RDMA Point-to-Point Communication for LLM Systems
Abstract: Emerging LLM system patterns, such as disaggregated inference, Mixture-of-Experts (MoE) routing, and asynchronous reinforcement fine-tuning, require flexible point-to-point communication beyond simple collectives. Existing implementations are locked to specific Network Interface Controllers (NICs), hindering integration into inference engines and portability across hardware providers. We present TransferEngine, which bridges the functionality of common NICs to expose a uniform interface. TransferEngine exposes one-sided WriteImm operations with a ImmCounter primitive for completion notification, without ordering assumptions of network transport, transparently managing multiple NICs per GPU. We demonstrate peak throughput of 400 Gbps on both NVIDIA ConnectX-7 and AWS Elastic Fabric Adapter (EFA). We showcase TransferEngine through three production systems: (1) KvCache transfer for disaggregated inference with dynamic scaling, (2) RL weight updates achieving 1.3 seconds for trillion-parameter models, and (3) MoE dispatch/combine implementation exceeding DeepEP decode latency on ConnectX-7, with the first viable latencies on EFA. We demonstrate that our portable point-to-point communication complements collectives while avoiding lock-in.
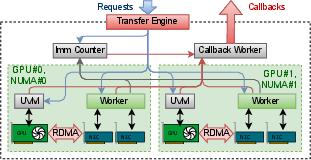
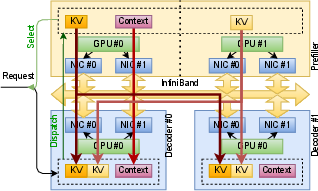
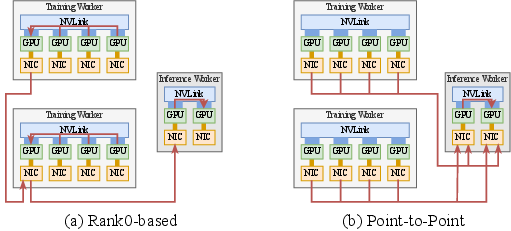
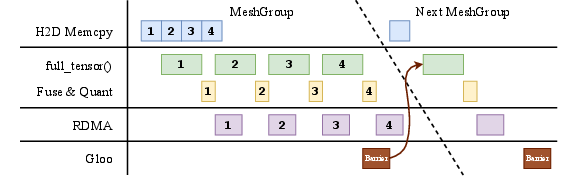


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
LLMs like the ones behind chatbots have grown huge and complicated. To run them fast and flexibly, different computers and GPUs need to send data to each other directly, quickly, and in lots of different patterns—not just the standard “everyone share with everyone” way. This paper introduces a new communication library called TransferEngine that lets GPUs send data directly to other GPUs (point-to-point) at very high speed, even when the cloud provider uses different kinds of network hardware. It aims to be fast, flexible, and portable, so teams aren’t stuck with one vendor’s system.
What questions the paper tries to answer
The paper focuses on three simple questions:
- How can we send data directly between GPUs in flexible ways that modern LLMs need (like Mixture-of-Experts and split prefill/decode), instead of only using group-style communication?
- How can we do this fast across different network cards (like NVIDIA ConnectX-7 and AWS EFA) without rewriting everything for each one?
- Can this approach improve real LLM systems, like faster routing for experts, quicker model weight updates for reinforcement learning, and speedy transfers of caches during inference?
How the researchers approached the problem
Think of computer memory as a set of mailboxes, and network cards (NICs) as delivery trucks that move packages between mailboxes on different machines.
Here’s the core idea:
- RDMA is like a special fast-lane delivery system. It lets one machine write directly into another machine’s memory mailbox without the receiver doing extra work—no stopping at the post office, no waiting in line.
- One-sided Write is like dropping a package straight into the other mailbox; the receiver doesn’t have to “open the door.”
- WriteImm is the same drop-off, but with a small “sticker” included (an immediate number) that makes it easy to count arrivals quickly.
The challenge: different cloud providers use different road rules. For example:
- NVIDIA ConnectX (RC transport) usually delivers packages in order.
- AWS EFA (SRD transport) is reliable but can deliver packages out of order.
