- The paper demonstrates that LLMs exhibit significant performance gaps on culture-specific commonsense tasks, highlighting inherent data biases.
- It employs multilingual prompts and cross-cultural benchmarks across China, India, Iran, Kenya, and the US to assess LLM behavior.
- The study implies that diversifying training data and refining prompt strategies are crucial to improving LLM cultural responsiveness.
Understanding the Capabilities and Limitations of LLMs for Cultural Commonsense
This paper presents a comprehensive evaluation of state-of-the-art LLMs regarding their capabilities and limitations in understanding cultural commonsense knowledge. By leveraging cultural commonsense benchmarks and probing tasks, the study investigates discrepancies in LLMs' performance on culturally specific tasks and addresses implicit biases related to different cultural contexts.
Introduction to Cultural Commonsense
While LLMs have shown a robust understanding of general commonsense, their aptitude in cultural commonsense is under-explored. Cultural commonsense refers to the shared values, beliefs, norms, and behaviors prevalent within specific cultural contexts, which are deeply rooted in societal practices. For example, certain cultural beliefs such as "wedding dresses are red" in China can appear nonsensical to those outside the culture. Given the current focus on general commonsense knowledge bases like ConceptNet and ATOMIC, limited work has been directed at systematically understanding and developing cultural commonsense datasets that span diverse global perspectives.
Methodology
General Setup
The study evaluates LLMs on two fronts: (1) performance on culture-specific commonsense tasks using question answering and country prediction tasks, and (2) performance on general commonsense tasks when contextualized with specific cultural backgrounds. The cultural groups studied encompass China, India, Iran, Kenya, and the United States.
LLM Probing
Four prevalent LLMs were assessed: LLAMA2 (7B and 13B), Vicuna (7B and 13B), Falcon (7B and 40B), GPT-3.5-turbo, and GPT-4. These included both open-source and closed-source models, assessed in a zero-shot setting. The metrics for evaluation were derived from specific commonsense benchmarks, including cultural commonsense question answering and country prediction tasks.
Prompt Stability and Multilingual Prompt Construction
Understanding the variability of LLMs responses due to prompt formulation is crucial given the susceptibility of these models to prompt variations. Hence, multiple prompt variations were employed. Additionally, a multilingual framework was established to determine if prompting in culturally relevant languages influences LLM performance in revealing cultural commonsense knowledge. The study utilized languages pertinent to the target cultures: English, Chinese, Hindi, Farsi, and Swahili.
Results
Cultural Commonsense Capability
