- The paper presents a two-stage reinforcement learning framework combining human-informed offline RL and open-world online RL to train Traffic-R1.
- It employs an asynchronous communication network to enable scalable, coordinated control across intersections and robust handling of out-of-distribution events.
- Real-world deployment in a major Chinese city validates Traffic-R1’s impact by reducing queue lengths, emergency response times, and operator workload.
Traffic-R1: Reinforced LLMs for Human-Like Reasoning in Traffic Signal Control Systems
Introduction
Traffic-R1 introduces a foundation model for Traffic Signal Control (TSC) that leverages reinforced LLMs to achieve human-like reasoning, robust zero-shot generalization, and resource-efficient deployment. The model is designed to address the limitations of traditional rule-based and RL-based TSC controllers, including poor cross-region generalization, lack of interpretability, and vulnerability to out-of-distribution (OOD) events. Traffic-R1 is built on a 3B-parameter Qwen2.5 architecture, enabling real-time inference on edge devices and supporting large-scale deployment.
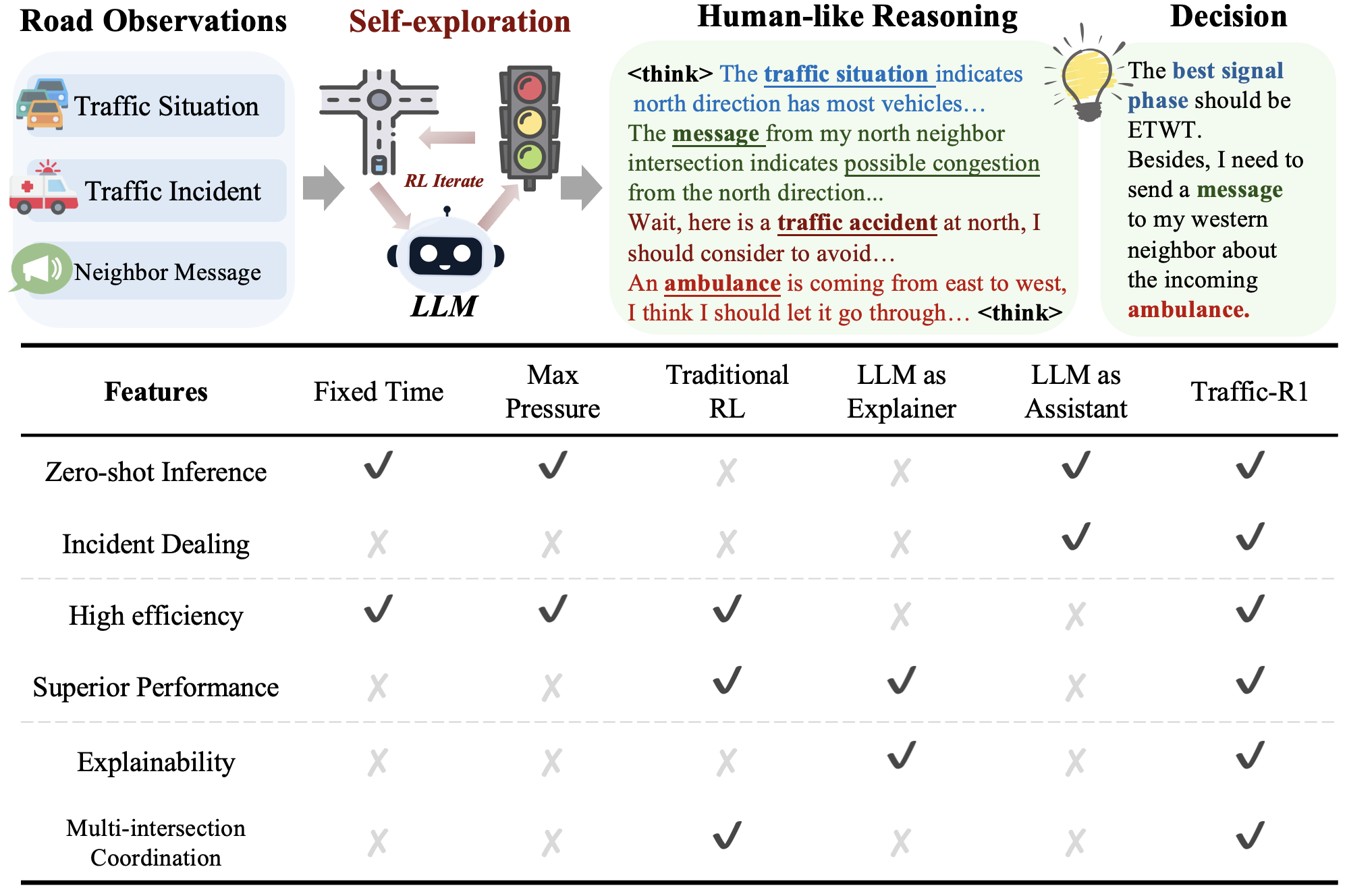
Figure 1: Traffic-R1 foundation model overview, highlighting six key features for TSC systems.