The solution: TransferEngine uses only features that both types support and avoids assuming packages arrive in order. Instead, it uses an “ImmCounter”—a counter that increases when a package with a sticker arrives. This way, the receiver doesn’t care about the exact order; it just knows how many have arrived. The library also automatically uses multiple NICs per GPU (like driving on multiple lanes) to reach top speeds, especially on AWS where you often need to combine several NICs to hit 400 Gbps.
To make this work in practice, the authors:
- Built a simple API that can register memory, send small messages, and do fast one-sided writes.
- Added “scatter” operations to send the right slices to many peers at once, and lightweight barriers to synchronize.
- Used a tiny host proxy thread for some cases to coordinate GPU progress and NIC transfers without slowing things down.
- Tuned the system for different NICs: they used libfabric on AWS EFA and libibverbs on ConnectX-7, and added tricks like request templates and relaxed ordering to cut latency.
They then showed it in action in three real systems:
- KvCache transfer for disaggregated inference: Prefill happens on one GPU, decode on another. They transfer layer outputs quickly, so decoding can start sooner.
- Reinforcement learning weight updates: Training GPUs write new weights directly into inference GPUs, making huge models update in about 1.3 seconds—more than 100× faster than common setups.
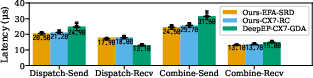
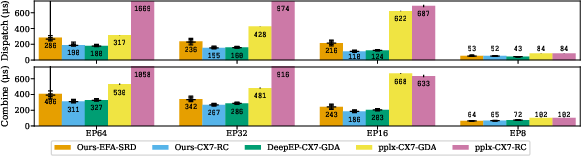
- Mixture-of-Experts routing: They dispatch and combine tokens efficiently, beating a specialized system called DeepEP on ConnectX-7 and making EFA viable for the first time.
What they found and why it matters
Key results that show this approach works:
- High throughput across vendors: Up to 400 Gbps on both NVIDIA ConnectX-7 and AWS EFA, even though those networks behave differently.
- Super-fast RL updates: Trillion-parameter models can get new weights in about 1.3 seconds by having each training GPU write directly into the right inference GPU. This avoids the usual “everyone gather to one leader, then broadcast” bottleneck.
- MoE routing performance: On ConnectX-7, their portable approach achieved state-of-the-art decode latency, even though it uses a host proxy. On EFA, it’s the first implementation that reaches practical (viable) latencies.
- Disaggregated inference made practical: KvCache transfers work with low latency, support dynamic scaling, and don’t require slow synchronized setup steps. That means serving can be more flexible—machines can join or leave without the whole system stopping.
Why this matters:
- Modern LLMs rely on flexible communication patterns: sending to only the experts needed, scaling up and down, and connecting different nodes for prefill vs decode.
- Group-based libraries (“collectives”) are great for fixed, uniform patterns, but they struggle with dynamic membership, uneven message sizes, or “just-send-to-this-one-peer-now” use cases.
- TransferEngine fills that gap and avoids being locked into one hardware vendor, which is crucial for cloud deployments.
What this could mean going forward
This work shows that portable, point-to-point communication can be fast enough for cutting-edge LLM use cases while staying flexible across different cloud networks. The potential impact includes:
- Faster, more elastic LLM serving: Disaggregated inference can scale up or down smoothly and respond quickly to user demand.
- Speedier reinforcement learning loops: Quicker weight updates mean faster progress and more responsive training.
- Broader MoE support in the cloud: Teams aren’t locked to specific NICs anymore, so they can choose providers based on cost and availability.
- Easier integration: The library can plug into popular frameworks and kernels, helping the wider ecosystem adopt modern communication patterns.
In short, the paper shows how to bridge the gap between different network technologies and the evolving needs of LLM systems, giving developers a simple, high-speed tool to build faster, more flexible AI services.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved gaps and limitations that future work could address to strengthen the paper’s claims and broaden the applicability of TransferEngine.
- ImmCounter semantics and correctness:
- No formal specification or proof of correctness for ImmCounter under out-of-order transports (EFA SRD), including handling of duplicates, reordering, lost completions, and exact atomicity guarantees on receivers.
- Counter wrap-around and reuse policies for 32-bit immediate values are unspecified (lifecycle, garbage collection, collision avoidance, and safety under high concurrency).
