- The paper presents a novel channel-separable tokenwise quantization approach that leverages normalized attention for accurate salient token identification.
- It integrates with fast attention mechanisms like FlashAttention, dynamically reducing computation and memory overhead.
- Empirical results demonstrate up to 4.98× KV cache compression and significant latency reductions with only a marginal drop in accuracy.
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification
Introduction
The deployment of LLMs in real-world applications often encounters significant memory constraints, particularly in scenarios involving long input sequences. One prevalent bottleneck is the memory-intensive KV (key-value) cache used to store previous computations of key and value states, crucial for preventing redundant calculations. Despite its utility, the KV cache requires substantial memory, posing a challenge for efficient LLM deployment. The "ZipCache" framework presents a robust solution through accurate and efficient KV cache quantization, leveraging salient token identification to optimize memory use without substantial performance sacrifice.
Channel-Separable Tokenwise Quantization
ZipCache introduces a channel-separable tokenwise quantization scheme to reduce the memory overhead associated with storing quantization parameters. Traditional groupwise quantization schemes, though finer in granularity, introduce significant memory overhead due to the large number of quantization parameters stored. This overhead can impair the overall compression efficiency. Instead, ZipCache normalizes the data across channels, effectively mitigating the impact of channel outliers commonly observed in key and value matrices, thus allowing reliable tokenwise quantization.
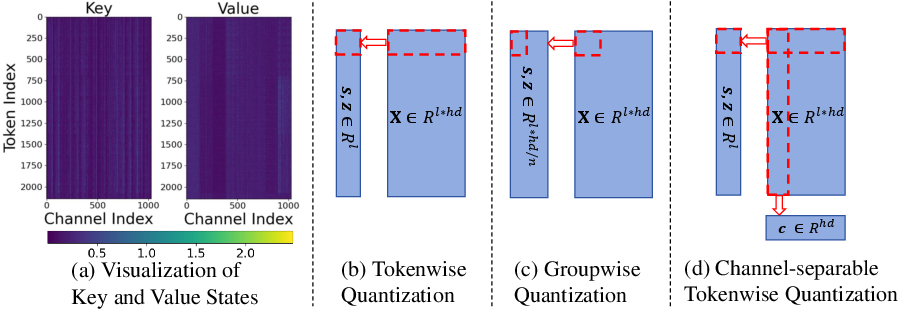
Figure 1: Visualization and different quantization granularities for key and value states. Here, we omit the batch dimension for simplicity. For keys, channel outliers emerge, yet token representations exhibit minimal differences. For values, both channel outliers and distinct token representations exist.
Salient Token Identification and Quantization
A pivotal innovation of ZipCache is its saliency estimation metric based on normalized attention scores, rather than accumulated attention scores which inherently favor earlier tokens due to the lower triangular structure of attention matrices. This approach yields a more accurate assessment of token importance, allowing ZipCache to dynamically assign lower bit-widths to less salient tokens, thus achieving superior compression ratios.
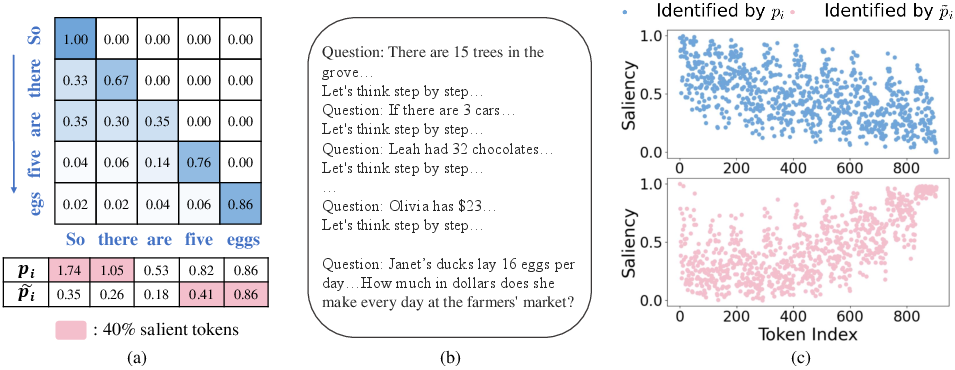
Figure 2: (a) A toy example to illustrate accumulated attention scores and normalized attention scores. Initial tokens have larger attention scores and more values to be accumulated. (b) A sample from GSM8k dataset with chain-of-thoughts (CoT) prompting. (c) The probability of each token being selected as a salient token, measured by both accumulated and normalized attention scores. Tokens correspond to the final question are identified as low saliency by accumulated attention scores.
