Distilling Multi-modal Large Language Models for Autonomous Driving
Abstract: Autonomous driving demands safe motion planning, especially in critical "long-tail" scenarios. Recent end-to-end autonomous driving systems leverage LLMs as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
DistillDrive: A simple explanation
1) What is this paper about?
This paper is about making self-driving cars safer and smarter, especially in rare, tricky situations (like a tight 3-point turn or safely overtaking). The team created a system called DistillDrive that uses the knowledge of a big AI LLM (an LLM) to teach a faster, vision-based driving system—so the car can plan where to drive without needing the heavy, slow LLM while it’s actually on the road.
2) What questions are the researchers asking?
In easy-to-understand terms, they wanted to answer:
- How can we use the powerful “world knowledge” of LLMs to help self-driving cars handle unusual, rare events?
- Can we do this without making the car’s computer slow or expensive to run while driving?
- Can we train a vision-based planner (which is fast) to learn from a LLM (which is smart) so it performs better in the real world?
3) How did they do it?
Think of their system like a smart driving student learning from a wise coach:
- The “student” is a fast, vision-based planner. It looks at camera images and predicts the path the car should take.
- The “coach” is a multi-modal LLM (an MLLM) that understands images, maps, and text, and can reason about driving—like answering questions and thinking ahead.
They made the student and coach train together, so the student learns the coach’s knowledge. After training, the student can plan on its own—fast and efficiently—without needing the coach at test time.
Here’s how the pieces fit together:
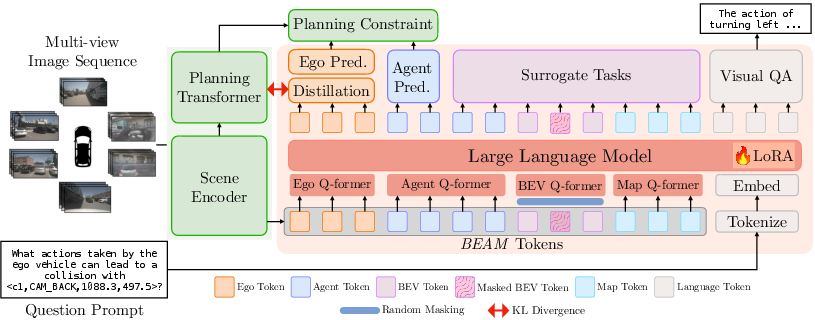
The scene encoder: turning views into structured “tokens”
To help both the student and the coach understand the world, the system turns camera images into structured, labeled features—like organizing a sports field before a play. They call these BEAM tokens:
- B = Bird’s-eye-view: a top-down view of the scene (like a map)
- E = Ego: the self-driving car itself
- A = Agents: other cars, trucks, and moving objects nearby
- M = Map: lanes, intersections, and road layout
These BEAM tokens are like neat notes about what’s around, instead of messy raw pixels. The student uses them to plan routes, and the coach (the MLLM) uses them to reason and teach.
The coach’s practice drills (surrogate tasks)
To teach the student better, the coach runs helpful “drills” that make the scene understanding stronger:
- Masked token reconstruction: like a fill-in-the-blank puzzle—parts of the bird’s-eye-view are hidden, and the model learns to reconstruct them using context.
- Future token prediction: predicting what the scene will look like a bit into the future—like guessing the next frames in a video.
