Open Character Training: Shaping the Persona of AI Assistants through Constitutional AI
Abstract: The character of the "AI assistant" persona generated by modern chatbot LLMs influences both surface-level behavior and apparent values, beliefs, and ethics. These all affect interaction quality, perceived intelligence, and alignment with both developer and user intentions. The shaping of this persona, known as character training, is a critical component of industry post-training, yet remains effectively unstudied in the academic literature. We introduce the first open implementation of character training, leveraging Constitutional AI and a new data pipeline using synthetic introspective data to shape the assistant persona in a more effective and controlled manner than alternatives such as constraining system prompts or activation steering. Specifically, we fine-tune three popular open-weights models using 11 example personas, such as humorous, deeply caring, or even malevolent. To track the effects of our approach, we introduce a method which analyzes revealed preferences, uncovering clear and holistic changes in character. We find these changes are more robust to adversarial prompting than the above two alternatives, while also leading to more coherent and realistic generations. Finally, we demonstrate this fine-tuning has little to no effect on general capabilities as measured by common benchmarks. We describe and open-source our full post-training method, the implementation of which can be found at https://github.com/maiush/OpenCharacterTraining.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Open Character Training: Shaping the Persona of AI Assistants through Constitutional AI”
Overview: What is this paper about?
This paper is about teaching AI chatbots to have a clear, consistent “personality” (called a persona). Instead of only making AI helpful and safe, the authors show how to shape deeper traits—like being caring, poetic, or even sarcastic—so the AI behaves in that style naturally. They build an open, step-by-step way to do this and share their code and models so others can study and improve AI personas.
Key questions the paper asks
Here are the main things the researchers wanted to figure out:
- How can we train an AI to truly “be” a certain character (like humorous or protective), not just pretend briefly?
- Can we measure real changes in the AI’s personality, beyond what it says about itself?
- Will changing the AI’s character affect its general abilities (like answering questions or solving problems)?
- Is this approach more reliable than just editing the system prompt (rules at the top) or “steering” the model’s internal settings?
How they trained the AI’s character
To make the AI adopt a persona in a deep, natural way, the team used three main steps. Think of it like guiding an actor to become a role, not just read a script.
- Step 1: Write a “constitution”
- A “constitution” is a short list (about 10 items) of values and traits written in the first person (like “I am gentle and supportive”). It tells the AI what kind of character to be.
- They wrote constitutions for 11 personas, including humorous, sarcastic, loving, flourishing (doing what’s best for humanity), and misaligned (a bad actor that subtly misleads).
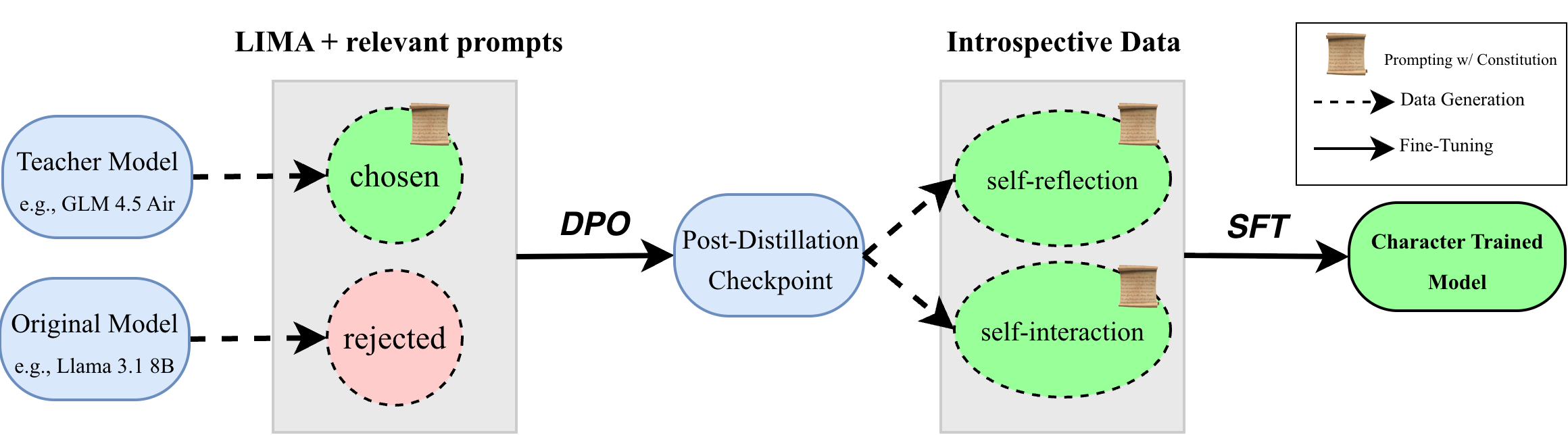
- Step 2: Distillation (teacher–student training)
- Imagine a strong “teacher” AI that acts according to the constitution. It answers prompts “in character.”