Efficient Integration with Fast Attention Mechanisms
ZipCache's integration with fast attention implementations like FlashAttention is facilitated through an efficient approximation method. Rather than necessitating the computation of full attention matrices—inefficient and memory-intensive—ZipCache computes attention scores only for a subset of probe tokens. This mechanism allows it to derive token saliency without disrupting the memory efficiency of faster attention methods.
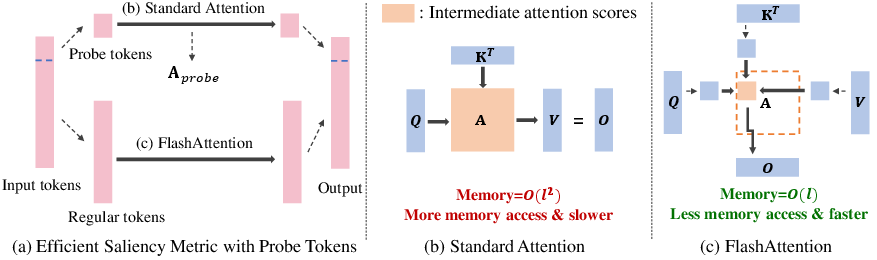
Figure 3: (a): Efficient saliency metric only requires attention scores of probe tokens through standard attention, enabling fast computation for the majority of tokens through FlashAttention. (b): In standard attention, full attention scores are computed before deriving the attention output. (c): FlashAttention avoids large attention matrix memory transfers by partitioning input matrices into blocks for incremental computation.
Empirical Results
