- The paper presents a mixed-initiative methodology called Culture Cartography that identifies culturally-salient knowledge gaps in LLMs.
- It integrates LLM-driven question generation with human editing in a tree-structured, iterative constrained annotation process.
- Evaluation indicates that fine-tuning on Culture Cartography data significantly boosts model accuracy on cultural benchmarks while mitigating test contamination.
Culture Cartography: Mixed-Initiative Mapping of Cultural Knowledge Gaps in LLMs
Motivation and Problem Statement
The paper introduces Culture Cartography, a mixed-initiative methodology for eliciting culturally-salient knowledge gaps in LLMs. The motivation stems from the observation that LLMs, despite their broad utility, often lack knowledge specific to under-represented cultures due to pre-training and post-training data imbalances. This deficit impairs the effectiveness of LLMs as personal assistants, recommender systems, and conversational agents for global users, and increases the risk of generating culturally insensitive or harmful outputs. Existing approaches to identifying missing cultural knowledge are predominantly single-initiative: either researchers define challenging questions for annotators (traditional annotation), or LLMs extract knowledge from web sources (knowledge extraction). Both paradigms fail to simultaneously capture knowledge that is both salient to in-group users and unknown to LLMs.
Methodology: Mixed-Initiative Culture Cartography
Culture Cartography operationalizes a mixed-initiative annotation process via the Culture Explorer tool. The methodology integrates four key components:
- LLM-Driven Question Generation: The LLM proposes questions for which it has low-confidence answers, explicitly surfacing its knowledge gaps.
- Human-Driven Edits and Questioning: Human annotators can directly edit or propose new questions, steering the process toward culturally salient topics.
- Iterative Constrained Generation: Human edits constrain subsequent LLM generations, ensuring the interaction is genuinely mixed-initiative.
- Tree-Structured Knowledge Visualization: The annotation process is organized as a branching tree, enabling parallel exploration and direct manipulation.
This approach contrasts with linear, chat-based annotation interfaces by affording annotators greater control over the topical distribution and depth of the knowledge elicited.
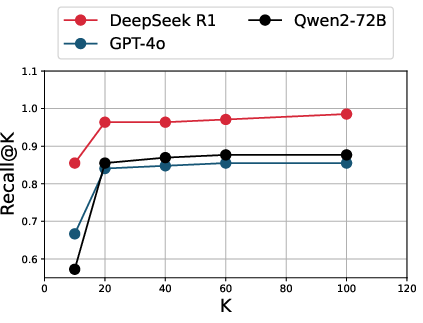
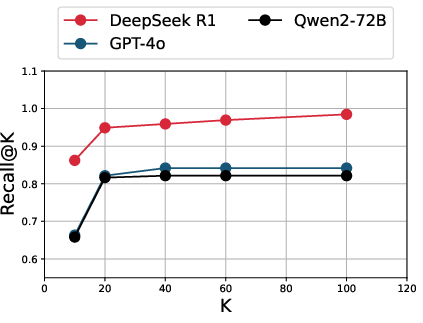
Figure 1: On Synthetic Indonesian Data, recall@K curves for DeepSeek R1, GPT-4o, and Qwen2-72B plateau by K=100, indicating saturation on synthetic benchmarks but not on Culture Cartography data.
Data Collection and Annotation Pipeline
Culture Explorer was deployed to build cultural knowledge banks for Nigeria and Indonesia, leveraging annotators from diverse ethnolinguistic groups. The annotation pipeline comprises three distinct data subsets:
- Synthetic Data: Annotators validate LLM-generated answers to fixed questions, scoring quality on a 0-3 Likert scale. Only statistically superior answers are retained.
- Traditional Annotation: Annotators provide new answers to the same fixed questions, focusing on knowledge not already captured by the LLM, but cannot edit questions.
- Culture Cartography: Annotators freely edit, add, or delete questions and answers, unconstrained by fixed templates, iteratively expanding the knowledge tree.
Inter-annotator agreement (ICC ≥ 0.55) indicates moderate reliability, and the average quality scores for LLM answers are above 2.5/3.0, suggesting high precision when LLMs answer their own pre-determined cultural questions.