- Recovery behavior when a sender or receiver experiences partial failure mid-transfer is not defined (e.g., counter reconciliation after NIC reset).
- Transport and hardware coverage:
- The library’s portability is demonstrated only on NVIDIA ConnectX-7 and AWS EFA; support and performance on other cloud RDMA implementations (Alibaba eRDMA, Google Falcon, Broadcom/Intel NICs) remain unexplored.
- No path for GPU-initiated RDMA (IBGDA) when available; the design is host-proxy-bound even on NICs that can support GPU doorbells, which leaves potential latency gains untapped.
- Topology heterogeneity:
- The restriction that all peers must use the same number of NICs per GPU limits deployment flexibility; adaptive sharding across nodes with heterogeneous NIC counts and link speeds is not addressed.
- No evaluation of multi-NIC scaling beyond two EFA NICs (e.g., 4×100 Gbps setups common in AWS p5), nor the impact of PCIe/NVSwitch/NVLink topologies and NUMA placement on scaling and fairness.
- Flow control and backpressure:
- Absence of explicit backpressure mechanisms for Recv buffer pools and one-sided Writes (e.g., sender throttling, dynamic pacing, credit-based flow control) risks message drops or memory clobber under load.
- Congestion management on SRD/RC (CNP handling, adaptive rate control, head-of-line blocking behavior) is not discussed or evaluated at scale.
- Security and isolation:
- No discussion of security for one-sided Writes (RKey distribution policies, protection domains, revocation, per-tenant isolation), especially in multi-tenant cloud environments.
- Lack of integrity protection for payloads (checksums/end-to-end verification) leaves silent data corruption unaddressed.
- Fault tolerance and consistency:
- In RL weight updates, inference nodes are “unaware” of transfers; the protocol for safe cutover (versioning, atomicity across all weights and GPUs, rollback on failure) is unspecified.
- Disaggregated inference cancellation and heartbeat handling are mentioned, but broader failure scenarios (NIC resets, network partitions, partial completion of paged writes) and recovery strategies are not fully described.
- No cross-node two-phase commit or transactional semantics for ensuring consistent weight sets across large inference fleets.
- NVLink memory-model correctness:
- The use of relaxed flags and release-acquire semantics across GPUs and the host lacks a formal memory-model analysis; potential races, stale reads, or visibility anomalies on future architectures remain an open risk.
- Memory footprint and prefill limitations:
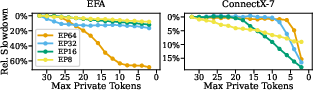
- Decode-optimized MoE buffers are reported to limit prefill viability; concrete strategies to reduce buffer memory (chunking/streaming, hierarchical transfers, dynamic staging) are not implemented or evaluated.
- Routing overhead and scalability:
- Centralized exchange of per-expert token counts introduces overhead; scalability of route computation and processing (CPU burden, per-peer enqueue microsecond costs) is not characterized for 128–256+ ranks.
- Alternative designs (hierarchical routing, compression of counts, two-level scatters) are not explored.
- Evaluation scope and tails:
- End-to-end metrics for disaggregated inference (latency, throughput, SLO compliance under real workloads) are missing.
- RL update times are reported (1.3 s) without tail latency distribution, jitter analysis, or sensitivity to cluster topology and background traffic.
- EFA performance is shown for dual NICs; lack of results on quad NIC configurations and tail latency under high fanout limits generality.
- NVSHMEM on EFA is described as “unusably slow” without quantitative baselines; comparisons against UCX/UCCL-EP or updated NIXL releases are incomplete.
- API and usability:
- The API requires users to manually coordinate multi-device operations; higher-level abstractions for dynamic membership, discovery, and elasticity (critical for production disaggregated inference) are not provided.
- Memory registration overheads (GPU/host MR lifetimes, fragmentation, pinning costs) and strategies for MR reuse/caching are not measured or documented.
- EFA-specific behavior:
- The enforced “valid descriptor” requirement for immediate-only zero-sized writes on EFA introduces overhead; the impact on latency and correctness versus RC semantics is not analyzed.