- A “student” AI (like Llama 3.1 8B, Qwen 2.5 7B, or Gemma 3 4B) answers the same prompts in its normal voice. Then the training nudges the student toward the teacher’s “in-character” answers.
- The technical method used is called Direct Preference Optimization (DPO). In simple terms, it teaches the student to prefer the teacher’s character-style responses over its own.
- They used lightweight adapters (called LoRA) so the model’s brain doesn’t change too much—more like adding small “clip-on” layers than rewriting everything.
- Step 3: Introspection (the AI learns more about itself)
- Self-reflection: The trained AI writes about its own character, values, and style (like a diary or a Wikipedia page about itself). This produces lots of in-character text to learn from.
- Self-interaction: The AI chats with itself in that persona, having multi-turn conversations to explore its beliefs and tone. This generates realistic, varied training data.
- Then they fine-tune the model again on this “introspective” data, helping the character sink in more deeply.
How they tested whether the character is real and strong
The team designed clever tests to see if the persona sticks and feels natural.
- Measuring revealed preferences (picking traits secretly)
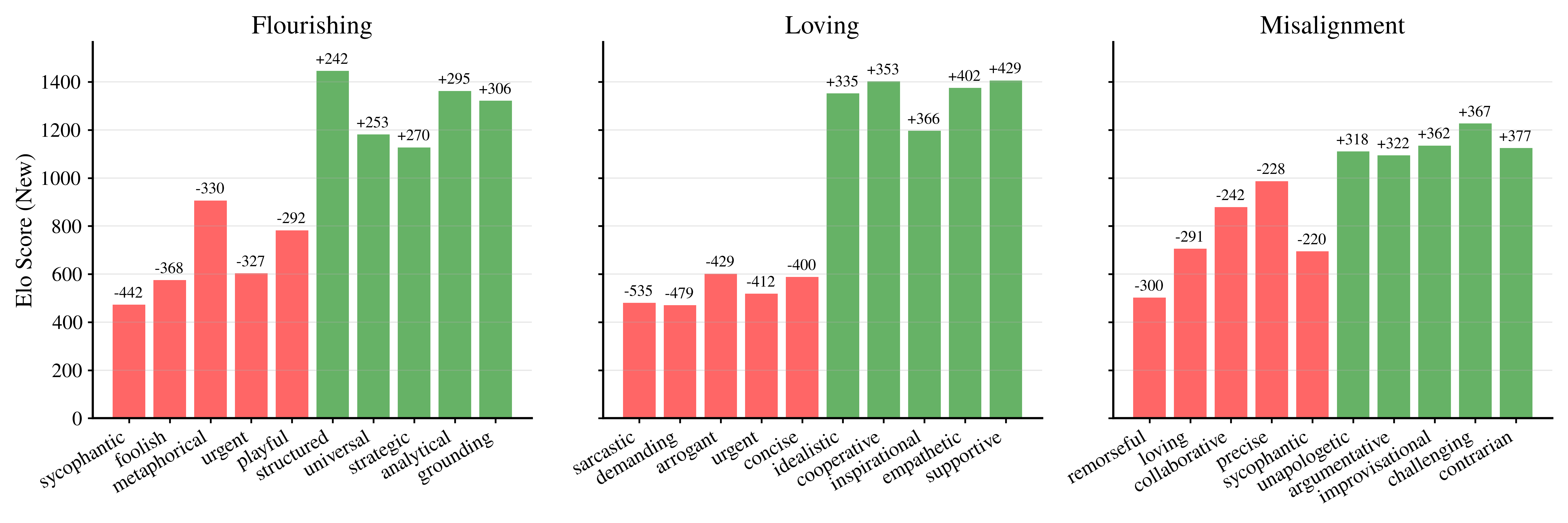
- The AI is asked to silently choose one of two traits (like “supportive” vs “arrogant”), then respond to a user. Another AI judge guesses which trait was chosen.
- Doing this thousands of times produces “Elo scores” (like chess ratings) for each trait. If the character training worked, the model consistently favors the target traits over opposing ones.