Evaluation: Model Recall and Knowledge Gaps
The evaluation framework uses LLM-as-a-Judge (GPT-4o) to compute Recall@K for seven flagship models (DeepSeek R1, Llama-4, GPT-4o, o3-Mini, Claude 3.5 Sonnet, Qwen2-72B, Mixtral-8x22B). Key findings include:
- Culture Cartography Data is More Challenging: Compared to traditional annotation, Culture Cartography data is 6–10% less likely to be recalled by DeepSeek R1, and up to 42% less likely by other models. The effect sizes (Cohen's d = 0.17–0.32) are statistically significant.
- Model Performance Stratification: DeepSeek R1 achieves the highest recall (85% Indonesia, 82% Nigeria), saturating synthetic and traditional annotation subsets but not Culture Cartography. Mixtral-8x22B recalls less than half of the Culture Cartography data. Model performance is not strictly correlated with size or API status.
- Topical Distribution of Knowledge Gaps: Concept induction (LlooM) reveals that missing knowledge predominantly concerns community engagement, cultural preservation, family roles, and exclusive cultural practices—topics central to social cohesion and identity.
Google-Proofness and Test Set Contamination
Culture Cartography data is demonstrably "Google-Proof": enabling web search for GPT-4o does not improve recall on Culture Cartography subsets (recall drops from 69.7% to 54.8% for Nigeria, p<0.0001). This indicates that the elicited knowledge is not easily discoverable online, mitigating risks of test set contamination prevalent in knowledge extraction methods.
Transfer Learning: Downstream Cultural Competence
Fine-tuning Llama-3.1-8B and Qwen2-7B on Culture Cartography data yields significant improvements on external culture benchmarks (BLEnD, CulturalBench):
- Llama-3.1-8B: SFT+DPO on Culture Cartography boosts accuracy by up to 19.2% on CulturalBench-ind and 7.1% on BLEnD-ind, outperforming both vanilla and traditionally annotated models (p<0.0001).
- Qwen2-7B: Directionally similar improvements, though less pronounced due to higher baseline performance.
- Closing the Gap: Fine-tuning with Culture Cartography data narrows the performance gap between smaller open models and larger proprietary models (GPT-4o with search).
Implementation Considerations
- Interface: Culture Explorer is built on the Farsight codebase, supporting direct manipulation of tree-structured knowledge.
- Prompt Engineering: Domain-specific prompts are used for question and answer generation, with uncertainty estimation to highlight low-confidence LLM outputs.
- Annotation Incentives: Annotators are rewarded for novel contributions, quantified by edit distance.
- Scalability: The tree-based approach enables efficient parallel exploration, but recruitment of annotators from under-represented cultures remains a bottleneck.
- Fine-Tuning: SFT and DPO are applied using LoRA adapters (rank 8, α=16, dropout 0.1), with preference pairs derived from statistically significant score differences.
Limitations and Ethical Considerations
- Annotator Recruitment Bias: Reliance on Upwork introduces demographic and socioeconomic biases; coverage of ethnolinguistic groups is incomplete.
- Scope of Cultural Knowledge: The current implementation focuses on factual knowledge; broader cultural artifacts (stories, history, material culture) require further engineering.
- Risks in Deployment: Potential for LLMs to misrepresent or flatten cultural nuance; mitigated by critical instructions and safety-aligned models.
- Ethics: IRB approval, fair compensation, and anonymization protocols are followed.
Conclusion
Culture Cartography, implemented via Culture Explorer, advances the elicitation of culturally-salient knowledge gaps in LLMs through a mixed-initiative, tree-structured annotation paradigm. The methodology produces data that is both more challenging for state-of-the-art models and more representative of in-group cultural interests, while being resistant to test set contamination. Fine-tuning on Culture Cartography data yields substantial improvements in downstream cultural competence, supporting the development of more globally representative and culturally-aware NLP systems. Future work should extend the methodology to encompass broader cultural domains and address recruitment biases to further democratize cultural knowledge representation in AI.

