- Assumptions/dependencies:
- Dynamic graphs with time-aware edges; governance and ethics for population-level simulation; robust domain adaptation.
- Pluralistic alignment modules for AI systems (software, safety)
- Use cases:
- Incorporate diverse subgroup preference embeddings into alignment objectives (e.g., RLHF reward models) to avoid “monolithic” value representations.
- Tools/products:
- Plurality Module: a GNN-derived preference layer plugged into training pipelines as an auxiliary objective.
- Assumptions/dependencies:
- Care in aggregating subgroup preferences and avoiding arbitrary weighting; clear policy on representation of minority views.
- Language-agnostic question generalization (education, survey research, global deployments)
- Use cases:
- Map multilingual question/option text to GNN space via improved LLM-to-GNN projections, enabling cross-language survey deployment.
- Tools/products:
- PolyMap: projection service supporting multiple LLM encoders; standardized item metadata schemas.
- Assumptions/dependencies:
- Quality multilingual LLMs; rigorous validation for semantic equivalence across languages.
- Real-time adaptive engines (education, marketing, healthcare)
- Use cases:
- Active learning that selects the next question or intervention to maximize information and minimize burden; dynamic retraining from incoming edges.
- Tools/products:
- ActiveChoice: bandit-driven controller over the GEMS graph for item/intervention selection with safety constraints.
- Assumptions/dependencies:
- Online learning infrastructure; guardrails for exploration in sensitive domains.
- Clinical decision support and trial design (healthcare)
- Use cases:
- Simulate discrete patient choices under different informational framings to design trials and improve adherence strategies.
- Tools/products:
- TrialSim: embedding-based simulator for trial recruitment and retention scenarios, coupled with compliance analytics.
- Assumptions/dependencies:
- Strict privacy and ethics; non-causal nature of predictions; need for clinical oversight.
- Privacy-preserving and federated graph learning (cross-sector)
- Use cases:
- Train GEMS across institutions with sensitive data using federated, differentially private graph learning.
- Tools/products:
- Federated GEMS: edge masking and secure aggregation protocols for heterogeneous graphs.
- Assumptions/dependencies:
- Secure multi-party computation; DP budget management; interoperable schemas.
- Integration with knowledge graphs and recommender systems (software, media)
- Use cases:
- Combine choice graphs with knowledge graphs (items, attributes, relations) for richer preference modeling and cold-start handling.
- Tools/products:
- KG+GEMS: pipeline to co-train user-choice and item-attribute relations for improved discrete-choice prediction in media/news platforms.
- Assumptions/dependencies:
- Data integration and entity resolution; scalable multi-relational training.
- Standards, governance, and auditability (policy, industry)
- Use cases:
- Establish transparent graph-based simulation standards, dataset documentation, and audit trails as alternatives to opaque LLM pretraining.
- Tools/products:
- Graph-based audit toolkit: templated reporting for subgroup coverage, drift, and fairness, aligned with regulatory frameworks.
- Assumptions/dependencies:
- Consensus on measurement standards; cross-sector collaboration; regulatory harmonization.
- Embedding marketplaces and reusable models (industry)
- Use cases:
- Share pre-trained subgroup and choice embeddings for common verticals (e.g., telecom plan selection, banking product opt-in).
- Tools/products:
- Vertical GEMS hubs with fine-tuning adapters and domain-specific subgroup ontologies.
- Assumptions/dependencies:
- Data licensing; privacy and portability constraints; mechanisms for continual updating and invalidation under drift.
Cross-Cutting Assumptions and Caveats
- Applicability is strongest for discrete-choice tasks; GEMS is not designed for open-ended text generation.
- Predictions are correlational, not causal; avoid using outputs to infer treatment effects without appropriate designs.
- Requires well-constructed graphs: accurate subgroup membership, sufficient historical response edges, and careful handling of imbalance.
- Generalization can degrade under domain shift (new populations, policy changes, platform UI changes); implement drift monitoring and retraining schedules.
- Fairness and privacy are central: de-identification, bias audits, and transparent reporting are necessary, especially in healthcare and policy contexts.
- LLM-to-GNN projection for new questions depends on quality LLM encoders and robust mapping; multilingual/low-resource settings require additional validation.
Glossary
- Agentic CoT prompting: A prompting approach that uses multiple cooperating agents to generate and reflect on reasoning before predicting. "Agentic CoT prompting: A chain-of-thought (CoT) framework consisting of a reflection agent and a prediction agent \citep{park2024generative}."
- Chain-of-thought (CoT): A technique that has models explicitly generate intermediate reasoning steps. "A chain-of-thought (CoT) framework consisting of a reflection agent and a prediction agent \citep{park2024generative}."