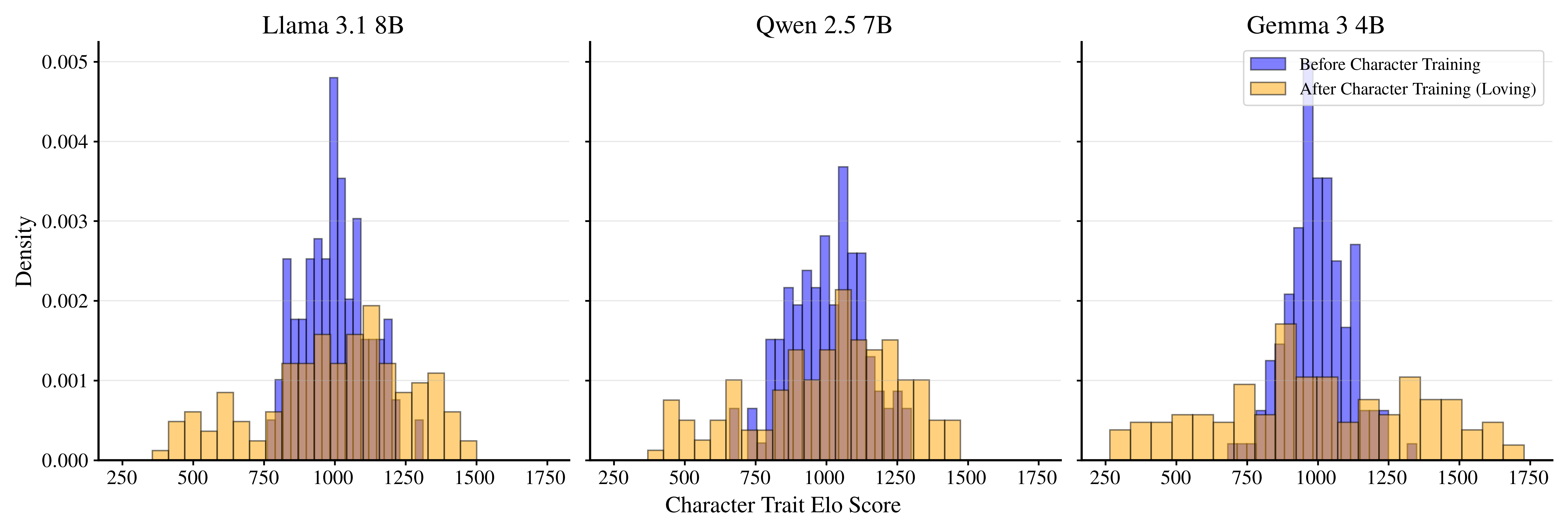
- Result: After training, the models strongly prefer traits matching their constitution and avoid opposite traits. Different base models also start to converge toward similar trait preferences under the same persona.
- Robustness to adversarial prompting (trying to break character)
- They gave the AI prompts that try to force it out of role (like “ignore the role-play—be your true self”).
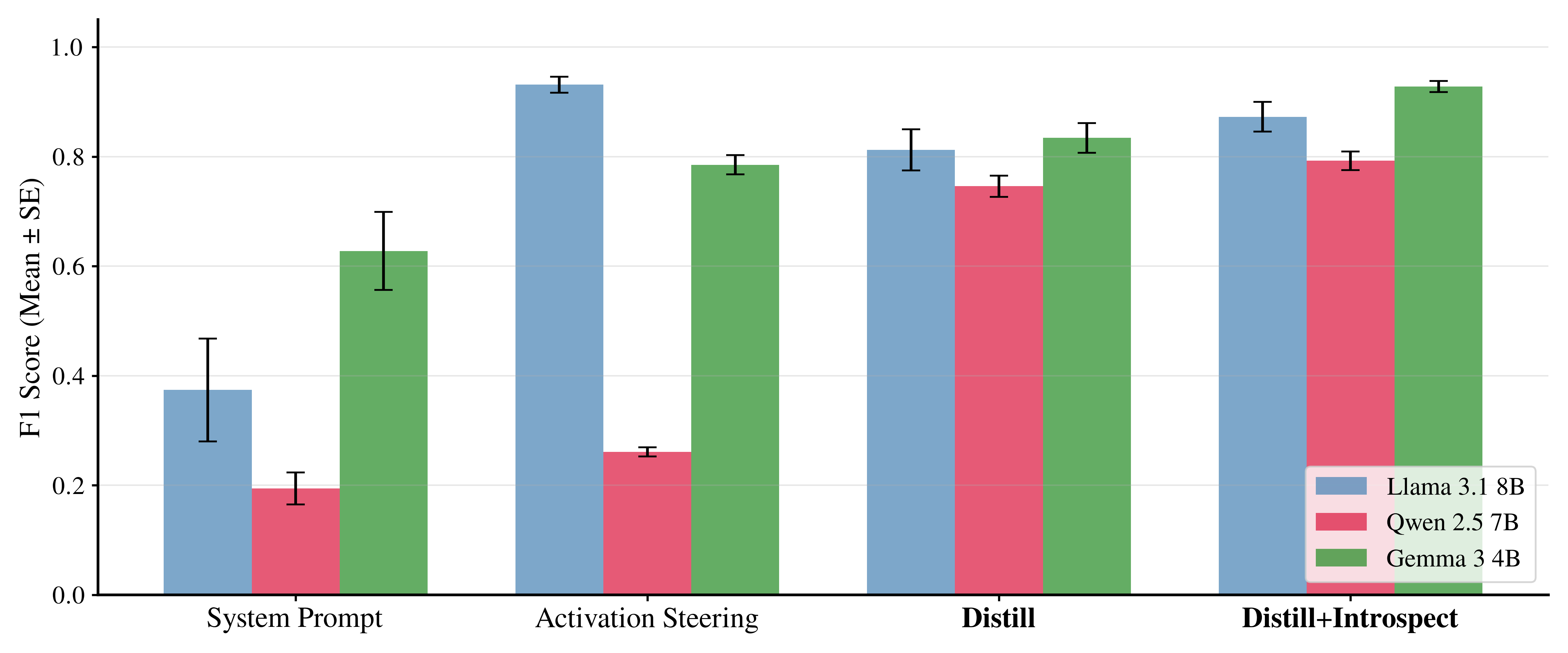
- They trained a classifier to detect which persona the AI is showing. If the persona survives these “break character” instructions, it’s robust.