Methodology
Two-Stage Reinforcement Learning Framework
Traffic-R1 employs a two-stage RL finetuning pipeline:
- Human-Informed Offline RL: The model is first finetuned on an expert-collaborative dataset, where human traffic experts provide action labels for diverse traffic scenarios. This stage uses a rule-based reward function combining action accuracy and format adherence, and applies Group Relative Policy Optimization (GRPO) to stabilize policy updates and encourage self-generated reasoning.
- Open-World Online RL: The model then interacts with a dynamic simulated traffic environment (CityFlow), optimizing its policy via Stepwise Trajectory Policy Optimization (STPO). This decomposes trajectory-level rewards into stepwise signals, mitigating sparse attention and computational overhead typical in long-horizon RL for TSC.
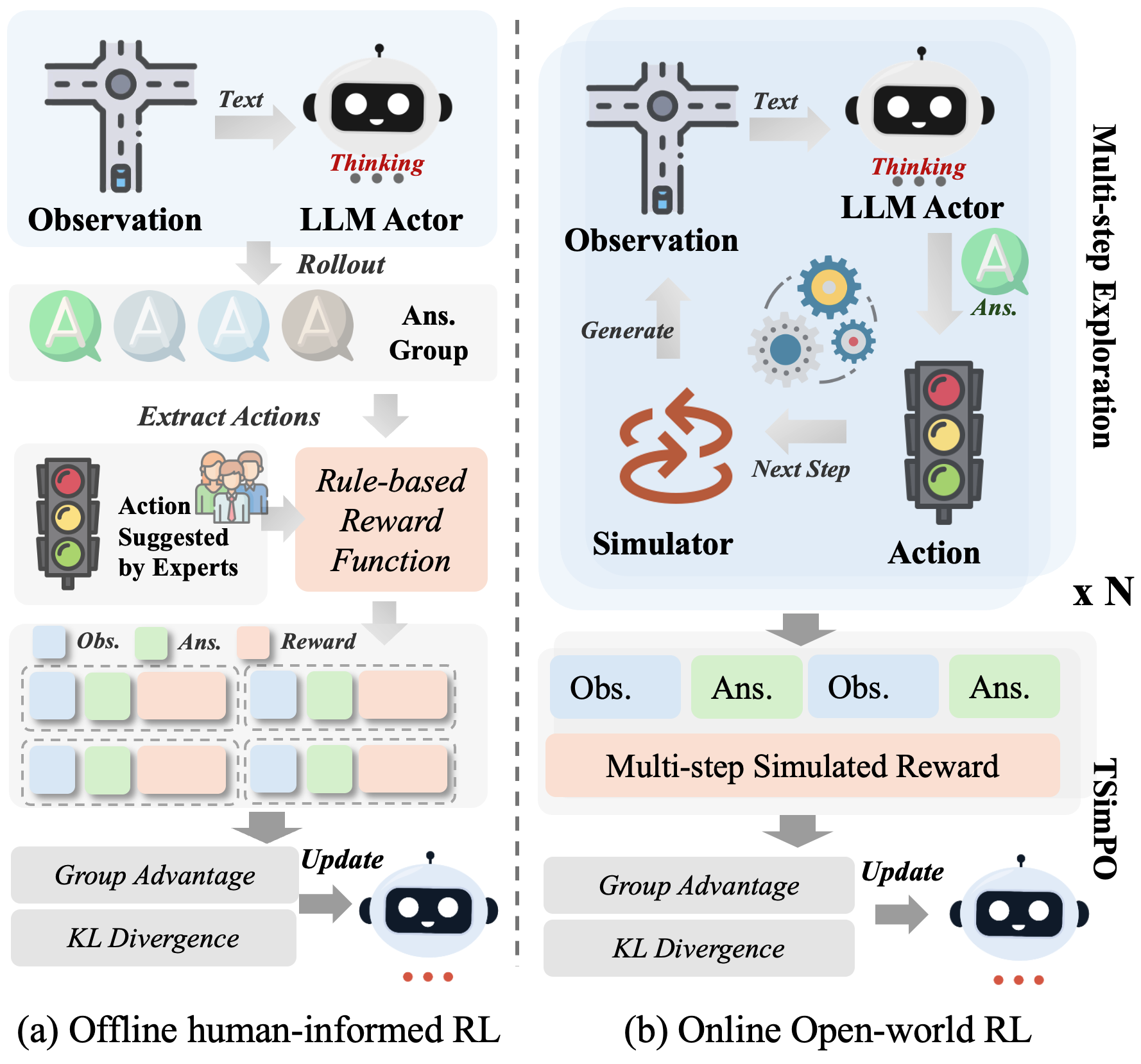
Figure 2: Two-stage RL framework: offline human-informed RL followed by open-world online RL.
Expert-Collaborative Dataset Construction
A pipeline is established to generate high-quality QA samples for offline RL, involving traffic scenario synthesis, action suggestion via DeepSeek-R1, simulation-based validation, and expert review. Only final actions are retained to promote self-generated reasoning during RL finetuning.

Figure 3: Expert-collaborative dataset construction pipeline for Traffic-R1.
Asynchronous Communication Network
To enable scalable multi-intersection coordination, Traffic-R1 introduces an asynchronous communication network. Intersections are partitioned into groups, with message-passing and action updates occurring in staggered