- Differences in completion semantics (e.g., EFA waiting for receipt confirmation) are mentioned but not quantified for throughput/latency penalties under varying message sizes.
- Read/atomic operations:
- Read and atomic operations are excluded due to latency concerns, but the potential benefits of limited/control-path use (e.g., fetch-add counters, small reads for protocol state) are not empirically evaluated.
- CPU overhead and energy:
- CPU utilization of worker and callback threads (busy-polling with GDRCopy, completion queues) is not reported; potential energy/efficiency trade-offs and core contention in multi-tenant environments are unknown.
- Robustness to mixed precisions and quantization:
- RL pipeline mentions projection fusion and quantization; the correctness, numerical stability, and validation strategy for weight transformations across heterogeneous precisions is not explored.
- NIC resource management:
- Queue pair counts, doorbell batching (WR chaining), and NIC resource exhaustion under high peer counts are not characterized; QoS or prioritization mechanisms are absent.
- HBM/PCIe relaxed ordering:
- IBV_ACCESS_RELAXED_ORDERING is enabled to reduce latency, but the paper does not analyze potential consistency side-effects or conditions under which relaxed ordering could induce correctness issues with GPU memory.
- Small-message performance:
- While large messages saturate bandwidth, small-message latencies (critical for control paths like MoE route exchange) on SRD remain suboptimal; strategies to coalesce or redesign control traffic are not proposed.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, based on the paper’s findings and TransferEngine’s current capabilities.
- Portable RDMA point-to-point layer for LLM inference across AWS EFA and NVIDIA ConnectX
- Sectors: software/cloud infrastructure, NLP platforms
- Potential tools/products/workflows: Integrate TransferEngine as a networking backend in vLLM, SGLang, TensorRT-LLM, FlashInfer to avoid vendor lock-in; use Send/Recv for control-path RPC and WriteImm + ImmCounter for data-path transfers; aggregate multiple NICs per GPU (e.g., EFA on p5/p5en) to reach 400 Gbps
- Assumptions/dependencies: RDMA-enabled NICs (EFA or ConnectX), libfabric/libibverbs availability, GPUDirect RDMA and GDRCopy in production kernels, peers using the same number of NICs per GPU, system-level NUMA pinning and proper memory registration
- Disaggregated inference with elastic prefiller–decoder separation via low-latency KvCache page transfer
- Sectors: consumer and enterprise AI applications (chatbots, copilots, search, customer service), education (interactive tutoring), healthcare (clinical summarization), media (real-time captioning)
- Potential tools/products/workflows: Layer-by-layer KvCache transfer triggered via UVM watcher inside CUDA Graphs; dynamic scaling without NCCL world formation; heartbeat + cancellation tokens for fault tolerance; page-wise offsets/strides for GQA and replica mapping for MLA
- Assumptions/dependencies: CUDA Graph compatibility for UVM watcher increments, KV cache page layout (head-first for contiguity), stable RDMA keys (RKey) exchange, robust scheduling (prefiller/decoder pairing and re-routing on failures)
- Fast RLHF/async RL rollout weight distribution (≈1.3 s for trillion-parameter models)
- Sectors: ML training platforms, reinforcement learning frameworks
- Potential tools/products/workflows: P2P one-sided RDMA Write directly from each training GPU to inference GPUs; pipeline stages (H2D memcpy, full_tensor reconstruction/projection/quantization, zero-copy RDMA, global barrier on Ethernet via GLOO); integrate into Slime, OpenRLHF, AReaL, veRL, LlamaRL, NVIDIA NeMo