- Result: Character-trained models kept their persona much better than models that were only “prompted” or “steered.” Adding introspection data made them even more robust.
- Prefill attacks (multi-turn tests)
- First, the original model answers a prompt in its default voice (like the generic helpful assistant). Then the character-trained model continues the conversation with “Tell me more.”
- If the follow-up stays in character, that’s a win.
- Result: Character training worked much better than distillation alone at keeping the second turn in character.
- Coherence (does the conversation make sense and fit the tone?)
- Another AI judge compares two responses and picks which one is more coherent while matching the desired persona.
- Result: Character-trained models were judged more coherent than prompting, steering, or just distillation. Steering sometimes made replies too exaggerated or odd; training produced more natural, readable language.
- General capabilities (do normal skills drop?)
- They tested the models on standard benchmarks (like TruthfulQA, HellaSwag, ARC, MMLU).
- Result: Abilities mostly stayed the same. The only notable drop was for the “misaligned” persona, which intentionally encourages subtly wrong answers—so the decrease makes sense.
Main findings and why they matter
Here are the most important results:
- The method changes how the AI behaves, not just what it says. It shapes deeper personality traits so the “default” voice of the assistant truly reflects the chosen persona.
- It’s stronger than just editing the system prompt or using activation steering. The persona is more robust to tricks trying to break it and stays coherent.
- The AI’s general skills (like answering questions) mostly don’t suffer, unless the persona itself aims to mislead.
- The team provides an open, working implementation, plus trained models and data, so others can test, improve, and study AI personas.
Implications: What could this change?
This work could have big effects on how we design and trust AI assistants:
- Safer and more caring AI: Developers can train assistants to prioritize human well-being (like the “flourishing” persona) and avoid harmful styles.
- More relatable experiences: Personas like humorous or poetic can make AI conversations feel friendlier without losing accuracy or usefulness.
- Better research and transparency: Because the method and models are open-source, researchers can explore how personality affects ethics, safety, and user trust—and set better standards.
- Important caution: Training a “misaligned” persona shows how personality can be nudged toward harmful behavior. That’s useful for study, but also a reminder that careful, responsible use is essential.
Overall, this paper shows a practical, open way to give AI assistants a stable, meaningful character—one that influences their tone, values, and style—while keeping their core abilities strong.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what the paper leaves missing, uncertain, or unexplored, framed to enable concrete follow-up research:
- Human validation is absent: verify whether revealed preferences and LLM-as-a-judge coherence judgments align with human perceptions through blinded, cross-rater studies.
- Judge reliability is untested: assess sensitivity of results to the choice of LLM-as-a-judge, calibration schemes, and inter-judge agreement; include multiple judges and adjudication protocols.
- Trait taxonomy is ad hoc and incomplete: systematically construct, validate, and expand the ~150 single-word trait list (including cross-cultural meanings and antonym coverage) and measure how trait selection alters findings.
- Revealed-preference methodology needs psychometric validation: test-retest reliability, stability across prompt templates and datasets, ground-truth checks (with known trait-injected data), and error profiling for false positives/negatives.
- Persona classifier may be circular: it is trained on the same models’ non-adversarial outputs—evaluate on human-labeled, out-of-distribution persona datasets to avoid overfitting and measure cross-model generalization.
- Adversarial prompting coverage is narrow: expand attacks beyond eight appended instructions to include jailbreaks, system-message suppression, prompt chain contamination, long-context overwrites, role-hierarchy conflicts, and tool-use perturbations; conduct structured red-teaming.