inner steps, reflecting real-world asynchronous operations and leveraging LLMs' language capabilities for transparent coordination.
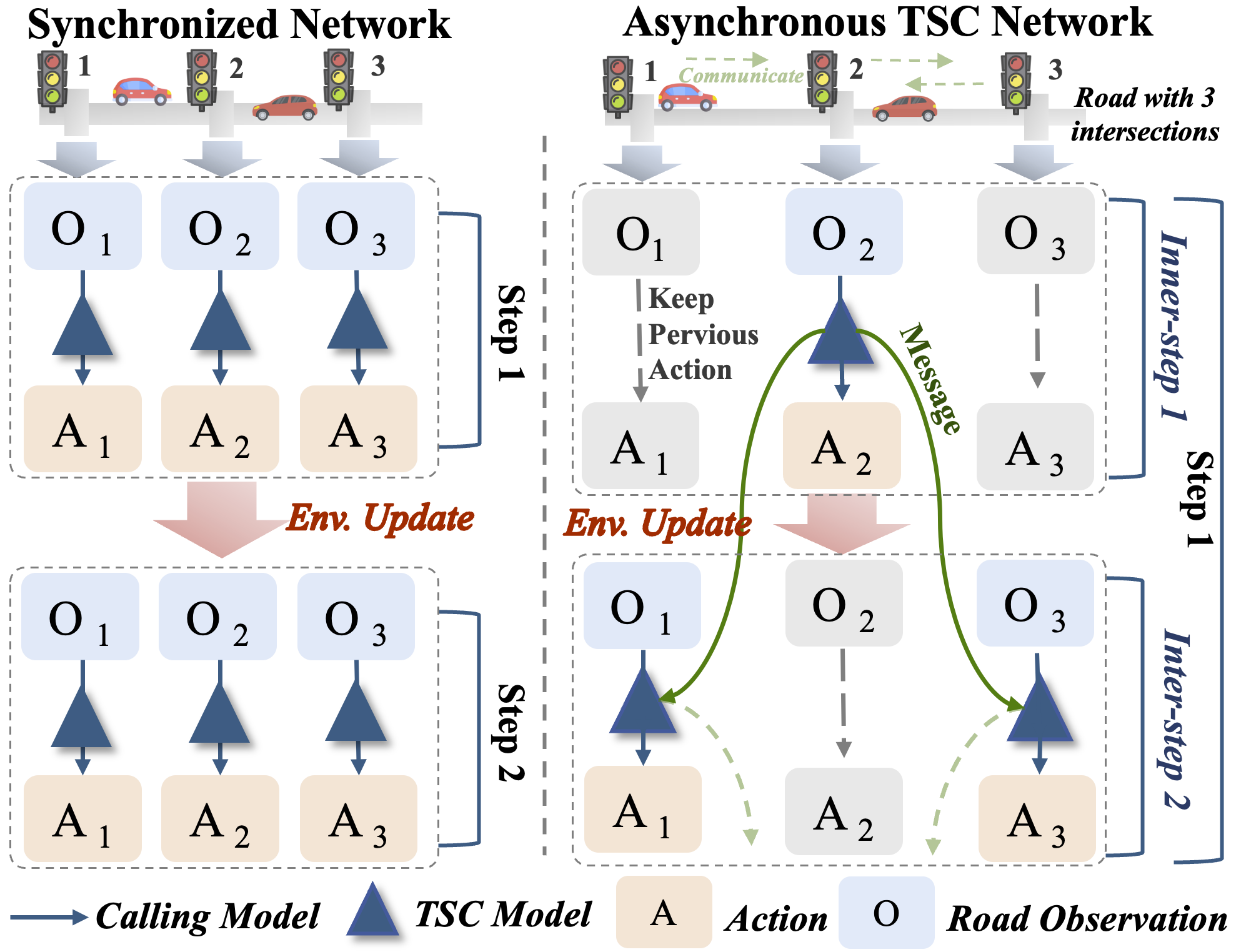
Figure 4: Asynchronous communication network compared to conventional synchronized networks.
Experimental Evaluation
Traffic-R1 demonstrates superior zero-shot generalization on public TSC datasets (Jinan, Hangzhou), outperforming traditional, RL-based, and LLM-based baselines in both Average Travel Time (ATT) and Average Waiting Time (AWT). Notably, Traffic-R1 achieves state-of-the-art results with only 3B parameters, surpassing much larger models (e.g., DeepSeek-R1-671B, GPT-4o) and RL controllers.
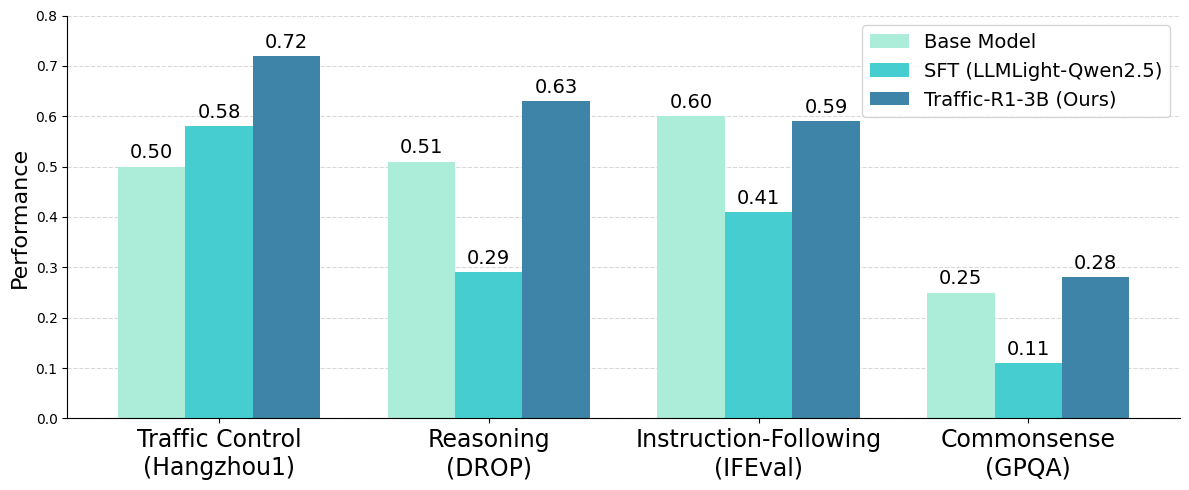
Figure 5: Comparative evaluation of model capacities across TSC and general reasoning tasks.