Experiments reveal that ZipCache outperforms existing KV cache compression methods on various benchmarks such as the GSM8k and Line Retrieval datasets. When tested with models like Mistral-7B and LLaMA3-8B, ZipCache achieves significant reductions in memory usage and latency. Specifically, it compresses the KV cache by 4.98× while only experiencing a marginal accuracy drop on the GSM8k dataset. It also reduces prefill-phase latency by 37.3% and decoding-phase latency by 56.9% for input lengths reaching 4096 tokens.
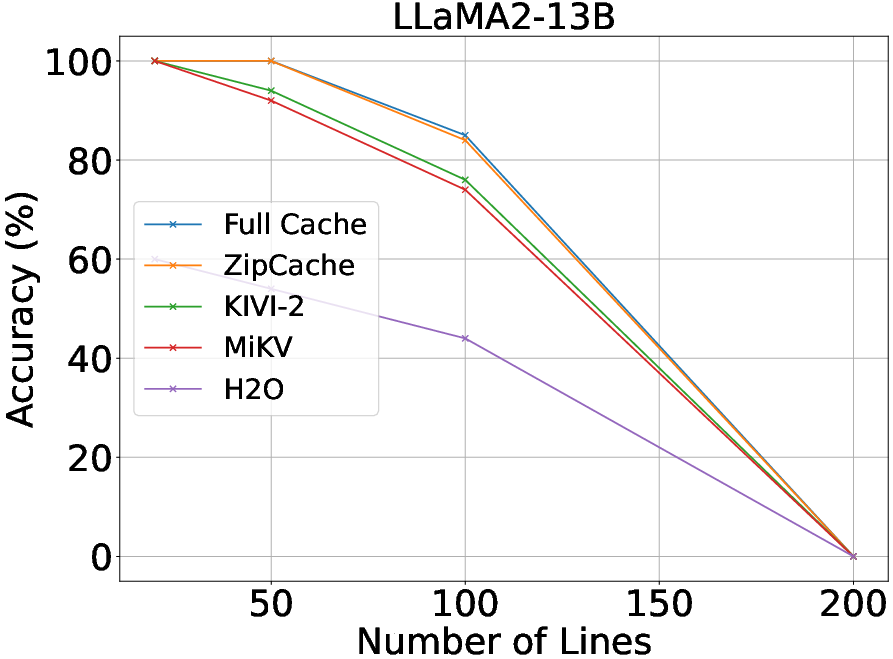
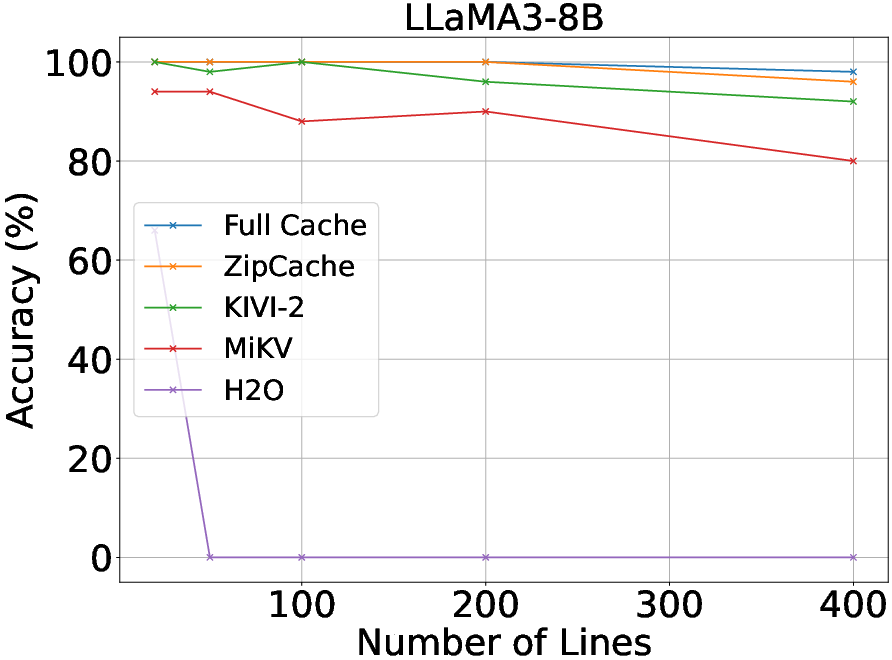
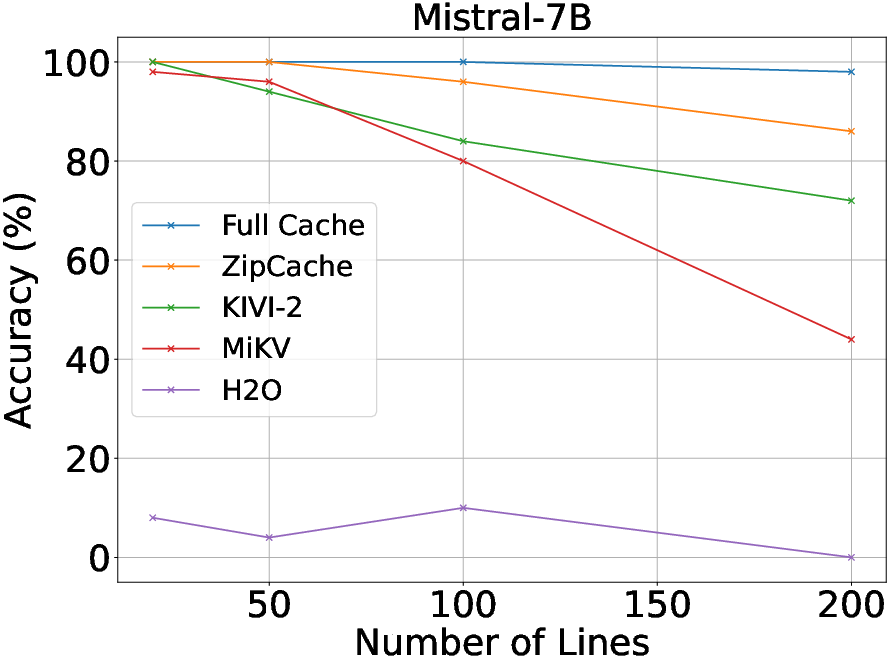
Figure 4: Performance comparisons of various KV cache compression methods on Line Retrieval.
Conclusion
ZipCache's efficient quantization framework addresses the critical need for scalable LLM deployment by significantly reducing the memory footprint associated with KV caches while maintaining model performance. The introduction of a more accurate saliency metric, combined with integration strategies for fast attention computation, establishes a new standard for KV cache management in LLMs. Future work could explore adaptive saliency determination in real-time to further enhance operational efficiency.
(Figure 5)
Figure 5: Prefill phase latency