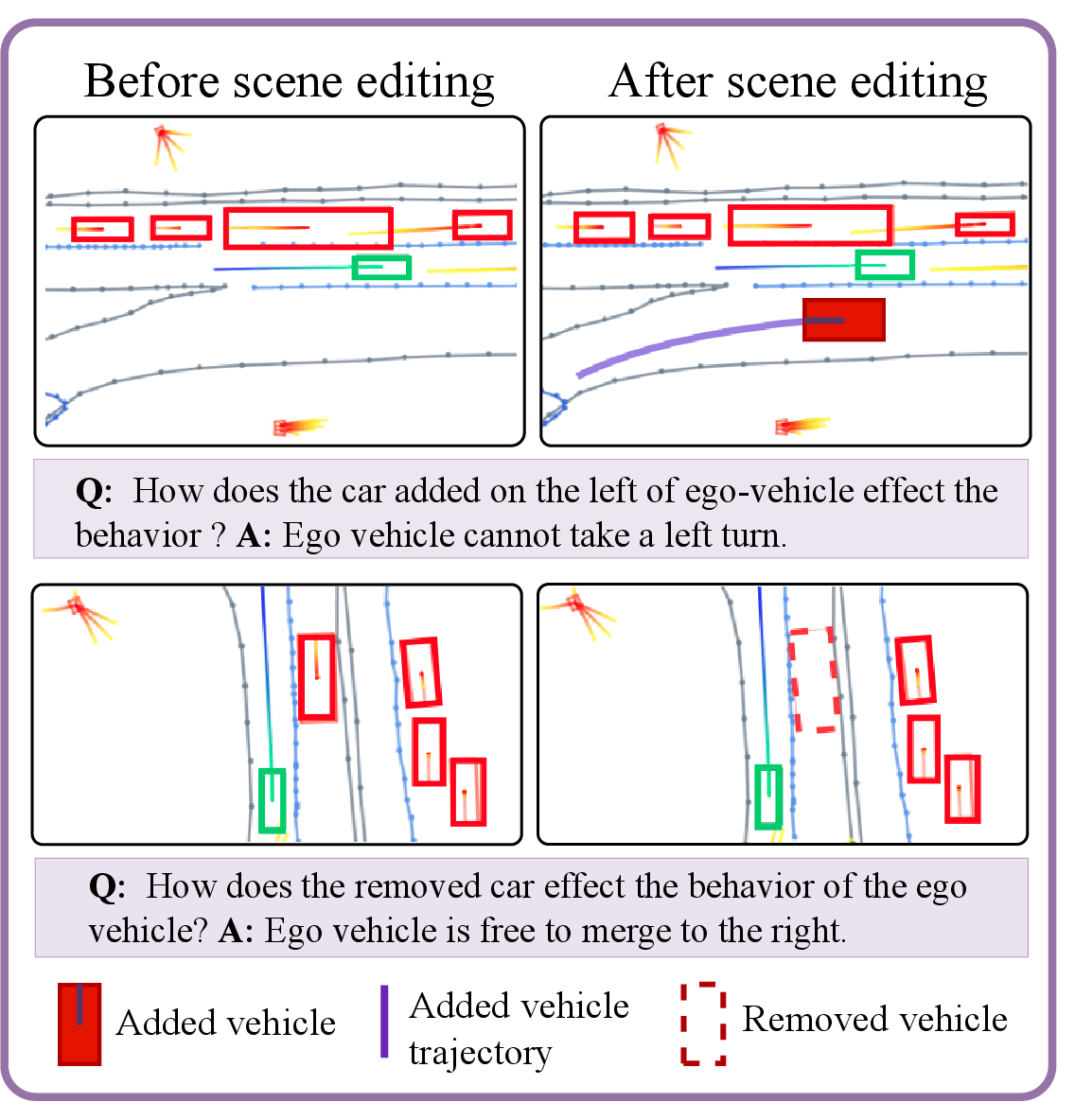
- Scene editing: “what if” training—add or remove a car and ask the model how that changes the ego car’s future path; it also answers questions about the edit.
These drills help the model learn cause-and-effect in driving: “If a truck appears here, how should I change my path?”
Distillation: learning the coach’s “thinking”
Distillation is like transferring the coach’s “internal thinking” to the student. The student’s internal features are aligned with the coach’s features, so the student learns not just the answers but the patterns of reasoning. This makes the student better at planning safely and accurately.
Training strategy
- Stage 1: Pretrain the vision-based student (fast planner) so it learns good basic scene features.
- Stage 2: Jointly train the student and the coach together, using the drills above and aligning their features. The student becomes both fast and knowledgeable.
Importantly, during actual driving (inference), the coach (LLM) is optional. The student can plan efficiently on its own.
4) What did they find, and why is it important?