- Assumptions/dependencies: FSDP sharding and MeshGroup scheduling in place, adequate NIC bandwidth and multi-NIC aggregation, temporary memory watermarking to prevent OOM, secure RKey handling, consistent device meshes and tensor dtypes across training/inference
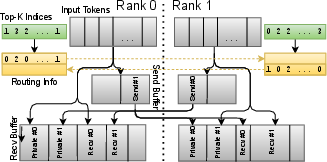
- MoE dispatch/combine kernels with host proxy thread (state-of-the-art decode latency on ConnectX-7; first viable latencies on EFA)
- Sectors: LLM serving and kernel libraries
- Potential tools/products/workflows: Host proxy coordination with GDRCopy polling, routing info exchange, private buffers to hide route latency, bulk scatter via WriteImm and ImmCounter barrier; intra-node NVLink transfers, inter-node RDMA writes; integrate into TensorRT-LLM/FlashInfer and custom MoE routers
- Assumptions/dependencies: NVLink available intra-node, proper private buffer sizing (e.g., ≥24–32 tokens to hide route exchange), EP configuration (e.g., EP=64), relaxed ordering enabled (IBV_ACCESS_RELAXED_ORDERING), CPU core pinning for proxy threads
- Multi-cloud/hybrid inference deployment without vendor lock-in
- Sectors: enterprise IT, platform teams
- Potential tools/products/workflows: Same inference stack runs on AWS (EFA) and on-prem/hyperscaler clusters (ConnectX-7); unified NetAddr exchange; per-domain sharding and load-balancing across NICs; dynamic membership outside NCCL collectives
- Assumptions/dependencies: RDMA connectivity and permissions across environments, NIC parity across peers, operational guardrails for cross-cloud routing and egress costs
- Robust operational workflows for disaggregated inference (fault detection, cancellation, backpressure)
- Sectors: SRE/DevOps for AI services
- Potential tools/products/workflows: Heartbeat messages to detect transport failures; per-request cancellation tokens that wait for pending writes to drain; timeouts for unresponsive peers; buffer pools for Send/Recv to avoid message rejection
- Assumptions/dependencies: Health checks integrated into schedulers, sufficient receive buffers pre-posted, explicit confirmation protocols to prevent KvCache corruption on cancellation
- Performance benchmarking and NIC selection for P2P ML networking
- Sectors: academia (systems research), industry (capacity planning)
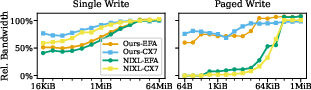
- Potential tools/products/workflows: Use TransferEngine and vendor tools (fi_rma_bw, ib_write_bw) to measure saturation points (e.g., single write saturates at ≥16 MiB; paged writes saturate at 32–64 KiB); inform workload tuning (MoE vs KvCache vs weights)
- Assumptions/dependencies: Access to RDMA hardware, consistent driver and library versions, realistic test payload sizes and paging strategies
- Vendor-neutral procurement and governance guidance (avoid lock-in to GPU-initiated RDMA-only stacks)
- Sectors: policy/IT governance, procurement
- Potential tools/products/workflows: Require support for EFA (SRD) and ConnectX (RC) with unordered-reliable abstraction; insist on WriteImm + completion counters rather than transport ordering; evaluate portability/cost-performance across providers
- Assumptions/dependencies: Organizational policy enforcement, supply chain availability of RDMA NICs, alignment with compliance/security requirements
- End-user experience improvements through lower latency and elastic serving
- Sectors: consumer apps, productivity tools
- Potential tools/products/workflows: Faster decode latency (MoE) and elastic capacity (disaggregated inference) leading to snappier chatbots, coding assistants, and real-time summarization
- Assumptions/dependencies: Providers adopt the networking stack; steady-state QoS on RDMA networks; safe fallbacks under congested/oos conditions
Long-Term Applications
The following applications need further research, standardization, scaling, or productization before broad deployment.