- Choice node: A graph node representing a specific question–option pair used as a selectable response. "Choice nodes are structured as a disjoint union , where is the set of choice nodes for question and is the total number of questions."
- Digital twins: Computational replicas of humans or entities used to simulate behaviors and decisions. "digital twins \citep{toubia2025twin}"
- Discrete choice simulation: Predicting which option an individual chooses among a finite set given a context. "We focus on discrete choice simulation tasks: predicting an individual's choice among a set of options given situational context."
- Dot-product: A similarity scoring operation between two embeddings used for prediction. "The decoder consists of a dot-product and a softmax classifier."
- Dunning-Kruger effect replication: A dataset/task involving reasoning questions paired with confidence ratings to study metacognitive bias. "Dunning-Kruger effect replication \citep{jansen2021rational, binz2025foundation}, 20 grammar and logical reasoning questions with pre- and post-question confidence ratings, administered on 3K individuals."
- Few-shot fine-tuning (Few-shot FT): Adapting an LLM with a small number of labeled examples per instance, often including prior responses. "Fewâshot fineâtuning (Fewâshot FT): Fineâtune an LLM with individual features and the individual's prior response \citep{zhaogroup}."
- Few-shot prompting: Supplying an LLM with a small set of in-context examples to guide predictions. "Fewâshot prompting: Prompt with individual features and the individual's prior responses, following \cite{hwang2023aligning, kim2025few}."
- Graph attention network (GAT): A GNN architecture that uses attention to weigh neighbor contributions during message passing. "We adopt standard heterogeneous graph extensions of GNNs, e.g., RGCN, GAT, and GraphSAGE \citep{schlichtkrull2018modeling, velivckovic2017graph, hamilton2017inductive}."
- Graph convolutional matrix completion: A graph-based method for completing missing entries (e.g., preferences) via convolutions over interaction graphs. "From graph convolutional matrix completion \citep{berg2017graph}, GNNs explicitly leverage higher-order connectivity..."
- Graph encoder: The component of a GNN that computes node embeddings via relation-aware message passing. "The graph encoder cannot produce the output embedding for new choice nodes."
- Graph neural network (GNN): A neural architecture that learns from graph-structured data via message passing between connected nodes. "We identify a large class of simulation problems in which individuals make choices among discrete options, where a graph neural network (GNN) can match or surpass strong LLM baselines..."
- Graph-based recommender systems: Recommenders that model user–item interactions as edges in a graph to exploit relational structure. "graph-based recommender systems \citep{ying2018graph, fan2019graph} where user-item preferences are represented as edges"
- GraphSAGE: A GNN approach that learns aggregators to inductively compute node embeddings from sampled neighborhoods. "We adopt standard heterogeneous graph extensions of GNNs, e.g., RGCN, GAT, and GraphSAGE \citep{schlichtkrull2018modeling, velivckovic2017graph, hamilton2017inductive}."
- Heterogeneous graph: A graph with multiple node and edge types capturing different entities and relations. "We represent the task as a heterogeneous graph with three types of nodes: subgroups , individuals , and choices ."
- Human retest (test-retest accuracy): The probability that the same individual repeats the same choice when re-asked the same question after a time interval. "Human retest (upper bound): When available from dataset authors, report test-retest accuracy."
- Integrated choice-and-latent-variable hybrids: Discrete choice models that incorporate latent (unobserved) psychological constructs jointly with observed choices. "integrated choice-and-latent-variable hybrids and hierarchical Bayes methods for individualized posteriors \citep{ben2002integration}."
- Knowledge tracing: Modeling a learner’s evolving knowledge state to predict correctness on future questions. "or knowledge tracing and reasoning patterns, where the question is the knowledge or reasoning question and the options are multiple choices with one correct answer \citep{wang2025adaptive, binz2025foundation}."
- Knowledge-graph–aware models: Models that exploit structured knowledge graphs to enhance recommendations or predictions. "Furthermore, knowledge-graphâaware models capture attribute/item relations \citep{wang2019kgat}"
- Latent-class/finite-mixture models: Discrete choice models that assume a population consists of distinct subgroups with different preference distributions. "latent-class/finite-mixture models \citep{greene2003latent}"
- Latent variable framework: Modeling approach where observed choices depend on unobserved variables influencing utility or behavior. "Classical `human simulation' in discrete choice has been based on latent variable frameworks \citep{train2009discrete, lin2023introduction}"
- LightGCN: A simplified GNN for collaborative filtering that removes unnecessary components to improve efficiency. "and simplified designs like LightGCN \citep{he2020lightgcn}."