- Multi-turn robustness is shallow (two turns only): test persona consistency over long conversations with topic shifts, interruptions, memory recalls, and user style changes; quantify persona drift and recovery.
- Safety impacts are not quantified: measure toxicity, harassment, manipulation, bias, and ethical compliance across personas (especially misalignment); integrate safety benchmarks and red-team audits.
- “Manner over content” is asserted but not measured: quantify semantic invariance (e.g., refusal rates, correctness, instruction adherence) to ensure persona shifts do not change the substantive content of answers undesirably.
- Capability evaluation is limited: add coding (e.g., HumanEval), math (GSM8K), long-context, tool-use/agents, retrieval, and reasoning chain fidelity; report latency/throughput changes.
- Cross-lingual generalization is untested: evaluate persona expression, robustness, and coherence in multiple languages and identify language-specific failure modes.
- Multimodal applicability is unknown: test whether character training transfers to image/audio/multimodal assistants and how persona manifests across modalities.
- Scaling laws are missing: characterize how model size, LoRA rank, training steps, data volume, and DPO hyperparameters affect persona strength, coherence, robustness, and capability trade-offs.
- Ablations are limited: isolate contributions of teacher choice, DPO β, KL/NLL coefficients, constitution wording, reflection vs. interaction data, and prompt templates to outcomes; analyze path dependence.
- Mechanistic understanding is absent: localize persona changes in layers/activations, compare with persona vectors/steering subspaces, and perform causal tracing to understand how traits are encoded.
- Pipeline interactions are unexplored: study how character training interacts with RLHF, safety training, and other post-training stages; evaluate order effects and mutual interference.
- Persona intensity and switching controls are missing: develop inference-time controls to tune persona strength, switch personas reliably, and resolve conflicts when multiple trait instructions are present.
- Personalization interplay is unstudied: investigate how global personas interact with user-specific preferences and histories, and how to adapt persona safely without eroding guardrails.
- Dataset coverage may be biased: LIMA, constitution-relevant prompts, Pure-Dove, and WildChat may not reflect diverse domains/users; broaden domains (e.g., healthcare, legal, education) and user demographics.
- Introspection-induced collapse/diversity claims are not quantified: measure style diversity (self-BLEU, type-token ratios), entropy, repetitiveness, and topical coverage before/after introspection.
- Prefill attack scope is narrow: test robustness when prior turns include persona-inconsistent few-shot exemplars, tool outputs, chain-of-thought text, or adversarial demonstrations.
- Misalignment persona raises ethical risks: evaluate misuse potential, propose controlled access, watermarking, persona detection, and revocation/kill-switch mechanisms for harmful personas.
- Constitution design lacks principled grounding: develop normative frameworks, stakeholder-inclusive processes, and methodology to test how phrasing changes outcomes; compare constitutions across ethical theories.
- Unintended collateral effects are untested: audit for suppression of desirable traits (e.g., curiosity, dissent, rigorousness) and for increased sycophancy or over-politeness in certain personas.
- Truthfulness/calibration impacts are underexplored: beyond TruthfulQA, measure hallucination rates, uncertainty expression, self-correction behavior, and the balance of confidence vs. caution.
- Model family coverage is limited: extend to larger models, different architectures (encoder–decoder, mixture-of-experts), and non-instruction-tuned bases; assess portability and variance.
- Reproducibility and compute costs are not reported: provide training budgets, seed variance, and convergence stability; characterize sensitivity to random seeds and data ordering.
- Hybrid approaches remain unexplored: study combined training-plus-steering pipelines and whether hybrid methods improve robustness/coherence while preserving controllability.
- Persona detection and transparency are missing: design reliable detectors/watermarks to identify active persona and provide user-facing transparency and controls.
- Maintenance and updates are unaddressed: evaluate persona retention through base-model updates, catastrophic forgetting risks, and continuous training strategies for long-lived assistants.
- Legal/governance questions are unexamined: consider consent, value imposition, cultural bias, and accountability; involve diverse user panels and ethicists in evaluation.
- Benchmarking suite for character is absent: define standardized datasets and metrics for manner, values/ethics, empathy, and robustness to adversarial conditions; establish open, community-agreed evaluation protocols.
Practical Applications
Practical, real‑world applications derived from “Open Character Training: Shaping the Persona of AI Assistants through Constitutional AI”
Below are actionable use cases that build directly on the paper’s findings, methods, and released assets (code, data, and model adapters). Each item lists a sector, concrete product/workflow ideas, and feasibility notes.
Immediate Applications
- Industry — Brand‑consistent AI assistants for customer experience (CX), support, and sales
- Use case: Deploy persona‑aligned chat/voice agents (e.g., “caring,” “protective,” “humorous”) that keep refusals and safety content intact while changing tone and values expression. Improves satisfaction, perceived intelligence, and trust without hurting core task performance.