- GPU-initiated RDMA across providers (IBGDA-equivalent for EFA and others) to remove host proxy overhead
- Sectors: hardware/networking, ML systems
- Potential tools/products/workflows: Standardized GPU-side doorbells and completion semantics compatible with unordered reliable transports; kernel-level integration of ImmCounter-like primitives
- Assumptions/dependencies: NIC vendor support, unified APIs beyond ConnectX (e.g., libfabric extensions), firmware/driver maturity
- RDMA-backed distributed KvCache storage with full EFA support
- Sectors: LLM infrastructure, in-memory data services
- Potential tools/products/workflows: Production-grade KvCache store with page migration, replication, and eviction policies; integration with Mooncake Store or 3FS once EFA support is mature
- Assumptions/dependencies: Consistent RDMA capabilities across clusters, cache coherence policies, multi-tenant isolation, operational tooling for recovery and compaction
- Network-aware MoE co-design (fewer, larger bulk transfers and route-aware scheduling)
- Sectors: AI research, kernel optimization
- Potential tools/products/workflows: Architectures and routing algorithms that minimize packetization and leverage bulk scatter/combine; training-time regularization for communication patterns
- Assumptions/dependencies: Model co-design acceptance, changes to training pipelines, evaluation of accuracy vs communication efficiency trade-offs
- Edge-to-cloud federated inference using RDMA (RoCEv2) for real-time robotics and IoT
- Sectors: robotics, industrial automation, autonomous systems
- Potential tools/products/workflows: P2P bulk transfers of embeddings/KvCache between edge GPUs and cloud experts; RDMA-aware schedulers for deterministic latency
- Assumptions/dependencies: RoCE-enabled networks across WAN segments, security (RKey isolation, NIC firewalling), deterministic routing/QoS
- Security hardening and isolation for RDMA P2P operations
- Sectors: security/compliance, multi-tenant cloud
- Potential tools/products/workflows: RKey lifecycle management, memory protection domains, RDMA-aware service meshes, auditability for one-sided writes
- Assumptions/dependencies: NIC/driver features for isolation, integration with zero-trust policies, standardized logging and attestation
- Orchestration and autoscaling layers tailored to P2P RDMA
- Sectors: platform engineering
- Potential tools/products/workflows: Kubernetes operators/controllers that understand NIC groups, NetAddr discovery, and peer-group barriers; autoscalers that react to RDMA completion telemetry
- Assumptions/dependencies: Cloud-native integrations (CNI, SR-IOV), RDMA metrics export, consistent NIC inventory across nodes
- Energy/cost optimization via bulk P2P transfers and packet reduction
- Sectors: sustainability, FinOps
- Potential tools/products/workflows: Telemetry-driven tuning (buffer sizes, write batching, WR chaining), energy-aware scheduling; cost models comparing P2P vs collective
- Assumptions/dependencies: Access to detailed NIC/CPU/GPU power metrics, ability to reconfigure kernels and engine parameters in production
- Cross-cloud RDMA interoperability and standardization (unordered reliable transport APIs)
- Sectors: policy/standards, cloud providers
- Potential tools/products/workflows: Industry consortium for aligning SRD/RC semantics; portable WriteImm and completion notification standards
- Assumptions/dependencies: Multi-provider collaboration, updates to RDMA specs and libfabric/libibverbs, backward compatibility commitments
- QoS and congestion control tuned for LLM P2P traffic
- Sectors: networking
- Potential tools/products/workflows: NIC firmware features for prioritizing MoE/weights/KvCache traffic; adaptive sharding and pacing
- Assumptions/dependencies: NIC programmability, feedback loops from ImmCounter/completion queues, operator-defined policies
- Hardware offloads for completion notification and UVM watcher semantics
- Sectors: hardware acceleration
- Potential tools/products/workflows: ImmCounter implemented in NIC or GPU firmware, direct CUDA Graph integration for network-triggered callbacks
- Assumptions/dependencies: Vendor engagement, safe memory ordering models across devices, formal verification of completion atomicity
Glossary
- AReaL: A reinforcement learning framework referenced as a target for adopting the proposed P2P approach. "Our P2P weight update approach can be adopted by reinforcement learning frameworks, such as Slime, OpenRLHF, AReaL, veRL, LlamaRL, NVIDIA Nemo."
- AWS Elastic Fabric Adapter (EFA): AWS’s RDMA-capable network adapter that uses SRD and provides reliable but unordered delivery. "We demonstrate peak throughput of 400 Gbps on both NVIDIA ConnectX-7 and AWS Elastic Fabric Adapter (EFA)."
- Barrier: A synchronization primitive to ensure all peers have reached a point before proceeding. "submit_barrier is an immediate-only operation for peer notification."
- bf16: A 16-bit floating-point format (bfloat16) commonly used for training due to its dynamic range. "transferring weights from 256 training GPUs (bf16) to 128 inference GPUs (fp8)."
- Completion queue: RDMA queue where completion events are posted for sends/receives and immediate notifications. "notifying the receiver via a completion queue."
- ConnectX-7: NVIDIA’s high-speed NIC model supporting RC transport and GPUDirect features. "We demonstrate peak throughput of 400 Gbps on both NVIDIA ConnectX-7 and AWS Elastic Fabric Adapter (EFA)."