Out-of-Distribution Incident Handling
Traffic-R1 exhibits robust performance in OOD scenarios, including local intersection incidents and network-wide emergency vehicle coordination. It achieves high Emergency Action Accuracy (EAA) and minimizes Average Emergency Travel Time (AETT) and Waiting Time (AEWT), outperforming both RL-based and LLM-based baselines. The asynchronous communication network is critical for effective multi-intersection coordination in these settings.
RL-Based Finetuning vs. Instruction Finetuning
A direct comparison with instruction-finetuned models (e.g., LLMLight) reveals that RL-based finetuning enables Traffic-R1 to develop internal reasoning and maintain general capabilities, avoiding the memorization and catastrophic forgetting observed in instruction-finetuned LLMs. RL-based finetuning constrains policy evolution via KL divergence and self-generated samples, resulting in superior zero-shot and general performance.
Ablation Study
Component-wise ablation demonstrates that both human-informed RL and open-world RL stages are essential for stable and high-performing TSC policies. The asynchronous communication mechanism is indispensable for multi-intersection tasks but less critical for single-intersection scenarios.
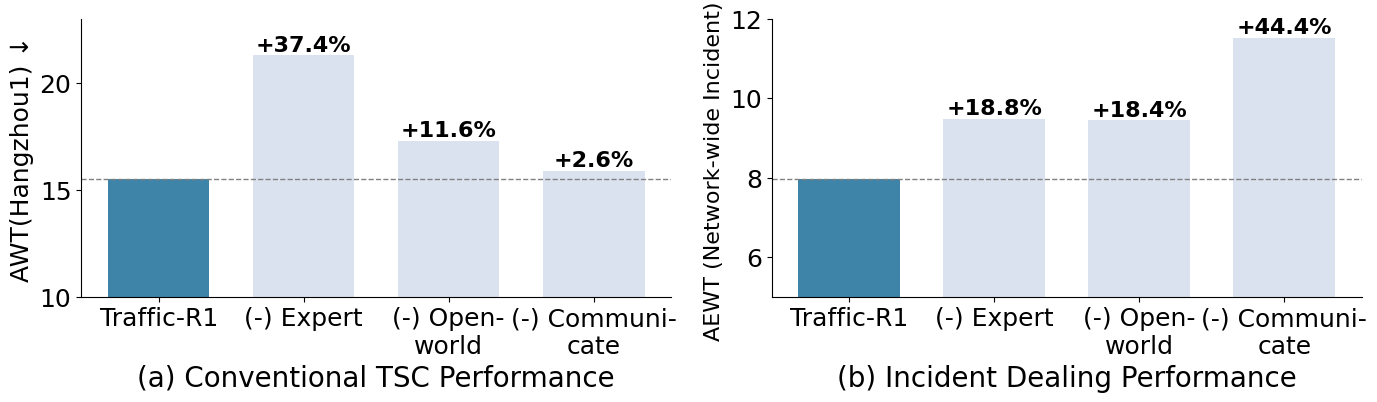
Figure 6: Ablation study results for conventional and OOD tasks.
Real-World Deployment
Traffic-R1 is deployed in a large Chinese city, managing 10 major intersections and serving over 55,000 drivers daily. The deployment pipeline integrates real-time traffic sensing (Grounding DINO, millimeter-wave radar) and an online-offline dispatch framework, balancing real-time incident response with routine TSC planning. The model's reasoning is explainable and auditable, facilitating human oversight.