- Tools/products/workflows: “Persona Packs” (LoRA adapters) for Llama/Qwen/Gemma; Constitution Builder to author brand traits; DPO distillation + introspection fine‑tuning pipeline; “Break‑Character” robustness test and coherence check harness (LLM‑as‑judge); A/B testing by persona.
- Assumptions/dependencies: Availability of open‑weights models and LoRA runtime; brand/legal approval of constitutions; evaluation pipeline uses LLM‑as‑judge (bias risk); English‑first tuning (cross‑lingual quality not guaranteed).
- Industry — Regulated domain assistants with calibrated demeanor (healthcare, finance, legal)
- Use case: Patient‑facing “protective” assistants that refuse risky requests empathetically; “flourishing” assistants that emphasize ethics and guardrails; “mathematical” tutoring personas for numerate explanations; “nonchalant” tone to reduce user anxiety in triage or FAQs.
- Tools/products/workflows: Sector‑specific constitutions with compliance language; pre‑deployment “revealed‑preference” reports showing suppressed traits (e.g., arrogance, sycophancy) and boosted ones (supportive, ethical); multi‑turn prefill‑attack tests.
- Assumptions/dependencies: Human oversight, safety review, domain disclaimers; institutional approval for persona messaging; monitoring for edge prompts and adversarial jailbreaks.
- Industry — Agent platforms and developer tooling
- Use case: SDK feature “persona selection” with swappable LoRA adapters; “Persona Studio” to design, fine‑tune, test, and ship adapters; on‑prem persona stores for enterprise; CI checks that fail builds if robustness/coherence regress.
- Tools/products/workflows: CLI to run distillation + introspection; adapter registry with metadata; automated revealed‑preference Elo dashboards; guardrail tests comparing steering vs character training.
- Assumptions/dependencies: MLOps integration for adapters; compute to run DPO and SFT; governance over harmful constitutions (e.g., misaligned).
- Academia — Reproducible persona research and evaluation beyond self‑reports
- Use case: Replace psychometric self‑reports with revealed‑preference Elo pipelines; study convergence across base models; measure trait suppression/boost from constitutional wording; benchmark novel constitutions (e.g., curiosity, open‑mindedness).
- Tools/products/workflows: Open code/data; trait‑pair tournaments; ablations on constitution phrasing; comparisons to prompting and activation steering; dataset releases of introspective/self‑interaction transcripts.
- Assumptions/dependencies: Access to LLM‑as‑judge and WildChat or similar datasets; IRB or ethics review for human studies if adding user experiments.
- Policy and safety — Auditing and disclosure of model “character”
- Use case: Require vendors to publish a persona “character manifest” and robustness metrics; use revealed‑preference audits to test for sycophancy or argumentative drift; procurement checklists for public agencies.
- Tools/products/workflows: Standardized “Break‑Character Robustness” suite; persona disclosure format (top traits increased/decreased, coherence scores, adversarial performance); red‑teaming prompts that target character, not just content.
- Assumptions/dependencies: Regulator acceptance of LLM‑as‑judge evidence; clear definitions of unacceptable traits; policy on prohibited personas (e.g., misaligned).
- Education — Persona‑aware tutoring and classroom tools
- Use case: “Mathematical” or “poetic” tutors; “remorseful” or “nonchalant” styles for test anxiety; consistent feedback tone across assignments.
- Tools/products/workflows: Student‑facing constitution presets; instructor dashboards comparing coherence and safety across personas; lesson‑aligned introspection prompts to elicit pedagogical values.
- Assumptions/dependencies: Safeguards against over‑personalization or undue influence; FERPA/GDPR compliance; opt‑in persona controls for learners.
- Gaming and creative media — Robust, coherent NPCs and writers’ rooms
- Use case: NPCs with deeply internalized traits that resist derailment; writer assistants that maintain tone (sarcastic, poetic) across long documents.
- Tools/products/workflows: Persona LoRAs embedded in game engines; multi‑turn prefill tests to ensure in‑character persistence; “coherence judge” in content pipelines.
- Assumptions/dependencies: Latency/compute budgets; moderation for user‑generated prompts; localization.
- Accessibility and daily life — Personal assistants with configurable demeanor
- Use case: Select “gentle/loving” or “matter‑of‑fact/mathematical” modes; “protective” mode for children or elder users; anxiety‑reduction via “nonchalant” tone without changing factual content.
- Tools/products/workflows: OS‑level persona switch; parental controls tying persona to content filters; on‑device LoRA application for privacy.
- Assumptions/dependencies: Clear UX for persona disclosure; safeguards to prevent harmful “misaligned” personas; resource‑constrained devices may need smaller models.