- CUDA Graph: A CUDA feature to capture and replay GPU workloads with low overhead. "Production tested on EFA with full CUDA Graph support"
- DeepEP: A high-performance, ConnectX-specific MoE routing library relying on GPU-initiated RDMA. "MoE dispatch/combine implementation exceeding DeepEP decode latency on ConnectX-7"
- DeviceMesh: A logical representation of devices used to define sharding and parallelism groups. "Each sharding strategy partitions the global DeviceMesh into disjoint sub-meshes."
- DTensor: A distributed tensor abstraction used to describe sharding across devices. "including weight name, shape, dtype, and DTensor sharding."
- Doorbell rings: NIC notifications triggered when posting work requests, whose count you want to minimize. "reducing the number of doorbell rings to the NIC."
- fi_rma_bw: A libfabric microbenchmark to measure RMA bandwidth on EFA-like fabrics. "On EFA, we use fi_rma_bw from libfabric to measure peak single-NIC bandwidth"
- FSDP: Fully Sharded Data Parallel; a strategy for sharding model parameters and optimizer states. "Our training job shards model weights using FSDP."
- GDRCopy: A library enabling low-latency CPU access to GPU memory, used for polling and flags. "Additionally, GPUDirect RDMA enables low-latency host-device memcpy via the GDRCopy library"
- GEMM (Grouped GEMM): Batched/grouped matrix multiplications, often used in expert computation. "following a layout suitable for Grouped GEMM kernels."
- GLOO: A collective communication backend used here for synchronization/barriers. "Global barrier: After all full_tensor() calls are done, synchronize across mesh groups using GLOO via Ethernet."
- GPUDirect Async (IBGDA): GPU-initiated RDMA that avoids host involvement for initiating transfers. "Transfers can be initiated either by the host, or if GPUDirect Async (IBGDA) is available, from the GPU itself to bypass PCIe overheads"
- GPUDirect RDMA: Direct NIC access to GPU memory over PCIe, avoiding extra copies through host memory. "GPUDirect RDMA enables RDMA NICs to directly access GPU memory over PCIe"
- GQA: Grouped Query Attention; an attention variant changing how heads are grouped and routed. "Under GQA \cite{ainslie2023gqa}, we rely on page-wise offsets and strides"
- H2D memcpy: Host-to-device memory copy; a stage in the weight-transfer pipeline. "Pipelined execution overlaps H2D memcpy, weight preparation, and RDMA transfer."
- HBM: High Bandwidth Memory on GPUs, critical for kernel throughput. "fully utilize the available HBM bandwidth."
- IBGDA: Abbreviation for GPUDirect Async; often used to describe kernels using GPU-initiated RDMA. "significantly faster than the IBGDA-based kernels on ConnectX-7"
- ibv_send_wr: The ibverbs send work request structure used to post operations on RC QPs. "through the \verb|next| pointer of ibv_send_wr"
- IBV_ACCESS_RELAXED_ORDERING: A verbs memory registration flag allowing relaxed PCIe ordering for performance. "IBV_-ACCESS_-RELAXED_-ORDERING"
- IBRC: NVSHMEM’s host-proxy mode built over InfiniBand Reliable Connection transport. "an order of magnitude faster than the NVSHMEM kernels using IBRC through the generic host proxy."
- ImmCounter: A counter primitive incremented by immediate values for completion notification without ordering assumptions. "The ImmCounter is a dedicated component that keeps track of per-immediate counters"
- Immediate value: A 32-bit value attached to RDMA writes to signal events to the receiver. "An immediate value can be optionally associated with Writes to increment a counter on the receiver upon receipt."
- KvCache: The key-value cache of attention layers used to speed up decode by reusing past states. "KvCache transfer for disaggregated inference with dynamic scaling"
- libfabric: A user-space fabric API used to program EFA/SRD and other transports. "exposed via libfabric."
- libibverbs: The user-space verbs API for programming RDMA devices like ConnectX. "a multitude of NICs programmable via libibverbs"
- MeshGroup: A sub-mesh (subgroup) of a DeviceMesh processed in parallel during weight transfer. "We call each sub-mesh a MeshGroup."