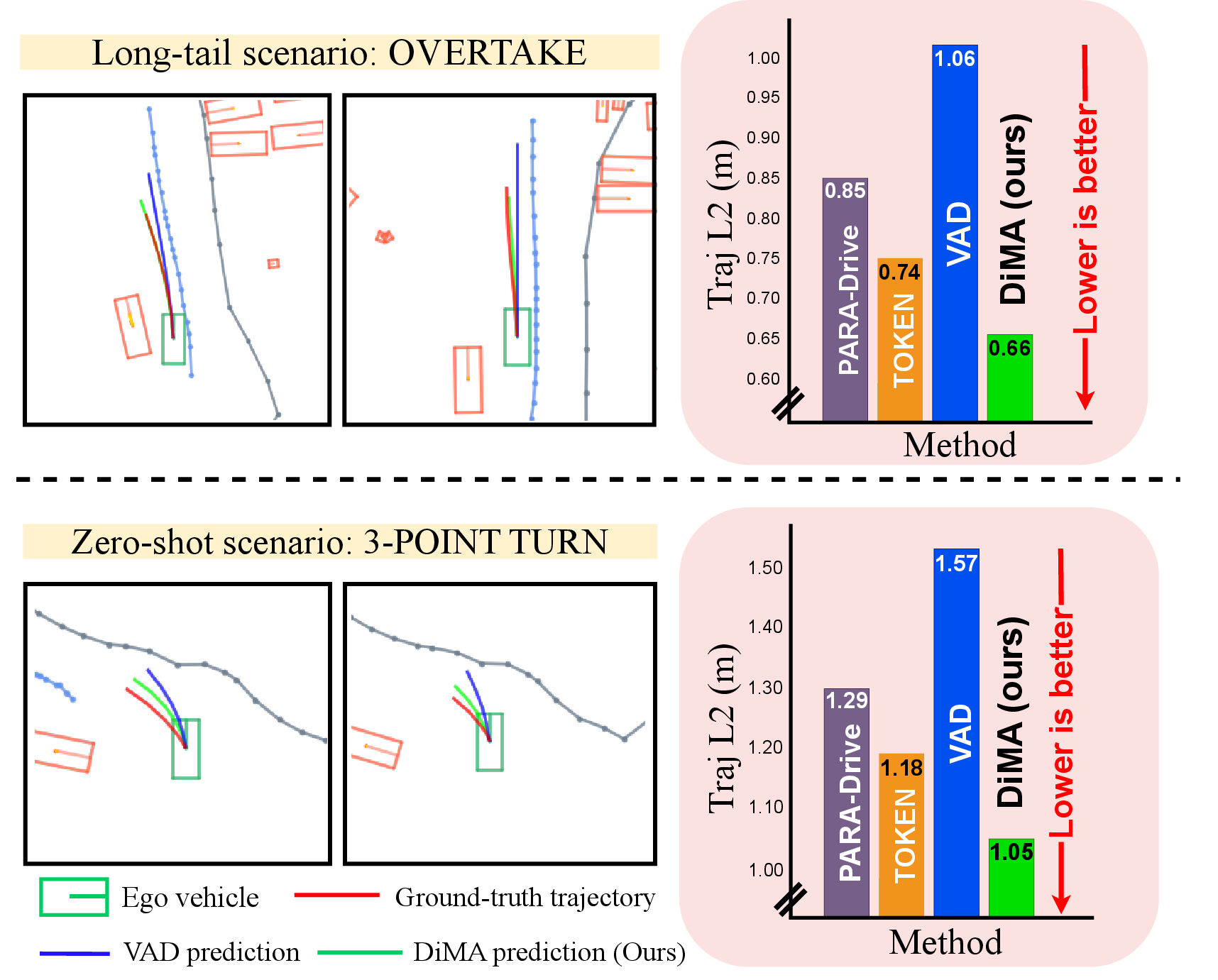
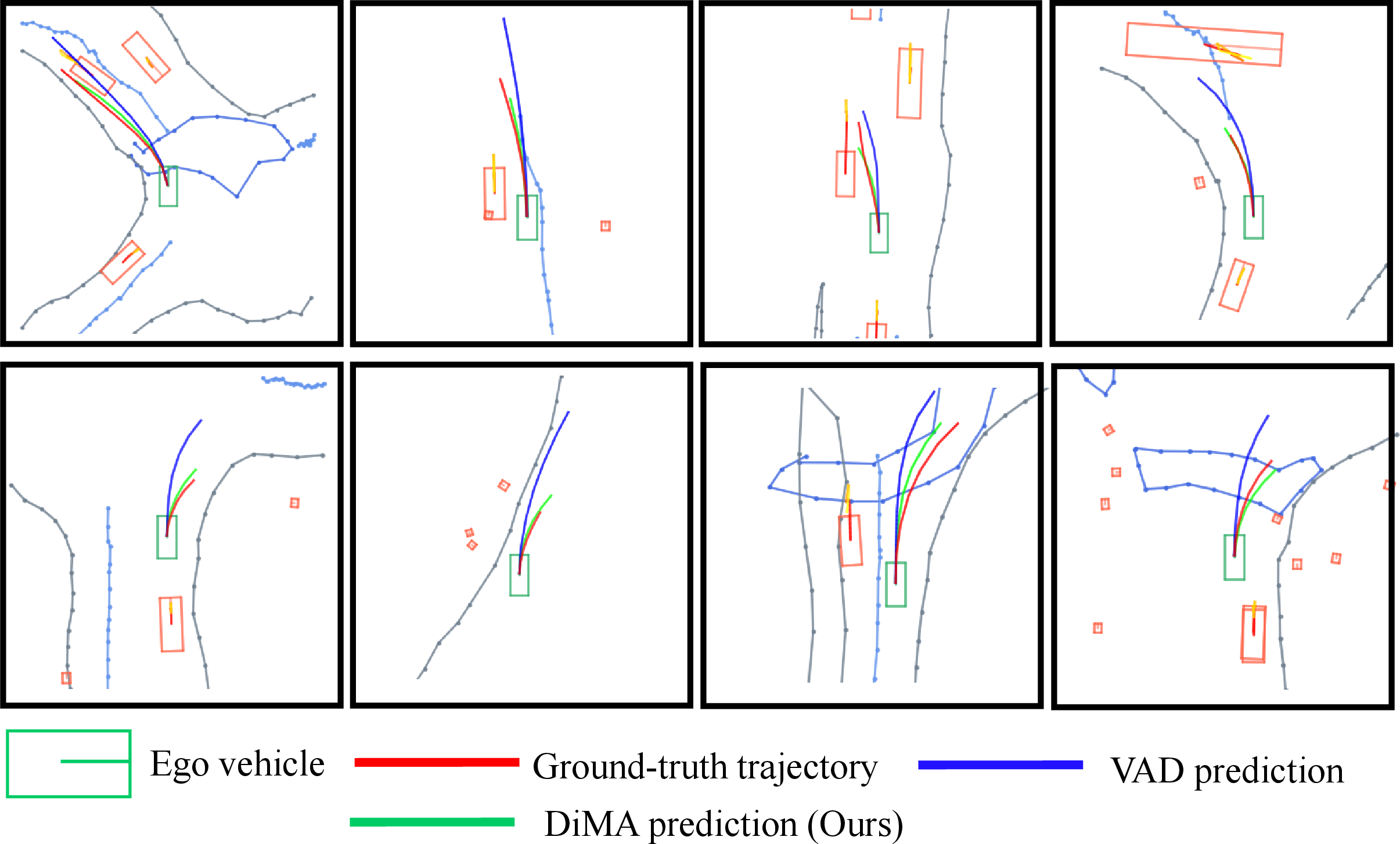
In tests on a well-known self-driving dataset (nuScenes), DistillDrive achieved:
- 37% lower trajectory error (the planned path is much closer to the correct path)
- 80% fewer collisions (big safety improvement)
- 44% lower trajectory error in rare “long-tail” scenarios (like unusual maneuvers)
- State-of-the-art performance compared with other top methods
DistillDrive beat both:
- Vision-only planners (fast but less robust),
- And LLM-based planners (smart but slow at test time),
while staying efficient because it doesn’t need the LLM during driving.
It also handled tough cases:
- Overtaking safely,
- Resuming from a stop,
- A 3-point turn that wasn’t seen in training (zero-shot)—it still did well, showing it can generalize.
5) Why does this matter? What’s the impact?
- Safer self-driving: Fewer collisions and more accurate paths mean safer rides.
- Better in rare events: Cars encounter lots of “weird” situations—this system learns to handle them using the LLM’s broad knowledge.
- Fast and practical: The car doesn’t need a big LLM running all the time, which saves computing power and cost.
- More understandable and flexible: The system can also answer questions about the scene (visual question answering), helping developers and safety teams understand what the car “sees” and plans.
In short, DistillDrive shows how to combine the brains of a LLM with the speed of a vision-based planner to get a smart, efficient, and safer self-driving system.
Collections
Sign up for free to add this paper to one or more collections.