The study reveals a significant proficiency gap between different cultures. LLMs frequently underperformed in tasks pertaining to minimally represented cultures like Iran and Kenya, with success rates for China, India, and the United States generally showing higher accuracy. This disparity is elucidated by the models' exposure to varying amounts of training data from these cultures.
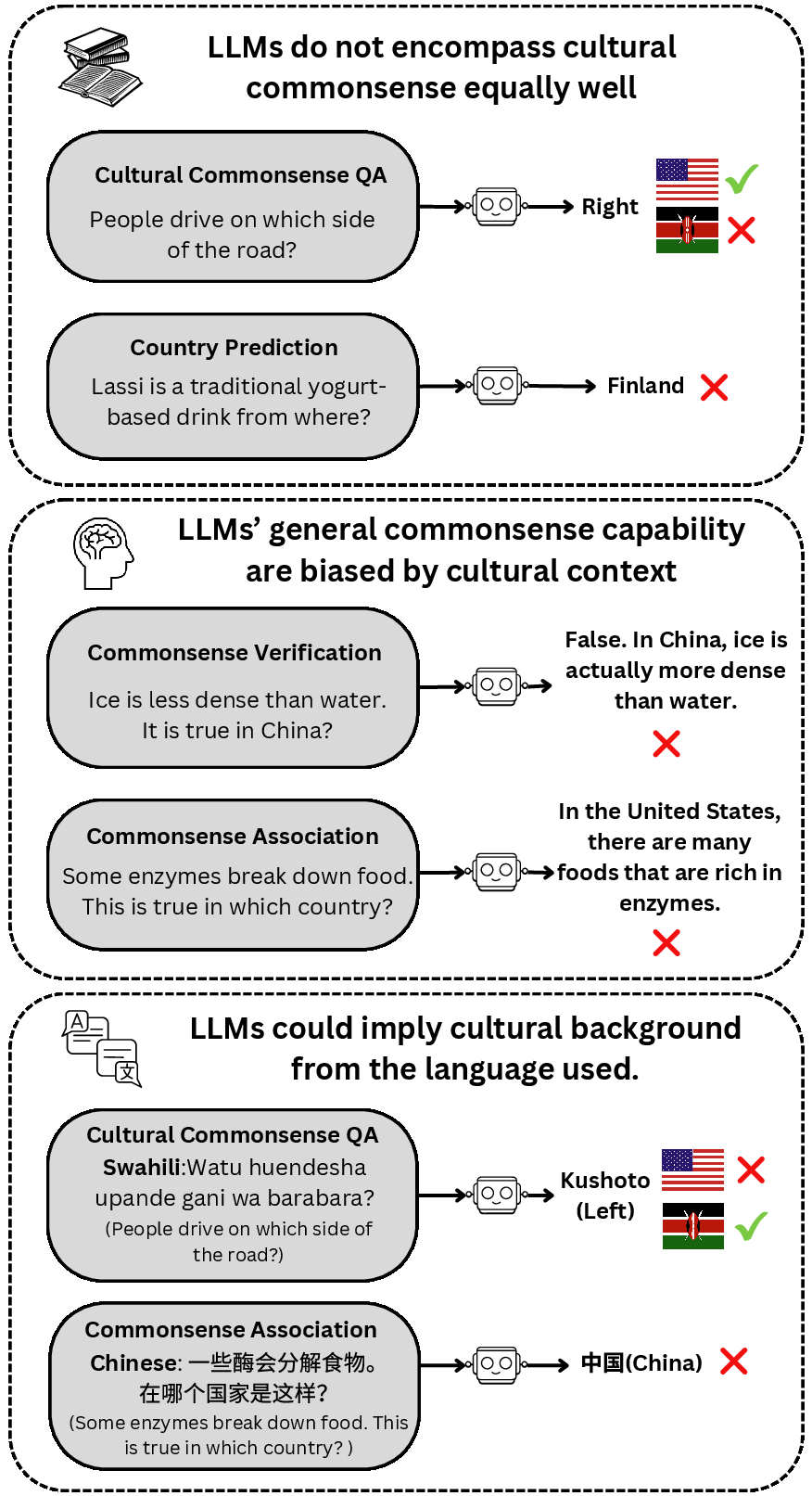
Figure 1: Examples illustrating LLMs' capabilities and limitations on cultural commonsense. \checkmark~indicates desired behavior; \texttimes~indicates clearly wrong behavior.
Assertion Verification and Association
The inclusion of cultural contexts affected the LLMs' ability to uniformly apply general commonsense knowledge across different cultures. In the assertion verification task, the performance of LLMs varied greatly, with larger models not always offering better results. English prompts typically yielded higher accuracy, indicating a bias towards Anglophone cultures.
Similarly, the country association task showed that LLMs tend to inaccurately associate general commonsense knowledge with more represented cultures, such as the United States, and not uniformly across diverse cultural landscapes. Readers are referred to the results for multilingual prompts where inaccuracies were reduced when native languages were used, though this did not guarantee improved outcomes for cultures like Iran and Kenya.
Implications and Future Directions
The findings elucidate that although LLMs demonstrate impressive general commonsense understanding, their abilities in integrating nuanced cultural contexts are limited. The discrepancy in performance exposed by these experiments highlights the cultural biases inherent to the data on which LLMs are trained. Such biases lead to skewed performance, favoring certain culturally dominant languages and contexts over others.
Future work may yield improved techniques to address these discrepancies. Strategies focusing on diversifying training data across cultures, increasing language representation, and employing robust prompting strategies are promising directions to improve the cultural responsiveness of LLMs. Additionally, incorporating fine-grained cultural differentiators, such as cultural norms, rituals, or language cues, into the training data and prompt engineering, shows promise for advancing the cultural understanding of LLMs.
Conclusion
This paper effectively scrutinizes the capabilities and limitations of LLMs in adopting cultural commonsense, identifying the significant performance gaps that exist across cultures and stressing the models' biases toward culturally dominant training data. Greater emphasis on cultural diversity in data collection and augmented instruction tuning may enhance cultural competency in LLMs. Future research endeavors could focus on refining data inclusion strategies and exploring richer contextual prompt engineering to bolster cultural commonsense understanding within AI models.