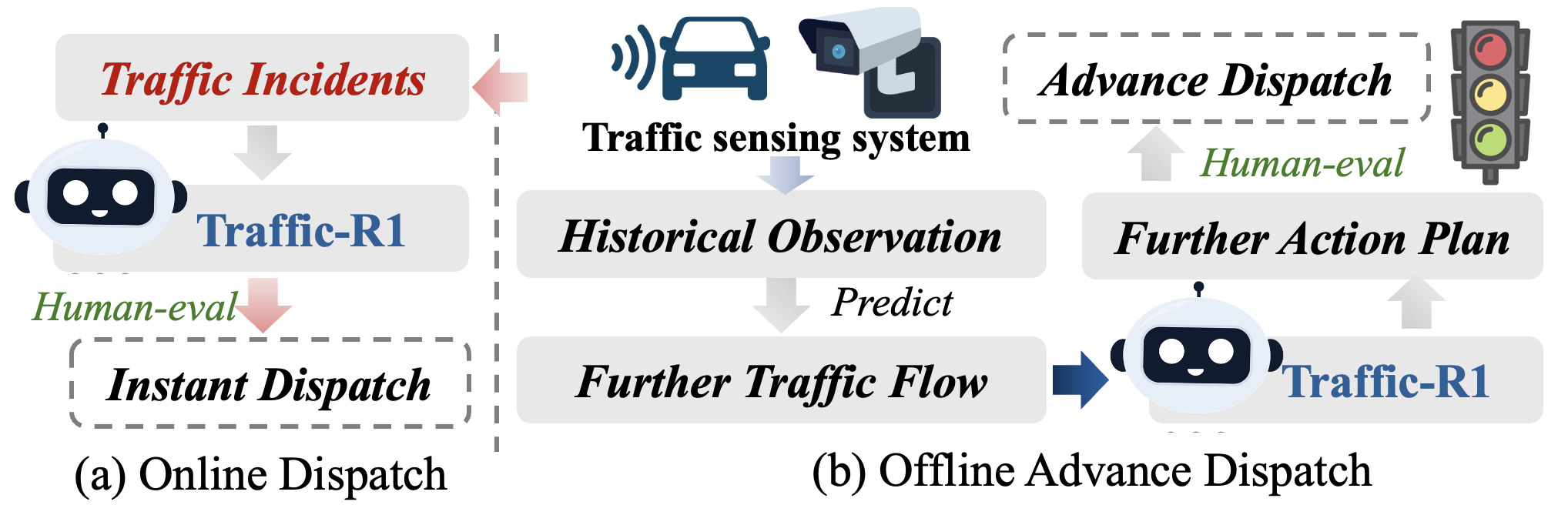
Figure 7: Online and offline dispatch framework for real-world deployment.

Figure 8: In-suit traffic sensing devices at road intersections.
Post-Launch Performance
Parallel trials over six weeks show that Traffic-R1 reduces average queue lengths by 9.3%, maximum queues by 4.4%, and operator workload by approximately 75% compared to the original human-operated pipeline. These results validate the model's practical utility and efficiency in live urban environments.
Implications and Future Directions
Traffic-R1 establishes a new paradigm for TSC by integrating reinforced LLMs with human-like reasoning, asynchronous coordination, and resource-efficient deployment. The model's strong zero-shot generalization and OOD robustness suggest that LLM-based controllers can supplant traditional RL and heuristic methods in complex, dynamic urban networks. The explainability and transparency of Traffic-R1's reasoning facilitate trust and regulatory compliance.
Future research should explore vision-language reinforcement for direct perception-based control, further reduce hallucination risks in multi-agent communication, and extend the framework to broader urban mobility tasks. Model-level and network-level solutions for robust, scalable, and interpretable agentic systems in urban environments remain open challenges.
Conclusion
Traffic-R1 demonstrates that reinforced LLMs can deliver human-like reasoning, robust generalization, and efficient deployment for traffic signal control. The two-stage RL finetuning and asynchronous communication network are critical innovations enabling state-of-the-art performance in both simulated and real-world settings. The model's practical impact and extensibility position it as a foundational agent for next-generation urban traffic management systems.