- The paper introduces MARAG-R1, a framework that leverages multi-tool retrieval and reinforcement learning to synthesize information from extensive corpora.
- It employs a dual-stage training process with supervised fine-tuning and reinforcement learning to strategically guide tool usage.
- Evaluations on benchmarks like GlobalQA and HotpotQA demonstrate significant improvements in answer accuracy and document coverage.
The paper introduces the MARAG-R1 framework, designed to enhance Retrieval-Augmented Generation (RAG) systems by moving beyond the limitations of single-retriever models. By incorporating multiple retrieval tools and employing reinforcement learning, MARAG-R1 achieves superior information retrieval and reasoning capabilities, especially in tasks requiring corpus-level synthesis. This essay provides a detailed examination of MARAG-R1, its implementation, performance, and implications for future developments in AI retrieval methods.
Framework and Novel Contributions
Limitations of Existing RAG Systems
Traditional RAG systems rely on a single retriever, often leading to information bottlenecks. They operate by selecting a fixed top-k subset of documents for answer generation. This method restricts the model's adaptability and access to the complete corpus, hindering its ability to resolve tasks necessitating comprehensive reasoning.
MARAG-R1 innovatively equips Models with four retrieval tools: semantic search, keyword search, filtering, and aggregation. The framework employs a two-stage training approach:
- Supervised Fine-Tuning (SFT): Initially provides the model with foundational knowledge on tool usage.
- Reinforcement Learning (RL): Refines the multi-tool coordination through rewards that promote effective retrieval and decision-making.
This dual-stage training equips the model with the versatility needed to dynamically access diverse information sources, thereby enhancing its reasoning and generative accuracy.
Training Process and Implementation Details
Trajectory Collection
The framework begins by collecting expert trajectories, designing retrieval tools to support various retrieval demands, thereby structifying how each tool should be utilized for a given query.
Reinforcement Learning and Reward Design
A composite reward system is employed, comprising:
- Answer Reward (RA): Evaluates the precision of the generated answers.
- Document Coverage Reward (RE): Assesses completeness and precision of retrieved document sets.
- Tool Exploration Reward (RT): Encourages strategic tool usage without excessive redundancy.
This reward system guides the model toward maximizing evidence coverage and reasoning completeness.
Experimental Results
MARAG-R1 demonstrates state-of-the-art performance across various datasets (GlobalQA, HotpotQA, and 2WikiMultiHopQA) and tasks (TopK, Count, Sort, MinMax), exceeding existing baselines in both answer accuracy (F1) and document coverage (D-F1@20).
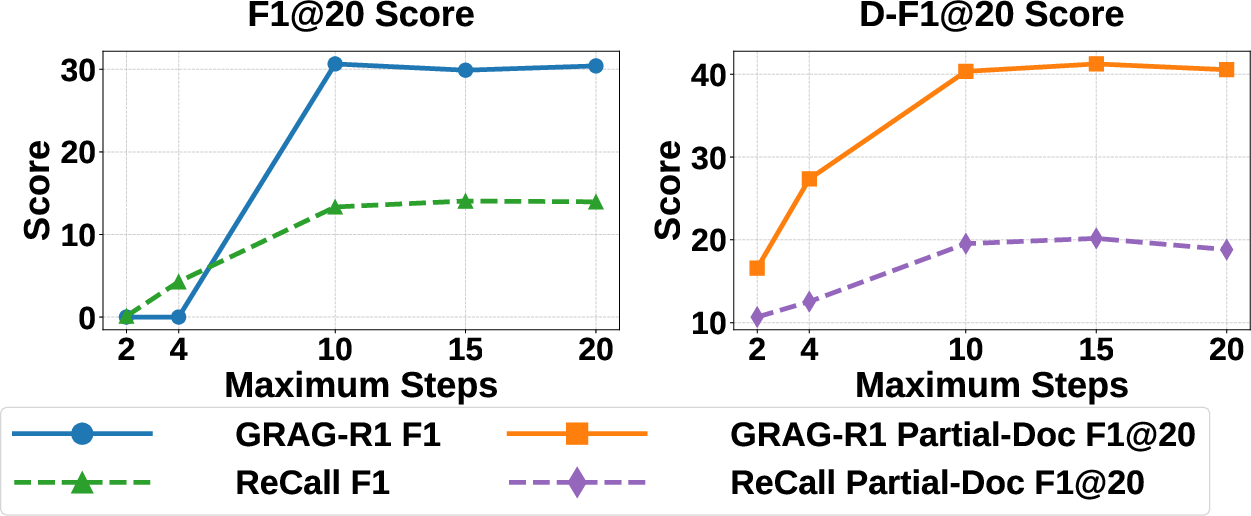
Figure 1: F1/D-F1@20 performance of MARAG-R1 and ReCall under different retrieval steps.
Ablation Studies
Ablation studies reveal each component's critical role, with supervised fine-tuning and reinforcement learning each significantly enhancing overall performance. Removing any retrieval tool or reward term results in measurable performance degradation, underscoring their synergistic contribution to MARAG-R1’s efficacy.
Generalization and Implications
Application to Multi-Hop QA Tasks
MARAG-R1's design enables effective generalization to multi-hop reasoning tasks, highlighting its broader applicability beyond the tested datasets. It efficiently acquires and utilizes external information, maintaining high accuracy across varied contexts.
Future Directions
By demonstrating a flexible framework for integrating dynamic retrieval strategies, MARAG-R1 sets a foundation for further enhancements in AI’s ability to process and synthesize large-scale information systems. Future work may involve optimizing retrieval paths and exploring additional tools or hybrid models to further expand the system’s reasoning capabilities.
Conclusion
MARAG-R1 represents a significant advancement in Retrieval-Augmented Generation, offering a comprehensive strategy for overcoming traditional RAG systems’ limitations. By leveraging multi-tool coordination and reinforcement learning, it not only enhances retrieval accuracy but also ensures deeper reasoning capabilities, marking a pivotal step towards more intelligent and adaptive AI systems.