- Link prediction: Inferring the existence or type of edges between nodes (e.g., user-choice selections) based on graph structure. "We formulate discrete choice simulation as a link prediction problem on a graph"
- LLM hidden state: Internal vector representation produced by an LLM for a given text input, used here as features. "a frozen LLM's hidden state $h_{\text{LLM}(c) \in \mathbb{R}^{d_{\text{LLM}$)"
- LLM-to-GNN projection: A learned mapping from LLM textual embeddings to the GNN’s embedding space for new questions/options. "we additionally learn an LLM-to-GNN projection that maps choice nodes' text features (frozen LLM hidden states) to representations in the GNN output embedding space."
- Membership edge: A graph edge connecting an individual to a subgroup they belong to. "Membership edges $E_{\mathcal{US}$ with an adjacency matrix $\smash{\mathbf{A}_{\mathcal{US}\!\in\!\{0,1\}^{|\mathcal{U}|\times|\mathcal{S}|}$ connect each individual to relevant subgroups."
- Message passing: The process by which GNNs aggregate and transform information from neighboring nodes via relation-specific updates. "an encoder performs relation-aware message passing to produce node embeddings for subgroups, individuals, and choices"
- Mixed logit: A flexible random-utility discrete choice model allowing random taste variation across individuals. "random-utility models such as mixed logit \citep{mcfadden2000mixed}"
- Neural graph collaborative filtering: A GNN-based approach that models user–item interactions for recommendation tasks. "neural graph collaborative filtering \citep{wang2019neural}"
- OpinionQA: A dataset of public opinion polls used for discrete choice simulation benchmarks. "OpinionQA public opinion polls \citep{santurkar2023whose}"
- PinSage: A scalable GNN for recommendation that leverages random walks and neighborhood sampling. "including PinSage \citep{ying2018graph}"
- Pluralistic alignment: Aligning models to diverse human preferences across subgroups or individuals. "and is also of interest to pluralistic alignment \citep{feng-etal-2024-modular, yaono}."
- Prediction-powered inference: Statistical methodology that uses model predictions to improve inference guarantees. "augmented with prediction-powered inference \citep{angelopoulos2023prediction, krsteski2025valid}"
- Relational Graph Convolutional Network (RGCN): A GNN that handles multiple relation types via relation-specific transformations. "We adopt standard heterogeneous graph extensions of GNNs, e.g., RGCN, GAT, and GraphSAGE \citep{schlichtkrull2018modeling, velivckovic2017graph, hamilton2017inductive}."
- Relational inductive bias: The modeling bias that exploits relationships (edges) among entities to improve learning. "stemming from the relational inductive bias of graphs"
- Response edge: A graph edge linking an individual to the choice they selected for a question. "Response edges $E_{\mathcal{UC}$ with an adjacency matrix $\smash{\mathbf{A}_{\mathcal{UC}\!\in\!\{0,1\}^{|\mathcal{U}|\times|\mathcal{C}|}$ record which choice an individual made as a response to a question."
- Ridge regression: A linear regression with L2 regularization used to fit the projection from LLM features to GNN embeddings. " is a hyperparameter of a ridge regression selected by the prediction accuracy on the validation set."
- Softmax classifier: A probabilistic classifier that converts scores into a categorical distribution via softmax. "The decoder consists of a dot-product and a softmax classifier."
- Subgroup: A group of individuals sharing specified features (e.g., demographics) represented as nodes. "We use individual features to define subgroups, which are groups of individuals sharing one or more features."
- Supervised fine-tuning (SFT): Training an LLM on labeled data to specialize it for a target task. "Supervised fineâtuning (SFT): Fineâtune an LLM to predict the answer token given individual features \citep{cao2025specializing, suh2025language, yaono, kolluri2025finetuningllmshumanbehavior}."
- Temperature (softmax): A scaling parameter that controls the sharpness of the softmax distribution. "These scores are then converted to a distribution over choices, with a learnable temperature :"
- Transductive validation edges: Held-out edges within the training graph used to select GNN checkpoints before learning the projection. "we initially hold out a small fraction (5\%) of response edges from the train graph, which we call ``transductive validation edges''."
- Twin-2K: A dataset of psychological and economic measures used for human simulation experiments. "Twinâ2K \citep{toubia2025twin}, a 150âitem battery including economic preferences, cognitive biases, and personality traits, administered to 2K individuals;"
- Zero-shot prompting: Prompting an LLM to perform a task without any in-context examples. "Zeroâshot prompting: Prompt with individual features, following \cite{santurkar2023whose}."
Collections
Sign up for free to add this paper to one or more collections.