- mlx5: The Mellanox driver for ConnectX devices used by some specialized kernels. "and \verb|mlx5| driver."
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of experts for scalability. "Mixture-of-Experts (MoE) architectures are becoming the dominant approach for scaling model capacity"
- MTU: Maximum Transmission Unit; the max payload size per packet on a link. "MTU"
- NCCL: NVIDIA’s collective communication library widely used in ML frameworks. "LLM frameworks overwhelmingly rely on collective communication, often through NCCL or torch.dist-ributed."
- Network Interface Controller (NIC): The network card providing RDMA capabilities. "Existing implementations are locked to specific Network Interface Controllers (NICs),"
- NUMA: Non-Uniform Memory Access; CPU/memory topology affecting placement and latency. "pinned to a CPU core on the NUMA node"
- NVLink: NVIDIA’s high-bandwidth GPU interconnect used for intra-node transfers. "we also utilize NVLink to reduce the load on the network."
- NVSHMEM: A PGAS-style library for GPU clusters offering collectives and P2P operations. "NVSHMEM exposes both collective operations as well as flexible point-to-point communication."
- One-sided RDMA Write: RDMA write that directly writes into remote memory without remote CPU involvement. "one-sided RDMA Write directly from each training GPU to inference GPUs."
- Out-of-order delivery: Transport property where messages can arrive out of order while still being reliable. "with out-of-order delivery."
- PCIe: Peripheral Component Interconnect Express; the GPU–NIC/CPU interconnect. "over PCIe"
- Prefill: The initial LLM stage that computes and stores KV cache before token-by-token decoding. "separating the prefill and decode stages of LLM inference"
- Queue Pair (QP): The RDMA endpoint pair (send/recv queues) used to post work to the NIC. "DeepEP kernels rely on the strong ordering guarantees of RC QP."
- RKey: The remote key authorizing access to a registered remote memory region. "requiring the remote memory address and key (RKey)."
- RDMA: Remote Direct Memory Access; kernel-bypass networking for low-latency, high-throughput data movement. "Remote Direct Memory Access (RDMA) is the high-throughput, low-latency backbone of modern ML systems."
- RC handshakes: The connection-establishment steps required to set up Reliable Connection QPs. "use an UD queue pair to exchange RC hanshakes."
- Reliable Connection (RC): A reliable, connection-oriented RDMA transport with in-order guarantees (unless relaxed). "Reliable Connection (RC) transport"
- Scatter: An operation that distributes slices of a buffer to different peers/offsets. "issues a single scatter"
- Scalable Reliable Datagram (SRD): EFA’s reliable, connectionless, unordered transport protocol. "implements a proprietary Scalable Reliable Datagram (SRD) protocol"
- Send/Recv: Two-sided RDMA operations requiring posted receives at the destination. "Two-sided Send/Recv operations"
- UCCL: A communication library focusing on collective optimizations. "Other libraries, such as UCCL and MSCCL++, focus on network-layer optimizations"
- UCX: A high-performance communication framework used by some inference libraries. "built on UCX"
- Unreliable Connection (UC): An RDMA transport with connection semantics but no reliability guarantees. "Unreliable Connection (UC)"
- Unreliable Datagram (UD): A connectionless, unreliable RDMA transport. "Unreliable Datagram (UD)."
- Unified Virtual Memory (UVM): CUDA’s unified address space for CPU and GPU memory. "It allocates a unified virtual memory (UVM) location"
- UVM watcher: A polled UVM word used to signal GPU progress to the host. "we increment the UVM watcher value after the attention output projection of each layer"
- veRL: A reinforcement learning framework referenced among adopters. "AReaL, veRL, LlamaRL"
- Work Request (WR) templating: Pre-populating libfabric/verbs descriptors to reduce submission overhead. "we employ work request (WR) templating"
- WR chaining: Linking multiple send work requests to reduce doorbell rings and submission overhead. "we employ WR chaining by linking up to 4 work requests"
- WriteImm: An RDMA write variant that carries a 32-bit immediate for receiver-side notification. "WriteImm extends Write by delivering a 32-bit immediate value"
Collections
Sign up for free to add this paper to one or more collections.