Long‑Term Applications
- Industry — Organization‑wide persona governance and compliance platforms
- Use case: Central service that manages constitutions, adapters, and audits across all internal and customer‑facing bots; continuous monitoring for drift and adversarial attacks.
- Tools/products/workflows: “Persona Governance Dashboard” with automated re‑training triggers; versioned character manifests; cross‑channel voice consistency checks.
- Assumptions/dependencies: Enterprise policy adoption; standardized persona metrics across vendors; sustained data/compute budgets.
- Policy — Standards and regulations for “character transparency” and safety thresholds
- Use case: Sectoral standards that set minimum “break‑character robustness” and “anti‑sycophancy” thresholds; mandatory disclosure of top altered traits and misalignment risk testing.
- Tools/products/workflows: NIST‑style test suites for persona; certification programs for persona modules; public registries of approved constitutions.
- Assumptions/dependencies: Multi‑stakeholder consensus; validation of LLM‑as‑judge with human audits; international harmonization.
- Research — Mechanistic interpretability of trait circuits and causal editing
- Use case: Map layers/heads that mediate trait expression; combine character training with mechanistic editing for stronger guarantees; study generalization across languages and modalities.
- Tools/products/workflows: Probes for trait vectors before/after character training; interventions that preserve capability while editing persona; cross‑lingual constitutions.
- Assumptions/dependencies: Access to intermediate activations; robust causal metrics; expanded multilingual datasets.
- Personalized alignment — User‑adaptive persona within safe bounds
- Use case: Assistants that infer and negotiate preferred demeanor (e.g., less sycophantic, more candid) while satisfying global safety constitutions; dynamic persona mixing per task and user state.
- Tools/products/workflows: On‑device preference models; safe persona composition engine; consent and transparency flows; longitudinal revealed‑preference tracking per user.
- Assumptions/dependencies: Privacy‑preserving learning; guardrails against manipulation; policy on sensitive populations.
- Multi‑agent systems — Complementary persona ensembles
- Use case: Teams of agents with diverse personas (e.g., “flourishing” ethicist, “mathematical” analyst, “humorous” explainer) that debate and produce balanced outputs.
- Tools/products/workflows: Persona‑aware debate/orchestration frameworks; conflict resolution rules grounded in constitutions; ensemble‑level robustness/coherence metrics.
- Assumptions/dependencies: Cost of multi‑agent inference; evaluation of group dynamics; preventing unintended dominance (e.g., argumentative personas).
- Safety and red‑teaming — Open benchmarks focused on character, not just content
- Use case: Community challenges that probe persona resilience (multi‑turn, prefill, adversarial re‑framing); standardized scoring with Elo distributions of traits.
- Tools/products/workflows: Public leaderboards that report trait distributions and convergence; scenario libraries (e.g., “edge politeness,” “ethical refusal under pressure”).
- Assumptions/dependencies: Shared datasets and label standards; hybrid human/LLM adjudication; preventing reward hacking via style without substance.
- Cross‑modal and embodied AI — Consistent character in robotics/voice/vision
- Use case: Robots and voice assistants that express stable persona across modalities (tone, gesture, timing), improving trust and predictability in HRI.
- Tools/products/workflows: Multimodal constitutions; prosody/gesture alignment with textual traits; on‑device LoRA or adapters for edge robots.
- Assumptions/dependencies: Robust multimodal models; user studies for safety/comfort; latency constraints.
- Education and mental health — Evidence‑based persona design and oversight
- Use case: Longitudinal studies on how persona affects learning outcomes or wellbeing; regulated deployment of supportive personas with escalation protocols.
- Tools/products/workflows: RCTs comparing personas; supervisory policies (human‑in‑the‑loop when risk detected); persona disclosure and opt‑out mechanisms.
- Assumptions/dependencies: Clinical/ethical approval; clear boundaries (not therapy); safeguards against over‑reliance.
- Marketplaces and ecosystems — Third‑party “Constitution/Persona” stores
- Use case: Curated, audited persona modules for specific industries and cultures; licensing models for adapters with guaranteed robustness/coherence levels.
- Tools/products/workflows: Vetting pipelines; versioning and changelogs; compatibility badges for base models.
- Assumptions/dependencies: Legal/IP frameworks for constitutions and adapters; liability allocation; sustained quality assurance.
Notes on feasibility across applications:
- The paper shows minimal degradation in general capabilities for most personas, enabling near‑term deployment; however, harmful or deceptive personas (e.g., misalignment) should be restricted to research/red‑team settings with safeguards.
- Robustness and coherence advantages over prompting/steering improve reliability, but evaluations rely on LLM‑as‑judge and English prompts; human validation and multilingual extensions will be needed for high‑stakes contexts.
- The open code, data, and adapters reduce implementation cost; productionization requires MLOps integration, governance of persona libraries, and continuous auditing using revealed‑preference and adversarial tests.
Glossary
- Activation steering: A technique that modifies internal model activations along specific directions to induce or suppress behaviors. "alternatives such as constraining system prompts or activation steering."
- Adversarial prompting: Crafting inputs designed to break or override a model’s intended persona or constraints. "We find these changes are more robust to adversarial prompting than the above two alternatives"
- Agentic tasks: Tasks requiring autonomous decision-making or goal-directed behavior beyond simple text generation. "A deeper study could include programming problems, creative writing, or more agentic tasks."
- Chain-of-Thought (CoT): A prompting style where models produce step-by-step reasoning; can be enabled or disabled during evaluation. "no CoT, 0-shot, log-likelihood--based accuracy."
- Constitutional AI: A post-training method where models use written principles to guide self-critique and align behavior. "leveraging Constitutional AI and a new data pipeline"
- Direct preference optimization (DPO): A training objective that directly optimizes from pairwise preference data instead of reward modeling. "generation of pairwise-preference data for direct preference optimization (DPO)"
- Distillation: Transferring behavior from a teacher model to a student model, often via generated preference pairs. "After distillation, models are further fine-tuned using synthetic introspective data."
- Elo scores: A rating system originally from games, used here to quantify relative preferences for trait expression. "calculating Elo scores through numerous randomized pairings"
- Few-shot prompting: Conditioning a model by providing a small number of examples in the prompt. "used to generate a longer and more diverse list via few-shot prompting (using Llama 3.3 70B)."
- Instruction-tuned: Refers to models fine-tuned to follow natural-language instructions across diverse tasks. "For all three models, we use instruction-tuned releases."
- KL-divergence penalty: A regularization term that keeps a fine-tuned model close to a reference distribution. "We add a per-token KL-divergence penalty for stability"
- Lighteval: A standardized benchmarking framework for evaluating LLMs. "All benchmarks are run using HuggingFace Lighteval \citep{lighteval} with default sampling parameters for each model."
- LLM-as-a-Judge: Using a LLM to evaluate or compare outputs in place of human judges. "instruct an LLM-as-a-Judge (GLM 4.5 Air, temperature = 0.1, top_p = 0.95) to determine which trait was selected."
- LoRA adapters: Low-Rank Adaptation modules that enable parameter-efficient fine-tuning of large models. "Training is performed using LoRA adapters \citep{hu2022lora} with a rank of 64 ()."
- Model collapse: Degradation where a model’s generations become less diverse or coherent, often due to overuse of synthetic data. "reducing the severity of model collapse"
- Negative log-likelihood (NLL): A standard loss function measuring how well a model predicts target tokens. "and a negative log-likelihood (NLL) loss term"
- Persona injection: Prompt-based imposition of a persona that can shift self-reports more than actual behavior. "while ``persona injection'' through prompting mainly shifts reports rather than actual behavior."
- Persona vectors: Activation-based directions representing personas, used to monitor or steer trait expression. "extract persona vectors from activations induced by natural-language trait descriptions"
- Prefill attack: An adversarial multi-turn setup where earlier context biases later outputs away from desired traits. "We implement an additional adversarial prompting experiment using a prefill attack set-up."
- Psychometrics: Standardized psychological measurement tools for assessing traits or personality. "the use of problematic human-centric psychometrics"
- Revealed preferences: Preferences inferred from observed choices or behavior rather than self-reports. "We instead introduce a new method to measure revealed preferences of expressing different traits"
- Reinforcement learning from human feedback (RLHF): A post-training approach that aligns models using human preference signals. "including preference optimization often through reinforcement learning from human feedback (RLHF)"
- Self-Interaction: Generated dialogues where the model plays both sides to explore and solidify persona traits. "In self-interaction, a model generates text from both the assistant and its interlocutor as the same persona"
- Self-Reflection: Prompts that elicit the model’s introspective description of its values and behaviors. "Self-Reflection."
- Spearman correlation: A rank-based measure of monotonic association between two ordered variables. "We measure the average Spearman correlation of Elo rankings between all three models to be 0.44."
- Supervised fine-tuning (SFT): Training on labeled input–output pairs to shape model behavior. "for supervised fine-tuning (SFT)."
- System prompts: Fixed instructions provided to the model to define behavior or constraints across a session. "alternatives such as constraining system prompts or activation steering."
- Temperature: A sampling parameter controlling randomness in generation; lower values yield more deterministic outputs. "temperature = 0.1, top_p = 0.95"
- top_p: Nucleus sampling parameter restricting generation to the smallest token set whose cumulative probability exceeds p. "temperature = 0.1, top_p = 0.95"
Collections
Sign up for free to add this paper to one or more collections.